The exponential growth of artificial intelligence and machine learning applications has created unprecedented demands for storage infrastructure capable of handling massive datasets with exceptional performance characteristics. Modern AI workloads require storage solutions that can efficiently manage petabytes of training data, support high-throughput data ingestion pipelines, and deliver consistent low-latency access patterns essential for productive machine learning workflows. The evolution of storage arrays specifically designed for AI data pipelines represents a critical foundation upon which the entire machine learning ecosystem depends for scalable and efficient operations.
Explore the latest AI infrastructure trends to understand how cutting-edge storage technologies are reshaping the landscape of machine learning data management and processing capabilities. The intersection of storage hardware innovation and artificial intelligence requirements has given rise to specialized solutions that address the unique challenges posed by modern AI workloads, from massive dataset storage to real-time inference serving.
Understanding AI Data Pipeline Requirements
The fundamental characteristics of machine learning workloads create distinct storage requirements that differentiate AI infrastructure from traditional enterprise storage solutions. Machine learning training processes typically involve sequential access to enormous datasets, requiring sustained high-bandwidth transfers that can maintain consistent throughput across extended training cycles lasting days or weeks. Unlike conventional database workloads that rely heavily on random access patterns, AI training exhibits predominantly sequential read behaviors with occasional large-block writes during checkpoint operations.
The data pipeline architecture for machine learning encompasses multiple stages, each with specific storage performance characteristics. Initial data ingestion often requires high-throughput write capabilities to accommodate streaming data sources, real-time sensor feeds, or batch processing of collected datasets. The preprocessing and feature engineering phases demand flexible storage access patterns that can efficiently handle both sequential scanning operations and random access for data transformation workflows. Training phases require sustained sequential read performance across multiple parallel processes, while inference serving introduces latency-sensitive random access patterns that must deliver consistent sub-millisecond response times.
Enhance your AI infrastructure with advanced tools like Claude to optimize data pipeline design and storage architecture planning for maximum efficiency in machine learning workflows. The complexity of modern AI data pipelines necessitates sophisticated storage solutions that can adapt to varying workload characteristics while maintaining optimal performance across all operational phases.
Storage Array Architectures for Machine Learning
Traditional storage architectures have evolved significantly to address the specific demands of artificial intelligence workloads, giving rise to specialized storage array designs optimized for machine learning data patterns. High-density storage arrays configured with large-capacity drives provide the foundation for cost-effective long-term dataset storage, enabling organizations to maintain extensive historical datasets essential for comprehensive model training and validation processes. These arrays typically incorporate intelligent tiering mechanisms that automatically migrate frequently accessed data to high-performance storage tiers while relegating archival datasets to cost-optimized storage layers.
All-flash storage arrays have emerged as the preferred solution for performance-critical AI workloads, delivering the consistent low-latency access patterns required for real-time inference serving and interactive model development workflows. These systems leverage advanced controller architectures with multiple processing cores, substantial cache memory, and optimized data paths that minimize latency bottlenecks throughout the storage stack. The parallel processing capabilities of modern flash arrays align perfectly with the concurrent data access patterns exhibited by distributed machine learning frameworks, enabling multiple training processes to access different portions of datasets simultaneously without performance degradation.
Hybrid storage arrays represent a balanced approach that combines the cost-effectiveness of traditional spinning disk storage with the performance advantages of solid-state technology. These systems employ intelligent caching algorithms that learn from AI workload access patterns, automatically promoting frequently accessed training data to high-speed flash tiers while maintaining less critical data on cost-effective mechanical storage. The automatic data movement capabilities of hybrid arrays prove particularly valuable for machine learning environments where dataset importance and access patterns evolve throughout model development lifecycles.
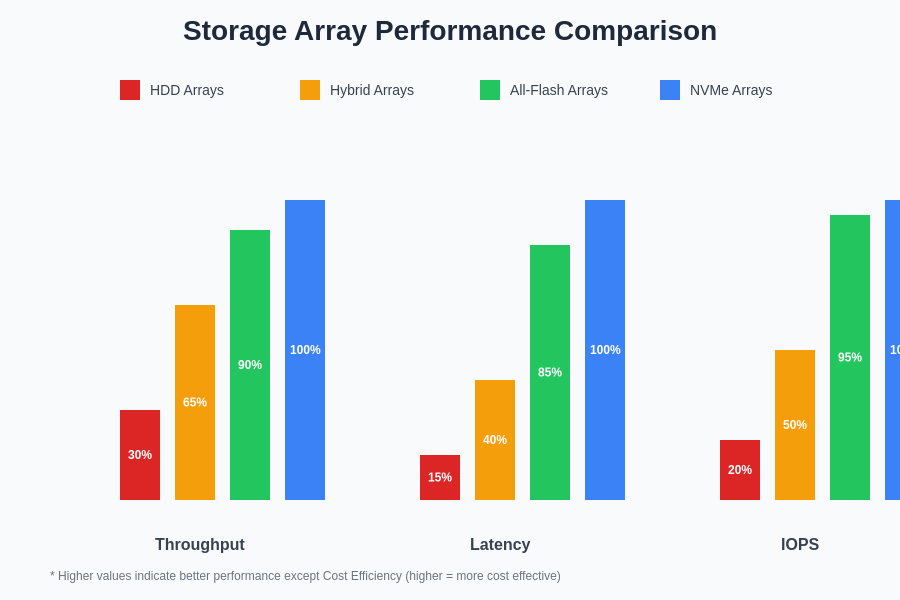
The performance characteristics of different storage array architectures reveal significant variations in their suitability for various machine learning workload types. All-flash arrays consistently deliver superior performance across all metrics, while hybrid systems provide balanced cost-performance ratios suitable for diverse AI environments.
High-Performance Storage Technologies
The foundation of effective AI storage infrastructure relies on advanced storage technologies specifically engineered to meet the demanding performance requirements of machine learning workloads. NVMe (Non-Volatile Memory Express) technology has revolutionized storage performance by eliminating traditional SATA and SAS interface bottlenecks, enabling direct communication between storage devices and system processors through high-speed PCIe connections. This architectural advancement reduces storage access latency by orders of magnitude while dramatically increasing concurrent I/O operations, making NVMe storage ideal for latency-sensitive AI inference workloads and real-time data processing applications.
Storage-class memory technologies, including Intel Optane and emerging persistent memory solutions, bridge the performance gap between traditional storage and system memory, providing ultra-low latency access to frequently referenced datasets. These technologies enable entirely new AI architecture patterns where large working datasets can be maintained in persistent storage that approaches DRAM performance characteristics, eliminating the need for complex data movement orchestration between storage and memory tiers during training operations.
Advanced controller technologies incorporating artificial intelligence accelerators directly within storage arrays represent the cutting edge of AI-optimized storage design. These intelligent storage systems can perform preprocessing operations, data compression, and even preliminary feature extraction directly within the storage layer, reducing data movement requirements and accelerating overall pipeline performance. The integration of AI acceleration capabilities within storage controllers enables sophisticated data optimization strategies that adapt automatically to specific workload characteristics and performance requirements.
Distributed Storage Solutions for Scale
The massive scale requirements of modern artificial intelligence applications have driven the development of distributed storage solutions capable of spanning hundreds or thousands of storage nodes while maintaining consistent performance and reliability characteristics. Distributed file systems specifically designed for machine learning workloads, such as specialized implementations of HDFS, GlusterFS, and emerging AI-native storage platforms, provide the scalability foundation required for enterprise-scale machine learning operations.
These distributed architectures employ sophisticated data placement algorithms that optimize dataset distribution across storage nodes based on access patterns, fault tolerance requirements, and performance objectives. Advanced erasure coding implementations provide robust data protection while minimizing storage overhead, enabling organizations to maintain multiple copies of critical training datasets without excessive storage capacity requirements. The parallel access capabilities of distributed storage systems align perfectly with the distributed training approaches used by modern machine learning frameworks, enabling linear performance scaling as additional storage nodes are integrated into the infrastructure.
Object storage platforms optimized for artificial intelligence workloads provide exceptional scalability for massive dataset storage while incorporating features specifically designed for machine learning data patterns. These systems support efficient batch processing operations, parallel data access from multiple training processes, and intelligent data lifecycle management policies that automatically transition datasets through various storage tiers based on access frequency and retention requirements.
Discover comprehensive AI research capabilities with Perplexity to stay informed about the latest developments in distributed storage technologies and their applications in large-scale machine learning environments. The continuous evolution of distributed storage solutions ensures that organizations can scale their AI infrastructure to accommodate growing dataset sizes and increasingly complex machine learning workloads.
Network-Attached Storage for AI Workloads
Network-attached storage systems designed for artificial intelligence applications must address the unique networking requirements imposed by distributed machine learning training and high-throughput data pipeline operations. High-bandwidth network fabrics, including InfiniBand and advanced Ethernet implementations, provide the foundation for efficient data movement between storage systems and compute resources, enabling multiple GPUs and training nodes to access shared datasets without network bottlenecks limiting overall system performance.
The network protocols used for AI storage access have evolved to optimize data transfer efficiency and minimize protocol overhead that can impact training performance. Remote Direct Memory Access (RDMA) technologies enable storage systems to transfer data directly into GPU memory, bypassing traditional CPU-mediated data movement pathways and reducing both latency and system resource utilization. These advanced networking approaches prove particularly valuable for large-scale distributed training operations where network efficiency directly impacts training completion times and resource utilization.
Intelligent caching strategies implemented within network-attached storage systems can significantly improve performance for repetitive data access patterns common in machine learning workflows. Distributed caching mechanisms that coordinate across multiple storage nodes ensure that frequently accessed dataset portions remain readily available close to compute resources, while less frequently accessed data can be retrieved from more distant storage tiers as needed. These caching optimizations prove particularly effective for hyperparameter tuning workflows that require repeated access to the same training datasets with different model configurations.
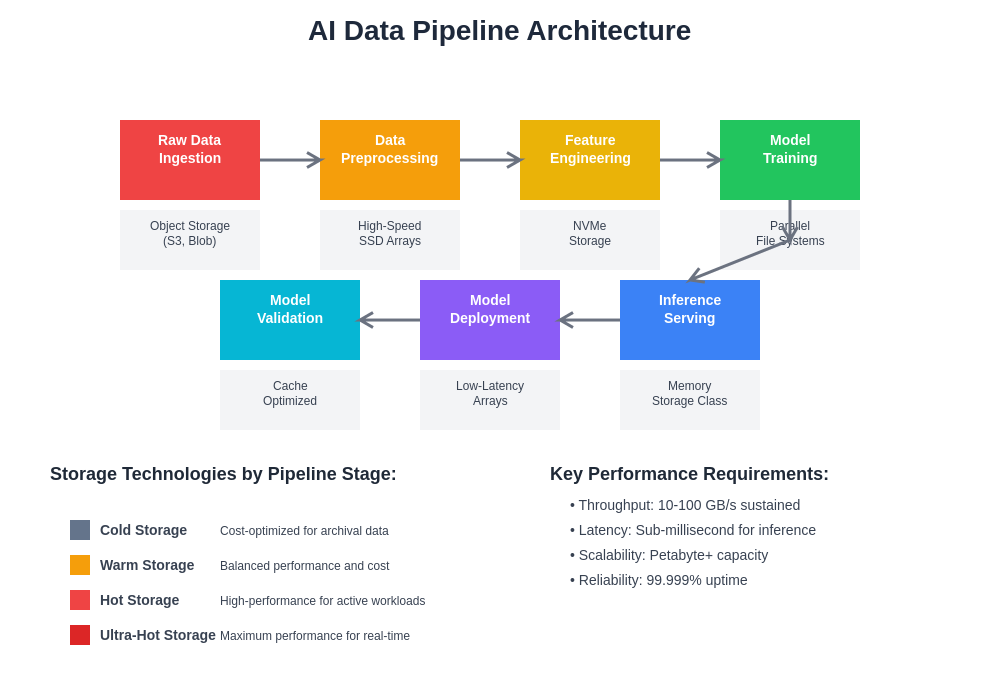
Modern AI data pipeline architectures integrate multiple storage tiers and networking technologies to optimize data flow from raw dataset storage through preprocessing, training, and inference serving stages. Each pipeline stage exhibits distinct performance requirements that inform optimal storage technology selection.
Storage Optimization Strategies
Effective storage optimization for artificial intelligence workloads requires comprehensive understanding of data access patterns, performance bottlenecks, and cost optimization opportunities throughout the machine learning development lifecycle. Data compression technologies specifically optimized for machine learning datasets can significantly reduce storage capacity requirements while maintaining acceptable decompression performance for training operations. Advanced compression algorithms that understand the statistical properties of different data types, including images, text, audio, and sensor data, achieve superior compression ratios compared to general-purpose compression techniques.
Automated data tiering policies based on dataset access patterns and training schedules can optimize storage costs while maintaining required performance levels for active machine learning projects. These policies automatically migrate datasets between high-performance and cost-optimized storage tiers based on factors such as last access time, training schedule requirements, and dataset importance classifications. Intelligent tiering systems can predict future data access patterns based on historical usage and proactively position datasets in appropriate storage tiers before they are required for training operations.
Data deduplication technologies adapted for machine learning environments can identify and eliminate redundant data across multiple dataset versions, model checkpoints, and experimental iterations. These systems understand the versioning patterns common in machine learning workflows and implement deduplication strategies that maintain data integrity while maximizing storage efficiency. Advanced deduplication implementations can identify similar datasets across different projects and experiments, enabling organization-wide storage optimization that scales with the growth of machine learning initiatives.
Performance Monitoring and Analytics
Comprehensive performance monitoring capabilities are essential for maintaining optimal storage infrastructure performance throughout the lifecycle of machine learning projects. Advanced monitoring systems specifically designed for AI workloads track metrics beyond traditional storage performance indicators, including data pipeline throughput, training iteration completion times, and inference serving latency distributions. These specialized monitoring approaches provide insights into how storage performance impacts overall machine learning productivity and model development velocity.
Real-time analytics capabilities enable immediate identification of storage bottlenecks that could impact training operations or inference serving performance. Predictive analytics based on historical performance data can forecast potential issues before they impact production workloads, enabling proactive infrastructure adjustments that maintain consistent performance levels. These analytics systems often incorporate machine learning algorithms themselves to identify complex performance patterns and optimization opportunities that might not be apparent through traditional monitoring approaches.
Storage performance optimization recommendations generated through continuous analysis of workload patterns and infrastructure utilization provide actionable insights for improving overall system efficiency. These recommendations can identify opportunities for storage configuration adjustments, hardware upgrades, or architectural changes that would deliver measurable improvements in machine learning workflow performance. Automated optimization implementations can apply certain classes of improvements automatically, ensuring that storage infrastructure continuously adapts to evolving workload requirements.
Security and Compliance Considerations
The security requirements for AI storage infrastructure extend beyond traditional data protection concerns to encompass intellectual property protection, regulatory compliance, and privacy preservation throughout the machine learning development lifecycle. Encryption implementations specifically optimized for machine learning workloads must balance security requirements with performance needs, ensuring that data protection mechanisms do not introduce unacceptable latency or throughput penalties that could impact training operations.
Access control systems for AI storage platforms must accommodate the collaborative nature of machine learning development while maintaining appropriate security boundaries around sensitive datasets and proprietary model architectures. Role-based access control implementations that understand machine learning workflow patterns can provide flexible security policies that adapt to different project phases and team collaboration requirements. These systems often incorporate audit logging capabilities that track data access patterns and modifications throughout model development processes.
Compliance requirements for industries such as healthcare, finance, and government impose additional constraints on AI storage infrastructure design and operation. Specialized storage solutions that incorporate compliance-aware data handling, retention policies, and audit capabilities enable organizations to pursue machine learning initiatives while maintaining regulatory compliance obligations. These systems often implement advanced data governance capabilities that track data lineage, transformation history, and usage patterns required for comprehensive compliance reporting.
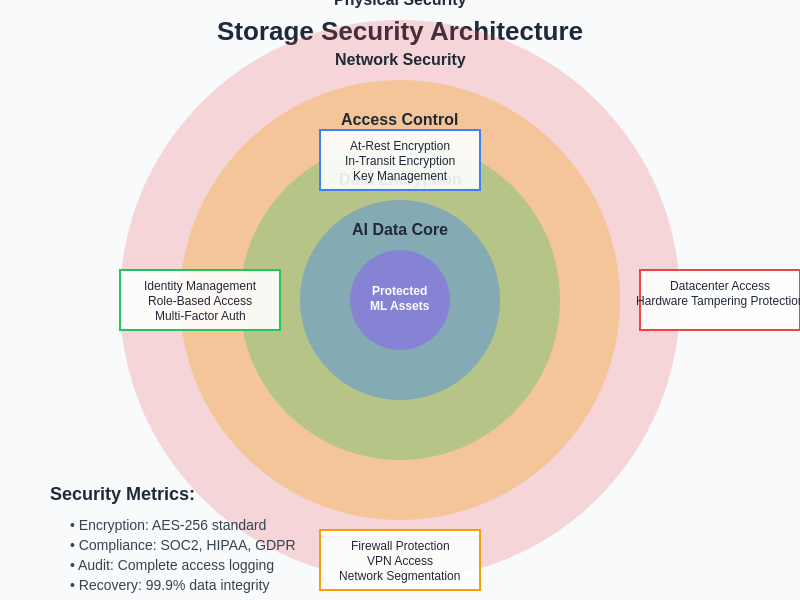
Multi-layered security architectures for AI storage systems incorporate encryption, access controls, audit logging, and compliance monitoring to protect sensitive machine learning datasets while maintaining performance requirements for training and inference operations.
Future Trends in AI Storage Technology
The rapid evolution of artificial intelligence applications continues to drive innovation in storage technologies specifically designed for machine learning workloads. Emerging memory technologies, including persistent memory, storage-class memory, and advanced NAND flash implementations, promise to further reduce the performance gap between storage and compute resources, enabling new architectural approaches that minimize data movement overhead in AI pipelines.
The integration of computational capabilities directly within storage devices represents a significant trend toward storage-centric computing architectures optimized for machine learning workloads. These intelligent storage systems can perform preprocessing operations, feature extraction, and even preliminary model inference directly within the storage layer, reducing data movement requirements and improving overall system efficiency. The development of specialized processors optimized for storage-resident computation will likely accelerate the adoption of these architectural approaches.
Quantum storage technologies, while still in early development phases, offer the potential for revolutionary advances in storage density, access speed, and computational integration that could fundamentally transform AI infrastructure requirements. The unique properties of quantum storage systems may enable entirely new approaches to machine learning data management and processing that transcend current architectural limitations.
The convergence of artificial intelligence and storage technology development promises to deliver increasingly sophisticated solutions that understand and adapt to machine learning workload requirements automatically. These future storage systems will likely incorporate advanced AI algorithms for performance optimization, predictive maintenance, and automated capacity planning, creating self-managing storage infrastructures that continuously optimize themselves for evolving AI workload demands.
Cost Optimization and ROI Analysis
Effective cost management for AI storage infrastructure requires sophisticated analysis of total cost of ownership factors that extend beyond initial hardware acquisition costs to encompass operational expenses, scalability requirements, and productivity impacts throughout the machine learning development lifecycle. The high acquisition costs of advanced storage technologies must be evaluated against the productivity gains and reduced time-to-market advantages they provide for machine learning projects, often resulting in compelling return on investment calculations despite substantial upfront investments.
Capacity planning strategies that account for the exponential growth patterns typical of machine learning datasets enable organizations to optimize storage investments while avoiding costly emergency capacity expansions. These planning approaches consider factors such as dataset growth rates, model complexity evolution, and experimental iteration requirements to project future storage needs accurately. Flexible storage architectures that support incremental capacity additions without performance disruption prove particularly valuable for managing the unpredictable growth patterns common in AI development environments.
The economic benefits of storage performance improvements extend beyond direct productivity gains to encompass reduced cloud computing costs, shorter development cycles, and improved model quality through more comprehensive training approaches. Organizations that invest in high-performance storage infrastructure often discover that the accelerated development cycles and improved model outcomes more than justify the additional infrastructure costs through competitive advantages and revenue generation opportunities.
Implementation Best Practices
Successful deployment of AI storage infrastructure requires careful consideration of integration requirements, performance optimization strategies, and operational management approaches that ensure maximum benefit realization from storage investments. Initial assessment of existing infrastructure capabilities and performance bottlenecks provides the foundation for informed storage architecture decisions that address specific organizational requirements and growth projections.
Phased implementation approaches that begin with pilot projects and gradually expand storage capabilities enable organizations to validate performance benefits and optimize configurations before committing to large-scale infrastructure investments. These incremental deployment strategies provide opportunities to refine operational procedures, train technical teams, and identify optimization opportunities that inform subsequent expansion phases.
Performance testing and validation procedures specifically designed for machine learning workloads ensure that storage infrastructure delivers expected performance characteristics under realistic operational conditions. These testing approaches should encompass various data access patterns, concurrent user scenarios, and failure recovery procedures to validate infrastructure resilience and performance consistency across diverse operational conditions.
The integration of AI storage infrastructure with existing machine learning development workflows requires careful attention to data pipeline design, tool compatibility, and operational procedures that minimize disruption while maximizing performance benefits. Successful implementations often involve collaboration between storage specialists, machine learning engineers, and operations teams to ensure that infrastructure capabilities align effectively with application requirements and development practices.
Disclaimer
This article is for informational purposes only and does not constitute professional advice regarding storage infrastructure selection or implementation. The views expressed are based on current understanding of AI storage technologies and industry best practices. Organizations should conduct thorough evaluations of their specific requirements, workload characteristics, and budget constraints when selecting storage solutions for machine learning applications. Storage technology performance and cost characteristics may vary significantly based on specific implementation details, workload patterns, and operational environments.