The exponential growth of artificial intelligence applications has introduced unprecedented demands on system performance and resource management, making sophisticated caching strategies essential for delivering responsive and scalable AI services. Modern AI workloads, characterized by computationally intensive model inference, large dataset processing, and real-time prediction requirements, necessitate advanced caching architectures that go far beyond traditional web application caching approaches. The integration of intelligent caching mechanisms using Redis, Memcached, and edge optimization techniques has become fundamental to achieving the performance benchmarks required for production AI systems.
Explore the latest AI infrastructure trends to understand how caching strategies are evolving alongside advancing AI technologies and computational requirements. The strategic implementation of caching layers within AI architectures represents a critical optimization that can dramatically reduce latency, minimize computational costs, and improve overall system reliability while handling the massive scale requirements typical of modern machine learning applications.
Understanding AI-Specific Caching Challenges
Artificial intelligence applications present unique caching challenges that distinguish them from conventional web applications and require specialized approaches to achieve optimal performance. Unlike traditional applications where cached data typically consists of static content or database query results, AI systems must cache complex computational results, model predictions, feature vectors, and intermediate processing states that vary significantly in size, access patterns, and computational cost. The dynamic nature of machine learning workloads, combined with the substantial computational overhead of model inference, creates caching scenarios where traditional strategies may prove inadequate or counterproductive.
The temporal characteristics of AI workloads introduce additional complexity, as model predictions may have varying relevance periods depending on the underlying data volatility and business requirements. Real-time recommendation systems, for instance, require caching strategies that balance the freshness of recommendations with the computational cost of regenerating them, while batch processing systems may benefit from longer cache retention periods but require different eviction strategies to manage memory efficiently. These considerations necessitate sophisticated caching architectures that can adapt to the specific requirements of different AI workload patterns while maintaining high performance across diverse use cases.
Redis: The Versatile AI Caching Powerhouse
Redis has emerged as a cornerstone technology for AI caching implementations, offering a comprehensive suite of data structures and capabilities that align perfectly with the complex requirements of machine learning applications. The in-memory nature of Redis provides the ultra-low latency access patterns essential for real-time AI inference, while its rich data type support enables efficient storage of vectors, matrices, and complex nested data structures commonly used in AI workloads. The atomic operations and transaction capabilities of Redis ensure data consistency in concurrent AI processing scenarios, where multiple processes may simultaneously access and modify cached computational results.
The advanced features of Redis, including pub/sub messaging, Lua scripting, and clustering capabilities, enable sophisticated caching patterns specifically tailored for AI applications. Vector similarity searches, a common requirement in recommendation systems and natural language processing applications, can be efficiently implemented using Redis modules like RediSearch or custom Lua scripts that perform complex operations directly within the cache layer. The ability to expire keys with precise timing control allows for implementing intelligent cache invalidation strategies that align with model retraining schedules or data freshness requirements, ensuring that cached predictions remain relevant and accurate over time.
Enhance your AI infrastructure with Claude’s advanced reasoning capabilities for designing and optimizing complex caching architectures that maximize performance while minimizing resource utilization. The integration of Redis into AI systems extends beyond simple key-value storage to encompass complex workflow orchestration, real-time analytics, and intelligent data lifecycle management that supports the full spectrum of machine learning operations from training to inference and monitoring.
Memcached: Simplicity and Performance for AI Workloads
Memcached represents a compelling choice for AI caching scenarios that prioritize simplicity, performance, and predictable memory usage patterns over advanced data structure support. The lightweight architecture and minimal operational overhead of Memcached make it particularly suitable for AI applications with straightforward caching requirements, such as storing model prediction results, preprocessed feature vectors, or computed embeddings that don’t require complex data manipulations within the cache layer. The distributed nature of Memcached enables horizontal scaling across multiple nodes, providing the memory capacity necessary for large-scale AI applications while maintaining consistent performance characteristics.
The simplicity of Memcached’s design translates into significant advantages for AI workloads with high-throughput requirements and predictable access patterns. The absence of complex data structures and advanced features reduces memory overhead and computational complexity, allowing more memory to be dedicated to actual cached data rather than metadata and indexing structures. This efficiency becomes particularly important in AI applications where cached data may consist of large tensors, model weights, or preprocessed datasets that require substantial memory allocation. The consistent hashing algorithm used by Memcached ensures even distribution of cached data across cluster nodes, preventing hotspots that could degrade performance in high-load AI serving scenarios.
Edge Computing Optimization for AI Caching
Edge computing has revolutionized AI caching strategies by bringing computational resources and cached data closer to end users and data sources, dramatically reducing latency and improving the user experience for AI-powered applications. The deployment of caching layers at edge locations enables intelligent preprocessing of requests, local storage of frequently accessed model outputs, and reduced bandwidth requirements for centralized AI services. This distributed approach is particularly valuable for applications such as autonomous vehicles, IoT sensor networks, and mobile AI applications where network latency and connectivity reliability are critical factors in system performance.
The implementation of edge caching for AI applications requires careful consideration of cache coherence, data synchronization, and model version management across distributed nodes. Smart caching algorithms at the edge can implement predictive prefetching based on usage patterns, geographic trends, and temporal factors that influence AI request patterns. The limited storage capacity at edge nodes necessitates highly efficient eviction policies that prioritize the most valuable cached data while ensuring that critical AI responses remain immediately available. Advanced edge caching systems can implement hierarchical caching structures that cascade from local edge caches to regional caches and ultimately to centralized AI computing resources, creating a multi-tiered architecture that optimizes both performance and resource utilization.
Intelligent Cache Invalidation and Consistency
The management of cache validity and consistency in AI systems presents unique challenges that require sophisticated strategies beyond traditional time-based or manual invalidation approaches. AI model predictions and computed results have complex dependency relationships with underlying data, model versions, and environmental factors that influence their continued accuracy and relevance. Implementing intelligent cache invalidation requires understanding these dependencies and developing automated systems that can detect when cached results should be refreshed based on data changes, model updates, or accuracy degradation metrics.
Advanced cache invalidation strategies for AI applications can leverage machine learning techniques themselves to predict when cached data should be refreshed. These meta-AI systems can analyze access patterns, accuracy metrics, and data drift indicators to proactively invalidate cache entries before they become stale or inaccurate. The integration of cache invalidation with continuous integration and deployment pipelines ensures that model updates automatically trigger appropriate cache refreshes, maintaining consistency between deployed models and cached predictions. Event-driven invalidation systems can respond to real-time data updates, user behavior changes, or external triggers that affect the validity of cached AI computations.
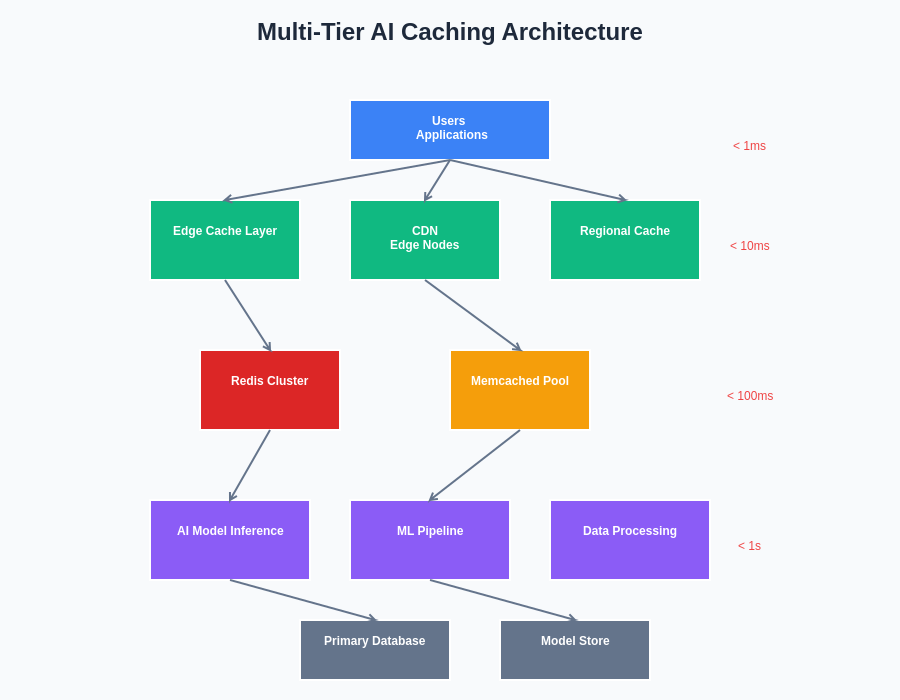
The hierarchical structure of modern AI caching architectures demonstrates the sophisticated coordination required between different cache layers to achieve optimal performance. This multi-tier approach enables intelligent data placement decisions that balance access speed, storage capacity, and computational cost across the entire system infrastructure.
Leverage Perplexity’s research capabilities to stay current with emerging caching technologies and optimization techniques that can enhance your AI system performance and reliability. The evolution of cache invalidation strategies continues to advance with new approaches including probabilistic invalidation, confidence-based expiration, and adaptive invalidation that learns from historical patterns to optimize cache hit rates while maintaining data freshness.
Performance Metrics and Monitoring
Effective monitoring and measurement of AI caching performance requires specialized metrics that capture both traditional caching effectiveness and AI-specific performance characteristics. Standard cache metrics such as hit ratio, latency, and throughput provide important baseline measurements, but AI applications benefit from additional metrics including prediction accuracy of cached results, computational cost savings, and model-specific performance indicators. The monitoring of cache performance must account for the varying computational costs of different AI operations, where a cache miss for an expensive deep learning inference may have dramatically different implications than a miss for a simple feature lookup.
Comprehensive monitoring systems for AI caching should track the relationship between cache performance and overall AI system performance, including inference latency, model accuracy, and resource utilization patterns. The measurement of cache effectiveness should consider the business value of cached computations, as some AI predictions may have significantly higher value than others, making cache optimization decisions more nuanced than simple hit ratio optimization. Advanced monitoring can implement predictive analytics to forecast cache performance under different load scenarios, enabling proactive optimization and capacity planning that ensures consistent performance during peak usage periods.
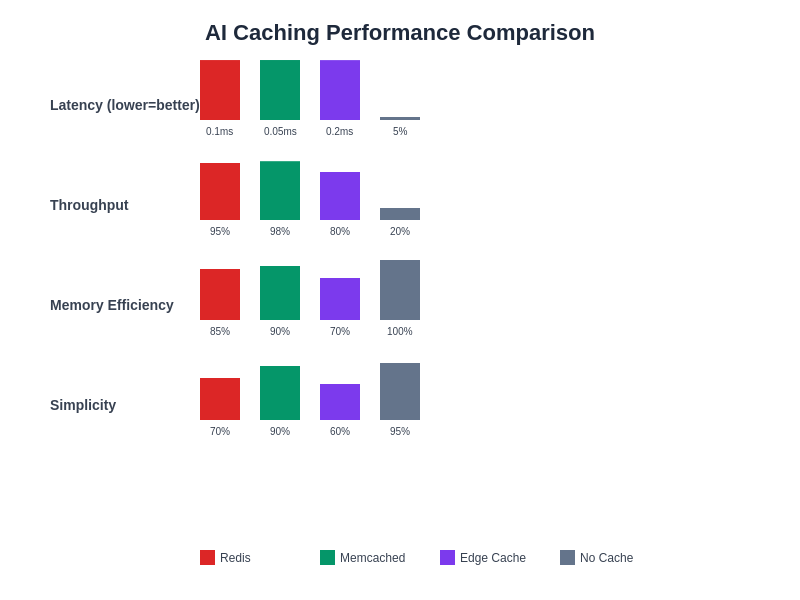
The quantitative analysis of different caching solutions reveals significant performance variations across key metrics including latency, throughput, memory efficiency, and implementation complexity. Understanding these performance characteristics enables informed decision-making when selecting appropriate caching technologies for specific AI workload requirements.
Multi-Tier Caching Architectures
The complexity and scale of modern AI applications often necessitate multi-tier caching architectures that combine different caching technologies and strategies to optimize performance across various layers of the system. These hierarchical approaches typically implement fast, small caches for the most frequently accessed data, medium-tier caches for moderately accessed content, and large-capacity storage for less frequently needed but expensive-to-compute results. The design of multi-tier caching systems requires careful analysis of access patterns, data characteristics, and performance requirements to ensure that each tier contributes effectively to overall system performance.
Intelligent promotion and demotion algorithms within multi-tier architectures can automatically manage data movement between cache layers based on access frequency, computational cost, and data size considerations. Hot data frequently accessed by AI inference processes can be promoted to faster cache tiers, while cold data can be moved to more cost-effective storage layers without significantly impacting performance. The coordination between cache tiers requires sophisticated consistency mechanisms that ensure data coherence while minimizing synchronization overhead that could negate the performance benefits of the multi-tier approach.
Security Considerations in AI Caching
The implementation of caching strategies in AI systems introduces important security considerations that must be addressed to protect sensitive data, model intellectual property, and system integrity. Cached AI predictions may contain sensitive information derived from personal data, proprietary algorithms, or confidential business intelligence that requires encryption, access controls, and audit logging. The distributed nature of many caching implementations creates additional attack surfaces that must be secured through network encryption, authentication mechanisms, and secure key management practices.
Cache poisoning attacks represent a particular concern for AI systems, where malicious actors might attempt to inject false data into caches to manipulate AI predictions or system behavior. The implementation of cache validation mechanisms, digital signatures, and integrity checks can help detect and prevent such attacks while maintaining the performance benefits of caching. The design of secure caching systems must balance security requirements with performance needs, implementing protection mechanisms that don’t significantly degrade the low-latency characteristics essential for real-time AI applications.
Cost Optimization Through Intelligent Caching
Strategic caching implementation can significantly reduce the operational costs of AI systems by minimizing expensive computational operations, reducing cloud service usage, and optimizing resource allocation across different infrastructure components. The cost savings from effective caching extend beyond simple compute cost reduction to include bandwidth savings, reduced API call charges, and improved resource utilization that enables better capacity planning and infrastructure efficiency. The calculation of caching ROI in AI systems should consider both direct cost savings and indirect benefits such as improved user experience and system reliability.
Advanced cost optimization strategies can implement dynamic caching policies that adjust based on real-time cost factors, computational load, and business priorities. These intelligent systems can automatically scale cache capacity during high-demand periods, implement cost-aware eviction policies that prioritize retaining expensive-to-compute results, and optimize cache placement across different cost tiers of infrastructure resources. The integration of cost monitoring with cache performance metrics enables data-driven optimization decisions that balance performance requirements with budget constraints.
Future Trends in AI Caching Technology
The evolution of AI caching technologies continues to advance with new approaches including neuromorphic caching systems that mimic brain-like storage and retrieval patterns, quantum-enhanced caching algorithms that leverage quantum computing principles for optimization problems, and AI-driven cache management systems that use machine learning to continuously optimize caching strategies. These emerging technologies promise to address current limitations in cache efficiency, scalability, and adaptability while introducing new capabilities that align with the advancing requirements of next-generation AI applications.
The integration of edge AI processing with advanced caching strategies is creating new paradigms where caching and computation become increasingly intertwined, enabling dynamic optimization that adapts to changing conditions, user behavior, and system requirements. The development of standardized caching APIs and protocols specifically designed for AI workloads will facilitate better integration between different caching technologies and AI frameworks, enabling more sophisticated and efficient caching implementations across diverse AI application domains.
The convergence of caching technologies with emerging AI hardware architectures, including specialized AI chips, processing-in-memory systems, and neuromorphic computing platforms, will create new opportunities for ultra-efficient caching implementations that achieve unprecedented performance levels while minimizing energy consumption and infrastructure costs. These advances will enable AI applications with even more stringent performance requirements and open new possibilities for real-time AI processing in resource-constrained environments.
Implementation Best Practices and Recommendations
Successful implementation of AI caching strategies requires careful planning, systematic testing, and continuous optimization based on real-world usage patterns and performance measurements. The selection of appropriate caching technologies should consider factors including data characteristics, access patterns, consistency requirements, scalability needs, and integration complexity with existing AI infrastructure. A phased approach to cache implementation allows for gradual optimization and validation of caching benefits while minimizing risks associated with major system changes.
The design of cache keys and data structures should reflect the specific characteristics of AI workloads, including hierarchical relationships between different types of cached data, version dependencies, and temporal validity patterns. Comprehensive testing of caching implementations should include performance testing under realistic load conditions, failure scenario testing to ensure system resilience, and accuracy testing to verify that cached results maintain the expected quality of AI predictions over time.
Ongoing monitoring and optimization of AI caching systems should incorporate feedback loops that enable continuous improvement of caching strategies based on evolving usage patterns, system performance, and business requirements. The establishment of clear performance baselines and optimization targets enables systematic evaluation of caching effectiveness and guides future enhancement efforts that maximize the value derived from caching investments.
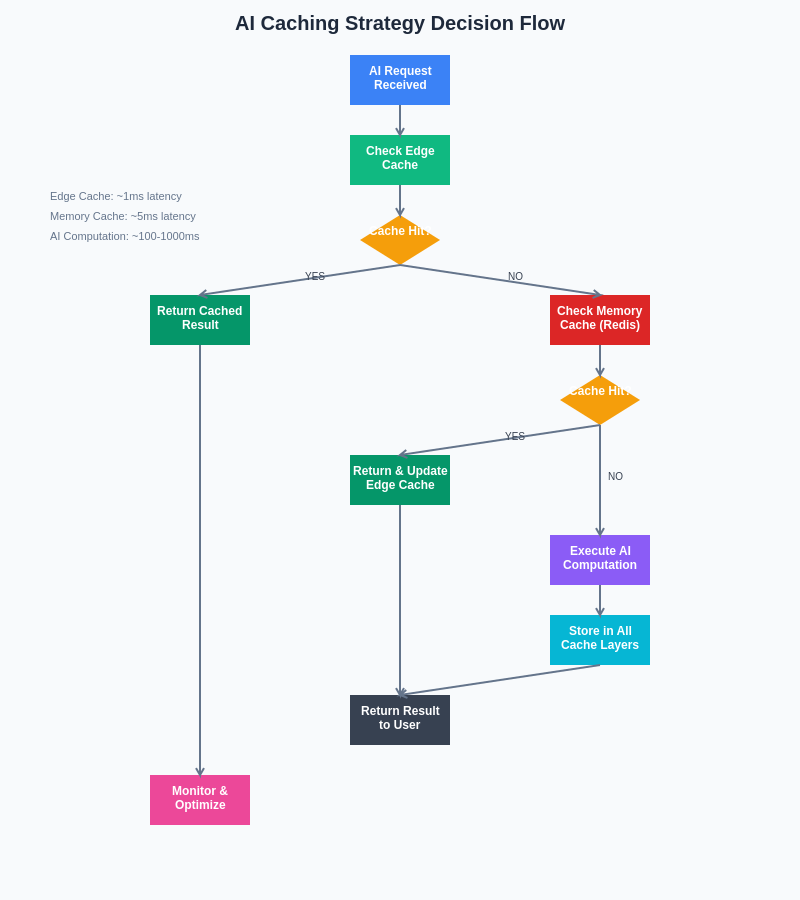
The decision-making process for AI caching implementations follows a structured approach that evaluates multiple cache layers and fallback strategies to ensure optimal performance while maintaining system reliability. This systematic workflow demonstrates how intelligent caching decisions can dramatically reduce computational overhead and improve response times for AI applications.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The implementation of caching strategies should be tailored to specific system requirements, performance objectives, and operational constraints. Readers should conduct thorough testing and evaluation before deploying caching solutions in production environments. The effectiveness of different caching approaches may vary significantly based on application characteristics, infrastructure configuration, and usage patterns.