
The evolution of artificial intelligence has fundamentally transformed database architecture requirements, creating an urgent need for specialized data storage and retrieval systems optimized for vector operations and similarity search capabilities. Traditional relational databases, while excellent for structured data operations, face significant limitations when handling high-dimensional vector data that powers modern AI applications including recommendation systems, semantic search, image recognition, and natural language processing tasks.
Discover the latest AI database trends and innovations that are reshaping how organizations store, index, and retrieve vector data for machine learning applications. The emergence of vector databases represents a paradigm shift in data management, offering unprecedented capabilities for handling complex multidimensional data structures that traditional database systems struggle to process efficiently.
Understanding Vector Database Architecture
Vector databases represent a specialized category of database management systems specifically engineered to store, index, and query high-dimensional vector embeddings with optimal performance characteristics. Unlike traditional databases that organize data in rows and columns, vector databases utilize sophisticated mathematical structures and algorithms designed to handle the unique challenges associated with multidimensional data operations, including similarity calculations, nearest neighbor searches, and clustering operations across vast datasets.
The fundamental architecture of vector databases revolves around the concept of embedding spaces, where complex data objects such as text documents, images, audio files, or user behaviors are transformed into numerical representations that capture their semantic meaning and relationships. These embeddings exist in high-dimensional spaces, often ranging from hundreds to thousands of dimensions, requiring specialized indexing structures and search algorithms that can efficiently navigate these complex mathematical landscapes while maintaining accuracy and performance.
The design principles underlying effective vector database architecture emphasize several critical factors including dimensional scalability, search latency optimization, memory efficiency, and the ability to handle dynamic data updates without compromising query performance. These systems must balance the trade-offs between search accuracy and computational efficiency, often employing approximate nearest neighbor algorithms that provide near-optimal results with significantly reduced computational overhead compared to exhaustive search approaches.
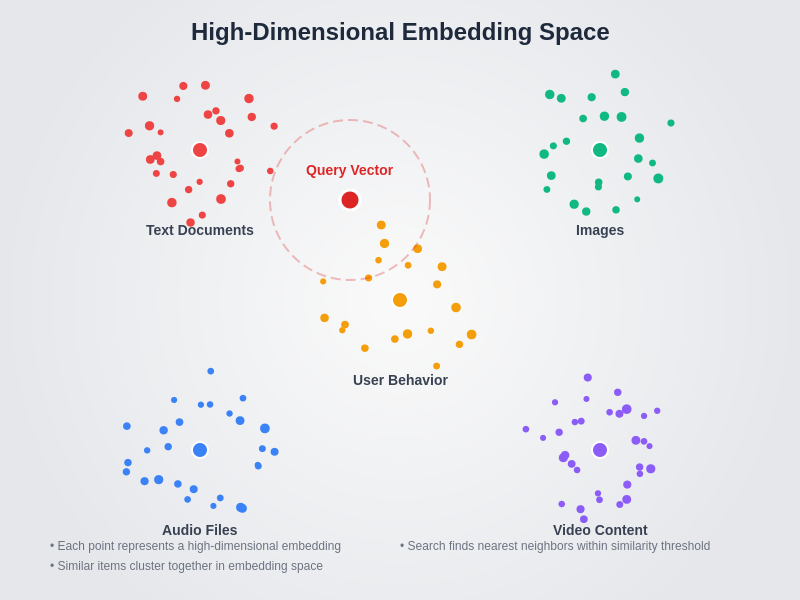
The visualization of high-dimensional embedding spaces demonstrates how complex data objects from different domains cluster together based on their semantic similarities, enabling efficient similarity search operations across diverse data types including text documents, images, audio files, and user behavior patterns.
Embedding Generation and Optimization Strategies
The process of generating high-quality embeddings forms the foundation of any successful vector database implementation, requiring careful consideration of the underlying data characteristics, intended use cases, and performance requirements. Modern embedding generation techniques leverage advanced neural network architectures including transformer models, convolutional neural networks, and specialized embedding models that can capture nuanced semantic relationships within the data while producing vector representations optimized for similarity search operations.
Embedding optimization involves multiple dimensions of consideration, beginning with the selection of appropriate embedding models that align with the specific data types and use cases being addressed. For textual data, models such as BERT, RoBERTa, and newer transformer-based architectures provide sophisticated semantic understanding, while image data benefits from convolutional neural networks and vision transformers that capture visual features and spatial relationships effectively.
The dimensionality of embeddings represents a critical optimization parameter that directly impacts both storage requirements and search performance characteristics. Higher-dimensional embeddings can capture more nuanced relationships and provide greater representational capacity, but they also increase storage costs, memory requirements, and computational complexity during search operations. The optimal embedding dimension typically depends on the complexity of the data, the required accuracy levels, and the available computational resources, with common dimensions ranging from 128 to 1536 depending on the specific application requirements.
Experience advanced AI capabilities with Claude for developing sophisticated embedding strategies and optimization techniques that maximize both accuracy and performance in vector database implementations. The integration of multiple embedding approaches and hybrid architectures often provides superior results compared to single-model approaches, enabling more robust and versatile vector search capabilities.
Vector Indexing Algorithms and Performance Optimization
The choice of vector indexing algorithm represents one of the most critical decisions in vector database design, directly impacting search performance, memory utilization, and scalability characteristics. Modern vector databases employ a variety of indexing strategies, each with distinct advantages and trade-offs that make them suitable for different use cases and performance requirements. Understanding these algorithms and their characteristics enables database architects to make informed decisions that optimize system performance for specific application needs.
Hierarchical Navigable Small World graphs, commonly known as HNSW, have emerged as one of the most effective indexing algorithms for high-dimensional vector search operations. HNSW constructs a multi-layered graph structure where each layer contains a subset of the data points, with higher layers providing coarse-grained navigation and lower layers enabling fine-grained search refinement. This hierarchical approach enables logarithmic search complexity while maintaining high accuracy levels, making it particularly suitable for applications requiring both speed and precision.
Inverted File Index structures, often combined with Product Quantization techniques, provide another powerful approach to vector indexing that excels in scenarios with large datasets and memory constraints. These systems partition the vector space into clusters and maintain inverted lists for each cluster, enabling efficient pruning of irrelevant regions during search operations. Product Quantization further enhances efficiency by compressing vectors into compact representations that reduce memory requirements while preserving sufficient information for accurate similarity calculations.
Locality Sensitive Hashing represents a probabilistic approach to vector indexing that trades some accuracy for exceptional speed and scalability. LSH algorithms create hash functions that map similar vectors to the same hash buckets with high probability, enabling rapid identification of candidate matches without requiring exhaustive distance calculations. This approach proves particularly valuable for real-time applications where response time requirements are stringent and approximate results are acceptable.

The comparative analysis of vector indexing algorithms reveals the fundamental trade-offs between accuracy, speed, and memory efficiency that characterize different approaches to high-dimensional similarity search, with each algorithm offering distinct advantages for specific use cases and performance requirements.
Similarity Search Algorithms and Distance Metrics
The effectiveness of vector search operations fundamentally depends on the choice of appropriate distance metrics and similarity algorithms that accurately capture the relationships between data points in the embedding space. Different distance metrics emphasize different aspects of vector relationships, and the optimal choice depends on the characteristics of the data, the embedding generation process, and the specific similarity semantics required by the application.
Euclidean distance represents the most intuitive similarity metric, measuring the straight-line distance between two points in multidimensional space. This metric works particularly well for embeddings where the magnitude of individual dimensions carries semantic meaning and where the geometric interpretation of distance aligns with the desired similarity semantics. Euclidean distance tends to perform effectively with embeddings generated from continuous data or when the embedding model has been specifically trained to produce geometrically meaningful representations.
Cosine similarity focuses on the angular relationship between vectors, effectively normalizing for vector magnitude and emphasizing directional similarity rather than absolute distance. This metric proves particularly valuable for text embeddings and other scenarios where the relative proportions of features matter more than their absolute values. Cosine similarity is especially effective with high-dimensional sparse vectors and embeddings generated from transformer-based models that tend to produce representations where direction carries more semantic meaning than magnitude.
Manhattan distance, also known as L1 distance, measures the sum of absolute differences between corresponding vector components, providing robustness against outliers and working effectively with embeddings that exhibit sparse characteristics. This metric often performs well with categorical or discrete data embeddings where individual dimensions represent distinct features or attributes that contribute additively to overall similarity.
Scalability Challenges and Distributed Architecture
As vector databases grow to handle billions of embeddings and serve millions of queries per second, traditional single-node architectures become insufficient, necessitating sophisticated distributed systems that can scale horizontally while maintaining consistency, availability, and performance characteristics. Distributed vector database architecture introduces complex challenges related to data partitioning, load balancing, query routing, and consistency management that require careful design consideration and implementation expertise.
Data partitioning strategies for vector databases must balance several competing objectives including query performance, load distribution, and system maintainability. Range-based partitioning divides vectors based on specific dimensional ranges, which can work effectively when queries exhibit locality patterns but may result in uneven load distribution. Hash-based partitioning provides more uniform distribution but may require querying multiple partitions for similarity searches, increasing latency and system complexity.
Clustering-based partitioning represents a more sophisticated approach that groups similar vectors together, potentially reducing the number of partitions that need to be queried for similarity searches while maintaining relatively balanced load distribution. However, this approach requires periodic rebalancing as data distributions change and may introduce complexity in handling dynamic updates and ensuring consistent performance across different query patterns.
The implementation of distributed consensus and consistency protocols becomes crucial in multi-node vector database deployments, where updates to vector data must be coordinated across multiple nodes while ensuring that queries return consistent and up-to-date results. The choice between strong consistency and eventual consistency models depends on application requirements, with many vector database applications tolerating eventual consistency in exchange for improved performance and availability characteristics.
Enhance your research capabilities with Perplexity to stay current with the latest developments in distributed vector database architectures and emerging scalability solutions that address the challenges of massive-scale AI applications. The continuous evolution of distributed systems techniques provides new opportunities for building more robust and scalable vector database solutions.
Query Optimization and Caching Strategies
Effective query optimization in vector databases requires understanding the unique characteristics of similarity search operations and implementing strategies that minimize computational overhead while maintaining result quality and system responsiveness. Unlike traditional database queries that can leverage standard optimization techniques such as query planning and index selection, vector queries present unique challenges related to the approximate nature of similarity search and the high dimensionality of the data.
Query result caching represents one of the most effective optimization strategies for vector databases, particularly in scenarios with repeated or similar query patterns. Implementing intelligent caching requires consideration of the approximate nature of vector search results and the trade-offs between cache hit rates and result freshness. Semantic caching strategies that cache results for similar queries rather than identical queries can significantly improve cache effectiveness, though they require sophisticated similarity detection mechanisms for query vectors themselves.
Query preprocessing and filtering techniques can dramatically reduce the search space and improve response times by eliminating obviously irrelevant candidates before performing expensive similarity calculations. These techniques might include dimensional reduction, early termination criteria based on partial distance calculations, or hierarchical filtering that progressively narrows the candidate set through multiple stages of increasingly refined similarity assessment.
Batch query optimization becomes particularly important in scenarios where multiple similar queries are submitted simultaneously or in rapid succession. Batching strategies can amortize the cost of index traversal and similarity calculations across multiple queries, while also enabling more efficient utilization of vectorized computing resources and specialized hardware acceleration capabilities.
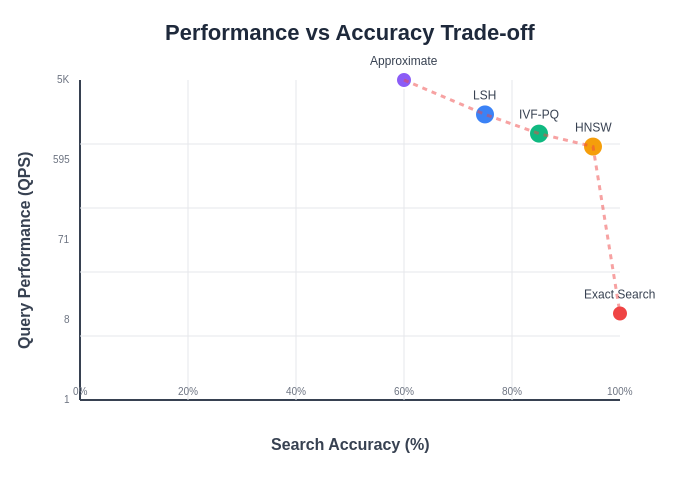
The performance versus accuracy trade-off analysis illustrates the critical decision points in vector database optimization, showing how different algorithmic approaches position themselves along the Pareto frontier of search performance and result quality, enabling informed architectural decisions based on specific application requirements.
Hardware Acceleration and GPU Optimization
The computational intensity of vector operations makes hardware acceleration a critical consideration for high-performance vector database implementations. Modern vector databases can benefit significantly from GPU acceleration, specialized vector processing units, and optimized CPU instruction sets that provide substantial performance improvements for similarity calculations and index operations.
GPU acceleration proves particularly effective for similarity search operations due to the highly parallel nature of vector computations and the ability to perform thousands of distance calculations simultaneously. However, effective GPU utilization requires careful consideration of memory bandwidth limitations, data transfer overhead, and the need for specialized algorithms that can take advantage of GPU architecture characteristics while avoiding common performance pitfalls.
CPU optimization strategies include leveraging SIMD instruction sets such as AVX and ARM NEON that enable parallel processing of multiple vector elements simultaneously, reducing the computational cost of distance calculations and other vector operations. Memory access pattern optimization becomes crucial for CPU-based vector processing, with strategies such as data layout optimization, prefetching, and cache-aware algorithms providing significant performance improvements.
Specialized hardware solutions including neuromorphic processors and dedicated vector processing units represent emerging opportunities for vector database acceleration, though adoption requires careful evaluation of cost-benefit trade-offs and compatibility considerations with existing database infrastructure.
Integration with Machine Learning Workflows
Modern vector databases must integrate seamlessly with machine learning pipelines and workflows, providing efficient mechanisms for embedding updates, model versioning, and real-time inference support that enable dynamic AI applications. This integration encompasses both the initial population of vector databases with embeddings generated from trained models and the ongoing maintenance and updates required as models evolve and data distributions change.
Real-time embedding generation and updates present significant challenges for vector database systems that must balance the need for fresh, accurate embeddings with the computational overhead and latency implications of on-demand embedding generation. Strategies for managing this trade-off include asynchronous update pipelines, embedding caching mechanisms, and hybrid approaches that combine pre-computed embeddings with real-time generation for critical queries.
Model versioning and backward compatibility considerations become crucial in production environments where multiple model versions may coexist and where database schemas must evolve to accommodate new embedding formats and dimensionalities. Effective version management requires careful planning of data migration strategies, index rebuilding processes, and compatibility layers that enable smooth transitions between model versions.
The integration of vector databases with feature stores and ML metadata management systems provides additional opportunities for optimization and consistency management, enabling more sophisticated workflows that can track embedding lineage, manage feature dependencies, and ensure consistency between training and inference data representations.
Security and Privacy Considerations
Vector databases handling sensitive or personal data must implement comprehensive security measures that protect both the raw data and the derived embeddings while maintaining the functionality required for effective similarity search operations. The unique characteristics of vector data present novel security challenges that require specialized approaches beyond traditional database security mechanisms.
Embedding privacy represents a particular challenge since vector representations can potentially leak information about the original data through various attack vectors including inversion attacks, membership inference, and similarity-based information extraction. Differential privacy techniques adapted for vector data can provide mathematical guarantees about privacy protection, though they typically involve trade-offs with query accuracy and system performance.
Access control mechanisms for vector databases must account for the semantic relationships encoded in embeddings and the potential for indirect information disclosure through similarity queries. Fine-grained access control that considers both individual vectors and similarity relationships requires sophisticated policy frameworks and enforcement mechanisms that can operate effectively at the scale and performance requirements of production vector database systems.
Encryption strategies for vector data must balance security requirements with the computational efficiency needed for similarity search operations, leading to the development of specialized techniques such as homomorphic encryption for vector operations and secure multi-party computation protocols that enable privacy-preserving similarity search across distributed datasets.
Performance Monitoring and Optimization
Effective performance monitoring for vector databases requires specialized metrics and analysis techniques that account for the unique characteristics of similarity search operations and the trade-offs between accuracy and efficiency that characterize vector database performance. Traditional database monitoring approaches must be extended to capture vector-specific performance indicators and provide insights into optimization opportunities.
Query performance analysis for vector databases must consider multiple dimensions including search latency, accuracy metrics, resource utilization patterns, and the distribution of query characteristics across different embedding spaces and similarity thresholds. Understanding these performance patterns enables database administrators to identify optimization opportunities and make informed decisions about index tuning, hardware allocation, and system configuration.
Index performance monitoring requires tracking metrics such as index build times, memory utilization, update overhead, and the effectiveness of different indexing strategies for various query patterns and data distributions. These metrics provide insights into when index rebuilding or reconfiguration may be beneficial and help guide capacity planning decisions for growing datasets.
Resource utilization monitoring must account for the intensive computational requirements of vector operations and the potential benefits of hardware acceleration, providing visibility into CPU, memory, and GPU utilization patterns that can inform optimization strategies and infrastructure scaling decisions.
Future Trends and Emerging Technologies
The rapidly evolving landscape of AI and machine learning continues to drive innovation in vector database technology, with emerging trends that promise to further enhance the capabilities and performance characteristics of vector search systems. Understanding these developments enables organizations to make informed decisions about technology adoption and system architecture evolution.
Quantum computing represents a potentially transformative technology for vector databases, offering theoretical advantages for certain types of similarity search operations and optimization problems that are fundamental to vector database performance. While practical quantum computing applications remain limited by current hardware constraints, ongoing research and development may eventually provide significant performance improvements for specific vector database operations.
Neuromorphic computing architectures designed to mimic neural network structures may offer natural advantages for vector processing and similarity search operations, potentially providing more efficient hardware platforms for vector database deployment. These specialized processors could enable new optimization strategies and performance characteristics that are difficult to achieve with conventional computing architectures.
Advanced embedding techniques including multimodal embeddings, dynamic embeddings, and context-aware representations continue to evolve, requiring vector databases to adapt to new data formats, dimensionality requirements, and similarity semantics. These developments may drive architectural changes and optimization strategies that better accommodate the increasing complexity and diversity of embedding approaches.
The integration of vector databases with edge computing platforms and distributed AI systems presents opportunities for new deployment patterns and optimization strategies that bring vector search capabilities closer to data sources and end users, potentially reducing latency and improving privacy characteristics while introducing new challenges related to synchronization and consistency management across distributed environments.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of vector database technologies and their applications in AI systems. Readers should conduct their own research and consider their specific requirements when implementing vector database solutions. The effectiveness of different approaches may vary depending on specific use cases, data characteristics, and performance requirements. Technology recommendations should be evaluated based on current vendor offerings and emerging standards in the rapidly evolving vector database ecosystem.