The exponential growth of large language models has fundamentally transformed the computational landscape, creating unprecedented demands on system memory resources that extend far beyond traditional software applications. Understanding the intricate relationship between RAM and VRAM requirements for these sophisticated AI systems has become crucial for developers, researchers, and organizations seeking to deploy or develop large language models effectively. The memory architecture decisions made today will determine the feasibility, performance, and scalability of AI implementations across diverse computing environments.
Explore the latest developments in AI hardware trends to stay informed about cutting-edge memory technologies and optimization techniques that are shaping the future of large language model deployment. The distinction between RAM and VRAM usage in AI workloads represents a critical knowledge gap that can significantly impact both performance outcomes and cost considerations in AI infrastructure planning.
Understanding Memory Fundamentals in AI Systems
The foundation of large language model performance rests upon the efficient utilization of memory resources, where the distinction between system RAM and graphics VRAM plays a pivotal role in determining overall computational efficiency. System RAM serves as the primary workspace for model loading, data preprocessing, and intermediate computations, while VRAM provides the high-bandwidth, parallel processing environment essential for matrix operations and tensor calculations that form the core of neural network computations.
Modern large language models typically require substantial memory allocations that can range from several gigabytes for smaller models to hundreds of gigabytes for state-of-the-art implementations. The memory footprint encompasses not only the model parameters themselves but also activation maps, gradient calculations during training, and various optimization states that must be maintained throughout the computational process. This comprehensive memory requirement necessitates careful planning and optimization to ensure efficient resource utilization.
The architectural differences between RAM and VRAM significantly influence how these memory types interact with large language models. System RAM offers larger capacity at lower cost per gigabyte but operates at relatively modest bandwidth compared to VRAM. Graphics VRAM provides exceptional bandwidth and parallel access patterns optimized for the matrix multiplication operations that dominate neural network computations, though typically at higher cost and lower total capacity than system RAM.
Model Size and Parameter Scaling Impact
The relationship between model parameters and memory requirements follows predictable patterns that inform hardware planning and optimization strategies. Each parameter in a language model typically requires specific memory allocations depending on the precision format used, with 32-bit floating-point parameters consuming four bytes, 16-bit half-precision requiring two bytes, and emerging 8-bit quantization techniques reducing this to one byte per parameter.
Contemporary large language models demonstrate exponential scaling in parameter counts, from relatively modest models containing millions of parameters to cutting-edge implementations featuring hundreds of billions of parameters. This scaling directly translates to proportional increases in base memory requirements, before considering additional overhead for activations, optimization states, and computational buffers that can multiply the effective memory footprint by factors of two to four times the raw parameter storage requirements.
Leverage advanced AI capabilities with Claude to optimize memory usage patterns and develop efficient deployment strategies for large language models across various hardware configurations. The complexity of memory management in these systems requires sophisticated understanding of both hardware capabilities and software optimization techniques.
RAM Utilization Patterns and Optimization
System RAM plays a fundamental role in large language model operations, serving multiple critical functions that extend beyond simple parameter storage. The primary RAM utilization patterns include model weight loading and caching, input data batching and preprocessing, intermediate result storage during inference and training, and coordination between multiple processing units in distributed computing environments.
Effective RAM optimization strategies focus on minimizing memory fragmentation, implementing efficient caching mechanisms, and coordinating data movement between system memory and processing units. Memory mapping techniques allow for virtual memory management that can handle models larger than available physical RAM, though at the cost of increased latency due to storage system interaction. Dynamic loading strategies enable selective parameter loading based on computational requirements, reducing peak memory usage while maintaining model functionality.
The interaction between RAM and storage systems becomes particularly critical when dealing with models that exceed available system memory. Modern optimization approaches include parameter streaming, where model weights are loaded on-demand from high-speed storage, and memory-efficient attention mechanisms that reduce peak memory requirements during computation. These strategies require careful balance between memory conservation and computational performance to maintain acceptable inference speeds.
VRAM Architecture and Performance Characteristics
Graphics VRAM represents the high-performance memory subsystem specifically designed for parallel computational workloads that characterize large language model operations. The architectural advantages of VRAM include exceptional bandwidth capabilities, typically ranging from 500 GB/s to over 3000 GB/s in modern GPUs, compared to system RAM bandwidth of 100-200 GB/s in typical configurations. This bandwidth advantage directly translates to improved performance for the matrix multiplication operations that dominate neural network computations.
VRAM capacity constraints present significant challenges for large language model deployment, as even high-end consumer graphics cards typically offer 24-48 GB of VRAM, while professional accelerators may provide 80-128 GB or more. These capacity limitations necessitate careful model partitioning, quantization strategies, and multi-GPU coordination to accommodate the largest language models within available VRAM resources.
The parallel access patterns supported by VRAM architecture align naturally with the computational requirements of transformer-based language models, where thousands of parallel threads can simultaneously access different memory locations to perform matrix operations. This architectural synergy results in significant performance improvements for AI workloads compared to traditional CPU-based computations relying solely on system RAM.

The fundamental differences in memory architecture between RAM and VRAM create distinct performance characteristics that directly impact large language model efficiency. Understanding these architectural distinctions enables informed decisions about hardware selection and optimization strategies.
Training vs Inference Memory Requirements
The memory requirements for language model training differ substantially from inference workloads, necessitating different optimization strategies and hardware configurations. Training operations require storage of forward pass activations, backward pass gradients, optimizer states, and multiple model checkpoints, resulting in memory requirements that can exceed inference needs by factors of three to ten times depending on the specific training configuration and optimization algorithm employed.
Inference workloads focus primarily on efficient parameter access and activation computation, with memory requirements concentrated on model weights and current batch processing. The reduced memory overhead during inference enables deployment of larger models on constrained hardware or supports higher batch sizes for improved throughput. Memory optimization techniques such as key-value cache management in autoregressive generation become critical for maintaining performance while minimizing memory consumption.
The temporal characteristics of memory usage also differ significantly between training and inference. Training exhibits cyclical memory patterns with peaks during gradient accumulation and optimization steps, while inference maintains more consistent memory usage patterns focused on parameter access and activation computation. These patterns inform memory allocation strategies and hardware selection criteria for specific deployment scenarios.
Enhance your AI research capabilities with Perplexity for comprehensive analysis of memory optimization techniques and hardware benchmarking studies that inform deployment decisions. The research community continuously develops new approaches to memory efficiency that can significantly impact practical deployment considerations.
Quantization and Precision Impact
Precision reduction through quantization techniques represents one of the most effective approaches for reducing memory requirements in large language models. The transition from 32-bit floating-point to 16-bit half-precision can halve memory requirements while maintaining acceptable model performance in most applications. Further quantization to 8-bit integer representations can achieve additional memory reductions, though with increasing complexity in implementation and potential impact on model accuracy.
Advanced quantization techniques such as mixed precision training and inference enable selective application of different precision levels throughout the model, optimizing memory usage while preserving accuracy in critical computations. These approaches require sophisticated understanding of numerical stability and error propagation to implement effectively while maintaining model quality standards.
The hardware support for different precision formats varies across GPU architectures and computing platforms, influencing the practical benefits of quantization strategies. Modern tensor processing units and specialized AI accelerators often provide optimized support for reduced precision operations, enabling significant performance improvements beyond the memory savings achieved through quantization.
Multi-GPU and Distributed Memory Strategies
Large language models that exceed single-GPU memory capacity require sophisticated distribution strategies that coordinate memory usage across multiple processing units. Model parallelism techniques partition model parameters across multiple GPUs, enabling collective computation on models larger than individual GPU memory capacity. This approach requires careful optimization of inter-GPU communication to minimize bandwidth bottlenecks that can severely impact performance.
Data parallelism distributes training batches across multiple GPUs while maintaining complete model copies on each device, trading increased total memory usage for improved training throughput and simplified implementation. Hybrid approaches combine model and data parallelism to optimize memory efficiency while maintaining computational performance across large-scale distributed systems.
The memory hierarchy in multi-GPU systems becomes increasingly complex, with considerations for GPU-to-GPU communication bandwidth, system RAM usage for coordination and buffering, and network bandwidth for multi-node distributed training. Effective optimization requires comprehensive understanding of these interconnected memory subsystems and their performance characteristics.
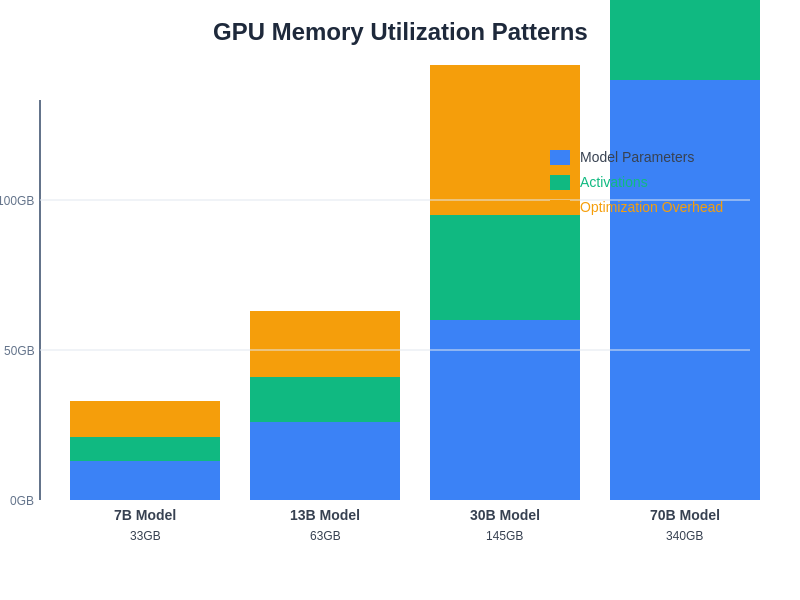
Modern GPU memory utilization patterns in large language model workloads demonstrate the complex interplay between parameter storage, activation computation, and optimization overhead across different model sizes and batch configurations.
Hardware Selection and Configuration Guidelines
Selecting appropriate hardware for large language model deployment requires careful analysis of memory requirements, performance objectives, and cost constraints. Consumer-grade GPUs offer accessible entry points for smaller models and research applications, while professional accelerators provide the memory capacity and computational performance required for production deployments of large-scale models.
The balance between VRAM capacity and computational performance varies across different GPU architectures and price points, necessitating detailed analysis of specific model requirements and deployment scenarios. Memory bandwidth often represents a more critical performance factor than raw computational throughput for many language model workloads, influencing hardware selection priorities.
System configuration considerations extend beyond GPU selection to include system RAM capacity, storage performance for model loading and checkpointing, and cooling solutions for sustained high-performance operation. The total cost of ownership includes not only initial hardware acquisition but also ongoing operational costs related to power consumption and cooling requirements.
Memory Optimization Techniques and Best Practices
Effective memory optimization for large language models encompasses multiple strategies that can be combined to maximize hardware utilization while maintaining acceptable performance levels. Gradient checkpointing trades computational overhead for memory savings by recomputing activations during backward passes rather than storing them in memory. This technique can significantly reduce peak memory requirements during training at the cost of increased computation time.
Dynamic memory allocation and deallocation strategies minimize memory fragmentation and enable more efficient utilization of available resources. Memory pooling techniques reduce allocation overhead and improve performance consistency by maintaining pre-allocated memory buffers for common operations. These optimizations become increasingly important as model sizes approach hardware memory limits.
Advanced optimization techniques such as memory-efficient attention implementations reduce the quadratic memory scaling of transformer architectures through algorithmic improvements that maintain mathematical equivalence while reducing memory requirements. These approaches enable deployment of larger models or processing of longer sequences within constrained memory environments.
Emerging Memory Technologies and Future Trends
The rapid evolution of memory technologies promises significant improvements in large language model deployment capabilities. High Bandwidth Memory implementations provide increased capacity and bandwidth compared to traditional GDDR memory architectures, enabling more efficient processing of large models. Emerging memory technologies such as persistent memory and storage-class memory blur the traditional boundaries between volatile and non-volatile storage, potentially enabling new deployment strategies for very large models.
Processing-in-memory technologies that integrate computational capabilities directly into memory subsystems represent a paradigm shift that could fundamentally alter memory requirements and performance characteristics for AI workloads. These technologies promise to reduce data movement overhead while providing specialized acceleration for neural network operations.
The integration of specialized AI accelerators with optimized memory subsystems continues to evolve, with new architectures designed specifically for large language model workloads. These developments promise to improve both memory efficiency and computational performance while reducing power consumption and total cost of ownership for AI infrastructure.
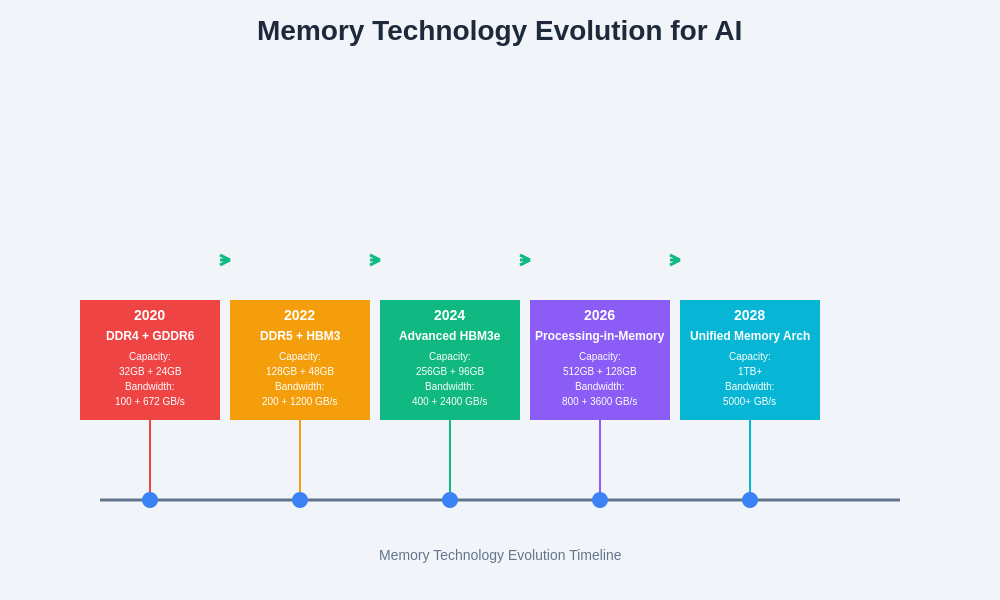
The evolution of memory technologies specifically designed for AI workloads demonstrates the industry’s commitment to addressing the unique requirements of large language models and other advanced AI applications.
Cost Analysis and Economic Considerations
The economic impact of memory requirements extends beyond initial hardware acquisition costs to encompass ongoing operational expenses and opportunity costs related to deployment constraints. VRAM costs per gigabyte typically exceed system RAM costs by factors of five to ten times, making memory optimization strategies critical for cost-effective deployment of large language models.
Cloud deployment strategies offer alternative approaches to hardware ownership, enabling access to high-end GPU resources without significant capital expenditure. However, the ongoing operational costs of cloud inference can exceed owned hardware costs for sustained high-utilization applications, necessitating detailed financial analysis based on specific usage patterns and performance requirements.
The relationship between model size, hardware requirements, and deployment costs creates complex optimization problems that require careful analysis of performance trade-offs, user experience requirements, and business objectives. Smaller, optimized models may provide better economic outcomes than larger models requiring expensive hardware, depending on specific application requirements and performance acceptability criteria.
Performance Monitoring and Optimization Strategies
Effective memory performance monitoring requires comprehensive instrumentation that tracks utilization patterns, allocation efficiency, and performance bottlenecks across both RAM and VRAM subsystems. Modern profiling tools provide detailed insights into memory access patterns, enabling identification of optimization opportunities and performance bottlenecks that may not be apparent through simple utilization monitoring.
Memory bandwidth utilization often represents a more critical performance metric than raw capacity utilization, as inefficient memory access patterns can result in significant performance degradation even when total memory usage appears acceptable. Optimizing for memory bandwidth requires careful attention to data layout, access patterns, and coordination between computational and memory operations.
Continuous optimization approaches enable dynamic adjustment of memory allocation strategies based on real-time performance monitoring and workload characteristics. These adaptive strategies can improve resource utilization while maintaining performance objectives across varying computational demands and model configurations.
Deployment Scenarios and Practical Recommendations
Different deployment scenarios present distinct memory requirement profiles that inform optimization strategies and hardware selection decisions. Edge deployment environments with constrained memory resources require aggressive optimization techniques and model compression strategies to achieve acceptable performance within hardware limitations. Cloud deployment environments may prioritize cost efficiency over absolute performance, leading to different optimization approaches and hardware selection criteria.
Development and research environments benefit from flexible memory allocation strategies that accommodate experimentation with different model architectures and hyperparameters. Production deployment environments prioritize consistent performance and resource utilization, requiring robust optimization strategies that maintain performance under varying load conditions.
The selection of appropriate deployment strategies requires comprehensive analysis of performance requirements, cost constraints, and operational considerations. Hybrid approaches that combine multiple optimization techniques often provide the best balance of performance, cost efficiency, and deployment flexibility for complex large language model applications.
Conclusion and Future Outlook
The memory requirements for large language models represent one of the most significant challenges in modern AI deployment, requiring sophisticated understanding of hardware architectures, optimization techniques, and cost trade-offs. The distinction between RAM and VRAM utilization patterns has become increasingly critical as model sizes continue to grow and deployment scenarios become more diverse and demanding.
Future developments in memory technology, optimization algorithms, and specialized AI hardware promise to address many current limitations while enabling new capabilities and deployment scenarios. The continued evolution of large language models will require ongoing adaptation of memory optimization strategies and hardware selection criteria to maintain cost-effective and performant AI deployments.
The successful deployment of large language models in production environments requires comprehensive consideration of memory requirements, optimization strategies, and hardware selection criteria. Organizations that develop expertise in these areas will be better positioned to leverage the capabilities of advanced AI systems while managing costs and performance trade-offs effectively.
Disclaimer
This article provides general information about AI memory requirements and hardware considerations for educational purposes. Memory requirements and performance characteristics can vary significantly based on specific model architectures, implementation details, and hardware configurations. Readers should conduct thorough testing and validation with their specific use cases and hardware environments. The rapidly evolving nature of AI hardware and optimization techniques means that specific recommendations may become outdated as new technologies emerge.