
The exponential growth of artificial intelligence model capabilities has created an unprecedented challenge in the field of machine learning deployment. While state-of-the-art models like GPT-4, Claude, and advanced computer vision networks deliver remarkable performance, their substantial computational requirements and memory footprints present significant obstacles when attempting to deploy these powerful systems on resource-constrained devices such as smartphones, IoT sensors, and edge computing platforms.
The democratization of AI technology depends heavily on our ability to bridge the gap between high-performance models developed in data centers and the practical limitations of everyday computing devices. Explore the latest AI optimization trends to understand how researchers and engineers are pushing the boundaries of efficient AI deployment across diverse hardware platforms.
Model compression represents a critical frontier in artificial intelligence research, encompassing a diverse array of sophisticated techniques designed to maintain model accuracy while dramatically reducing computational overhead, memory consumption, and energy requirements. This technological evolution enables the deployment of previously impossible AI applications directly on consumer devices, industrial sensors, autonomous vehicles, and embedded systems where cloud connectivity may be unreliable or where real-time processing demands cannot tolerate network latency.
The Imperative for Model Compression
The computational demands of modern AI models have grown exponentially over the past decade, with parameter counts increasing from millions to hundreds of billions. Large language models like GPT-3 contain 175 billion parameters and require substantial GPU clusters for inference, making them impractical for direct deployment on mobile devices or edge computing environments. Similarly, state-of-the-art computer vision models, advanced speech recognition systems, and multimodal AI architectures demand computational resources that far exceed the capabilities of typical consumer hardware.
This computational disparity has created a significant barrier to the widespread adoption of AI technology in scenarios where cloud-based processing is not feasible or desirable. Privacy-sensitive applications, real-time autonomous systems, remote monitoring devices, and applications operating in bandwidth-limited environments all require local AI processing capabilities. The challenge lies in preserving the sophisticated reasoning, pattern recognition, and decision-making capabilities of large models while adapting them to operate within the strict constraints of mobile processors, limited memory, and battery-powered operation.
The economic implications of this challenge extend beyond technical considerations. Cloud-based AI inference incurs ongoing operational costs that can become prohibitive for high-volume applications, while edge deployment eliminates recurring inference costs and reduces dependence on network infrastructure. Organizations seeking to deploy AI solutions at scale increasingly recognize that model compression techniques are essential for achieving cost-effective, scalable AI deployment strategies.
Quantization: Precision Engineering for Efficiency
Quantization represents one of the most effective and widely adopted approaches to model compression, fundamentally altering how neural networks represent and process numerical information. Traditional neural networks typically operate using 32-bit floating-point arithmetic, providing high precision but consuming substantial computational resources and memory bandwidth. Quantization techniques systematically reduce this numerical precision to 16-bit, 8-bit, or even lower bit-widths while maintaining acceptable model performance.
The mathematical principles underlying quantization involve mapping the continuous range of floating-point values to a discrete set of quantized representations. This process requires careful calibration to ensure that the most frequently used weight and activation ranges are represented with sufficient precision while allowing less critical values to be approximated with lower precision. Advanced quantization schemes employ non-uniform quantization distributions, adaptive bit allocation, and learned quantization parameters that optimize compression efficiency for specific model architectures and application domains.
Discover advanced AI compression tools with Claude for implementing sophisticated quantization strategies that maintain model accuracy while achieving significant performance improvements. The integration of quantization-aware training methodologies enables models to adapt to reduced precision during the training process, often achieving better compressed performance than post-training quantization approaches.
Dynamic quantization techniques further enhance efficiency by adapting precision levels based on the computational context and input characteristics. These approaches recognize that different layers, operations, and input patterns may benefit from different quantization strategies, enabling fine-grained optimization that balances accuracy preservation with computational efficiency. The result is compressed models that can achieve 4x to 8x reduction in model size and inference time while maintaining performance levels suitable for production deployment.
Neural Network Pruning: Surgical Model Reduction
Neural network pruning employs sophisticated analysis techniques to identify and eliminate redundant or minimally contributory parameters from trained models. This approach recognizes that deep neural networks typically exhibit significant over-parameterization, containing numerous connections and neurons that contribute minimally to overall model performance. By systematically removing these superfluous elements, pruning techniques can achieve substantial model compression while preserving essential computational pathways.
Structured pruning approaches operate at the level of entire neurons, filters, or channels, removing complete computational units and their associated connections. This methodology provides clear computational benefits by reducing the number of operations required during inference and simplifying the resulting network architecture. The challenge lies in accurately identifying which structural elements can be safely removed without significantly impacting model performance across diverse input scenarios.
Unstructured pruning techniques offer more granular control by removing individual weights or connections based on magnitude-based criteria, gradient information, or learned importance scores. While these approaches can achieve higher compression ratios, they often require specialized hardware support or software implementations to realize the theoretical computational savings. Recent advances in unstructured pruning have focused on developing hardware-aware pruning strategies that align compression patterns with the capabilities of target deployment platforms.
Iterative pruning methodologies combine gradual parameter removal with fine-tuning procedures, allowing models to adapt to the progressive reduction in capacity. This approach has proven particularly effective for achieving high compression ratios while maintaining model accuracy, as it enables the network to redistribute computational load across remaining parameters. The integration of pruning with other compression techniques, such as quantization and knowledge distillation, creates synergistic effects that maximize overall compression efficiency.
Knowledge Distillation: Transferring Wisdom to Compact Models
Knowledge distillation represents a sophisticated approach to model compression that focuses on transferring the learned representations and decision-making capabilities of large, complex models to smaller, more efficient architectures. This technique operates on the principle that much of the knowledge embedded in large models can be effectively captured by carefully designed smaller networks when provided with appropriate guidance during the training process.
The distillation process typically involves training a compact “student” model to mimic the behavior of a larger “teacher” model by matching not only the final predictions but also the intermediate representations, attention patterns, and feature maps generated throughout the network. This comprehensive knowledge transfer enables student models to achieve performance levels that would be difficult to attain through traditional training approaches alone, effectively compressing the expertise of large models into deployable architectures.
Advanced distillation techniques extend beyond simple output matching to include sophisticated alignment strategies that capture the relational knowledge, uncertainty estimates, and feature relationships learned by teacher models. Progressive distillation approaches gradually transfer knowledge through multiple stages, allowing student models to build understanding incrementally and achieve better compression-performance trade-offs. The integration of adversarial training principles into distillation frameworks further enhances the fidelity of knowledge transfer by encouraging student models to generate teacher-like representations across diverse input scenarios.
Multi-teacher distillation strategies leverage the complementary expertise of multiple large models to train student networks that benefit from diverse sources of knowledge. This approach has proven particularly effective in domains where different teacher models excel at different aspects of the task, enabling student models to capture a broader range of capabilities within a compact architecture. The result is efficient models that maintain much of the sophistication and accuracy of their larger counterparts while operating within the constraints of resource-limited deployment environments.
Hardware-Aware Optimization Strategies
The effectiveness of model compression techniques depends critically on alignment between compression strategies and the characteristics of target deployment hardware. Modern mobile processors, edge computing devices, and specialized AI accelerators each present unique computational capabilities, memory hierarchies, and optimization opportunities that must be considered when designing compressed models for optimal performance.
Mobile GPU architectures typically excel at parallel processing of grouped operations but may struggle with irregular memory access patterns or highly sparse computations. Compression strategies targeting mobile deployment must therefore prioritize techniques that maintain regular computational patterns while reducing overall operation counts. This often involves favoring structured pruning approaches over unstructured methods and implementing quantization schemes that align with native hardware data types and vector processing capabilities.
Specialized AI accelerators such as Neural Processing Units (NPUs) and Tensor Processing Units (TPUs) offer unique optimization opportunities through dedicated support for specific operation types, data formats, and memory access patterns. Compression techniques designed for these platforms can leverage hardware-specific features such as specialized quantization support, efficient sparse matrix operations, or optimized memory layouts to achieve superior performance compared to general-purpose processors.
Enhance your AI optimization research with Perplexity for comprehensive analysis of hardware platforms and their optimization requirements. The rapid evolution of AI hardware continues to create new opportunities for specialized compression approaches that maximize the capabilities of emerging computational architectures.
The development of hardware-aware compression frameworks has emerged as a critical research direction, enabling automated optimization of model compression strategies based on detailed profiling of target deployment platforms. These systems analyze hardware characteristics, measure actual performance metrics, and iteratively refine compression parameters to achieve optimal deployment configurations for specific device constraints and performance requirements.
Advanced Compression Architectures
Recent advances in neural architecture search and efficient model design have led to the development of architectures specifically optimized for compressed deployment scenarios. These approaches move beyond traditional compression techniques by fundamentally rethinking network design principles to create models that achieve excellent performance with inherently efficient computational characteristics.
MobileNet architectures employ depthwise separable convolutions to dramatically reduce computational complexity while maintaining representational capability. These designs recognize that traditional convolutional operations often involve significant redundancy and implement factorized operations that achieve similar functionality with substantially reduced parameter counts and computational requirements. The evolution of MobileNet designs through multiple generations has demonstrated consistent improvements in efficiency-accuracy trade-offs through architectural innovations.
EfficientNet families utilize compound scaling strategies that simultaneously optimize network depth, width, and resolution to achieve optimal performance within specified computational budgets. This approach recognizes that naive scaling of individual architectural dimensions often leads to suboptimal results and implements principled scaling strategies based on extensive empirical analysis. The resulting architectures achieve state-of-the-art efficiency across a wide range of computational constraints.
Transformer compression has become increasingly important as attention-based models dominate numerous AI applications. Techniques such as linear attention mechanisms, sparse attention patterns, and efficient positional encoding strategies enable the deployment of transformer-based models on resource-constrained devices. The development of distilled transformer architectures, such as DistilBERT and TinyBERT, demonstrates that much of the capability of large language models can be preserved in significantly more compact implementations.
Real-World Deployment Considerations
The practical deployment of compressed AI models involves numerous considerations beyond pure compression efficiency, including inference latency requirements, memory constraints, power consumption limitations, and thermal management challenges. Successful deployment strategies must balance these competing requirements while maintaining acceptable model performance across diverse operating conditions and input scenarios.
Inference latency optimization requires careful consideration of not only raw computational requirements but also memory access patterns, cache utilization, and parallelization opportunities. Compressed models that achieve excellent throughput in batch processing scenarios may exhibit poor latency characteristics when processing individual inputs, necessitating architecture-specific optimizations for real-time applications. The integration of dynamic inference techniques, such as early exit mechanisms and adaptive computation, enables models to adjust their computational complexity based on input difficulty and latency requirements.
Memory management strategies become critical when deploying compressed models on devices with limited RAM and storage capacity. Techniques such as weight sharing, parameter quantization, and efficient data layout optimization can significantly reduce memory footprints while maintaining model functionality. The development of streaming inference approaches enables the processing of large inputs that exceed device memory capacity by processing data in manageable chunks with minimal accuracy degradation.
Power consumption considerations are particularly important for battery-powered devices and energy-constrained environments. Compressed models must be optimized not only for computational efficiency but also for energy-efficient execution patterns that minimize battery drain and heat generation. This often involves trade-offs between model accuracy and power consumption that must be carefully balanced based on application requirements and device capabilities.
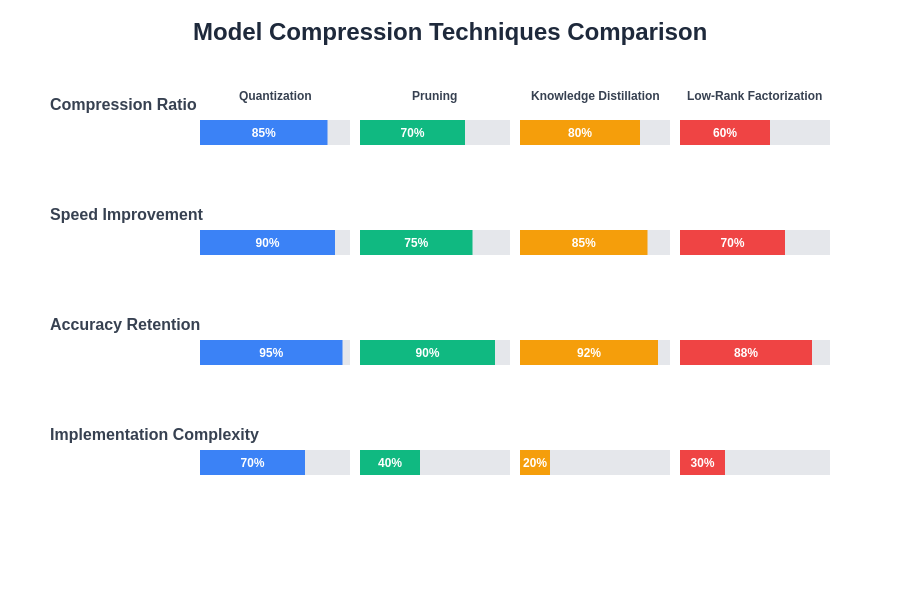
The landscape of model compression techniques offers diverse approaches with distinct advantages and trade-offs. Understanding the characteristics and optimal applications of each technique enables developers to select and combine compression strategies that best match their specific deployment requirements and performance objectives.
Framework Integration and Tooling
The practical implementation of model compression techniques has been significantly simplified through the development of comprehensive frameworks and tooling ecosystems that automate many aspects of the compression process. TensorFlow Lite provides extensive support for quantization, pruning, and optimization techniques specifically designed for mobile and edge deployment scenarios. The framework includes automated optimization pipelines, hardware-specific backends, and comprehensive profiling tools that streamline the deployment process.
PyTorch Mobile offers similar capabilities with strong integration into the broader PyTorch ecosystem, enabling seamless transitions from research prototypes to optimized deployment configurations. The framework supports dynamic quantization, static quantization, and quantization-aware training workflows that can be easily integrated into existing model development pipelines. Advanced features such as selective quantization and custom operator support provide flexibility for specialized compression requirements.
ONNX Runtime has emerged as a platform-agnostic solution for deploying compressed models across diverse hardware environments. The runtime includes optimization passes, execution providers for specialized hardware, and comprehensive profiling capabilities that enable efficient deployment across CPU, GPU, and dedicated AI accelerator platforms. The standardized ONNX format facilitates interoperability between different compression tools and deployment frameworks.
Specialized compression frameworks such as Neural Compressor, Brevitas, and TensorRT provide advanced capabilities for specific compression techniques and hardware platforms. These tools often offer more sophisticated optimization strategies and fine-grained control over compression parameters, enabling expert users to achieve superior compression results for challenging deployment scenarios.
Performance Benchmarking and Evaluation
Comprehensive evaluation of compressed models requires sophisticated benchmarking methodologies that assess not only accuracy preservation but also computational efficiency, memory utilization, energy consumption, and deployment-specific performance characteristics. Traditional accuracy metrics provide only partial insight into the effectiveness of compression techniques, necessitating broader evaluation frameworks that capture the full spectrum of deployment considerations.
Latency benchmarking must account for the specific characteristics of target deployment hardware, including warm-up effects, batch size dependencies, and variability across different input types. Real-world latency measurements often reveal significant discrepancies from theoretical computational complexity estimates, highlighting the importance of empirical evaluation on actual deployment hardware. The development of standardized benchmarking suites enables consistent comparison of compression techniques across different research groups and commercial implementations.
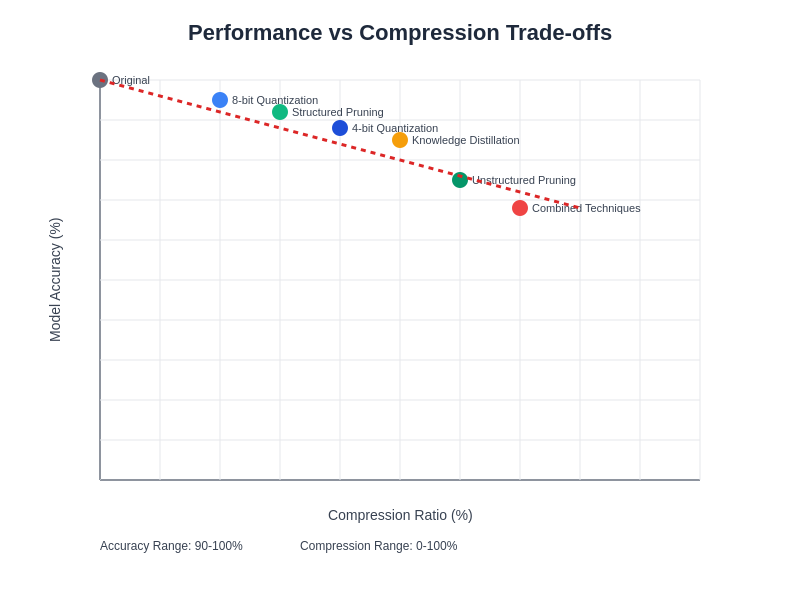
The relationship between compression ratio and performance preservation varies significantly across different model architectures, datasets, and compression techniques. Understanding these trade-offs enables informed decision-making when selecting compression strategies for specific applications and performance requirements.
Energy efficiency evaluation has become increasingly important for battery-powered and energy-constrained applications. Comprehensive energy profiling requires measurement of not only computational energy consumption but also memory access costs, data movement overhead, and thermal management requirements. The development of energy-aware compression metrics enables optimization strategies that prioritize overall system efficiency rather than purely computational performance.
Emerging Trends and Future Directions
The field of model compression continues to evolve rapidly, with emerging techniques pushing the boundaries of what is possible in terms of compression efficiency and performance preservation. Neural architecture search techniques are being applied to discover compression-optimized architectures that achieve superior efficiency-accuracy trade-offs compared to manually designed compression approaches. These automated discovery methods promise to unlock new compression strategies that may not be apparent through traditional analytical approaches.
Mixed-precision training and inference techniques are becoming increasingly sophisticated, with learned precision assignment strategies that optimize bit-width allocation based on layer sensitivity, input characteristics, and hardware capabilities. The integration of hardware-specific precision optimizations enables compression techniques to fully exploit the capabilities of modern AI accelerators and specialized computing platforms.
Federated compression approaches address the unique challenges of deploying AI models across distributed edge computing environments where communication constraints, privacy requirements, and heterogeneous hardware capabilities create complex optimization challenges. These techniques enable collaborative model compression strategies that adapt to local device constraints while maintaining global model performance.
The integration of compression techniques with continual learning and model adaptation capabilities represents an emerging research direction that addresses the challenge of maintaining compressed model performance as data distributions evolve over time. These approaches enable deployed models to adapt their compression strategies based on observed performance characteristics and changing computational requirements.
Industry Applications and Case Studies
The practical impact of model compression techniques can be observed across numerous industry applications where the deployment of AI capabilities on resource-constrained devices has created significant business value. Autonomous vehicle systems require real-time processing of sensor data using computer vision models that must operate within strict latency and power consumption constraints while maintaining safety-critical accuracy levels. Compression techniques enable the deployment of sophisticated perception models on automotive computing platforms that would otherwise lack sufficient computational capacity.
Mobile photography applications demonstrate the consumer impact of model compression through features such as computational photography, real-time image enhancement, and intelligent scene recognition. The deployment of advanced image processing models directly on smartphone hardware has been made possible through careful application of quantization, pruning, and architecture optimization techniques that maintain image quality while operating within mobile hardware constraints.
Industrial IoT applications leverage compressed AI models for predictive maintenance, quality control, and process optimization in environments where cloud connectivity may be unreliable or where real-time decision-making is critical. The deployment of anomaly detection models, predictive analytics, and control optimization algorithms on edge computing devices has enabled new categories of industrial automation that were previously impractical due to computational limitations.
Healthcare applications utilize compressed AI models for medical imaging analysis, patient monitoring, and diagnostic assistance in settings where privacy requirements, real-time processing needs, and resource constraints intersect. The deployment of medical AI capabilities directly on imaging devices, wearable sensors, and portable diagnostic equipment has expanded access to advanced healthcare technologies while maintaining patient privacy and reducing operational costs.
Security and Privacy Implications
The deployment of compressed AI models introduces unique security and privacy considerations that must be carefully addressed in production environments. Model compression techniques can potentially alter the attack surface and vulnerability profile of AI systems, requiring comprehensive security analysis and mitigation strategies. Adversarial robustness may be affected by compression processes, necessitating evaluation of compressed models against relevant threat models and attack vectors.
Privacy-preserving compression techniques have emerged as an important research direction, particularly for applications where sensitive data or proprietary model architectures must be protected. Techniques such as differential privacy integration, secure multi-party computation, and homomorphic encryption compatibility enable compression strategies that maintain privacy guarantees while achieving deployment efficiency objectives.
The integration of compression techniques with federated learning systems creates opportunities for privacy-preserving model deployment while also introducing new challenges related to model consistency, security verification, and collaborative optimization. These approaches enable the deployment of personalized AI capabilities while maintaining data privacy and reducing communication overhead in distributed systems.
Conclusion and Strategic Considerations
The field of AI model compression has matured into a critical enabler for the widespread deployment of artificial intelligence capabilities across diverse computing environments and application domains. The sophisticated techniques and comprehensive tooling ecosystems now available enable organizations to deploy previously impractical AI applications while maintaining acceptable performance characteristics and operational efficiency.
The strategic implications of model compression extend beyond purely technical considerations to encompass business model opportunities, competitive advantages, and market differentiation strategies. Organizations that effectively leverage compression techniques can deploy AI capabilities in scenarios where competitors cannot, creating unique value propositions and market positioning opportunities.
The continued evolution of compression techniques, hardware capabilities, and deployment frameworks promises to further expand the possibilities for edge AI deployment while maintaining the sophisticated capabilities that make modern AI systems valuable. The intersection of compression research with emerging technologies such as neuromorphic computing, quantum-inspired algorithms, and advanced hardware architectures will likely create new categories of efficient AI systems that push the boundaries of what is possible in resource-constrained environments.
As the field continues to advance, the integration of compression techniques with broader AI development workflows will become increasingly seamless, enabling developers to create efficient, deployable AI solutions without requiring deep expertise in optimization techniques. This democratization of compression capabilities will accelerate the adoption of edge AI technologies and expand the impact of artificial intelligence across numerous application domains and use cases.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of AI model compression technologies and their applications. Readers should conduct their own research and consider their specific requirements when implementing model compression techniques. The effectiveness of compression methods may vary depending on specific model architectures, hardware platforms, and application requirements. Performance claims and optimization results may not be representative of all use cases or deployment scenarios.