
The reliability and robustness of machine learning systems depend fundamentally on comprehensive testing strategies that extend far beyond traditional software testing paradigms. Unlike conventional applications where deterministic outputs can be predicted and verified, machine learning pipelines introduce probabilistic behaviors, data dependencies, and model complexities that require specialized testing approaches. The implementation of rigorous unit testing frameworks for AI models has become essential for ensuring production-ready systems that maintain consistent performance across diverse operational conditions.
Explore the latest AI testing methodologies to understand emerging trends and best practices that are shaping the future of machine learning quality assurance. The evolution of AI model testing represents a critical intersection where software engineering principles meet statistical validation requirements, creating new paradigms for ensuring system reliability and performance consistency.
Foundations of Machine Learning Testing
Machine learning testing encompasses multiple dimensions that traditional software testing frameworks rarely address. The complexity begins with data validation, where input datasets must be continuously monitored for distribution shifts, missing values, outliers, and schema changes that could significantly impact model performance. Unlike conventional software where inputs are typically well-defined and predictable, machine learning systems must handle dynamic, real-world data that constantly evolves and presents new challenges to model stability and accuracy.
The testing pyramid for machine learning systems extends the traditional concept by incorporating data tests, model tests, and integration tests that specifically address the unique characteristics of AI systems. Data tests validate input quality, feature engineering correctness, and preprocessing pipeline integrity. Model tests evaluate prediction accuracy, bias detection, fairness metrics, and performance consistency across different data segments. Integration tests ensure that the entire machine learning pipeline functions correctly within the broader system architecture while maintaining expected service levels and response times.
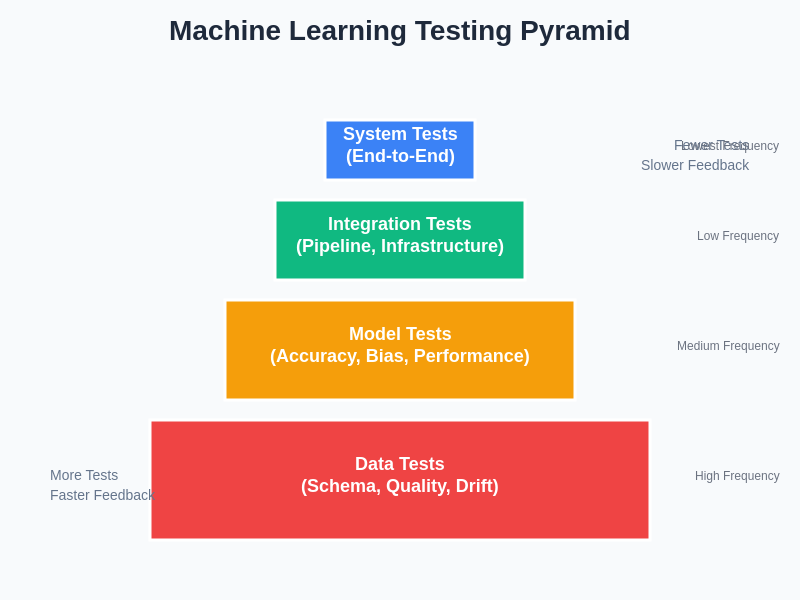
This hierarchical approach to machine learning testing ensures comprehensive coverage while maintaining efficiency in the testing process. The pyramid structure reflects both the frequency of test execution and the scope of validation, with data tests forming the foundation through their high frequency and rapid feedback capabilities.
The probabilistic nature of machine learning models introduces additional complexity to testing strategies. Traditional unit tests typically verify that specific inputs produce exact outputs, but machine learning models generate probability distributions, confidence intervals, and predictions that may vary within acceptable ranges. This fundamental difference requires testing frameworks that can validate statistical properties, distribution characteristics, and performance metrics rather than exact matches between expected and actual outputs.
Data Pipeline Testing Strategies
Data quality represents the foundation upon which all machine learning models build their predictions, making comprehensive data pipeline testing absolutely critical for system reliability. Data validation tests must verify schema compliance, ensuring that incoming data matches expected formats, data types, and structural requirements. These tests should detect missing columns, unexpected data types, null value patterns, and schema evolution that could break downstream model processing.
Statistical validation forms another crucial component of data pipeline testing, where tests continuously monitor data distributions to detect drift, outliers, and anomalous patterns that could indicate data quality issues or underlying system problems. Distribution tests compare current data batches against historical baselines to identify significant changes that might require model retraining or pipeline adjustments. Range validation ensures that numerical features fall within expected boundaries, while categorical validation verifies that discrete features contain only valid values from predefined sets.
Leverage advanced AI tools like Claude for designing sophisticated data validation frameworks that can automatically generate comprehensive test suites based on data characteristics and model requirements. The integration of AI-powered testing tools enables more intelligent validation strategies that adapt to changing data patterns while maintaining robust quality assurance standards.
Feature engineering pipeline tests focus on transformation correctness, ensuring that data preprocessing steps produce expected outputs and maintain data integrity throughout the transformation process. These tests validate scaling operations, encoding procedures, feature selection logic, and aggregation functions that prepare raw data for model consumption. Transformation tests should verify that feature engineering steps produce consistent results across different data batches while preserving the statistical properties necessary for model performance.
Model Validation and Performance Testing
Model validation testing encompasses multiple evaluation dimensions that assess both technical performance and business relevance of machine learning predictions. Accuracy tests evaluate fundamental model performance using appropriate metrics for specific problem types, including classification accuracy, precision, recall, F1-scores for classification tasks, and mean absolute error, root mean square error, and R-squared values for regression problems. These tests establish baseline performance expectations and trigger alerts when model accuracy degrades beyond acceptable thresholds.
Bias and fairness testing has emerged as a critical component of responsible AI development, requiring systematic evaluation of model behavior across different demographic groups, geographic regions, and other sensitive attributes. Fairness tests measure disparate impact, equalized odds, and demographic parity to ensure that models do not systematically discriminate against protected classes or exhibit unintended biases that could result in harmful outcomes.
Robustness testing evaluates model stability under various conditions, including adversarial inputs, edge cases, and unusual data patterns that models might encounter in production environments. These tests assess model behavior when presented with out-of-distribution inputs, missing features, or corrupted data to ensure graceful degradation rather than catastrophic failures.
Performance regression tests establish benchmarks for model behavior over time, comparing current model performance against historical baselines to detect performance degradation that might indicate data drift, model decay, or infrastructure issues. These tests should include both overall performance metrics and segment-specific evaluations that can identify performance issues affecting particular user groups or use cases.
Infrastructure and Integration Testing
The infrastructure supporting machine learning pipelines requires specialized testing approaches that address the unique requirements of AI workloads, including computational resource management, scalability characteristics, and fault tolerance capabilities. Load testing evaluates system performance under various traffic patterns, ensuring that machine learning services can handle expected request volumes while maintaining acceptable response times and resource utilization levels.
Scalability tests assess how machine learning systems perform as data volumes, model complexity, and user demand increase over time. These tests should evaluate both vertical scaling capabilities, such as utilizing more powerful hardware resources, and horizontal scaling approaches, including distributed training and inference across multiple nodes.
Enhance your testing capabilities with Perplexity’s research tools to stay updated on the latest infrastructure testing methodologies and best practices for ML systems. The rapid evolution of machine learning infrastructure requires continuous learning and adaptation of testing strategies to address emerging challenges and opportunities.
Fault tolerance testing evaluates system behavior under various failure conditions, including network partitions, hardware failures, and service dependencies becoming unavailable. Machine learning systems must gracefully handle these situations while maintaining data integrity and providing meaningful error responses to downstream consumers.
Integration testing validates the interaction between machine learning components and external systems, including databases, APIs, monitoring systems, and user interfaces. These tests ensure that data flows correctly through the entire pipeline, that model predictions are properly formatted and transmitted, and that error handling mechanisms function correctly across system boundaries.
Automated Testing Frameworks and Tools
The complexity and scale of modern machine learning systems necessitate automated testing frameworks that can continuously validate system behavior without manual intervention. Continuous integration and continuous deployment practices for machine learning require specialized tools that understand the unique characteristics of AI workflows, including model training cycles, data dependency management, and performance validation requirements.
Testing frameworks specifically designed for machine learning, such as Great Expectations for data validation, MLflow for experiment tracking and model registry, and TensorFlow Extended for end-to-end ML pipeline orchestration, provide comprehensive solutions for automated testing and validation. These tools integrate with existing CI/CD pipelines while providing ML-specific functionality for data validation, model evaluation, and deployment verification.
Custom testing frameworks often become necessary for organizations with specific requirements or unique machine learning architectures. These frameworks should incorporate domain-specific validation logic, business rule verification, and performance benchmarks that align with organizational objectives and regulatory requirements.
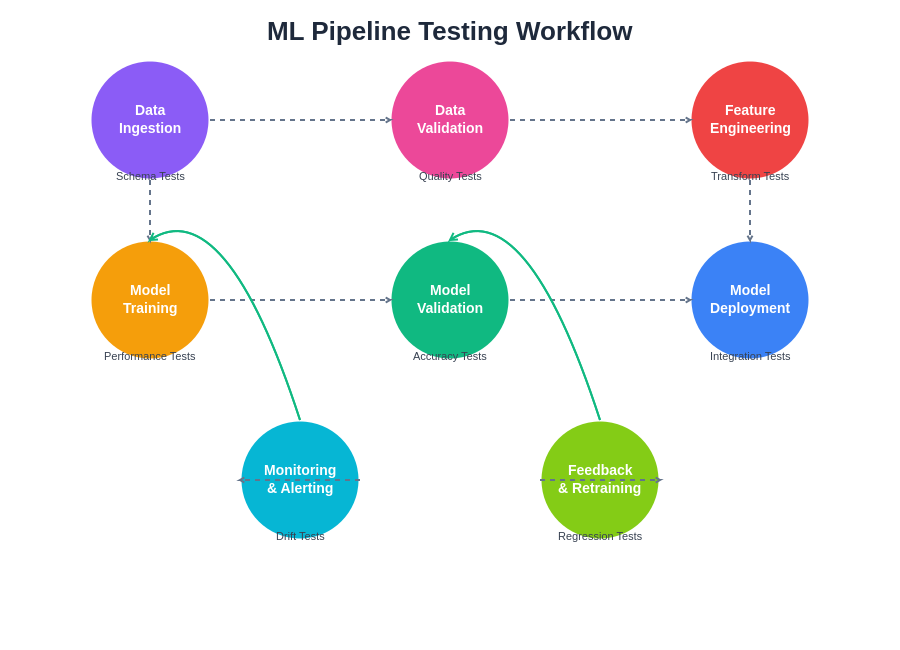
The comprehensive testing workflow illustrates the interconnected nature of machine learning pipeline validation, where each stage requires specific testing approaches while maintaining continuity across the entire system. This workflow ensures that quality assurance measures are integrated throughout the development and deployment lifecycle.
Monitoring and alerting systems form an integral part of automated testing infrastructure, providing real-time feedback on system health, model performance, and data quality issues. These systems should integrate with existing observability platforms while providing ML-specific metrics and alerts that enable rapid response to emerging issues.
Data Drift and Model Monitoring
Data drift detection represents one of the most critical ongoing testing requirements for machine learning systems, as models trained on historical data may become less accurate when applied to evolving real-world conditions. Statistical tests for drift detection compare current data distributions against training data or recent historical baselines to identify significant changes that might impact model performance.
Distribution-based drift detection methods analyze feature distributions using statistical tests such as the Kolmogorov-Smirnov test, Anderson-Darling test, or Population Stability Index to quantify the magnitude of distribution changes. These methods provide quantitative measures of drift that can trigger automated responses, including model retraining, feature engineering adjustments, or human intervention requirements.
Model performance monitoring extends beyond simple accuracy metrics to include business-relevant indicators that reflect the real-world impact of model predictions. These metrics might include conversion rates, user engagement measures, revenue impact, or customer satisfaction scores that provide context for technical performance metrics.
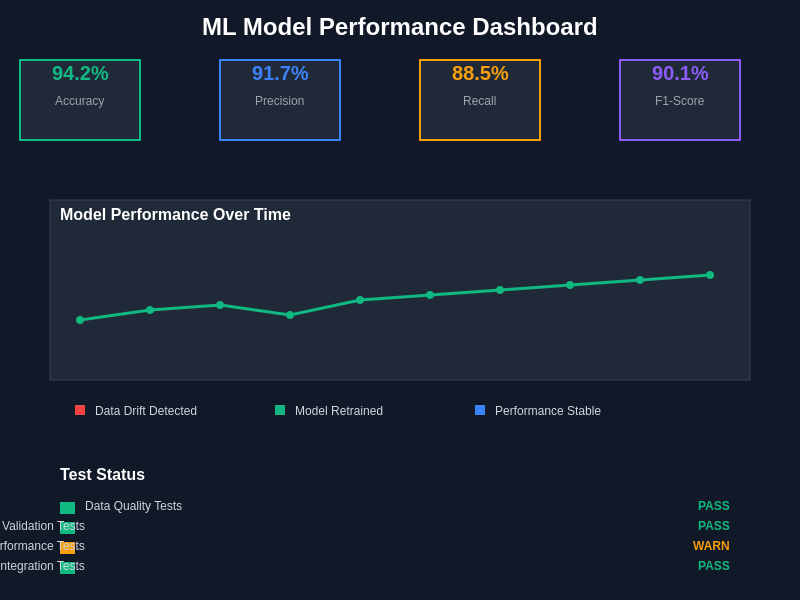
Real-time monitoring dashboards provide comprehensive visibility into model performance, test results, and system health indicators that enable proactive identification and resolution of issues before they impact production systems. These dashboards integrate multiple data sources to present a holistic view of machine learning system performance.
Concept drift detection addresses changes in the underlying relationships between features and target variables, which can occur even when feature distributions remain stable. These changes require more sophisticated detection methods that analyze model residuals, prediction confidence intervals, and error patterns to identify when retraining becomes necessary.
Security and Privacy Testing
Machine learning systems introduce unique security vulnerabilities that require specialized testing approaches, including adversarial attack resistance, data privacy protection, and model intellectual property security. Security testing for AI systems must address both traditional cybersecurity concerns and ML-specific vulnerabilities such as model inversion attacks, membership inference attacks, and adversarial examples.
Privacy testing ensures that machine learning models do not inadvertently leak sensitive information about training data or individual users. Differential privacy testing validates that models provide appropriate privacy guarantees while maintaining acceptable utility levels. These tests should verify that model outputs do not reveal information about specific individuals in training datasets.
Adversarial testing evaluates model robustness against intentionally crafted inputs designed to cause misclassification or unexpected behavior. These tests should cover various attack methodologies, including gradient-based attacks, optimization-based attacks, and decision-based attacks that might be employed by malicious actors.
Data anonymization and pseudonymization testing verifies that data protection measures function correctly throughout the machine learning pipeline, ensuring that sensitive information cannot be recovered from processed data or model outputs.
Regulatory Compliance and Audit Testing
Regulatory compliance testing for machine learning systems addresses industry-specific requirements and emerging AI governance frameworks that mandate transparency, explainability, and fairness in algorithmic decision-making. These tests must validate that models meet regulatory standards while maintaining detailed audit trails that demonstrate compliance with relevant regulations.
Explainability testing ensures that machine learning models can provide meaningful explanations for their decisions, particularly in high-stakes applications such as healthcare, finance, and criminal justice. These tests validate that explanation methods produce consistent, accurate, and interpretable results that meet regulatory and business requirements.
Documentation and lineage testing verifies that comprehensive records exist for all aspects of the machine learning lifecycle, including data sources, model development processes, validation procedures, and deployment decisions. These records must be sufficient to support regulatory audits and internal governance requirements.
Model governance testing ensures that appropriate approvals, reviews, and oversight mechanisms function correctly throughout the model development and deployment lifecycle. These tests validate that models undergo proper review processes and that deployment decisions align with organizational risk management policies.
Performance Optimization and Scaling
Performance testing for machine learning systems encompasses multiple dimensions, including inference latency, throughput capacity, resource utilization efficiency, and cost optimization across various deployment scenarios. Latency testing evaluates response times under different load conditions to ensure that models meet service level agreements and user experience expectations.
Throughput testing assesses the maximum request volume that machine learning systems can handle while maintaining acceptable performance levels. These tests should evaluate both steady-state performance and system behavior during traffic spikes or unusual usage patterns.
Resource utilization testing monitors CPU, GPU, memory, and storage consumption patterns to optimize infrastructure costs while maintaining performance requirements. These tests help identify opportunities for resource optimization and cost reduction without compromising system reliability.
Benchmark testing compares model performance against industry standards, competitive alternatives, and historical baselines to ensure that systems deliver competitive performance levels. These comparisons provide context for performance metrics and help identify areas for improvement.
Future Directions and Emerging Practices
The evolution of machine learning testing continues to accelerate with the development of new model architectures, deployment patterns, and operational requirements. Emerging practices include automated test generation using AI techniques, continuous model validation in production environments, and integrated testing frameworks that span the entire ML lifecycle from data ingestion to model retirement.
The integration of machine learning testing with broader DevOps and site reliability engineering practices creates new opportunities for improving system reliability and operational efficiency. These integrations enable more sophisticated monitoring, alerting, and automated response capabilities that can maintain system health with minimal human intervention.
Edge computing and federated learning introduce additional testing challenges that require distributed validation approaches and privacy-preserving testing methodologies. These emerging deployment patterns necessitate new testing frameworks that can validate system behavior across diverse hardware environments and network conditions.
The continued development of explainable AI and interpretable machine learning models creates new testing requirements focused on explanation quality, consistency, and reliability. These tests must validate that model explanations accurately represent decision-making processes while remaining accessible to non-technical stakeholders.
Disclaimer
This article provides general information about AI model testing and machine learning pipeline validation for educational purposes. Implementation of testing strategies should be tailored to specific organizational requirements, regulatory obligations, and technical constraints. The effectiveness of testing approaches may vary depending on model types, data characteristics, and deployment environments. Readers should consult with qualified professionals and conduct thorough evaluation before implementing testing frameworks in production systems.