The convergence of artificial intelligence and DevOps practices has given birth to a revolutionary approach known as AI DevOps, fundamentally transforming how organizations develop, deploy, and maintain machine learning systems at scale. This paradigm shift extends traditional DevOps methodologies to accommodate the unique challenges of AI model lifecycle management, creating sophisticated MLOps pipelines that ensure continuous integration, automated testing, and seamless deployment of machine learning models across diverse production environments.
Stay updated with the latest AI operational trends to understand how leading organizations are implementing cutting-edge MLOps practices that drive competitive advantages through intelligent automation. The evolution from traditional software development practices to AI-centric operational frameworks represents a fundamental shift in how we conceptualize, build, and maintain intelligent systems that can adapt and evolve in real-time.
Understanding AI DevOps and MLOps Fundamentals
AI DevOps represents the natural evolution of traditional DevOps practices, specifically adapted to address the unique challenges inherent in machine learning system development and deployment. Unlike conventional software applications that primarily deal with deterministic code and predictable outputs, AI systems introduce elements of uncertainty, model drift, data dependency, and performance variability that require specialized operational approaches. MLOps, as a subset of AI DevOps, focuses specifically on the operational aspects of machine learning model lifecycle management, encompassing everything from data ingestion and model training to deployment monitoring and automated retraining.
The fundamental principle underlying AI DevOps is the recognition that machine learning systems are inherently more complex than traditional software applications. They depend not only on code but also on data quality, model performance metrics, computational resources, and continuous adaptation to changing input patterns. This complexity necessitates sophisticated pipeline architectures that can handle the iterative nature of model development, the need for extensive experimentation, and the requirement for robust monitoring and maintenance of deployed models in production environments.
The integration of AI DevOps practices enables organizations to achieve unprecedented levels of automation in their machine learning workflows, reducing the time from model conception to production deployment while maintaining high standards of reliability, security, and performance. This operational excellence is achieved through the implementation of comprehensive pipeline architectures that automate every aspect of the machine learning lifecycle, from initial data preprocessing through final model serving and ongoing performance optimization.
Designing Robust MLOps Pipeline Architectures
The foundation of effective AI DevOps lies in the design and implementation of robust MLOps pipeline architectures that can handle the full spectrum of machine learning operational requirements. These pipelines must accommodate multiple stages of the machine learning lifecycle, including data collection and preprocessing, feature engineering, model training and validation, hyperparameter optimization, model evaluation, deployment, monitoring, and automated retraining. Each stage requires careful orchestration and coordination to ensure seamless data flow and consistent model performance across different environments.
Modern MLOps pipelines are designed with modularity and scalability in mind, allowing organizations to adapt their operational frameworks to accommodate different types of machine learning projects, from simple classification models to complex deep learning architectures and ensemble methods. The pipeline architecture typically incorporates multiple parallel processing streams that can handle different aspects of model development simultaneously, enabling faster iteration cycles and more efficient resource utilization.
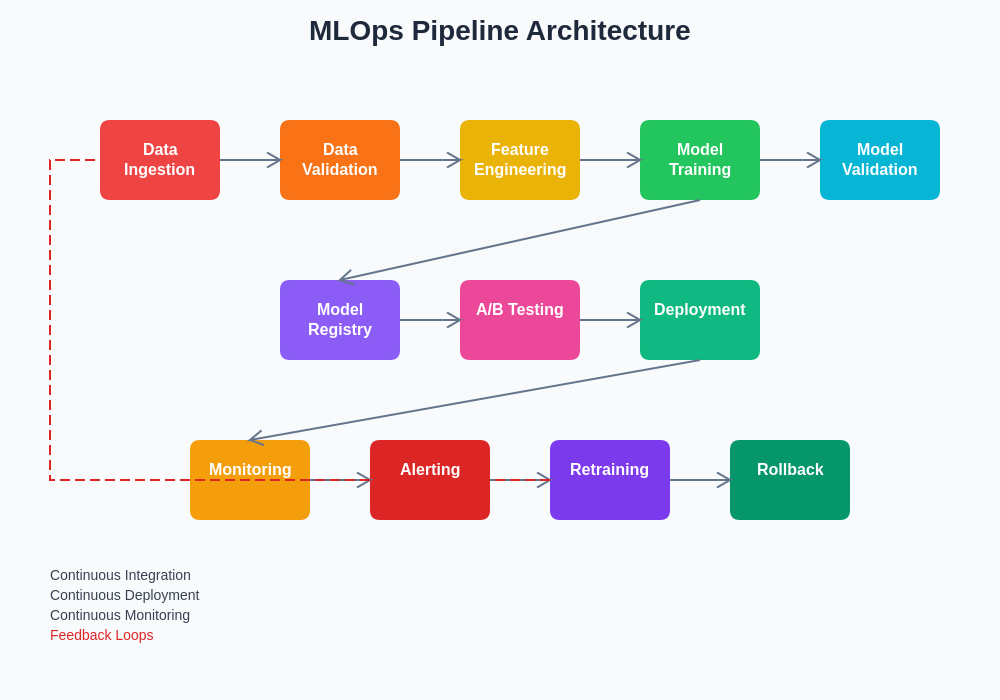
This comprehensive MLOps architecture demonstrates the interconnected nature of modern machine learning operations, showcasing how data flows through various stages of validation, processing, training, and deployment while maintaining continuous feedback loops for optimization and retraining. The architecture emphasizes the critical importance of monitoring and automated response mechanisms that ensure model performance remains optimal throughout the production lifecycle.
Experience advanced AI capabilities with Claude to understand how intelligent systems can be integrated into MLOps workflows for enhanced decision-making and automated optimization. The sophistication of modern MLOps architectures allows for dynamic resource allocation, automatic scaling based on computational demands, and intelligent routing of different model versions through appropriate testing and validation procedures before reaching production environments.
Implementing Continuous Integration for Machine Learning
Continuous integration in the context of machine learning extends far beyond traditional code integration practices to encompass data validation, model performance verification, and comprehensive testing of the entire machine learning pipeline. This expanded scope requires specialized CI/CD tools and practices that can handle the unique challenges of machine learning development, including data versioning, model artifact management, and performance regression detection across different datasets and computational environments.
The implementation of continuous integration for machine learning involves creating automated workflows that trigger whenever changes are made to any component of the machine learning system, including code modifications, data updates, or configuration changes. These workflows must validate not only code quality but also data integrity, model performance metrics, and compatibility across different deployment targets. The CI pipeline typically includes stages for automated testing of data preprocessing functions, model training procedures, validation against benchmark datasets, and comprehensive performance analysis.
Advanced continuous integration practices for machine learning also incorporate automated model comparison and selection processes that can evaluate multiple model versions simultaneously and select the best-performing variant based on predefined criteria. This automated selection process considers various factors including accuracy metrics, computational efficiency, resource requirements, and compatibility with existing production infrastructure, ensuring that only the most suitable models progress through the deployment pipeline.
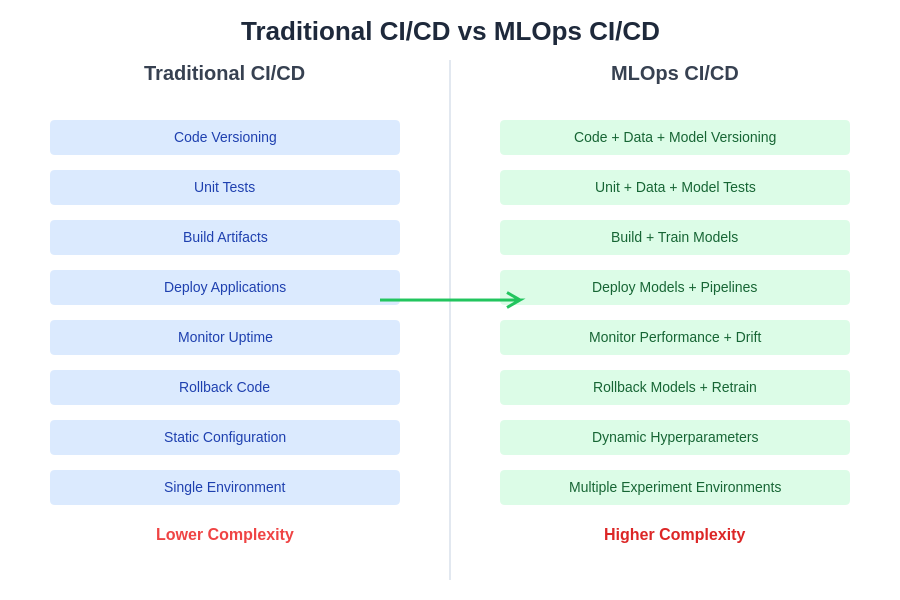
The evolution from traditional continuous integration and deployment practices to MLOps-specific approaches represents a significant increase in complexity and capability. While traditional CI/CD focuses primarily on code versioning and application deployment, MLOps CI/CD must handle the additional complexities of data versioning, model training, performance monitoring, and dynamic retraining workflows that are essential for maintaining effective machine learning systems in production environments.
Automating Model Training and Validation Processes
The automation of model training and validation processes represents one of the most critical aspects of AI DevOps, enabling organizations to maintain consistent model quality while reducing manual intervention and accelerating development cycles. Automated training pipelines incorporate sophisticated orchestration mechanisms that can handle complex training workflows, including distributed training across multiple computational nodes, hyperparameter optimization using advanced search algorithms, and comprehensive validation against multiple evaluation metrics and datasets.
Modern automated training systems incorporate intelligent resource management capabilities that can dynamically allocate computational resources based on training requirements, automatically scaling infrastructure to accommodate varying workloads and optimizing cost efficiency through intelligent scheduling and resource sharing. These systems also implement comprehensive logging and monitoring functionality that tracks training progress, identifies potential issues early in the training process, and provides detailed analytics on model performance and resource utilization patterns.
The validation automation extends beyond simple accuracy measurements to include comprehensive testing of model robustness, fairness, explainability, and performance consistency across different data distributions and operational conditions. Automated validation pipelines incorporate advanced testing methodologies including adversarial testing, distribution shift analysis, and comprehensive bias detection to ensure that deployed models maintain high standards of reliability and ethical operation across diverse real-world scenarios.
Implementing Sophisticated Deployment Strategies
Deployment strategies in AI DevOps require careful consideration of model versioning, rollback capabilities, traffic management, and performance monitoring to ensure smooth transitions between different model versions while maintaining service availability and quality. Modern deployment approaches incorporate techniques such as blue-green deployment, canary releases, and A/B testing specifically adapted for machine learning contexts, allowing organizations to minimize risks associated with model updates while gathering comprehensive performance data on new model versions.
The implementation of sophisticated deployment strategies involves creating infrastructure that can simultaneously support multiple model versions, enabling gradual traffic shifting and comprehensive comparison of model performance under real-world conditions. This infrastructure typically includes load balancing mechanisms, feature flag systems, and automated rollback capabilities that can quickly revert to previous model versions if performance degradation or other issues are detected in production environments.
Enhance your research capabilities with Perplexity to stay informed about the latest deployment strategies and best practices in MLOps implementation. Advanced deployment strategies also incorporate intelligent traffic routing that can direct different types of requests to appropriate model versions based on request characteristics, user segments, or other contextual factors, enabling sophisticated experimentation and optimization of model performance across diverse use cases.
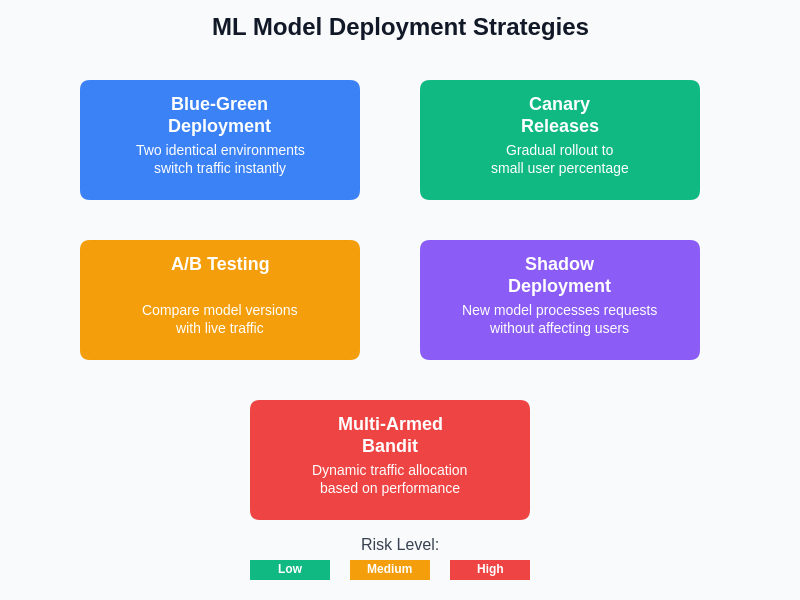
The selection of appropriate deployment strategies depends on various factors including risk tolerance, business requirements, and technical constraints. Each strategy offers different trade-offs between deployment speed, risk mitigation, and operational complexity, requiring careful consideration of organizational capabilities and specific use case requirements when implementing production machine learning systems.
Monitoring and Observability in AI Systems
Comprehensive monitoring and observability represent fundamental requirements for successful AI DevOps implementation, providing the visibility necessary to detect model drift, performance degradation, and operational issues before they impact end-user experience. AI system monitoring extends beyond traditional application monitoring to include specialized metrics related to model performance, data quality, prediction accuracy, and business impact, requiring sophisticated monitoring architectures that can handle the unique characteristics of machine learning workloads.
Modern AI monitoring systems incorporate real-time alerting mechanisms that can detect various types of anomalies including data distribution shifts, model performance degradation, infrastructure issues, and unusual prediction patterns. These systems utilize advanced statistical analysis and machine learning techniques to establish baseline performance characteristics and identify deviations that may indicate potential problems, enabling proactive intervention before issues escalate into service disruptions.
The observability framework for AI systems typically includes comprehensive dashboards that provide visibility into all aspects of model performance and operational status, including training metrics, deployment status, prediction quality, resource utilization, and business impact measurements. These dashboards enable stakeholders across different organizational functions to monitor AI system health and make informed decisions about model updates, infrastructure scaling, and operational optimizations.
Data Pipeline Management and Quality Assurance
Effective data pipeline management forms the backbone of successful AI DevOps implementations, ensuring that high-quality, consistent data flows through the entire machine learning lifecycle while maintaining strict governance and compliance standards. Data pipeline architectures must accommodate diverse data sources, handle varying data volumes and velocities, and implement comprehensive quality assurance mechanisms that can detect and address data quality issues before they impact model training or inference processes.
Modern data pipeline management systems incorporate automated data validation, cleansing, and transformation capabilities that can handle complex data processing requirements while maintaining data lineage and provenance information. These systems implement sophisticated monitoring and alerting mechanisms that can detect data quality issues, schema changes, and pipeline failures, enabling rapid response to data-related problems that could impact downstream machine learning processes.
The quality assurance framework for data pipelines includes comprehensive testing of data transformation logic, validation of data integrity across different processing stages, and automated detection of data anomalies that could indicate upstream system issues or data quality problems. This framework ensures that only high-quality, validated data reaches model training and inference processes, maintaining the reliability and accuracy of machine learning systems throughout their operational lifecycle.
Infrastructure Automation and Resource Management
Infrastructure automation in AI DevOps contexts requires sophisticated orchestration capabilities that can handle the dynamic resource requirements of machine learning workloads while optimizing cost efficiency and maintaining high availability standards. Modern infrastructure automation frameworks incorporate intelligent resource provisioning that can automatically scale computational resources based on workload demands, optimize resource allocation across different types of machine learning tasks, and implement cost-effective scheduling strategies that maximize resource utilization.
The automation of infrastructure management includes comprehensive configuration management systems that can maintain consistency across different deployment environments, automate the provisioning of specialized hardware resources such as GPUs and TPUs, and implement robust backup and disaster recovery procedures specifically designed for machine learning workloads. These systems ensure that machine learning applications can operate reliably across diverse infrastructure environments while maintaining optimal performance characteristics.
Advanced infrastructure automation also incorporates intelligent workload scheduling that can optimize the allocation of computational resources based on job priorities, resource requirements, and cost constraints. This scheduling capability enables organizations to maximize the efficiency of their machine learning infrastructure while maintaining service level agreements and controlling operational costs through intelligent resource management and optimization strategies.
Security and Compliance in AI Operations
Security and compliance considerations in AI DevOps require specialized approaches that address the unique risks associated with machine learning systems, including model stealing, adversarial attacks, data privacy concerns, and regulatory compliance requirements. Comprehensive security frameworks for AI systems incorporate multiple layers of protection including secure model serving, encrypted data transmission, access control mechanisms, and comprehensive audit logging that tracks all interactions with machine learning models and associated data.
The implementation of compliance frameworks for AI systems involves establishing comprehensive governance processes that ensure adherence to relevant regulations such as GDPR, HIPAA, and industry-specific compliance requirements. These frameworks incorporate automated compliance checking, comprehensive documentation generation, and audit trail maintenance that provides complete visibility into model decision-making processes and data handling procedures.
Advanced security measures for AI systems also include specialized techniques for protecting model intellectual property, detecting and mitigating adversarial attacks, and implementing robust privacy-preserving mechanisms that enable machine learning on sensitive data while maintaining strict privacy protection standards. These security measures are integrated throughout the MLOps pipeline to ensure comprehensive protection of AI assets and sensitive information.
Performance Optimization and Cost Management
Performance optimization in AI DevOps encompasses multiple dimensions including computational efficiency, inference latency, throughput optimization, and resource utilization, requiring sophisticated optimization strategies that can balance performance requirements with cost constraints. Modern optimization approaches incorporate advanced techniques such as model quantization, pruning, distillation, and specialized hardware utilization to achieve optimal performance characteristics while maintaining acceptable accuracy levels.
Cost management strategies for AI operations involve comprehensive monitoring and optimization of resource utilization across the entire machine learning lifecycle, including training costs, inference serving costs, data storage expenses, and infrastructure overhead. These strategies incorporate intelligent resource scheduling, automated scaling policies, and cost-aware optimization algorithms that can minimize operational expenses while maintaining required service levels and performance standards.
Advanced performance optimization techniques also include sophisticated caching strategies, load balancing mechanisms, and predictive scaling that can anticipate resource requirements based on historical usage patterns and business forecasts. These optimization strategies enable organizations to achieve maximum performance efficiency while controlling operational costs and maintaining high service availability standards.
Integration with Existing Enterprise Systems
The successful implementation of AI DevOps requires seamless integration with existing enterprise systems including traditional DevOps tools, business applications, data warehouses, and enterprise resource planning systems. This integration involves creating comprehensive API frameworks, implementing robust data exchange mechanisms, and establishing consistent authentication and authorization systems that enable secure and efficient communication between AI systems and enterprise infrastructure.
Modern integration approaches incorporate sophisticated orchestration capabilities that can coordinate complex workflows spanning multiple enterprise systems, enabling automated processes that combine machine learning capabilities with traditional business logic and operational procedures. These integration frameworks ensure that AI systems can operate effectively within existing enterprise environments while maintaining consistency with established operational practices and security standards.
The integration framework also includes comprehensive monitoring and management capabilities that provide unified visibility into AI system performance and its impact on broader enterprise operations. This unified monitoring enables organizations to understand the full business impact of their AI investments while maintaining operational efficiency and service quality across all integrated systems.
Future Trends and Evolution in AI DevOps
The future evolution of AI DevOps is being shaped by emerging technologies including federated learning, edge computing, quantum machine learning, and advanced automated machine learning capabilities that promise to further transform how organizations develop and deploy intelligent systems. These emerging technologies are driving the development of new operational frameworks that can handle distributed learning scenarios, edge deployment requirements, and increasingly sophisticated automation capabilities.
Future AI DevOps platforms are expected to incorporate advanced artificial intelligence capabilities for self-optimizing pipelines, predictive maintenance of machine learning systems, and automated problem resolution that can handle complex operational issues without human intervention. These self-managing systems will enable organizations to achieve unprecedented levels of operational efficiency while reducing the complexity and overhead associated with managing sophisticated AI infrastructure.
The continued evolution of AI DevOps will also be influenced by growing regulatory requirements, sustainability considerations, and the need for greater transparency and explainability in AI system operations. These factors are driving the development of more sophisticated governance frameworks, environmental impact optimization strategies, and comprehensive explainability tools that will become integral components of future AI operational platforms.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of AI DevOps and MLOps technologies and their applications in enterprise environments. Readers should conduct their own research and consider their specific requirements when implementing AI DevOps and MLOps practices. The effectiveness and suitability of different approaches may vary depending on specific use cases, organizational requirements, and technological constraints.