
The complexity of modern machine learning systems demands sophisticated testing approaches that extend far beyond traditional software testing methodologies. AI integration testing represents a critical discipline that ensures the reliability, accuracy, and robustness of end-to-end machine learning pipelines from data ingestion through model deployment and monitoring. This comprehensive validation process encompasses data quality assurance, feature engineering verification, model performance testing, and production system integration, creating a holistic framework that maintains the integrity of AI systems throughout their entire lifecycle.
Explore the latest AI development trends to understand how testing practices are evolving alongside rapidly advancing machine learning technologies. The integration of comprehensive testing strategies into ML workflows has become essential for organizations seeking to deploy reliable, scalable, and maintainable artificial intelligence solutions that deliver consistent value in production environments.
Understanding AI Integration Testing Fundamentals
AI integration testing differs significantly from conventional software testing due to the inherent complexity and non-deterministic nature of machine learning systems. Traditional software testing focuses on verifying that code produces expected outputs for given inputs, while AI integration testing must account for probabilistic outcomes, data distribution shifts, model degradation over time, and the interdependencies between multiple components in complex ML pipelines. This fundamental difference requires specialized testing frameworks, methodologies, and tools designed specifically for the unique challenges presented by machine learning systems.
The scope of AI integration testing encompasses multiple layers of validation, including data pipeline integrity, feature engineering consistency, model behavior verification, API integration testing, and end-to-end system performance validation. Each layer presents distinct challenges and requires specific testing strategies that account for the statistical nature of machine learning algorithms, the importance of data quality, and the need for continuous monitoring and validation in production environments.
Data Pipeline Validation and Quality Assurance
The foundation of any successful machine learning system rests upon the quality and integrity of its data pipelines. Data pipeline validation represents the first and most critical layer of AI integration testing, ensuring that data flows correctly through the system, maintains its quality and consistency, and arrives at each stage in the expected format and structure. This validation process must account for data schema evolution, missing value handling, outlier detection, and the preservation of data lineage throughout the entire pipeline.
Comprehensive data pipeline testing involves implementing automated checks that verify data completeness, accuracy, consistency, and timeliness at each stage of the data flow. These checks must be designed to detect anomalies, schema changes, data drift, and quality degradation that could impact downstream model performance. The testing framework should include mechanisms for data profiling, statistical validation, and automated alerting when data quality metrics fall below acceptable thresholds.
Enhance your AI development workflow with Claude to implement sophisticated data validation strategies that ensure pipeline reliability and data quality across complex machine learning systems. The integration of advanced AI tools into testing workflows enables more thorough validation and faster identification of potential issues before they impact production systems.
Feature Engineering and Transformation Testing
Feature engineering represents one of the most critical aspects of machine learning pipeline development, directly impacting model performance and system reliability. Testing feature engineering processes requires validation of transformation logic, consistency across different data batches, and verification that engineered features maintain their expected statistical properties and business meaning. This testing must ensure that feature transformations are reproducible, scalable, and maintain consistent behavior across training and inference environments.
The complexity of feature engineering testing increases significantly when dealing with time-series data, categorical encodings, normalization processes, and feature interactions. Testing frameworks must validate that feature transformations handle edge cases appropriately, maintain numerical stability, and produce consistent results across different computational environments. Additionally, testing must verify that feature engineering pipelines can handle missing data, outliers, and unexpected input distributions without compromising system stability or producing invalid features.
Model Performance and Behavior Validation
Model validation extends beyond simple accuracy metrics to encompass comprehensive behavior testing that ensures models perform reliably across diverse scenarios and edge cases. This validation process must evaluate model performance across different data distributions, demographic groups, and operational conditions to identify potential biases, failure modes, and performance degradation patterns. Comprehensive model testing includes evaluation of prediction consistency, confidence calibration, robustness to adversarial inputs, and behavior under distribution shift scenarios.
The testing framework must implement statistical tests that validate model behavior against expected performance baselines, detect significant performance changes, and identify potential overfitting or underfitting issues. Model validation should also include testing of model interpretability features, ensuring that explanation methods produce consistent and meaningful insights that align with domain expertise and business requirements.
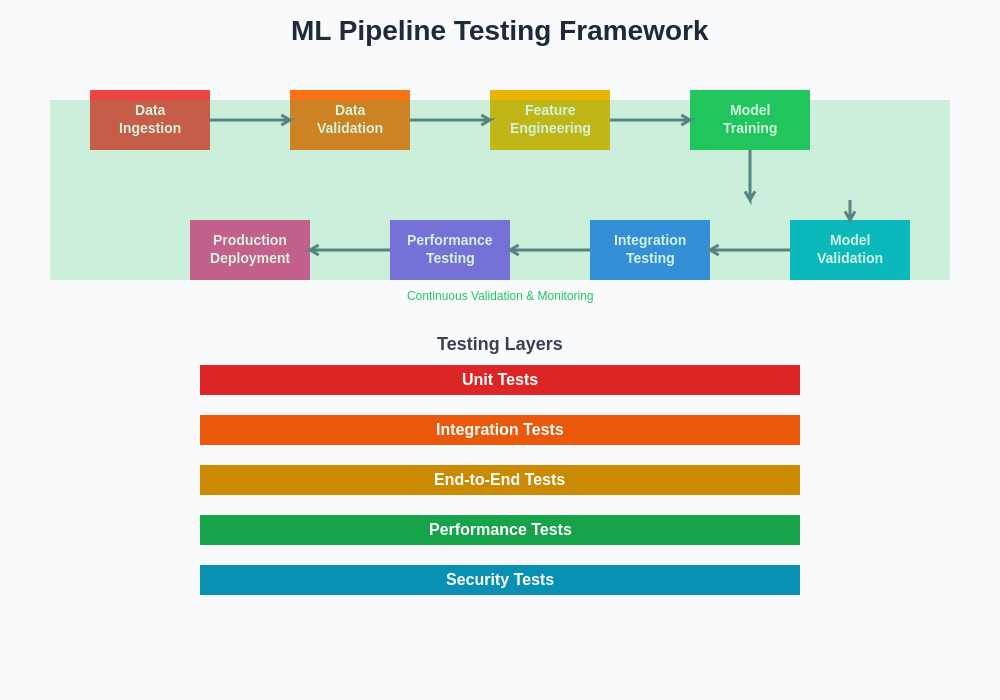
The comprehensive ML pipeline testing framework encompasses multiple validation layers that work together to ensure system reliability, from initial data ingestion through final model deployment and monitoring. Each validation layer addresses specific aspects of the pipeline while contributing to overall system integrity and performance assurance.
Integration Testing Across ML Components
Modern machine learning systems consist of numerous interconnected components that must work seamlessly together to deliver reliable predictions and insights. Integration testing for ML systems requires validation of component interactions, data flow consistency, API compatibility, and end-to-end system behavior under various operational conditions. This testing must ensure that changes to individual components do not introduce unexpected behaviors or performance degradation in other parts of the system.
The integration testing process must validate that model serving infrastructure correctly handles prediction requests, maintains appropriate response times, and gracefully handles error conditions. Testing should verify that model updates and deployments occur without service interruption, that versioning systems maintain consistency, and that rollback procedures function correctly when issues are detected. Additionally, integration testing must validate that monitoring and alerting systems accurately detect and report system anomalies and performance issues.
Continuous Validation and Monitoring Strategies
The dynamic nature of machine learning systems requires continuous validation and monitoring that extends well beyond initial deployment. Continuous validation frameworks must monitor model performance degradation, detect data drift, identify concept drift, and validate that system behavior remains consistent with expectations over time. This ongoing validation process requires automated testing pipelines that can detect subtle changes in system behavior and alert stakeholders to potential issues before they impact business outcomes.
Effective continuous validation strategies implement statistical process control methods that establish baseline performance metrics and detect statistically significant deviations from expected behavior. The monitoring framework should include capabilities for A/B testing new model versions, gradual rollout strategies, and automated rollback mechanisms when performance degradation is detected. Additionally, continuous validation must monitor system resource utilization, prediction latency, and throughput to ensure that performance requirements are maintained as system load and data volumes change.
Leverage advanced research capabilities with Perplexity to stay current with the latest developments in ML testing methodologies and implement cutting-edge validation techniques that enhance system reliability and performance monitoring capabilities.
Test Data Management and Synthetic Data Generation
Effective AI integration testing requires comprehensive test data management strategies that ensure adequate coverage of edge cases, boundary conditions, and diverse operational scenarios. Test data management for ML systems presents unique challenges due to data privacy requirements, the need for representative samples across different population segments, and the importance of maintaining realistic data distributions that reflect production environments. Synthetic data generation has emerged as a powerful solution for creating comprehensive test datasets that preserve statistical properties while protecting sensitive information.
The test data management framework must implement strategies for creating diverse test scenarios that include adversarial examples, edge cases, and stress testing conditions that validate system robustness and reliability. Synthetic data generation techniques enable the creation of controlled test environments where specific failure modes can be systematically evaluated, model behavior can be thoroughly validated, and system performance can be characterized across a wide range of operational conditions.
Automated Testing Frameworks and Tool Integration
The complexity and scale of modern ML systems necessitate sophisticated automated testing frameworks that can efficiently validate system behavior across multiple dimensions and operational scenarios. Automated testing frameworks for AI systems must integrate with existing MLOps toolchains, support continuous integration and deployment pipelines, and provide comprehensive reporting capabilities that enable stakeholders to understand system health and performance characteristics.
These frameworks must support parallel execution of test suites, distributed testing across multiple environments, and integration with popular machine learning platforms and cloud services. The testing infrastructure should provide capabilities for test case generation, automated regression testing, performance benchmarking, and integration with monitoring and alerting systems that enable proactive issue detection and resolution.
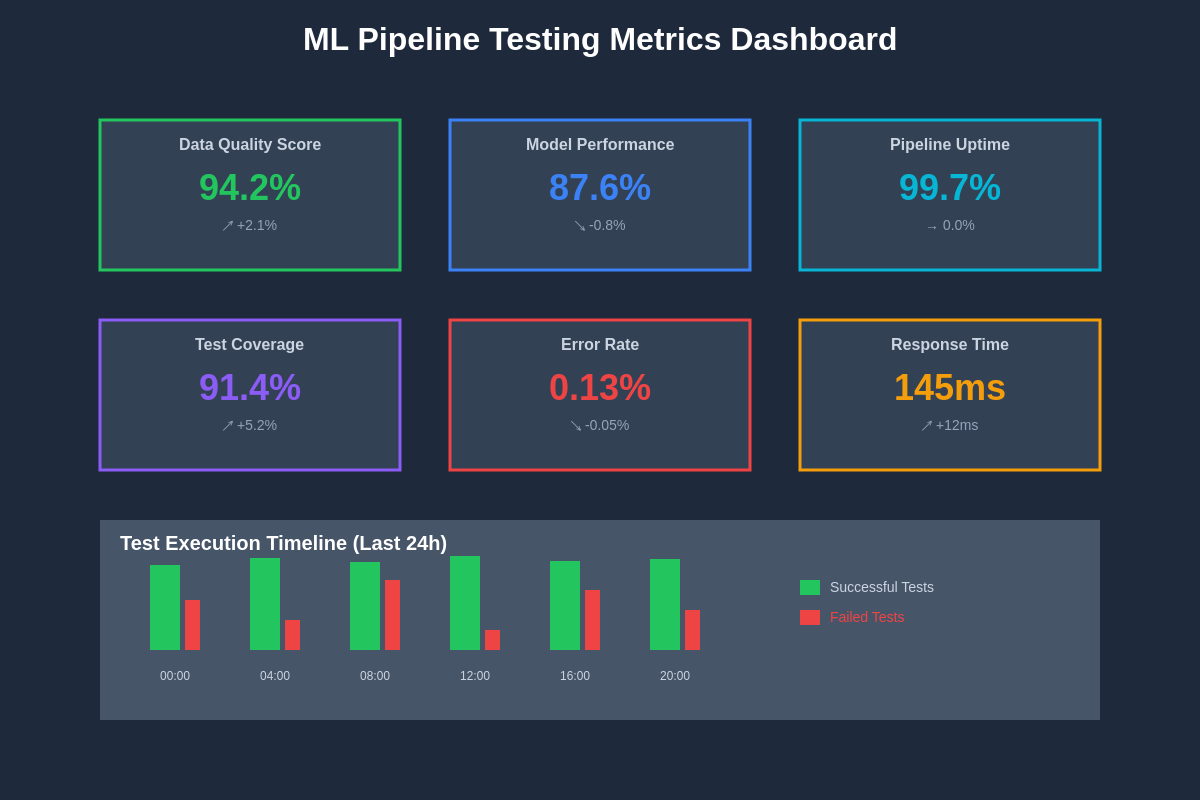
A comprehensive testing metrics dashboard provides real-time visibility into ML pipeline health, performance trends, and validation results across all testing layers. This centralized monitoring approach enables quick identification of issues and supports data-driven decisions about system improvements and maintenance priorities.
Security and Privacy Testing in ML Systems
The deployment of machine learning systems in production environments requires comprehensive security and privacy testing that validates data protection measures, access controls, and resistance to adversarial attacks. Security testing for ML systems must evaluate vulnerability to model inversion attacks, membership inference attacks, and adversarial examples that could compromise system integrity or expose sensitive information. Privacy testing must validate that data anonymization techniques are effective, that model outputs do not leak sensitive information, and that data handling procedures comply with relevant regulations and privacy requirements.
The security testing framework must implement automated vulnerability scanning, penetration testing procedures, and validation of encryption and access control mechanisms throughout the ML pipeline. Testing should verify that audit logging captures appropriate system events, that data governance policies are correctly implemented, and that incident response procedures can effectively address security breaches or privacy violations when they occur.
Performance and Scalability Validation
Production ML systems must handle varying loads, scale efficiently with increasing data volumes, and maintain acceptable performance characteristics under diverse operational conditions. Performance and scalability testing for AI systems requires validation of prediction latency, throughput capacity, resource utilization patterns, and system behavior under stress conditions. This testing must evaluate how system performance changes with increasing concurrent users, growing data volumes, and evolving model complexity.
The performance testing framework must implement load testing procedures that simulate realistic production workloads, stress testing scenarios that evaluate system limits, and endurance testing that validates long-term system stability. Testing should verify that auto-scaling mechanisms function correctly, that resource allocation strategies optimize cost and performance trade-offs, and that system monitoring accurately captures performance metrics and trends.
Regulatory Compliance and Audit Trail Validation
Machine learning systems deployed in regulated industries must maintain comprehensive audit trails, support regulatory compliance requirements, and provide transparency into decision-making processes. Compliance testing must validate that audit logging captures all required system events, that data lineage tracking provides complete visibility into data sources and transformations, and that model explainability features produce consistent and accurate explanations for regulatory review.
The compliance testing framework must implement validation procedures for data retention policies, access logging, change management processes, and documentation requirements. Testing should verify that compliance reporting systems generate accurate reports, that data governance procedures are correctly implemented, and that system behavior aligns with regulatory requirements and industry standards.

A systematic compliance testing checklist ensures that all regulatory requirements are thoroughly validated, from data handling procedures to model explainability features. This comprehensive approach supports audit readiness and demonstrates due diligence in regulatory compliance efforts.
Error Handling and Recovery Testing
Robust ML systems must handle errors gracefully, implement effective recovery mechanisms, and maintain service availability despite component failures or unexpected conditions. Error handling testing must validate that systems correctly identify and respond to various failure modes, that error messages provide appropriate information for debugging and resolution, and that recovery procedures restore normal operation without data loss or corruption.
The error handling testing framework must simulate various failure scenarios including network interruptions, hardware failures, data corruption, and service dependencies becoming unavailable. Testing should verify that circuit breaker patterns prevent cascade failures, that retry mechanisms implement appropriate backoff strategies, and that system monitoring accurately detects and reports error conditions to enable rapid response and resolution.
Version Control and Model Management Testing
The complexity of ML systems requires sophisticated version control and model management capabilities that ensure reproducibility, support rollback procedures, and maintain consistency across development, staging, and production environments. Version control testing must validate that model artifacts, training data, feature engineering code, and configuration parameters are correctly versioned and tracked throughout the system lifecycle.
The model management testing framework must verify that model deployment procedures correctly handle version transitions, that A/B testing infrastructure accurately routes traffic between model versions, and that rollback procedures can quickly restore previous system states when issues are detected. Testing should validate that model metadata tracking captures all relevant information for reproducibility and compliance requirements.
Emerging Trends and Future Directions
The field of AI integration testing continues to evolve rapidly with advances in machine learning technologies, testing methodologies, and automation capabilities. Emerging trends include the development of AI-powered testing tools that can automatically generate test cases, identify potential failure modes, and optimize testing strategies based on system behavior patterns. The integration of formal verification methods, advanced simulation techniques, and synthetic data generation is expanding the capabilities of ML testing frameworks.
Future developments in AI integration testing are likely to focus on improved automation, more sophisticated validation techniques, and better integration with emerging MLOps platforms and cloud services. The growing importance of responsible AI practices is driving development of testing frameworks that can validate fairness, transparency, and accountability requirements in addition to traditional performance and reliability metrics.
The continued advancement of AI integration testing methodologies will play a crucial role in enabling the reliable deployment of increasingly sophisticated machine learning systems across diverse industries and applications. Organizations that invest in comprehensive testing strategies will be better positioned to realize the full potential of AI technologies while managing the associated risks and maintaining stakeholder confidence in their AI-powered solutions.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The testing methodologies and strategies discussed should be adapted to specific system requirements, regulatory environments, and organizational constraints. Readers should conduct thorough evaluation and testing of any implementation approaches in their specific context. The effectiveness of testing strategies may vary depending on system complexity, data characteristics, and operational requirements.