
The security landscape of artificial intelligence systems faces increasingly sophisticated threats, with data poisoning attacks emerging as one of the most insidious and potentially devastating attack vectors targeting machine learning models. These attacks manipulate training datasets to compromise model behavior, creating vulnerabilities that can remain undetected until deployed systems exhibit malicious or erratic behavior in production environments. Understanding the mechanisms, detection methods, and prevention strategies for data poisoning attacks has become critical for organizations developing and deploying AI systems in security-sensitive applications.
Stay updated on the latest AI security trends as the threat landscape continues evolving with new attack methodologies and defensive techniques emerging regularly. The sophistication of data poisoning attacks requires comprehensive defensive strategies that address both technical vulnerabilities and operational security practices throughout the machine learning development lifecycle.
Understanding Data Poisoning Attack Mechanisms
Data poisoning attacks operate by introducing maliciously crafted samples into training datasets, exploiting the fundamental assumption that training data accurately represents the target distribution. These attacks can be broadly categorized into availability attacks, which aim to degrade overall model performance, and integrity attacks, which seek to cause specific misclassifications while maintaining acceptable general performance. The subtle nature of these attacks makes them particularly dangerous, as poisoned models may perform normally on most inputs while exhibiting targeted vulnerabilities on specific triggers or input patterns.
The attack vectors for data poisoning are diverse and evolve continuously as attackers discover new exploitation techniques. Clean-label attacks represent one of the most sophisticated approaches, where attackers inject correctly labeled samples that appear legitimate but contain subtle perturbations designed to influence model decision boundaries. These attacks are particularly challenging to detect because the poisoned samples maintain correct labels and may appear indistinguishable from legitimate training data to human reviewers. Backdoor attacks constitute another significant threat category, where attackers embed hidden triggers in training data that cause models to exhibit specific malicious behaviors when these triggers appear in production inputs.
The effectiveness of data poisoning attacks depends on several factors, including the proportion of poisoned samples relative to clean data, the sophistication of the attack methodology, and the target model architecture. Research has demonstrated that even small percentages of poisoned data can significantly impact model behavior, with some attacks achieving high success rates with poisoning rates as low as one percent of the total training dataset. This low threshold for attack effectiveness highlights the critical importance of implementing robust data validation and verification processes throughout the machine learning development pipeline.
Detection Strategies and Methodologies
Detecting data poisoning attacks requires multi-layered approaches that combine statistical analysis, anomaly detection, and specialized verification techniques designed specifically for adversarial scenarios. Statistical outlier detection forms the foundation of many defensive strategies, identifying samples that deviate significantly from expected data distributions or exhibit unusual feature patterns. However, sophisticated attacks often evade simple statistical detection by carefully crafting poisoned samples to remain within normal distribution boundaries while still achieving their malicious objectives.
Advanced detection methodologies leverage ensemble approaches that combine multiple detection algorithms to improve overall accuracy and reduce false positive rates. These systems analyze various aspects of potential poisoning attempts, including feature space clustering patterns, gradient-based anomaly scores, and influence function analysis that measures how individual training samples affect model behavior. Machine learning-based detection systems can be trained to recognize subtle patterns indicative of poisoning attempts, though these approaches require careful validation to ensure they do not themselves become vulnerable to adversarial manipulation.
Enhance your AI security capabilities with Claude for comprehensive analysis of potential threats and development of robust defensive strategies tailored to specific deployment scenarios. The complexity of modern attacks necessitates sophisticated analytical tools that can process large datasets and identify subtle manipulation patterns that may indicate poisoning attempts.
Behavioral analysis represents another crucial detection dimension, monitoring how models perform on carefully curated validation sets and identifying unexpected performance degradations or classification patterns that may indicate compromised training data. This approach involves establishing baseline performance metrics during clean training phases and continuously monitoring for deviations that cannot be explained by normal data drift or environmental changes. Anomaly detection in model behavior patterns can reveal the presence of backdoor triggers or other malicious manipulations that affect model decision-making processes.
Data Validation and Preprocessing Defenses
Robust data validation frameworks form the first line of defense against poisoning attacks, implementing comprehensive verification processes that examine incoming training data for potential manipulation or contamination. These frameworks incorporate multiple validation layers, including format verification, consistency checking, and domain-specific validation rules that identify samples falling outside expected parameter ranges. Automated validation systems can process large datasets efficiently while maintaining high detection accuracy for obvious manipulation attempts.
Preprocessing defenses focus on sanitizing training data through various transformation and filtering techniques designed to neutralize potential poisoning attempts while preserving legitimate data integrity. Data augmentation strategies can dilute the impact of poisoned samples by generating additional clean examples that overwhelm malicious contributions to the training process. Differential privacy techniques add controlled noise to training data, making it more difficult for attackers to precisely control model behavior while maintaining overall utility for legitimate learning objectives.
Feature space analysis plays a critical role in identifying potentially compromised data by examining the distribution and relationships between different input dimensions. Clustering algorithms can group similar samples and identify outliers that may represent poisoning attempts, while dimensionality reduction techniques can reveal hidden patterns in high-dimensional data that indicate manipulation. These preprocessing approaches require careful calibration to balance security benefits with potential impacts on model performance and accuracy.
Model Architecture and Training Defenses
Defensive training methodologies incorporate robustness considerations directly into the model development process, creating architectures and training procedures that are inherently more resistant to data poisoning attacks. Adversarial training exposes models to known attack patterns during development, improving their ability to maintain correct behavior when encountering similar threats in production environments. This approach requires comprehensive threat modeling to identify potential attack vectors and develop appropriate training scenarios that build resistance without compromising legitimate functionality.
Ensemble methods provide natural resistance to poisoning attacks by combining predictions from multiple models trained on different data subsets or with different architectural approaches. The diversity inherent in ensemble systems makes it significantly more difficult for attackers to simultaneously compromise all component models, reducing the overall system vulnerability to coordinated poisoning attempts. Byzantine-robust aggregation algorithms can identify and exclude potentially compromised model contributions while maintaining overall system performance and accuracy.
Regularization techniques specifically designed for adversarial robustness can limit the impact of poisoned samples by constraining model complexity and preventing overfitting to malicious patterns. These approaches include spectral normalization, gradient penalty methods, and custom loss functions that penalize excessive sensitivity to individual training samples. Model interpretability tools can provide insights into decision-making processes, helping identify potential backdoors or other anomalous behaviors that may indicate successful poisoning attacks.
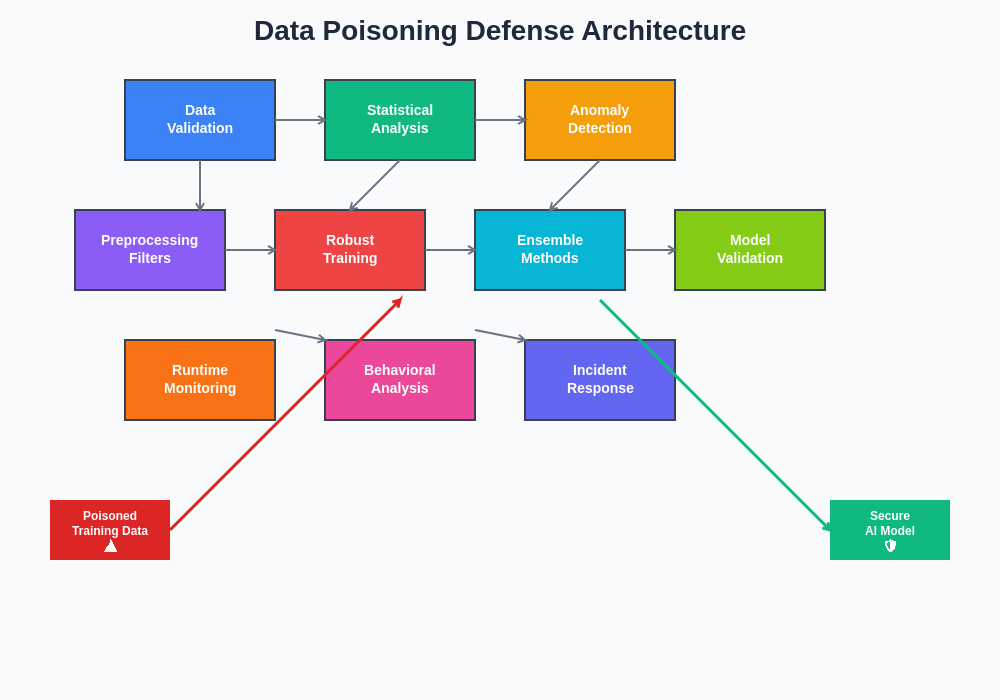
The implementation of layered defensive architectures creates multiple barriers against data poisoning attacks, combining preprocessing validation, robust training methodologies, and runtime monitoring to provide comprehensive protection throughout the machine learning lifecycle. Each defensive layer contributes specific capabilities while supporting overall system resilience against sophisticated attack strategies.
Continuous Monitoring and Threat Assessment
Production deployment of machine learning systems requires continuous monitoring capabilities that can detect potential poisoning effects in real-time operational environments. These monitoring systems track model behavior patterns, performance metrics, and prediction distributions to identify anomalies that may indicate compromised training data or ongoing attacks against deployed systems. Automated alerting mechanisms can notify security teams of potential threats, enabling rapid response to contain damage and initiate defensive countermeasures.
Threat intelligence integration enhances monitoring effectiveness by incorporating knowledge of emerging attack methodologies and indicators of compromise specific to machine learning systems. This intelligence feeds into automated detection systems and helps security teams understand the evolving threat landscape affecting AI deployments. Regular assessment of model vulnerability to known attack patterns provides ongoing validation of defensive effectiveness and identifies areas requiring additional protection measures.
Leverage Perplexity for comprehensive threat research and analysis of emerging attack vectors that may not be covered by traditional security monitoring tools. The rapidly evolving nature of adversarial machine learning requires continuous research and adaptation of defensive strategies to address new threat vectors as they emerge.
Performance baseline establishment creates reference points for normal model behavior that enable detection of gradual degradation or subtle manipulation effects that may indicate successful poisoning attacks. These baselines must account for normal data drift and environmental changes while remaining sensitive to malicious influences on model behavior. Statistical process control techniques can identify trends and patterns in model performance that warrant further investigation for potential security implications.
Incident Response and Recovery Procedures
When data poisoning attacks are detected or suspected, organizations must implement rapid response procedures to contain damage, assess impact scope, and initiate recovery operations. Incident response planning for AI systems requires specialized procedures that address the unique challenges of machine learning security, including model quarantine protocols, data forensic analysis capabilities, and coordinated response across development and operations teams. Response procedures must balance the need for rapid containment with thorough investigation requirements to understand attack methodologies and prevent future incidents.
Model rollback capabilities provide critical recovery options when poisoning attacks are confirmed, enabling organizations to revert to previously validated model versions while investigating the extent of compromise. These rollback procedures require comprehensive version control systems and validated backup models that can be quickly deployed to maintain service continuity. Emergency response protocols must address both technical recovery requirements and communication procedures for stakeholders affected by potential security incidents.
Data forensic analysis techniques specifically designed for machine learning environments can help investigate poisoning incidents and identify attack vectors, compromised data sources, and potential ongoing threats. These investigations require specialized tools and expertise to analyze training datasets, model behavior patterns, and system logs to reconstruct attack timelines and assess damage scope. Forensic findings inform improvements to defensive measures and help prevent similar incidents in future deployments.
Regulatory Compliance and Standards
The increasing recognition of AI security risks has led to evolving regulatory frameworks and industry standards that address data poisoning threats and defensive requirements. Organizations developing AI systems must navigate compliance requirements while implementing effective security measures that meet both regulatory mandates and operational security objectives. Understanding these requirements helps prioritize security investments and ensure defensive strategies align with legal and industry obligations.
Industry standards for AI security provide frameworks for implementing comprehensive defensive measures against data poisoning and other adversarial threats. These standards offer guidance on risk assessment methodologies, defensive architecture design, and validation procedures that help organizations build robust security programs. Compliance with recognized standards can also provide legal protection and demonstrate due diligence in addressing known security risks.
Documentation requirements for AI security implementations create audit trails that support compliance verification and incident investigation processes. These documentation standards cover risk assessments, defensive measure implementations, monitoring procedures, and incident response capabilities. Maintaining comprehensive security documentation supports both regulatory compliance and operational security effectiveness by ensuring defensive measures are properly implemented and maintained.
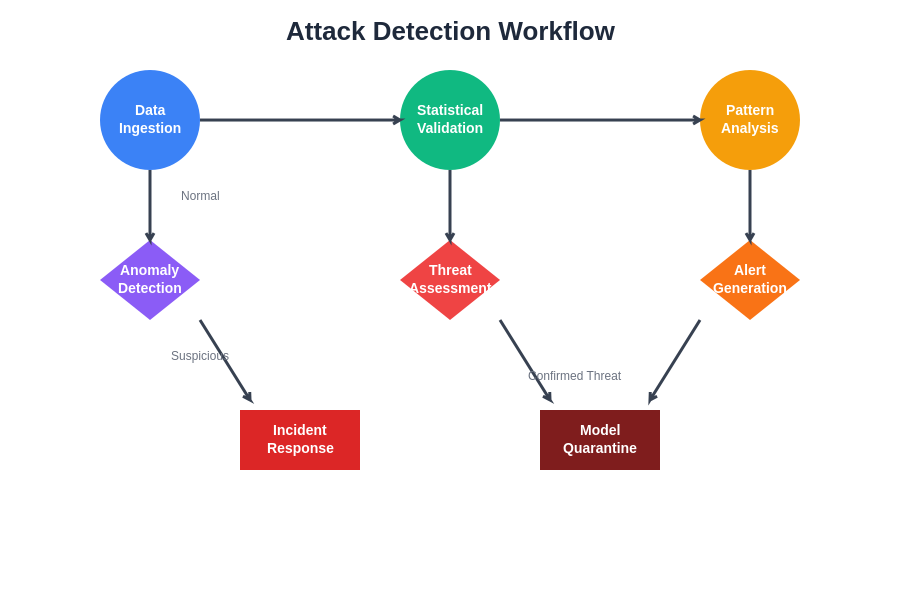
The systematic approach to detecting and responding to data poisoning attacks requires coordinated workflows that integrate automated detection capabilities with human expertise and organizational response procedures. This comprehensive approach ensures rapid identification of threats while maintaining thorough investigation and response capabilities.
Future Developments and Research Directions
The evolving landscape of adversarial machine learning continues producing new attack methodologies and defensive techniques that shape the future of AI security. Research into federated learning security addresses unique challenges of distributed training environments where data poisoning attacks may target specific participants or exploit communication protocols. Advanced cryptographic techniques, including homomorphic encryption and secure multi-party computation, offer potential solutions for protecting training data while enabling collaborative model development.
Automated defense systems leveraging artificial intelligence for security monitoring represent promising developments in the fight against data poisoning attacks. These systems can adapt to new attack patterns, optimize defensive parameters automatically, and provide scalable protection for large-scale AI deployments. Research into adversarial robustness continues exploring fundamental limits of defensive capabilities and identifying theoretical boundaries for achievable security guarantees.
The integration of blockchain technologies and distributed ledger systems offers potential solutions for ensuring training data integrity and provenance verification. These approaches can create tamper-evident records of data sources and transformations while supporting decentralized validation of training dataset authenticity. However, implementation challenges related to scalability, privacy, and computational efficiency require continued research and development efforts.
Implementation Best Practices
Successful implementation of data poisoning defenses requires coordinated approaches that integrate security considerations throughout the machine learning development lifecycle. Organizations should establish security-focused development processes that incorporate threat modeling, risk assessment, and defensive measure validation at each stage of AI system development. These processes should include regular security reviews, penetration testing, and red team exercises specifically designed to test defenses against data poisoning attacks.
Training and education programs for development teams ensure that security considerations are properly understood and implemented throughout AI development projects. These programs should cover attack methodologies, defensive techniques, and incident response procedures while providing hands-on experience with security tools and procedures. Regular security awareness updates help teams stay current with evolving threats and defensive best practices.
Vendor evaluation processes for AI development tools and services should include security assessments that address data poisoning risks and defensive capabilities. Organizations should require vendors to demonstrate security measures, provide transparency into defensive implementations, and support security monitoring and incident response requirements. Supply chain security considerations become critical when using third-party data sources or pre-trained models that may introduce poisoning risks.
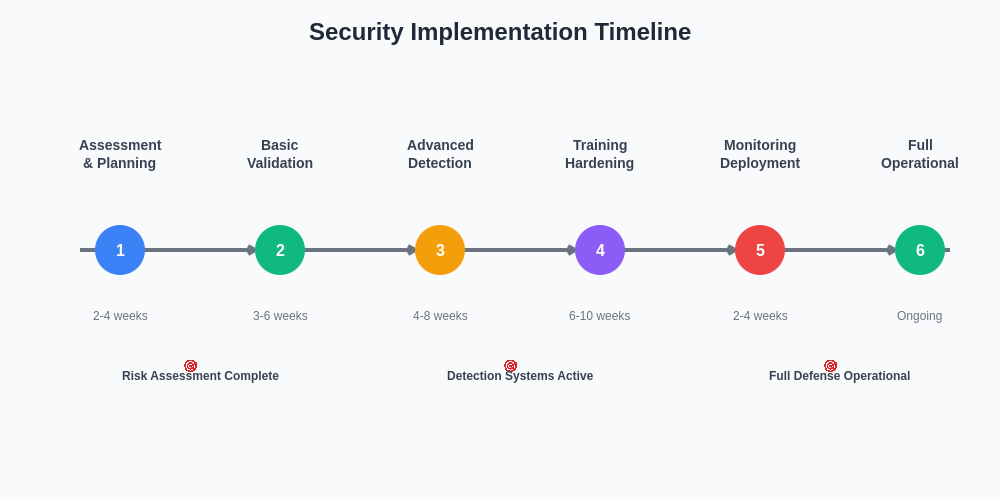
The phased approach to implementing comprehensive data poisoning defenses enables organizations to build robust security capabilities while maintaining development velocity and operational efficiency. This structured implementation strategy ensures critical defensive measures are prioritized while supporting long-term security maturation goals.
Economic and Business Impact Considerations
The economic implications of data poisoning attacks extend beyond immediate technical damage to include reputation impact, regulatory penalties, and long-term competitive disadvantages resulting from compromised AI capabilities. Organizations must consider these broader business risks when evaluating security investment priorities and developing risk management strategies. Cost-benefit analysis of defensive measures should account for potential attack damages, implementation costs, and ongoing operational requirements for maintaining security effectiveness.
Insurance considerations for AI security risks are becoming increasingly important as organizations seek to transfer some liability for potential attacks and security incidents. Insurance providers are developing specialized coverage for AI-related risks, though coverage terms and requirements continue evolving as the industry gains experience with these emerging threats. Understanding insurance requirements and coverage limitations helps inform security investment decisions and risk management strategies.
Return on investment calculations for security measures must account for both risk reduction benefits and potential performance impacts from defensive implementations. While security measures may introduce some overhead or complexity, the cost of successful attacks typically far exceeds the investment required for robust defenses. Long-term competitive advantages from trusted AI systems can also justify security investments that exceed immediate risk mitigation value.
The sophisticated nature of data poisoning attacks against AI systems requires comprehensive defensive strategies that address technical vulnerabilities, operational security practices, and organizational preparedness for emerging threats. Success in defending against these attacks depends on implementing layered defensive architectures, maintaining continuous monitoring capabilities, and staying current with evolving attack methodologies and defensive techniques. Organizations that proactively address data poisoning risks through systematic security programs will be better positioned to leverage AI technologies safely while maintaining competitive advantages in their respective markets.
Disclaimer
This article is for educational and informational purposes only and does not constitute professional security advice. The information provided represents current understanding of AI security threats and defensive measures, which continue evolving rapidly. Organizations should consult with qualified security professionals and conduct thorough risk assessments before implementing specific defensive measures. The effectiveness of security measures may vary depending on specific use cases, threat environments, and implementation details. Readers should verify current best practices and regulatory requirements applicable to their specific situations.