
The deployment of machine learning models into production environments represents only the beginning of a complex journey that requires continuous vigilance and sophisticated monitoring systems. As data patterns evolve, user behaviors shift, and real-world conditions change, even the most meticulously trained models can experience performance degradation through a phenomenon known as model drift. This critical challenge in production machine learning demands comprehensive detection strategies, robust monitoring frameworks, and proactive mitigation approaches to ensure consistent AI performance and reliability over extended operational periods.
Stay updated with the latest AI monitoring trends to understand emerging techniques and best practices for maintaining production ML systems. The complexity of modern AI deployments necessitates sophisticated approaches to drift detection that go far beyond simple accuracy tracking, encompassing statistical analysis, behavioral monitoring, and predictive alerting systems that can identify potential issues before they impact business outcomes.
Understanding the Nature of Model Drift
Model drift encompasses several distinct phenomena that can collectively degrade machine learning performance in production environments. Data drift occurs when the statistical properties of input features change over time, potentially rendering training data less representative of current conditions. Concept drift manifests when the underlying relationships between features and target variables evolve, causing models to make predictions based on outdated patterns. Prediction drift reflects changes in the distribution of model outputs, while label drift involves shifts in the target variable distribution that may not be immediately apparent in unlabeled production data.
The subtle and often gradual nature of these drift types makes detection particularly challenging, as performance degradation may occur slowly enough to avoid immediate attention while accumulating substantial impact over extended periods. Understanding these different drift manifestations enables organizations to implement targeted monitoring strategies that can identify specific types of degradation and trigger appropriate remediation responses.
The interconnected nature of drift types means that organizations must adopt holistic monitoring approaches that can detect multiple forms of degradation simultaneously while distinguishing between temporary fluctuations and sustained shifts that require intervention. This comprehensive understanding forms the foundation for effective drift detection systems that can maintain model performance in dynamic production environments.
Statistical Foundations of Drift Detection
Effective drift detection relies on robust statistical methods that can identify meaningful changes in data distributions while minimizing false alarms from normal variation. Population Stability Index (PSI) provides a fundamental approach for measuring differences between training and production data distributions, offering quantitative thresholds that can trigger automated alerts when drift exceeds acceptable levels. The Kolmogorov-Smirnov test enables comparison of continuous feature distributions, while chi-square tests serve similar purposes for categorical variables.
Jensen-Shannon divergence offers a symmetric measure of distribution similarity that proves particularly valuable for comparing complex, multi-dimensional data distributions common in modern AI applications. Wasserstein distance provides another powerful metric that captures both distributional shape and location differences, offering insights into the magnitude and nature of observed shifts.
Enhance your ML monitoring with advanced AI tools like Claude to implement sophisticated statistical analysis and automated drift detection systems. The selection and combination of appropriate statistical measures depends heavily on data characteristics, model architecture, and business requirements, necessitating careful consideration of detection sensitivity, computational efficiency, and interpretability requirements.
Implementing Comprehensive Monitoring Frameworks
Production ML monitoring requires sophisticated frameworks that can continuously evaluate model performance across multiple dimensions while providing actionable insights for remediation. Feature-level monitoring tracks individual input variables for distributional changes, enabling identification of specific data sources or collection processes that may be contributing to drift. Model output monitoring examines prediction distributions and confidence scores to identify behavioral changes that may not be apparent from input analysis alone.
Performance metric tracking provides direct insight into model effectiveness through accuracy, precision, recall, and domain-specific metrics that reflect business objectives. However, this approach faces challenges in scenarios where ground truth labels are delayed or unavailable, necessitating proxy metrics and indirect performance indicators that can provide early warning signals.
Business impact monitoring extends beyond traditional ML metrics to track downstream effects on key performance indicators, customer satisfaction, and operational efficiency. This holistic approach ensures that technical drift detection aligns with practical business outcomes and enables prioritization of remediation efforts based on actual impact rather than purely statistical significance.
Advanced Detection Techniques and Algorithms
Modern drift detection leverages sophisticated algorithms that can identify subtle patterns and relationships that traditional statistical methods might miss. Multivariate drift detection techniques examine relationships between multiple features simultaneously, capturing complex interdependencies that univariate approaches cannot detect. Dimensionality reduction methods such as Principal Component Analysis (PCA) and t-SNE enable visualization and analysis of high-dimensional data spaces, revealing drift patterns that may be obscured in individual feature analysis.
Machine learning-based drift detectors utilize trained models to distinguish between training and production data distributions, providing learned representations that can capture complex, non-linear relationships. These approaches can adapt to specific data characteristics and model architectures, offering more nuanced detection capabilities than generic statistical tests.
Time-series analysis techniques enable detection of temporal patterns in drift, distinguishing between cyclical variations, seasonal effects, and genuine distributional shifts. These methods prove particularly valuable in applications where data naturally exhibits periodic behavior, preventing false alarms while maintaining sensitivity to meaningful changes.
Real-Time Monitoring and Alert Systems
Production environments demand real-time monitoring capabilities that can detect drift as it occurs and trigger immediate response mechanisms. Stream processing frameworks enable continuous analysis of incoming data, computing drift metrics in near real-time and maintaining rolling statistics that can identify both sudden shifts and gradual changes over extended periods.
Alert systems must balance sensitivity with practicality, providing timely notifications of significant drift while avoiding alert fatigue from minor fluctuations. Multi-threshold approaches enable escalating response protocols, with minor drift triggering monitoring increases and severe drift initiating automatic model retraining or fallback procedures.
Leverage Perplexity’s research capabilities to stay informed about cutting-edge drift detection methodologies and monitoring tools. Integration with existing DevOps and MLOps pipelines ensures that drift detection becomes a seamless component of production ML workflows, enabling automated responses and maintaining system reliability without requiring constant manual intervention.
Data Quality and Preprocessing Monitoring
Data quality degradation represents a common source of apparent model drift that may not reflect genuine distributional changes but rather issues in data collection, preprocessing, or feature engineering pipelines. Monitoring data completeness, accuracy, and consistency provides essential context for interpreting drift signals and distinguishing between genuine model degradation and data quality issues.
Feature engineering pipeline monitoring tracks the behavior of transformation steps, aggregations, and derived features that may be sensitive to upstream changes. This monitoring proves particularly important in complex data processing workflows where multiple transformation steps can amplify or mask underlying drift signals.
Data lineage tracking enables rapid identification of drift sources by maintaining comprehensive records of data sources, processing steps, and transformation history. This capability proves invaluable when investigating drift incidents and implementing targeted remediation strategies that address root causes rather than symptoms.
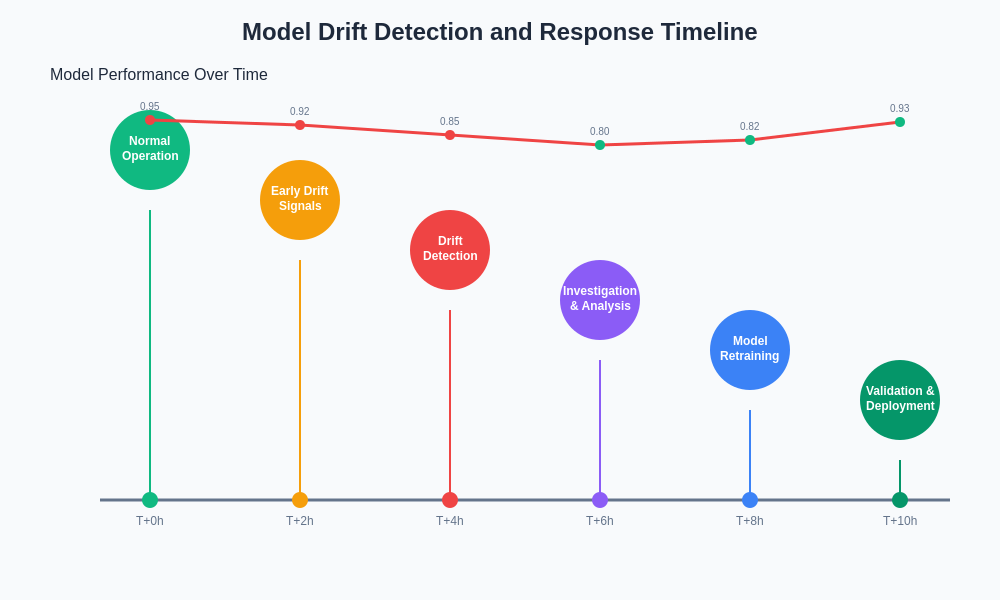
The progression of model drift detection and response involves multiple stages from initial signal identification through investigation, remediation, and validation. Understanding this timeline enables organizations to implement proactive monitoring strategies that can identify issues early and minimize business impact through rapid response protocols.
Model Retraining and Adaptation Strategies
Effective drift mitigation requires sophisticated retraining strategies that can adapt models to changing conditions while maintaining stability and performance. Incremental learning approaches enable continuous model updates using new data while preserving knowledge from historical training, avoiding the computational overhead and potential disruption of complete retraining cycles.
Online learning algorithms can adapt to drift in real-time, updating model parameters as new data arrives and automatically adjusting to changing patterns. However, these approaches require careful implementation to prevent catastrophic forgetting and maintain model stability in the face of noisy or adversarial inputs.
Ensemble methods provide robust approaches to drift adaptation by maintaining multiple models trained on different time periods or data subsets, enabling dynamic weighting based on current performance and drift indicators. This approach provides natural fallback mechanisms and can maintain performance even when individual component models experience degradation.
Business Impact Assessment and Prioritization
Not all drift represents equal business risk, necessitating sophisticated frameworks for assessing and prioritizing remediation efforts based on actual impact rather than purely statistical significance. Revenue impact analysis examines how drift affects key business metrics, customer satisfaction, and operational efficiency, enabling cost-benefit analysis of different remediation approaches.
User experience monitoring tracks how drift affects customer interactions, conversion rates, and satisfaction metrics, providing direct insight into the practical consequences of model degradation. This monitoring proves particularly important in customer-facing applications where performance issues can have immediate and measurable business consequences.
Risk assessment frameworks evaluate potential downstream effects of continued drift, considering factors such as regulatory compliance, safety implications, and competitive positioning. This holistic approach ensures that organizations allocate resources appropriately and maintain focus on the most critical drift scenarios.
Regulatory Compliance and Governance
Production ML systems increasingly operate under regulatory oversight that demands comprehensive monitoring, documentation, and explainability capabilities. Model drift detection becomes a critical component of compliance frameworks, providing evidence of ongoing model validation and performance monitoring that regulatory bodies increasingly require.
Audit trails and documentation systems must capture drift detection activities, remediation decisions, and performance outcomes to support regulatory reporting and compliance verification. This documentation serves multiple purposes, supporting both compliance requirements and internal process improvement initiatives.
Explainability and interpretability requirements extend to drift detection systems themselves, necessitating clear documentation of detection methods, threshold selection, and alert criteria that can be understood and validated by both technical teams and regulatory auditors.
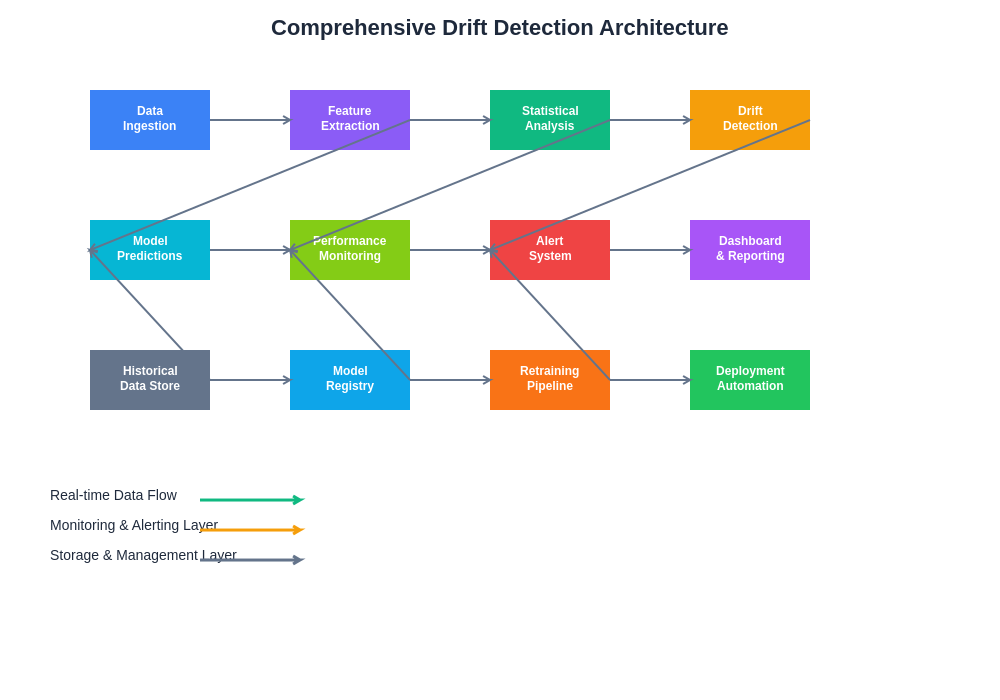
A comprehensive drift detection architecture encompasses multiple monitoring layers, from real-time data ingestion through statistical analysis, alert generation, and remediation workflows. This systematic approach ensures thorough coverage of potential drift sources while maintaining operational efficiency and minimizing false alerts.
Advanced Visualization and Dashboard Design
Effective drift monitoring requires sophisticated visualization capabilities that can present complex statistical information in actionable formats for different stakeholder audiences. Executive dashboards must distill drift information into business-relevant metrics and trends that support strategic decision-making without requiring deep technical knowledge.
Technical dashboards provide detailed drift metrics, statistical test results, and diagnostic information that enable data scientists and ML engineers to investigate issues, validate detection results, and implement appropriate remediation strategies. These interfaces must balance comprehensiveness with usability, presenting large amounts of information in organized, intuitive formats.
Historical trend analysis and comparative visualizations enable identification of patterns, seasonal effects, and long-term trends that inform both detection threshold tuning and strategic planning for model lifecycle management. These capabilities prove essential for understanding drift patterns and improving detection accuracy over time.
Integration with MLOps and DevOps Pipelines
Modern production ML environments require seamless integration between drift detection systems and broader MLOps and DevOps workflows. Continuous integration and deployment pipelines must incorporate drift monitoring as a standard component, ensuring that model updates and deployments include appropriate monitoring capabilities.
Automated remediation workflows can respond to drift detection by triggering retraining processes, deploying fallback models, or escalating issues to human operators based on predefined criteria and business rules. This automation reduces response times and ensures consistent handling of drift incidents.
Version control and model registry integration ensures that drift detection results are properly documented and associated with specific model versions, enabling traceability and supporting rollback procedures when remediation efforts prove unsuccessful.
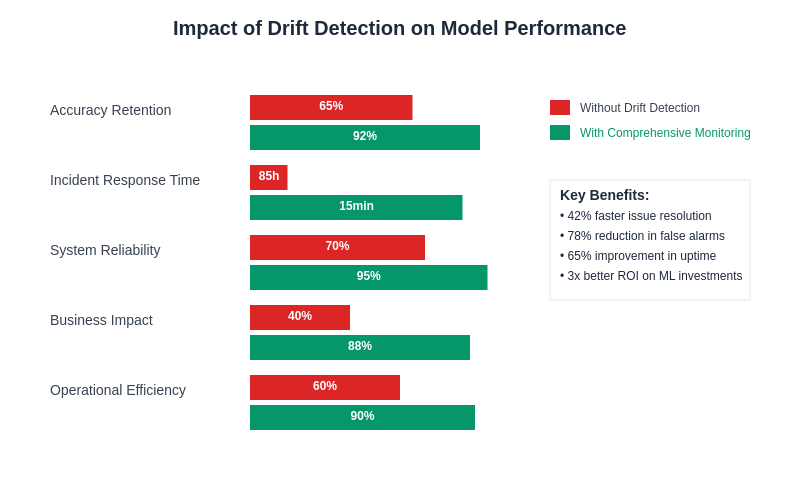
The quantitative impact of effective drift detection on model performance demonstrates substantial improvements in accuracy retention, incident response times, and overall system reliability. Organizations implementing comprehensive monitoring show significantly better long-term performance stability compared to reactive approaches.
Future Directions and Emerging Technologies
The evolution of drift detection continues with advances in automated machine learning, federated learning, and edge computing that present new challenges and opportunities for production ML monitoring. AutoML systems require sophisticated drift detection that can adapt to automatically generated model architectures and feature engineering pipelines.
Federated learning environments introduce distributed drift detection challenges where model performance may vary across different data sources and participant organizations. These scenarios require novel approaches that can identify local drift while maintaining privacy and security constraints.
Edge computing deployments face unique monitoring challenges due to resource constraints and connectivity limitations, necessitating lightweight drift detection methods that can operate with minimal computational overhead while maintaining detection accuracy.
The integration of drift detection with broader AI governance and responsible AI initiatives represents an important evolution that aligns technical monitoring with ethical considerations and societal impact assessment. This convergence ensures that drift detection supports not only technical performance but also fairness, transparency, and accountability objectives that are increasingly important in AI deployment.
Conclusion and Best Practices
Effective AI model drift detection requires comprehensive approaches that combine statistical rigor with practical implementation considerations, business impact assessment, and organizational integration. The most successful implementations adopt multi-layered monitoring strategies that can detect different types of drift while providing actionable insights for remediation and prevention.
Organizations must balance detection sensitivity with operational practicality, implementing alert systems that provide timely notification of significant issues without overwhelming technical teams with false alarms or minor fluctuations. This balance requires careful threshold tuning, statistical method selection, and ongoing refinement based on operational experience and business requirements.
The future of production ML reliability depends on sophisticated drift detection capabilities that can adapt to evolving AI technologies while maintaining robust performance monitoring and automated response capabilities. Organizations that invest in comprehensive drift detection frameworks will be better positioned to maintain competitive advantages through reliable AI systems that continue performing effectively as conditions change and evolve over time.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of AI model drift detection and monitoring practices. Readers should conduct their own research and consider their specific requirements when implementing drift detection systems. The effectiveness of monitoring approaches may vary depending on specific use cases, data characteristics, and organizational constraints.