The exponential growth of artificial intelligence applications has created unprecedented demands on computing infrastructure, requiring sophisticated orchestration solutions that can handle the complex, resource-intensive nature of machine learning workloads. Modern AI infrastructure relies heavily on containerization technologies, particularly Docker and Kubernetes, to provide the scalability, reliability, and efficiency necessary for deploying and managing AI applications at enterprise scale. This comprehensive exploration examines how these technologies form the backbone of contemporary AI infrastructure and enable organizations to build robust, scalable machine learning platforms.
Stay updated with the latest AI infrastructure trends to understand how containerization and orchestration technologies are evolving to meet the growing demands of artificial intelligence applications. The convergence of containerization technology with AI workloads represents a fundamental shift in how organizations approach machine learning infrastructure, enabling unprecedented levels of scalability and operational efficiency.
Understanding AI Infrastructure Requirements
Modern artificial intelligence applications present unique infrastructure challenges that distinguish them from traditional software deployments. AI workloads typically require substantial computational resources, including high-performance GPUs, large amounts of memory, and specialized hardware accelerators. These applications often involve complex dependency chains, multiple runtime environments, and varying resource requirements depending on whether they are performing training, inference, or data preprocessing tasks.
The dynamic nature of AI workloads further complicates infrastructure management. Machine learning models may need to scale rapidly to handle inference requests, require periodic retraining with updated datasets, or need to be deployed across multiple environments for A/B testing and gradual rollouts. Traditional infrastructure approaches often struggle to accommodate these requirements efficiently, leading to resource waste, deployment complexity, and operational overhead that can significantly impact both performance and cost-effectiveness.
Container orchestration platforms like Kubernetes have emerged as the preferred solution for managing these complex AI workloads by providing automated scaling, resource allocation, and deployment management capabilities that align with the unique requirements of machine learning applications. The combination of Docker’s containerization capabilities with Kubernetes’ orchestration features creates a powerful foundation for building AI infrastructure that can adapt to changing demands while maintaining operational stability.
Docker Fundamentals for AI Applications
Docker containerization provides the foundational layer for modern AI infrastructure by encapsulating machine learning applications, their dependencies, and runtime environments into portable, consistent execution units. This approach addresses one of the most persistent challenges in AI development: environment consistency across development, testing, and production systems. Machine learning frameworks often have complex dependency requirements, specific version constraints, and hardware-specific optimizations that can create significant deployment challenges when managed through traditional approaches.
The containerization of AI workloads offers several critical advantages beyond simple dependency management. Docker containers provide isolation between different AI applications, preventing resource conflicts and enabling multiple models to run simultaneously on the same infrastructure. This isolation is particularly valuable in multi-tenant AI platforms where different teams or applications may have conflicting requirements or need to maintain separate security boundaries.
Explore advanced AI development tools like Claude to enhance your containerized AI workflows with intelligent assistance for infrastructure design and optimization. The integration of AI-powered development tools with containerized infrastructure creates powerful synergies that streamline both development and operational processes.
Docker’s layered filesystem approach provides significant benefits for AI applications, where large model files and datasets can be shared efficiently across multiple containers. Base images can include common machine learning frameworks and dependencies, while application-specific layers contain models and configuration data. This layered approach reduces storage requirements, accelerates container startup times, and simplifies updates when only specific components need modification.
Kubernetes Architecture for Machine Learning
Kubernetes provides a sophisticated orchestration platform specifically designed to manage containerized applications at scale, making it exceptionally well-suited for AI infrastructure requirements. The platform’s architecture consists of multiple components that work together to provide automated deployment, scaling, and management of containerized AI workloads across clusters of compute nodes.
The master node components, including the API server, etcd datastore, scheduler, and controller manager, coordinate cluster operations and maintain the desired state of AI applications. The scheduler plays a particularly crucial role in AI workloads by making intelligent decisions about pod placement based on resource requirements, node capabilities, and constraints such as GPU availability or specific hardware requirements that may be necessary for particular machine learning tasks.
Worker nodes in a Kubernetes cluster run the kubelet agent, which manages pod lifecycle and communicates with the master components, along with the container runtime that actually executes the containerized AI applications. For AI workloads, worker nodes are often specialized with high-performance GPUs, large memory configurations, or other hardware accelerators that provide the computational power required for machine learning tasks.
The distributed nature of Kubernetes architecture enables AI infrastructure to span multiple data centers, cloud regions, or hybrid environments, providing the geographic distribution and redundancy necessary for global AI applications. This distributed approach also enables organizations to leverage specialized hardware resources located in different facilities while maintaining centralized management and orchestration capabilities.
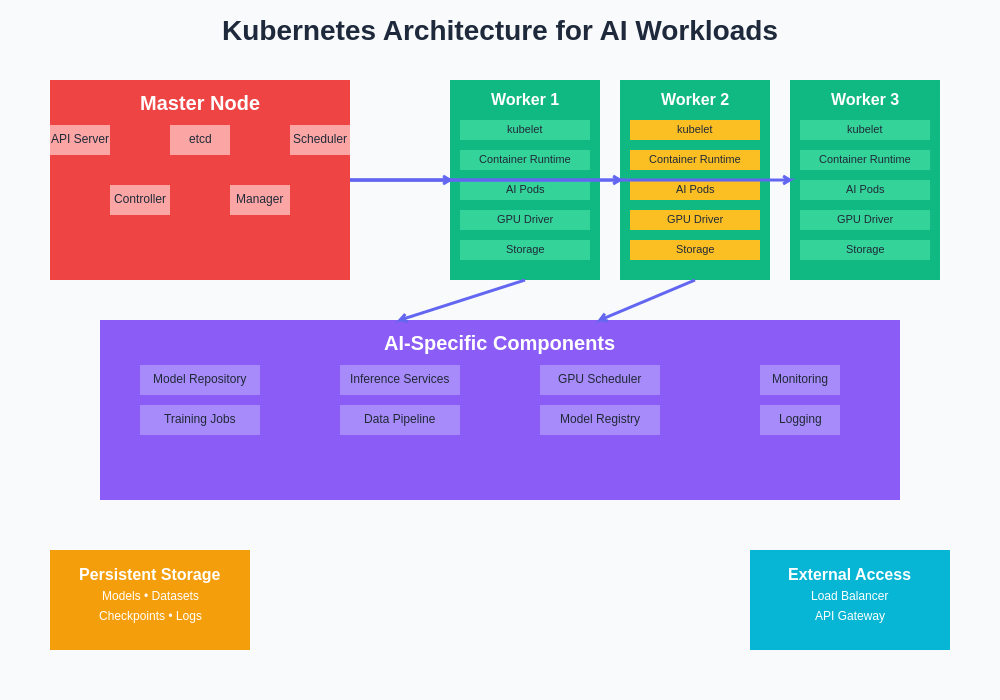
The comprehensive Kubernetes architecture for AI workloads encompasses both traditional cluster components and specialized AI-specific elements such as model repositories, GPU schedulers, and training job orchestrators. This integrated approach ensures that AI applications benefit from robust infrastructure capabilities while maintaining the flexibility and scalability required for complex machine learning workflows.
Container Orchestration Strategies
Effective container orchestration for AI workloads requires sophisticated strategies that account for the unique characteristics of machine learning applications. Unlike traditional web applications that typically follow predictable traffic patterns, AI workloads often exhibit highly variable resource demands that depend on factors such as model complexity, input data size, and computational requirements that can vary significantly between different types of inference requests.
Horizontal pod autoscaling in Kubernetes can be configured to monitor custom metrics relevant to AI applications, such as GPU utilization, memory usage patterns, or queue depths for inference requests. This enables dynamic scaling decisions based on actual workload characteristics rather than simple CPU utilization metrics that may not accurately reflect the resource demands of AI applications.
Vertical pod autoscaling provides another important dimension for AI workload management by automatically adjusting resource allocations for individual containers based on observed usage patterns. This capability is particularly valuable for AI applications where optimal resource allocation may not be immediately apparent and can change over time as models are updated or usage patterns evolve.
The implementation of custom resource definitions and operators enables Kubernetes to understand and manage AI-specific resources such as distributed training jobs, model serving endpoints, and data pipeline components. These extensions to the base Kubernetes functionality provide native support for complex AI workflows that would be difficult to manage using standard Kubernetes resources alone.
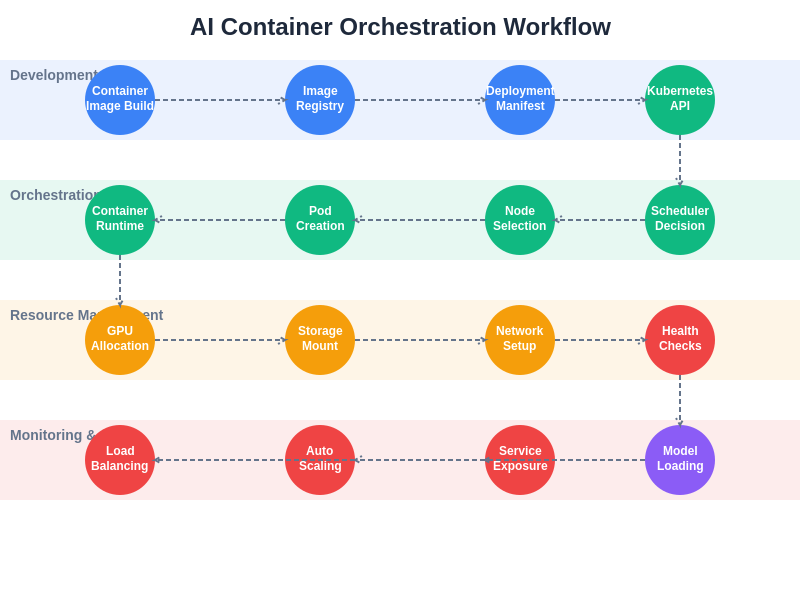
The complete orchestration workflow for AI containers demonstrates the intricate coordination required between development, deployment, resource management, and monitoring phases. Each stage of this workflow incorporates AI-specific considerations such as GPU allocation, model loading, and specialized health checks that ensure optimal performance and reliability for machine learning workloads.
GPU Resource Management and Allocation
Graphics processing units represent critical resources for AI infrastructure, requiring specialized management approaches within containerized environments. Kubernetes provides several mechanisms for GPU resource allocation, including device plugins that enable containers to request and utilize GPU resources in a controlled manner. The NVIDIA GPU Operator and similar solutions provide comprehensive GPU management capabilities that integrate seamlessly with Kubernetes orchestration.
GPU resource sharing presents unique challenges in containerized AI environments, as traditional approaches often allocate entire GPUs to individual containers, potentially leading to resource underutilization when workloads don’t fully utilize available GPU capacity. Multi-instance GPU technology and GPU virtualization solutions enable more efficient resource utilization by allowing multiple containers to share GPU resources while maintaining performance isolation.
Enhance your infrastructure research capabilities with Perplexity to stay informed about the latest developments in GPU virtualization and resource management technologies. The rapidly evolving landscape of GPU technology requires continuous learning and adaptation to optimize AI infrastructure performance and cost-effectiveness.
The scheduling of GPU-enabled workloads requires careful consideration of factors such as GPU memory requirements, computational intensity, and potential conflicts between different types of AI applications. Advanced scheduling strategies can take into account GPU topology, memory bandwidth requirements, and communication patterns between distributed AI workloads to optimize overall system performance.
Storage Solutions for AI Workloads
AI applications typically have substantial storage requirements that encompass training datasets, model artifacts, checkpoints, and intermediate processing results. These storage needs often exceed the capabilities of traditional container storage approaches and require specialized solutions that can provide high-performance, scalable storage while integrating seamlessly with containerized environments.
Persistent volume management in Kubernetes enables AI applications to maintain state across container restarts and scheduling changes, which is essential for long-running training jobs and applications that need to preserve model state or accumulated learning. Dynamic provisioning of persistent volumes allows storage resources to be allocated on-demand based on application requirements, providing both flexibility and cost optimization.
Distributed storage systems such as Ceph, GlusterFS, or cloud-native solutions like Amazon EFS provide the scalability and performance characteristics necessary for AI workloads. These systems can deliver the high-throughput, low-latency access patterns required for training data ingestion while providing the durability and availability necessary for critical model artifacts and results.
The integration of object storage systems with containerized AI workflows enables efficient management of large datasets and model repositories. Container-native backup and disaster recovery solutions ensure that valuable training results, model checkpoints, and datasets are protected against infrastructure failures while providing rapid recovery capabilities that minimize downtime for critical AI applications.
Networking and Service Mesh Architecture
AI applications often require sophisticated networking capabilities to support distributed training, model serving, and data pipeline coordination. Service mesh technologies such as Istio or Linkerd provide advanced networking features including traffic management, security policies, and observability that are particularly valuable for complex AI infrastructures with multiple interconnected components.
Load balancing for AI inference services requires specialized algorithms that can account for the varying computational complexity of different requests and the stateful nature of some machine learning models. Advanced load balancing strategies can route requests based on model characteristics, expected processing time, or resource availability to optimize overall system performance and user experience.
Network policies in Kubernetes enable fine-grained control over communication between AI application components, providing security isolation and traffic shaping capabilities that are essential for multi-tenant AI platforms. These policies can restrict access to sensitive model serving endpoints, control data flow between training and inference systems, and implement compliance requirements for regulated industries.
The implementation of ingress controllers and API gateways specifically designed for AI workloads provides external access management, rate limiting, and authentication capabilities that protect AI services while enabling integration with external applications and users. These components often include specialized features such as request queuing, batch processing coordination, and model version routing that are tailored to AI application requirements.
Monitoring and Observability
Comprehensive monitoring and observability are critical components of AI infrastructure, as machine learning workloads often exhibit complex behavior patterns that require specialized monitoring approaches. Traditional infrastructure monitoring metrics may not provide sufficient insight into AI application performance, necessitating the collection and analysis of AI-specific metrics such as model accuracy, inference latency, training convergence, and resource utilization patterns.
Prometheus and Grafana integration with Kubernetes provides a powerful foundation for AI infrastructure monitoring, enabling the collection of custom metrics from AI applications and the creation of specialized dashboards that provide visibility into model performance, resource utilization, and system health. These tools can be extended with AI-specific exporters that collect metrics directly from machine learning frameworks and applications.
Distributed tracing solutions such as Jaeger or Zipkin provide valuable insights into the complex request flows that characterize many AI applications, particularly those involving multiple model inference steps, data preprocessing pipelines, or distributed training coordination. These tracing capabilities enable developers and operators to identify performance bottlenecks, understand system behavior, and optimize AI application architectures.
Log aggregation and analysis platforms specialized for AI workloads can process the large volumes of structured and unstructured data generated by machine learning applications, providing insights into model behavior, error patterns, and performance trends that inform optimization and troubleshooting efforts.
Security and Compliance Considerations
AI infrastructure security encompasses multiple dimensions, including container security, data protection, model integrity, and compliance with regulatory requirements that may apply to AI applications in specific industries. Container image scanning and vulnerability assessment tools help identify and remediate security issues in the software dependencies and base images used for AI applications.
Network security policies and encryption capabilities ensure that sensitive training data, model parameters, and inference results are protected both in transit and at rest. Pod security policies and security contexts provide fine-grained control over container execution privileges, resource access, and system capabilities that are essential for maintaining secure AI environments.
Access control and authentication mechanisms must account for the unique requirements of AI workflows, including service-to-service authentication for distributed training jobs, secure access to model repositories, and integration with identity management systems that may need to support both human users and automated AI pipeline components.
Compliance frameworks for AI applications often require detailed audit trails, data lineage tracking, and reproducibility guarantees that can be challenging to implement in containerized environments. Specialized tools and practices for AI governance can help organizations meet these requirements while maintaining the operational benefits of containerized infrastructure.
Deployment Patterns and Best Practices
Successful AI infrastructure deployment requires the implementation of proven patterns and practices that account for the unique characteristics of machine learning workloads. Blue-green deployments for AI applications must consider model warming requirements, state migration for stateful models, and validation procedures that ensure new model versions perform correctly before switching traffic.
Canary deployments for AI models present unique challenges related to result consistency, A/B testing coordination, and gradual traffic shifting that must account for the stochastic nature of many machine learning models. Advanced deployment strategies may include shadow testing, where new models process production traffic without affecting user-facing results, enabling thorough validation before full deployment.
Rolling updates for AI applications require careful consideration of resource requirements, as new model versions may have different computational or memory requirements that affect scheduling and resource allocation decisions. Automated rollback mechanisms must account for model-specific validation criteria and performance thresholds that determine when deployments should be reverted.
The implementation of multi-environment deployment pipelines enables AI teams to progress models through development, staging, and production environments while maintaining consistency and enabling thorough testing at each stage. These pipelines often integrate with model management platforms and automated testing frameworks that validate model behavior and performance across different environments.
Scaling Strategies for AI Infrastructure
Effective scaling strategies for AI infrastructure must account for both the computational intensity of machine learning workloads and their often unpredictable demand patterns. Horizontal scaling approaches can distribute inference workloads across multiple containers or nodes, but must consider factors such as model loading times, memory requirements, and potential performance variations between different hardware configurations.
Vertical scaling strategies may be more appropriate for certain types of AI workloads, particularly those involving large models that cannot be easily distributed across multiple containers. Dynamic resource allocation mechanisms can adjust container resource limits based on observed usage patterns and performance requirements.
Auto-scaling policies for AI workloads should incorporate domain-specific metrics and thresholds that reflect the actual performance characteristics of machine learning applications. Custom metrics such as queue depth for inference requests, GPU utilization patterns, or model-specific latency requirements provide more accurate scaling triggers than generic CPU or memory utilization metrics.
The implementation of predictive scaling approaches can anticipate demand patterns for AI applications based on historical usage data, scheduled batch processing jobs, or external factors that influence AI application usage. These proactive scaling strategies can pre-position resources to handle expected load increases, reducing response times and improving user experience.
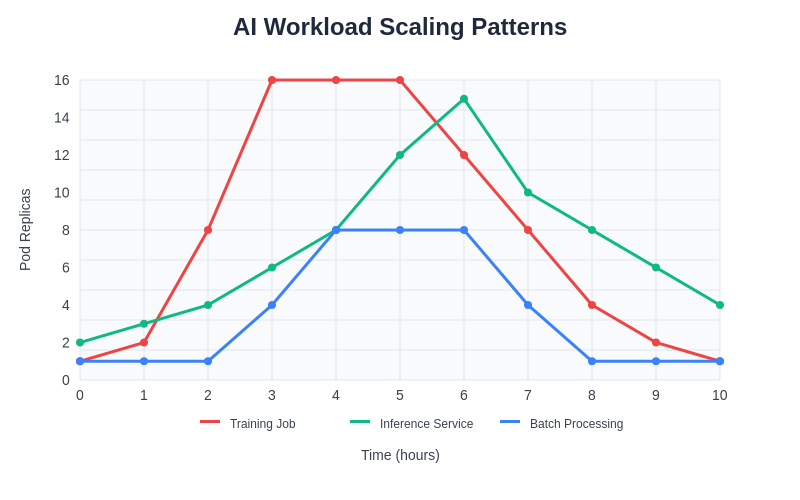
The scaling patterns for different types of AI workloads demonstrate the diverse resource requirements and temporal characteristics of machine learning applications. Training jobs typically require intensive resource allocation during specific time periods, while inference services show more consistent but variable demand patterns, and batch processing workloads exhibit predictable scheduling requirements that enable optimized resource planning.
Future Trends and Evolution
The evolution of AI infrastructure continues to be driven by advancing requirements from increasingly sophisticated machine learning applications and emerging technologies that promise to further optimize containerized AI workloads. Edge computing integration with Kubernetes enables AI applications to run closer to data sources and users, reducing latency and bandwidth requirements while maintaining centralized orchestration capabilities.
Serverless computing platforms specifically designed for AI workloads are beginning to integrate with container orchestration systems, providing event-driven execution models that can significantly reduce infrastructure costs for sporadic or batch-oriented AI applications. These serverless approaches maintain the benefits of containerization while eliminating the need to maintain persistent infrastructure for infrequently used AI capabilities.
Quantum computing integration represents an emerging frontier for AI infrastructure, as quantum processing capabilities become more accessible through cloud platforms and specialized hardware. Container orchestration platforms are beginning to incorporate support for hybrid classical-quantum workloads that can leverage both traditional and quantum computing resources within unified AI applications.
Machine learning operations platforms are increasingly incorporating advanced automation capabilities that can optimize container resource allocation, automate model deployment decisions, and coordinate complex AI workflows with minimal human intervention. These developments promise to further reduce the operational complexity of AI infrastructure while improving performance and cost-effectiveness.
The continued advancement of AI infrastructure through containerization and orchestration technologies represents a critical enabler for the next generation of artificial intelligence applications. Organizations that invest in building robust, scalable AI infrastructure using these proven technologies position themselves to take advantage of rapidly evolving AI capabilities while maintaining the operational efficiency and reliability necessary for production AI deployments.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The implementation of AI infrastructure using Docker and Kubernetes should be carefully planned and tested based on specific organizational requirements, security policies, and compliance obligations. Readers should consult with qualified infrastructure professionals and conduct thorough testing before deploying AI workloads in production environments. Technology recommendations and best practices may evolve as the field continues to develop.