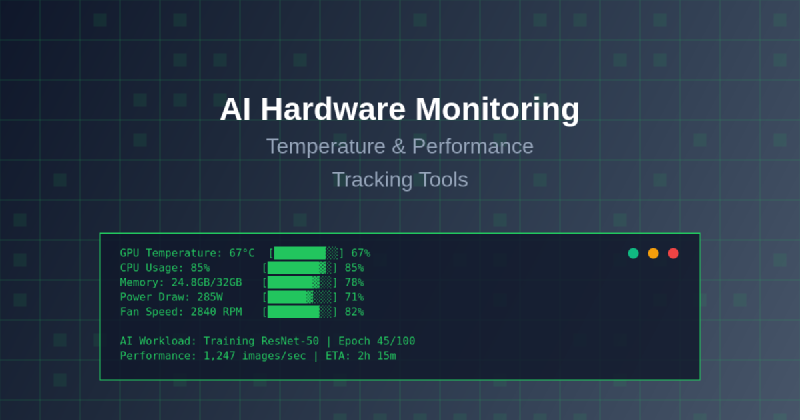
The exponential growth of artificial intelligence and machine learning workloads has placed unprecedented demands on computing hardware, making effective monitoring and performance tracking essential for maintaining optimal system operation. Modern AI applications, particularly deep learning models and large language models, generate substantial computational loads that push hardware components to their limits, creating critical needs for comprehensive temperature management and performance optimization strategies.
Discover the latest AI hardware trends and monitoring solutions to stay informed about cutting-edge technologies that are revolutionizing how we approach system monitoring and optimization. The complexity of contemporary AI workloads requires sophisticated monitoring approaches that go beyond traditional system metrics to provide detailed insights into hardware behavior under extreme computational stress.
The Critical Importance of AI Hardware Monitoring
Artificial intelligence workloads present unique challenges for system monitoring due to their intensive computational requirements and prolonged execution times. Unlike traditional computing tasks that may utilize system resources intermittently, AI training and inference operations often sustain maximum hardware utilization for hours or days, creating sustained thermal stress and power consumption patterns that can quickly lead to system instability or hardware degradation without proper monitoring and management.
The financial implications of hardware failure in AI environments are particularly severe, given the high cost of specialized hardware such as graphics processing units, tensor processing units, and high-performance memory systems. A single GPU failure during a multi-day training run can result in significant financial losses and project delays, making proactive monitoring and preventive maintenance strategies essential for cost-effective AI operations. Furthermore, the competitive landscape of AI development demands maximum efficiency from available hardware resources, requiring precise performance optimization that can only be achieved through comprehensive monitoring and analysis.
GPU Temperature Management and Thermal Monitoring
Graphics processing units represent the most critical components in AI hardware monitoring due to their central role in machine learning computations and their susceptibility to thermal-related performance degradation. Modern GPUs can generate substantial heat output under sustained AI workloads, with temperatures often approaching or exceeding safe operating thresholds without adequate cooling and monitoring systems. Effective GPU temperature management requires real-time monitoring of multiple thermal sensors, dynamic fan curve adjustment, and automated throttling mechanisms that prevent thermal damage while maintaining optimal performance levels.
The complexity of GPU thermal management in AI environments extends beyond simple temperature monitoring to include consideration of memory junction temperatures, power delivery system thermal characteristics, and the thermal interaction between multiple GPUs in multi-card configurations. Advanced monitoring tools provide granular visibility into these thermal dynamics, enabling system administrators to implement precise cooling strategies that maximize performance while ensuring long-term hardware reliability. The integration of machine learning algorithms into monitoring systems themselves has enabled predictive thermal management that can anticipate temperature spikes and proactively adjust cooling parameters before critical thresholds are reached.
Experience advanced AI monitoring capabilities with Claude for intelligent system analysis and optimization recommendations based on comprehensive hardware performance data. The sophistication of modern monitoring solutions enables unprecedented visibility into system behavior patterns that can inform both immediate operational decisions and long-term infrastructure planning strategies.
CPU Performance Tracking in AI Workloads
While graphics processing units often receive primary attention in AI hardware discussions, central processing units continue to play crucial roles in machine learning pipelines, particularly in data preprocessing, model serving, and distributed training coordination tasks. CPU performance monitoring in AI environments requires specialized attention to multi-core utilization patterns, memory bandwidth consumption, and thermal management across sustained high-utilization periods that differ significantly from traditional server workloads.
The evolution of CPU architectures toward higher core counts and specialized AI acceleration features has created new monitoring requirements that traditional system monitoring tools may not adequately address. Modern AI-optimized CPUs include dedicated tensor processing units, specialized instruction sets for machine learning operations, and complex cache hierarchies that require sophisticated monitoring approaches to fully understand and optimize performance characteristics. Advanced monitoring solutions provide detailed visibility into these specialized features, enabling administrators to fine-tune system configurations for optimal AI workload performance.
Memory System Monitoring and Optimization
Memory systems in AI environments face unique challenges related to the massive datasets and model parameters characteristic of modern machine learning applications. High-bandwidth memory, graphics memory, and system memory all play critical roles in AI performance, requiring comprehensive monitoring that tracks not only utilization levels but also bandwidth consumption, error rates, and thermal characteristics that can impact system stability and performance.
The complexity of memory hierarchy management in AI systems extends from high-speed GPU memory through system RAM to storage subsystems, each with distinct monitoring requirements and optimization opportunities. Modern monitoring tools provide integrated visibility across these memory tiers, enabling administrators to identify bottlenecks, optimize data movement patterns, and prevent memory-related performance degradation that can significantly impact AI workload execution times and system efficiency.
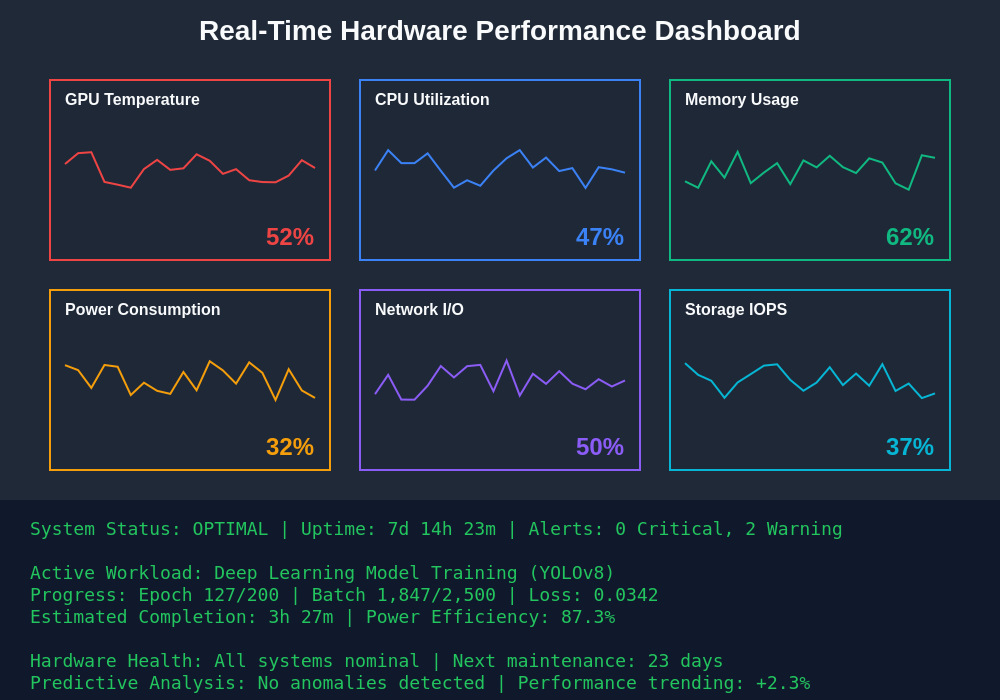
Contemporary monitoring dashboards provide comprehensive real-time visibility into all critical hardware metrics, enabling administrators to quickly identify performance bottlenecks, thermal issues, and optimization opportunities across complex AI infrastructure deployments. Advanced dashboard interfaces integrate multiple monitoring domains into unified views that facilitate rapid decision-making and proactive system management.
Power Consumption Analysis and Efficiency Optimization
Power consumption monitoring has become increasingly critical in AI environments due to the substantial energy requirements of modern machine learning workloads and the associated operational costs. Comprehensive power monitoring extends beyond simple wattage measurements to include power quality analysis, efficiency optimization, and predictive modeling that can inform both immediate operational decisions and long-term infrastructure planning strategies.
The relationship between power consumption, performance, and thermal characteristics in AI systems creates complex optimization challenges that require sophisticated monitoring and analysis capabilities. Advanced monitoring solutions provide detailed visibility into power consumption patterns across different workload types, enabling administrators to implement dynamic power management strategies that maximize performance per watt while maintaining system stability and reliability.
Network Performance Monitoring for Distributed AI Systems
Modern AI applications increasingly rely on distributed computing architectures that span multiple systems, data centers, and cloud regions, creating critical requirements for comprehensive network performance monitoring. The communication patterns characteristic of distributed AI training, particularly in large-scale model training scenarios, generate unique network load patterns that require specialized monitoring approaches to ensure optimal performance and identify potential bottlenecks.
Network monitoring in AI environments must address both high-bandwidth data transfer requirements and low-latency communication needs that are essential for effective distributed training coordination. Advanced monitoring tools provide detailed visibility into network utilization patterns, latency characteristics, and error rates that can significantly impact distributed AI workload performance, enabling administrators to optimize network configurations and identify infrastructure improvements that can enhance overall system efficiency.
Storage System Performance and I/O Monitoring
Storage systems in AI environments face unprecedented challenges related to the massive dataset sizes and high-throughput requirements characteristic of modern machine learning applications. Effective storage monitoring must address both sequential and random I/O patterns, queue depth management, and thermal characteristics of high-performance storage devices that are essential for maintaining optimal AI workload performance.
The evolution toward NVMe solid-state drives, storage area networks, and distributed storage systems has created new monitoring requirements that traditional storage monitoring tools may not adequately address. Modern AI-optimized storage monitoring solutions provide comprehensive visibility into performance characteristics, wear leveling status, and predictive failure analysis that can prevent data loss and minimize system downtime in critical AI production environments.
Enhance your research and monitoring capabilities with Perplexity for comprehensive analysis of hardware performance trends and optimization strategies across diverse AI deployment scenarios. The integration of multiple monitoring and analysis tools creates a comprehensive ecosystem that supports both real-time operational decision-making and strategic infrastructure planning.
Real-Time Alerting and Automated Response Systems
The critical nature of AI workloads and the potential for rapid hardware degradation under extreme computational loads necessitate sophisticated alerting and automated response systems that can detect and respond to performance issues faster than human operators. Advanced monitoring solutions incorporate machine learning algorithms that can identify anomalous behavior patterns, predict potential failures, and automatically implement corrective actions to maintain system stability and performance.
The complexity of modern AI infrastructure requires alerting systems that can correlate information across multiple monitoring domains, distinguishing between normal operational variations and genuine performance issues that require intervention. Intelligent alerting systems reduce false positive rates while ensuring that critical issues receive immediate attention, enabling efficient resource utilization and minimizing the risk of system failures that could impact important AI workloads.
Integration with Container Orchestration and Cloud Platforms
The widespread adoption of containerized AI workloads and cloud-native deployment architectures has created new requirements for monitoring integration that spans traditional hardware metrics and modern orchestration platforms. Effective monitoring solutions must provide visibility into both physical hardware performance and the virtualization layers that abstract hardware resources for containerized applications.
Cloud platform integration enables monitoring solutions to leverage cloud-native scaling capabilities, automatically adjusting monitoring granularity and retention periods based on workload characteristics and cost optimization objectives. Advanced monitoring platforms provide seamless integration with popular container orchestration systems, enabling unified visibility across physical hardware, virtualization layers, and application performance metrics that are essential for comprehensive AI infrastructure management.
Predictive Analytics and Failure Prevention
The integration of machine learning techniques into monitoring systems themselves has enabled sophisticated predictive analytics capabilities that can identify potential hardware failures before they occur, enabling proactive maintenance strategies that minimize system downtime and prevent data loss. Predictive monitoring analyzes historical performance patterns, environmental conditions, and hardware characteristics to generate failure probability models that inform maintenance scheduling and component replacement decisions.
The financial benefits of predictive maintenance in AI environments are particularly substantial due to the high cost of specialized hardware and the potential impact of unexpected failures on critical workloads. Advanced monitoring solutions provide detailed failure prediction analytics, maintenance scheduling recommendations, and component health scoring that enable administrators to optimize maintenance strategies while minimizing both planned and unplanned downtime.
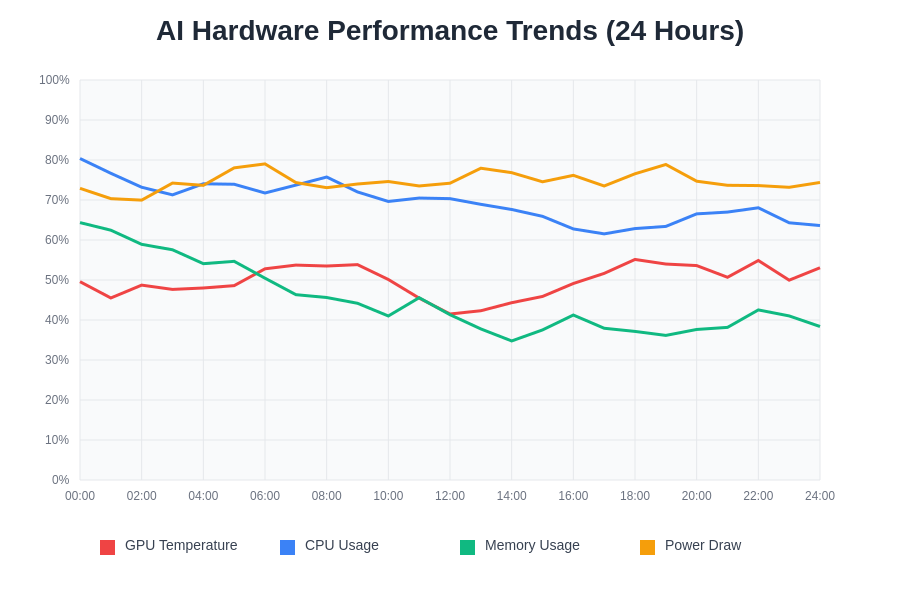
Trend analysis capabilities enable administrators to identify long-term performance patterns, capacity planning requirements, and optimization opportunities that may not be apparent through real-time monitoring alone. Historical data analysis reveals seasonal patterns, workload-specific performance characteristics, and gradual degradation trends that inform both immediate optimization strategies and long-term infrastructure investment planning.
Security Monitoring and Hardware-Level Threat Detection
The increasing sophistication of cyber security threats and the high value of AI intellectual property have created new requirements for security-focused hardware monitoring that can detect anomalous behavior patterns potentially indicative of security breaches or unauthorized system access. Advanced monitoring solutions incorporate security analytics that analyze hardware utilization patterns, network communications, and system behavior to identify potential security threats.
Hardware-level security monitoring provides visibility into low-level system behavior that may indicate firmware-level attacks, unauthorized hardware modifications, or sophisticated malware that operates below traditional software-based security detection systems. The integration of security monitoring with performance monitoring creates comprehensive visibility that supports both operational efficiency and security objectives essential for protecting valuable AI assets and intellectual property.
Cost Optimization and Resource Utilization Analysis
The substantial operational costs associated with AI infrastructure create critical requirements for comprehensive cost optimization analysis that combines hardware performance data with financial metrics to identify efficiency improvements and resource optimization opportunities. Advanced monitoring solutions provide detailed cost per workload analysis, resource utilization optimization recommendations, and capacity planning guidance that enables organizations to maximize the return on investment from expensive AI hardware.
Resource utilization analysis extends beyond simple usage metrics to include efficiency scoring, workload scheduling optimization, and multi-tenant resource sharing strategies that can significantly reduce operational costs while maintaining performance standards. The integration of financial analytics with technical monitoring data enables informed decision-making about infrastructure investments, scaling strategies, and workload optimization approaches that balance performance requirements with cost constraints.
Future Trends in AI Hardware Monitoring
The evolution of AI hardware architectures toward increasingly specialized processing units, quantum computing integration, and neuromorphic computing systems will create new monitoring requirements that extend beyond traditional performance metrics to include quantum coherence monitoring, neural network hardware optimization, and hybrid computing resource management. Advanced monitoring solutions are evolving to address these emerging requirements while maintaining compatibility with existing infrastructure investments.
The integration of artificial intelligence into monitoring systems themselves represents a significant trend that will enable autonomous optimization, predictive scaling, and intelligent resource management that can adapt to changing workload characteristics without human intervention. The future of AI hardware monitoring lies in the development of self-managing systems that combine comprehensive visibility with intelligent automation to maximize performance while minimizing operational complexity and costs.
The continued advancement of monitoring technologies promises to unlock new levels of efficiency and reliability in AI infrastructure management while enabling the development of increasingly sophisticated AI applications that push the boundaries of computational capability. The symbiotic relationship between AI development and monitoring technology advancement will continue to drive innovation in both domains, creating opportunities for breakthrough improvements in system performance and operational efficiency.
Disclaimer
This article is for informational purposes only and does not constitute professional advice regarding hardware monitoring or system optimization. The information provided is based on current understanding of AI hardware monitoring technologies and best practices. Readers should conduct their own research and consider their specific requirements when implementing monitoring solutions. Hardware monitoring effectiveness may vary depending on specific system configurations, workload characteristics, and operational environments. Always consult with qualified professionals before making significant changes to critical infrastructure systems.