
The deployment of artificial intelligence models in production environments demands exceptional performance optimization to meet real-world latency and throughput requirements. As machine learning applications increasingly become mission-critical components of modern software systems, the choice of inference optimization framework becomes paramount to achieving optimal performance across diverse hardware configurations. Three leading frameworks have emerged as industry standards for AI inference optimization, each bringing unique strengths and specialized capabilities to the complex challenge of maximizing deep learning model performance in production environments.
Stay updated with the latest AI optimization trends as new techniques and frameworks continue to evolve the landscape of high-performance machine learning inference. The selection between TensorRT, OpenVINO, and ONNX Runtime represents more than a technical decision; it fundamentally shapes the performance characteristics, deployment flexibility, and long-term scalability of AI-powered applications across industries ranging from autonomous vehicles to real-time recommendation systems.
Understanding AI Inference Optimization Fundamentals
AI inference optimization represents the critical bridge between research-phase model development and production-ready deployment, encompassing a comprehensive suite of techniques designed to maximize computational efficiency while preserving model accuracy. The fundamental challenge lies in transforming models that were typically trained with abundant computational resources into highly optimized versions capable of delivering consistent performance under strict latency and resource constraints. This optimization process involves sophisticated techniques including quantization, pruning, kernel fusion, memory optimization, and hardware-specific acceleration that collectively transform theoretical model capabilities into practical, deployable solutions.
The complexity of modern deep learning architectures, combined with the diverse hardware landscape spanning CPUs, GPUs, specialized AI accelerators, and edge devices, creates a multifaceted optimization challenge that requires specialized frameworks capable of navigating these technical complexities. Each optimization framework approaches this challenge through distinct philosophical and technical strategies, resulting in performance characteristics that vary significantly depending on the specific use case, hardware configuration, and deployment requirements.
TensorRT: NVIDIA’s GPU-Centric Powerhouse
TensorRT stands as NVIDIA’s flagship inference optimization platform, specifically engineered to extract maximum performance from NVIDIA GPU architectures through deep integration with CUDA and advanced GPU-specific optimization techniques. The framework’s strength lies in its sophisticated understanding of GPU memory hierarchies, compute capabilities, and architectural characteristics, enabling it to perform aggressive optimizations that would be impossible with more generalized approaches.
The platform excels in scenarios requiring extreme performance on NVIDIA hardware, particularly in applications such as autonomous driving, real-time computer vision, and high-throughput inference serving where millisecond-level latency improvements translate directly to business value. TensorRT’s optimization pipeline includes advanced techniques such as layer fusion, precision calibration, dynamic tensor memory allocation, and kernel auto-tuning that collectively deliver performance improvements often exceeding 5-10x over unoptimized implementations.
The framework’s precision optimization capabilities deserve particular attention, as TensorRT can automatically convert models from FP32 to FP16 or INT8 precision while maintaining accuracy through sophisticated calibration processes. This precision reduction dramatically improves both inference speed and memory efficiency, making it possible to deploy larger models or achieve higher batch throughput on the same hardware configuration.
Explore advanced AI development with Claude for comprehensive assistance in implementing and optimizing inference pipelines across different frameworks and hardware configurations. The integration of AI-assisted development workflows significantly accelerates the optimization process while ensuring best practices are consistently applied across diverse deployment scenarios.
OpenVINO: Intel’s Cross-Platform Optimization Suite
OpenVINO represents Intel’s comprehensive approach to AI inference optimization, designed with a philosophy of hardware agnosticism and broad ecosystem support that extends far beyond Intel’s own silicon offerings. The framework’s architectural foundation emphasizes flexibility and portability, making it an excellent choice for organizations deploying across heterogeneous hardware environments or seeking to avoid vendor lock-in while maintaining optimization capabilities.
The platform’s strength lies in its sophisticated intermediate representation and comprehensive optimization pipeline that can effectively target CPUs, integrated graphics, VPUs, and various AI accelerators through a unified development experience. OpenVINO’s CPU optimizations are particularly noteworthy, leveraging advanced vectorization, threading strategies, and memory access patterns to extract impressive performance from commodity server and edge hardware configurations.
The framework’s model zoo and pre-trained optimization profiles provide significant value for common use cases, allowing developers to leverage Intel’s extensive optimization expertise without requiring deep knowledge of low-level performance tuning techniques. This democratization of optimization expertise makes OpenVINO particularly attractive for teams seeking to achieve production-ready performance without extensive specialization in hardware-specific optimization techniques.
OpenVINO’s support for dynamic batching and asynchronous execution patterns makes it well-suited for server-side deployment scenarios where request patterns may vary significantly over time. The framework can automatically adjust resource allocation and processing strategies based on real-time workload characteristics, ensuring optimal resource utilization across diverse operational conditions.
ONNX Runtime: Microsoft’s Universal Inference Engine
ONNX Runtime emerges as Microsoft’s contribution to the inference optimization landscape, built around the Open Neural Network Exchange standard to provide maximum model portability and framework interoperability. The platform’s core strength lies in its ability to seamlessly work with models trained in virtually any major machine learning framework while providing consistent optimization capabilities across diverse deployment environments.
The framework’s architectural design prioritizes flexibility and extensibility, making it an ideal choice for organizations working with diverse model types, training frameworks, or deployment requirements. ONNX Runtime’s provider-based architecture allows it to leverage hardware-specific optimizations through specialized execution providers while maintaining a consistent high-level interface that simplifies deployment and maintenance workflows.
The platform’s optimization capabilities encompass both graph-level and runtime optimizations, including operator fusion, constant folding, redundant computation elimination, and memory allocation optimization. These techniques work together to improve both inference speed and memory efficiency across a wide range of model architectures and hardware configurations.
ONNX Runtime’s support for quantization and mixed precision computation provides significant performance benefits while maintaining the flexibility to fine-tune precision trade-offs based on specific accuracy requirements. The framework’s quantization toolkit includes both post-training and quantization-aware training approaches, giving developers multiple pathways to achieve optimal performance characteristics.
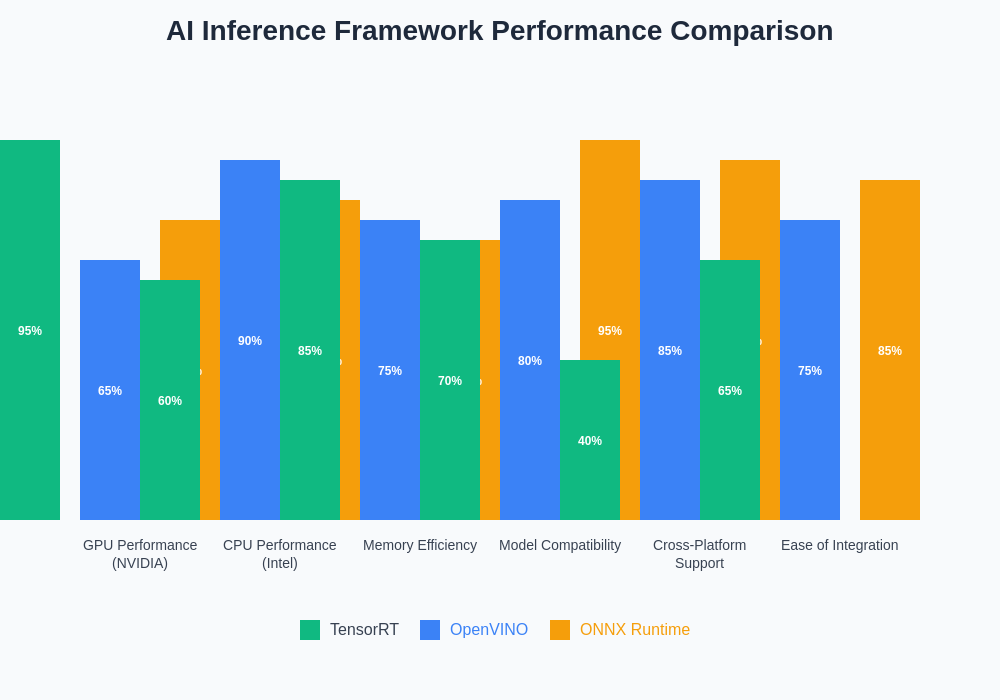
The performance characteristics of different inference optimization frameworks vary significantly based on hardware configuration, model architecture, and deployment requirements, making framework selection a critical decision that impacts both immediate performance and long-term scalability considerations.
Hardware Compatibility and Ecosystem Integration
The hardware compatibility matrix for each inference optimization framework reveals important strategic considerations that extend beyond raw performance metrics. TensorRT’s deep integration with NVIDIA’s hardware stack provides unparalleled performance on supported platforms but creates dependency constraints that may limit deployment flexibility in heterogeneous environments.
OpenVINO’s broad hardware support encompasses Intel CPUs, integrated graphics, Movidius VPUs, and various third-party accelerators, making it an excellent choice for deployment scenarios requiring hardware flexibility or cost optimization through commodity hardware utilization. The framework’s CPU optimization capabilities are particularly strong, often delivering performance that rivals specialized hardware solutions for many common inference workloads.
ONNX Runtime’s provider-based architecture offers the most comprehensive hardware support, with execution providers available for CPUs, NVIDIA GPUs, AMD GPUs, Intel hardware, ARM processors, and various specialized AI accelerators. This broad compatibility makes ONNX Runtime particularly attractive for organizations seeking to maintain deployment flexibility while leveraging hardware-specific optimizations where available.
Enhance your AI research capabilities with Perplexity for comprehensive information gathering and analysis of the latest developments in inference optimization techniques and hardware acceleration technologies. The rapidly evolving landscape of AI hardware requires continuous monitoring of technological developments to maintain competitive advantages in performance optimization.
Model Format Support and Conversion Workflows
The supported model formats and conversion workflows represent critical practical considerations that significantly impact development and deployment efficiency. TensorRT primarily works with TensorFlow, PyTorch, and ONNX models through its comprehensive parsing capabilities, but achieving optimal performance often requires careful attention to model structure and operator support during the conversion process.
OpenVINO’s model optimizer supports an extensive range of input formats including TensorFlow, PyTorch, ONNX, Caffe, and MXNet, providing a unified conversion pathway that standardizes models into the framework’s intermediate representation. This comprehensive format support simplifies deployment workflows while ensuring that optimization benefits are accessible regardless of the original training framework.
ONNX Runtime’s native ONNX format support provides the most straightforward deployment pathway for models already in ONNX format, while comprehensive conversion tools enable integration with models from virtually any training framework. The standardized ONNX representation facilitates model sharing and deployment across different runtime environments while maintaining optimization capabilities.
Performance Optimization Techniques and Capabilities
The optimization techniques employed by each framework reflect different philosophical approaches to achieving maximum inference performance. TensorRT’s optimization pipeline focuses heavily on GPU-specific techniques such as kernel fusion, precision optimization, and memory coalescing that extract maximum performance from NVIDIA hardware architectures.
The framework’s dynamic shape support and optimization capabilities make it particularly well-suited for applications with variable input dimensions, such as natural language processing models with varying sequence lengths or computer vision applications processing images of different resolutions. TensorRT can generate optimized execution plans for different input configurations while maintaining optimal performance across the supported range.
OpenVINO’s optimization approach emphasizes cross-platform techniques that deliver consistent performance improvements across diverse hardware configurations. The framework’s graph optimization capabilities include advanced techniques such as sub-graph replacement, operator fusion, and memory optimization that improve performance while maintaining portability across different deployment environments.
ONNX Runtime’s optimization strategy combines graph-level transformations with runtime optimizations to deliver performance improvements that scale effectively across different hardware configurations. The framework’s ability to dynamically select optimal execution strategies based on runtime conditions makes it particularly effective in deployment scenarios with varying workload characteristics.
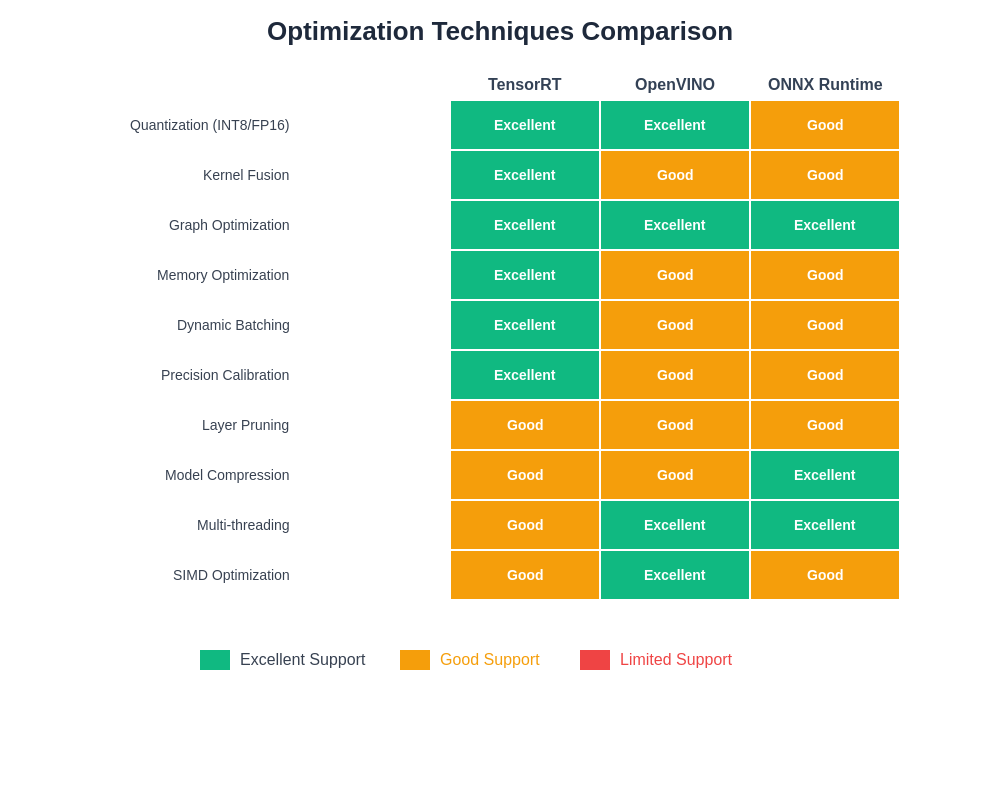
Different optimization frameworks employ varying techniques to achieve maximum performance, with each approach offering distinct advantages depending on specific deployment requirements and hardware configurations.
Deployment Scenarios and Use Case Suitability
The selection of an appropriate inference optimization framework depends heavily on specific deployment scenarios and performance requirements. TensorRT excels in high-performance scenarios where maximum GPU utilization is critical, such as autonomous vehicle perception systems, real-time video analytics, and high-throughput recommendation engines where millisecond improvements in latency translate directly to business value.
Data center deployment scenarios often benefit from TensorRT’s ability to maximize GPU utilization through advanced batching strategies and memory optimization techniques. The framework’s support for multi-instance GPU configurations enables efficient resource sharing while maintaining performance isolation between different inference workloads.
OpenVINO’s strength in edge deployment scenarios makes it an excellent choice for applications requiring inference capabilities on resource-constrained devices such as industrial IoT systems, retail analytics platforms, and smart city infrastructure where power efficiency and cost optimization are primary concerns.
The framework’s CPU optimization capabilities are particularly valuable in scenarios where GPU acceleration is not available or cost-effective, enabling high-performance inference on commodity server hardware or edge computing platforms. OpenVINO’s support for heterogeneous execution across different hardware types within the same deployment enables sophisticated load balancing and resource optimization strategies.
ONNX Runtime’s flexibility makes it ideal for cloud-native deployment scenarios where model portability and framework interoperability are critical requirements. The framework’s comprehensive hardware support enables deployment across diverse cloud infrastructure configurations while maintaining consistent performance characteristics.
Integration Complexity and Development Workflows
The integration complexity and development workflows associated with each framework represent important practical considerations that impact both initial implementation time and long-term maintenance requirements. TensorRT’s optimization process requires careful attention to model structure and operator compatibility, but the framework provides comprehensive tools and documentation that streamline the optimization workflow.
The framework’s Python and C++ APIs provide flexible integration options that support both prototyping and production deployment scenarios. TensorRT’s integration with popular training frameworks through official plugins and community contributions simplifies the transition from model development to optimized deployment.
OpenVINO’s comprehensive development toolkit includes model optimization utilities, accuracy validation tools, and performance benchmarking capabilities that support the entire optimization workflow from initial model conversion through production deployment. The framework’s extensive documentation and sample applications provide clear guidance for implementing optimization best practices.
The platform’s support for both high-level Python APIs and optimized C++ runtime libraries enables flexible integration strategies that balance development productivity with deployment performance requirements. OpenVINO’s containerized deployment options and Kubernetes integration support modern cloud-native deployment patterns.
ONNX Runtime’s straightforward integration process reflects its design philosophy of minimizing deployment complexity while maximizing performance benefits. The framework’s consistent API across different hardware backends simplifies development workflows while ensuring that hardware-specific optimizations remain accessible when needed.
Performance Benchmarking and Evaluation Methodologies
Accurate performance evaluation of inference optimization frameworks requires sophisticated benchmarking methodologies that account for the diverse factors influencing real-world performance characteristics. Hardware configuration, model architecture, batch size, input data characteristics, and deployment environment all significantly impact performance results, making comprehensive evaluation essential for informed framework selection.
TensorRT’s performance characteristics typically excel in GPU-accelerated scenarios with consistent input patterns and batch processing requirements. The framework’s optimization benefits become more pronounced with larger models and higher throughput requirements, where the overhead of optimization preparation is amortized across many inference operations.
Benchmark results consistently demonstrate TensorRT’s ability to achieve exceptional performance on supported NVIDIA hardware, with improvements often ranging from 2x to 10x over unoptimized implementations depending on model complexity and deployment configuration. The framework’s precision optimization capabilities contribute significantly to these performance gains while maintaining acceptable accuracy levels for most applications.
OpenVINO’s performance profile demonstrates consistent optimization benefits across diverse hardware configurations, with particularly strong results on Intel CPU and integrated graphics platforms. The framework’s CPU optimizations often deliver performance comparable to specialized hardware solutions for many common inference workloads.
Performance benchmarks reveal OpenVINO’s effectiveness in resource-constrained environments where power efficiency and cost optimization are primary concerns. The framework’s ability to maintain good performance across different hardware generations makes it an attractive choice for deployment scenarios with diverse infrastructure configurations.
ONNX Runtime’s performance characteristics reflect its focus on broad compatibility and consistent optimization benefits across different deployment environments. Benchmark results demonstrate the framework’s ability to deliver meaningful performance improvements while maintaining the flexibility to work effectively across diverse hardware and software configurations.
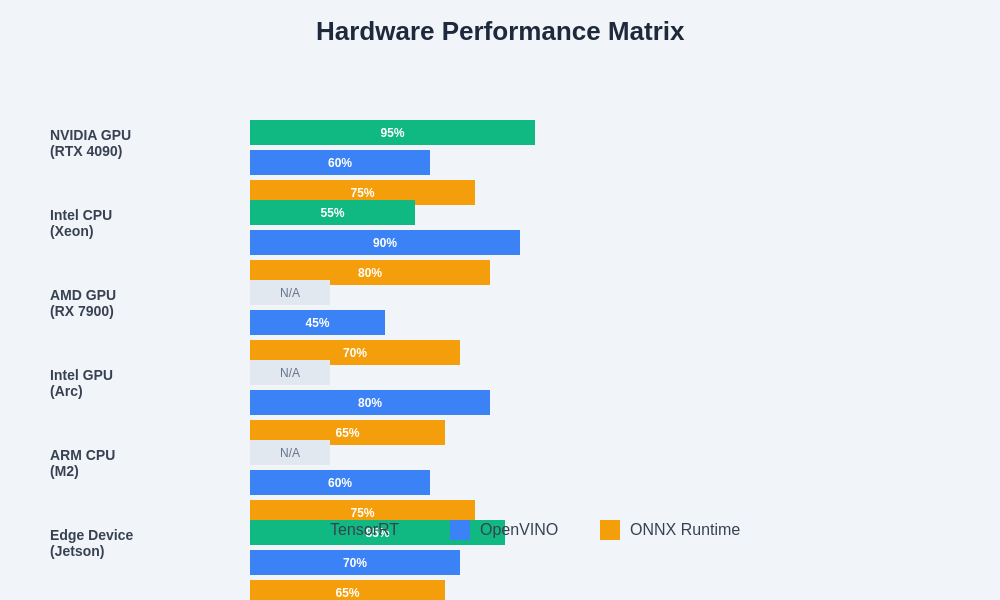
Performance characteristics vary significantly across different hardware configurations and deployment scenarios, highlighting the importance of comprehensive evaluation when selecting an appropriate inference optimization framework.
Security Considerations and Production Readiness
Production deployment of AI inference systems requires careful attention to security considerations that extend beyond basic performance optimization. Each inference optimization framework approaches security through different architectural and operational strategies that impact both development workflows and runtime security postures.
TensorRT’s close integration with NVIDIA’s hardware stack provides certain security advantages through hardware-level protections and secure memory management capabilities. The framework’s optimization process generates platform-specific execution plans that can provide some protection against reverse engineering while maintaining optimal performance characteristics.
OpenVINO’s security model emphasizes secure model handling and protected execution environments that support deployment scenarios with stringent security requirements. The framework provides tools for model encryption and secure loading that protect intellectual property while maintaining optimization benefits.
ONNX Runtime’s security approach focuses on secure runtime execution and comprehensive input validation that prevents common attack vectors while maintaining high performance. The framework’s provider-based architecture enables integration with hardware security features where available.
Future Developments and Technology Evolution
The rapid evolution of AI hardware and software technologies continues to drive innovation in inference optimization frameworks, with each platform pursuing distinct development strategies that reflect their core strengths and target markets. Understanding these development trajectories helps inform strategic decisions about framework adoption and long-term compatibility.
TensorRT’s development roadmap emphasizes deeper integration with emerging NVIDIA hardware architectures and advanced optimization techniques that push the boundaries of GPU-accelerated inference performance. The framework’s evolution toward supporting larger models and more complex architectures reflects the growing computational demands of cutting-edge AI applications.
OpenVINO’s future development focuses on expanding hardware support and improving cross-platform optimization capabilities that maintain its position as a leading choice for heterogeneous deployment environments. The framework’s roadmap includes enhanced support for emerging AI accelerators and improved tools for automated optimization workflow management.
ONNX Runtime’s development trajectory emphasizes expanding the ONNX ecosystem and improving interoperability between different AI frameworks and deployment environments. The platform’s evolution toward supporting more sophisticated model architectures and optimization techniques reflects its commitment to universal AI deployment capabilities.
Strategic Framework Selection Guidelines
Selecting the optimal inference optimization framework requires careful evaluation of multiple factors including performance requirements, hardware constraints, development resources, and long-term strategic considerations. Organizations must balance immediate performance needs with long-term flexibility and maintainability requirements to make informed decisions that support both current and future deployment scenarios.
For scenarios prioritizing maximum GPU performance with NVIDIA hardware, TensorRT represents the optimal choice, providing unparalleled optimization capabilities that justify the associated hardware dependencies and integration complexity. The framework’s sophisticated optimization techniques deliver performance benefits that often justify the additional development investment required for optimal implementation.
Organizations requiring broad hardware compatibility and flexible deployment options should strongly consider OpenVINO, particularly for CPU-intensive workloads or edge deployment scenarios where hardware diversity and cost optimization are primary concerns. The framework’s comprehensive optimization capabilities and extensive documentation support efficient implementation across diverse deployment environments.
ONNX Runtime emerges as the ideal choice for organizations prioritizing model portability and framework interoperability, particularly in cloud-native deployment scenarios where flexibility and consistent performance across diverse infrastructure configurations are critical requirements. The framework’s universal approach to AI inference optimization provides significant strategic advantages for complex deployment scenarios.
The continued evolution of AI inference optimization frameworks promises to deliver even more sophisticated capabilities and improved performance characteristics as hardware and software technologies advance. Organizations investing in AI deployment infrastructure should maintain awareness of these technological developments while building flexible architectures capable of adapting to future optimization opportunities.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. Performance characteristics may vary significantly based on specific hardware configurations, model architectures, and deployment requirements. Readers should conduct thorough testing and evaluation based on their specific use cases before making production deployment decisions. The effectiveness of different optimization frameworks depends on numerous factors that should be carefully evaluated for each unique deployment scenario.