
The exponential growth of artificial intelligence and machine learning workloads has created unprecedented demands on data center networking infrastructure, particularly for high-performance computing clusters that power today’s most advanced AI models. As organizations scale their machine learning operations from single-node experiments to massive distributed training environments spanning thousands of GPUs, the choice of networking technology becomes a critical architectural decision that directly impacts training performance, scalability, and operational costs.
Stay updated with the latest AI infrastructure trends to understand how networking technologies are evolving to meet the demanding requirements of modern machine learning workloads. The networking backbone of AI clusters represents far more than a simple data transport mechanism; it serves as the nervous system that enables efficient coordination, synchronization, and communication between distributed computing resources working in harmony to solve complex computational challenges.
The Critical Role of Network Architecture in AI Clusters
The architecture of network communication systems in machine learning clusters fundamentally determines the efficiency of distributed training algorithms, the scalability of model parallelism strategies, and the overall throughput of data-intensive AI workloads. Unlike traditional enterprise networking scenarios where peak bandwidth and occasional latency spikes may be acceptable, machine learning clusters demand consistent, predictable, and extremely low-latency communication patterns that enable thousands of processing units to maintain precise synchronization during iterative training processes.
The communication patterns inherent in distributed machine learning present unique challenges that distinguish AI networking requirements from conventional data center applications. Model parameter synchronization, gradient aggregation, and all-reduce operations require frequent, simultaneous communication between numerous nodes, creating network traffic patterns that can quickly overwhelm traditional networking infrastructures not specifically designed for these highly parallel, latency-sensitive workloads.
InfiniBand: The High-Performance Computing Standard
InfiniBand has established itself as the de facto networking standard for high-performance computing environments, offering exceptional performance characteristics that make it particularly well-suited for demanding machine learning workloads. This specialized networking technology was specifically designed to address the communication bottlenecks that commonly occur in parallel computing environments, providing ultra-low latency, high bandwidth, and advanced features that enable efficient scaling of distributed applications across large numbers of compute nodes.
The architecture of InfiniBand incorporates several key innovations that distinguish it from traditional networking approaches. The technology utilizes a switched fabric topology that provides multiple pathways between nodes, enabling dynamic load balancing and fault tolerance that are essential for maintaining consistent performance in large-scale deployments. The protocol stack is optimized for minimum software overhead, with hardware-level processing of network operations that dramatically reduces CPU utilization compared to software-based networking protocols.
InfiniBand’s Remote Direct Memory Access capabilities represent one of its most significant advantages for machine learning applications. This feature enables direct memory-to-memory transfers between nodes without involving the operating system or CPU, eliminating the traditional bottlenecks associated with network stack processing and memory copying operations. For machine learning workloads that frequently exchange large parameter matrices and gradient updates, RDMA can provide substantial performance improvements and reduce the computational overhead associated with network communication.
The quality of service mechanisms built into InfiniBand provide another crucial advantage for machine learning clusters. The technology supports multiple service levels with guaranteed bandwidth allocation, ensuring that critical communication patterns such as collective operations and synchronization primitives receive the network resources necessary for optimal performance. This capability is particularly valuable in mixed workload environments where multiple machine learning jobs may compete for network resources simultaneously.
Explore advanced AI infrastructure solutions with Claude to optimize your machine learning cluster networking for maximum performance and efficiency. The sophisticated features of InfiniBand extend beyond raw performance metrics to encompass comprehensive management and monitoring capabilities that enable fine-tuned optimization of network performance for specific machine learning workload characteristics.
Ethernet: The Ubiquitous Networking Foundation
Ethernet technology has evolved significantly from its humble origins as a simple local area networking solution to become a versatile, high-performance networking platform capable of supporting demanding applications including machine learning clusters. Modern Ethernet implementations offer substantial bandwidth capabilities, mature ecosystem support, and cost-effective deployment options that make it an attractive alternative to specialized networking technologies for many AI infrastructure scenarios.
The widespread adoption of Ethernet across enterprise and cloud environments has created a deep ecosystem of expertise, tooling, and support infrastructure that significantly reduces the operational complexity of deploying and maintaining large-scale networking installations. This ubiquity translates into lower training costs for network administrators, broader availability of troubleshooting expertise, and more extensive vendor competition that drives continued innovation and cost optimization.
Recent advances in Ethernet technology have addressed many of the historical limitations that made it less suitable for high-performance computing applications. The introduction of RDMA over Converged Ethernet and other protocol enhancements have enabled Ethernet to support many of the low-latency, high-throughput communication patterns required by machine learning workloads while maintaining compatibility with existing network infrastructure and management tools.
The flexibility of Ethernet networking extends to its support for diverse traffic types and communication patterns within the same physical infrastructure. Machine learning clusters often require not only high-performance inter-node communication for training workloads but also traditional TCP/IP connectivity for management, monitoring, data ingestion, and result distribution. Ethernet’s native support for multiple protocols and traffic types eliminates the need for separate networking infrastructures for different aspects of cluster operation.
The economic advantages of Ethernet become particularly compelling when considering total cost of ownership across the entire lifecycle of machine learning infrastructure deployments. The commodity nature of Ethernet components, combined with intense vendor competition and continuous technology improvement, typically results in more favorable price-performance ratios compared to specialized networking technologies, especially when factoring in operational costs and the value of standardization across diverse computing environments.
Performance Characteristics and Benchmarking Analysis
The performance differences between InfiniBand and Ethernet technologies in machine learning cluster environments manifest across multiple dimensions including raw bandwidth, latency characteristics, CPU utilization, and scalability properties. Understanding these performance trade-offs requires careful analysis of specific workload patterns and cluster configurations rather than relying solely on theoretical maximum performance specifications.
Latency performance represents one of the most critical differentiating factors between these networking technologies for machine learning applications. InfiniBand typically achieves sub-microsecond latencies for small message transfers, which proves essential for the frequent synchronization operations required by distributed training algorithms. The hardware-accelerated protocol processing and optimized software stack of InfiniBand minimize the software overhead associated with network operations, enabling more of the available compute resources to focus on actual machine learning computations rather than communication management.
Ethernet latencies, while higher than InfiniBand in absolute terms, have improved significantly with recent technological advances and may prove acceptable for many machine learning workloads, particularly those with larger batch sizes or less frequent synchronization requirements. The gap between InfiniBand and Ethernet latency performance continues to narrow as Ethernet technology incorporates hardware acceleration and protocol optimization techniques originally developed for specialized networking platforms.
Bandwidth scalability characteristics differ substantially between these technologies, with important implications for cluster architecture and growth planning. InfiniBand fabrics typically provide more predictable bandwidth scaling as cluster size increases, thanks to their non-blocking switched fabric architecture and sophisticated traffic management capabilities. Ethernet networks, particularly those based on traditional hierarchical designs, may experience bandwidth bottlenecks as traffic concentrates at higher levels of the network topology, though modern leaf-spine architectures have largely addressed these concerns.
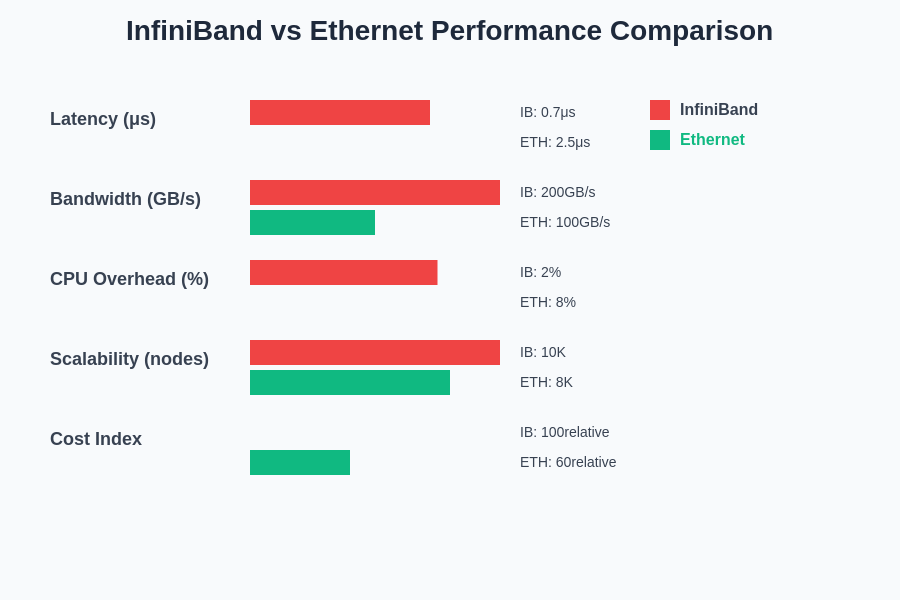
The performance characteristics of InfiniBand and Ethernet technologies reveal significant differences across multiple dimensions that directly impact machine learning cluster effectiveness. These metrics demonstrate the trade-offs between specialized high-performance networking and cost-effective general-purpose solutions.
The impact of network technology choice on overall system efficiency extends beyond simple bandwidth and latency measurements to encompass CPU utilization, memory bandwidth consumption, and power efficiency considerations. InfiniBand’s hardware-accelerated protocol processing typically results in lower CPU overhead for network operations, freeing more computational resources for machine learning algorithms. However, this advantage must be weighed against the higher acquisition costs and operational complexity associated with specialized networking infrastructure.
Scalability and Cluster Architecture Considerations
The scalability characteristics of networking technologies become increasingly important as machine learning models grow in complexity and organizations deploy larger clusters to accelerate training and inference workloads. The ability to efficiently scale network performance while maintaining cost-effectiveness and operational simplicity directly impacts the practical limits of machine learning cluster deployments and influences architectural decisions that affect long-term system evolution.
InfiniBand’s native support for large-scale switched fabric architectures enables relatively straightforward scaling to thousands of nodes while maintaining consistent performance characteristics. The technology’s built-in support for multiple parallel paths between nodes provides both performance benefits through traffic distribution and resilience benefits through automatic failover capabilities. These features prove particularly valuable in large machine learning clusters where individual node failures should not significantly impact overall training performance.
The hierarchical nature of traditional Ethernet architectures can present scaling challenges as clusters grow beyond certain size thresholds, particularly when communication patterns require high bandwidth connectivity between arbitrary node pairs. However, modern data center Ethernet architectures based on leaf-spine topologies have largely addressed these limitations, providing non-blocking performance characteristics that rival specialized networking technologies while maintaining the operational advantages of Ethernet infrastructure.
Network topology design considerations differ significantly between InfiniBand and Ethernet deployments, with important implications for physical infrastructure requirements, cable management complexity, and future expansion capabilities. InfiniBand networks typically require more specialized design expertise to optimize topology for specific communication patterns, while Ethernet networks benefit from more standardized design approaches and broader availability of design and implementation expertise.
The interaction between network architecture and machine learning framework capabilities represents another crucial consideration for scaling decisions. Different distributed training frameworks exhibit varying sensitivity to network performance characteristics, with some frameworks optimized for high-bandwidth, moderate-latency environments while others require ultra-low latency for efficient operation. Understanding these framework-specific requirements helps inform networking technology selection and cluster architecture design decisions.
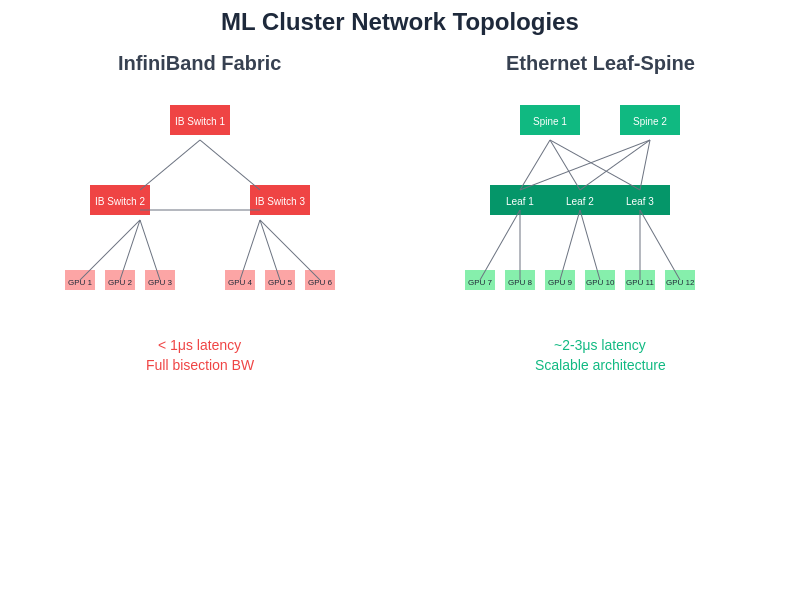
The architectural differences between InfiniBand fabric and Ethernet leaf-spine topologies directly influence cluster performance, scalability, and operational characteristics. Each topology offers distinct advantages for different machine learning workload patterns and organizational requirements.
Enhance your research capabilities with Perplexity AI to stay current with rapidly evolving networking technologies and their applications in machine learning infrastructure. The continuous evolution of both networking technologies and machine learning frameworks requires ongoing evaluation of performance trade-offs and architectural optimization opportunities.
Cost Analysis and Total Cost of Ownership
The economic considerations surrounding networking technology selection for machine learning clusters extend far beyond initial hardware acquisition costs to encompass installation complexity, operational expenses, maintenance requirements, and long-term scalability investments. A comprehensive total cost of ownership analysis must consider both direct costs associated with networking infrastructure and indirect costs related to performance impacts on machine learning productivity and operational efficiency.
Initial capital expenditure differences between InfiniBand and Ethernet solutions can be substantial, with InfiniBand typically commanding premium pricing due to its specialized nature and smaller market volume. However, these upfront cost differences must be evaluated in the context of performance benefits that may enable more efficient utilization of expensive computing resources such as high-end GPUs and specialized AI accelerators. In scenarios where network performance directly limits training throughput, the higher cost of InfiniBand infrastructure may be justified by improved overall system efficiency.
Operational cost considerations include power consumption, cooling requirements, and administrative overhead associated with different networking technologies. InfiniBand networks often require specialized expertise for optimal configuration and troubleshooting, potentially increasing staffing costs or external support requirements. Ethernet networks benefit from widespread familiarity among IT professionals and more extensive vendor support ecosystems, potentially reducing ongoing operational expenses.
The depreciation timeline and technology refresh considerations also impact total cost of ownership calculations. Ethernet technology typically follows more aggressive performance improvement curves driven by broader market adoption and vendor competition, potentially providing better long-term value through more frequent and substantial capability enhancements. InfiniBand technology improvements, while still significant, may occur at different cadences aligned with high-performance computing market cycles rather than broader networking industry trends.
Indirect costs associated with machine learning productivity and time-to-insight metrics often represent the most significant component of total cost of ownership for AI infrastructure investments. Network bottlenecks that extend training times or limit model complexity can have cascading impacts on research productivity, competitive positioning, and ultimately business value creation. The challenge lies in accurately quantifying these productivity impacts and attributing them to specific infrastructure decisions rather than other factors affecting machine learning development cycles.
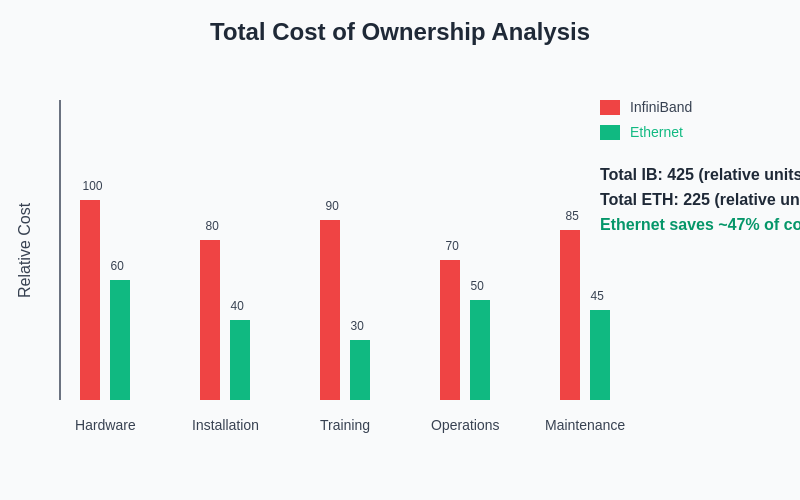
The comprehensive cost analysis reveals that while InfiniBand typically requires higher initial investment across multiple categories, Ethernet solutions provide substantial cost advantages that can significantly impact budget allocation decisions for machine learning infrastructure deployments.
Real-World Deployment Scenarios and Case Studies
The practical application of InfiniBand versus Ethernet networking technologies in production machine learning environments reveals important insights that complement theoretical performance analysis and benchmark results. Different organizational contexts, workload characteristics, and operational constraints lead to varying optimal networking technology selections, demonstrating that the choice between these technologies depends heavily on specific deployment requirements and constraints.
Large-scale cloud service providers often favor Ethernet-based solutions for machine learning infrastructure due to the operational advantages of standardization across diverse workload types and the economic benefits of commodity hardware procurement. The ability to utilize the same networking infrastructure for machine learning training, inference serving, and general-purpose computing workloads provides significant operational efficiency gains that often outweigh raw performance advantages of specialized networking technologies.
Research institutions and organizations focused on cutting-edge machine learning research frequently choose InfiniBand solutions to maximize performance for experimental workloads where training time directly impacts research velocity. The ultra-low latency characteristics of InfiniBand prove particularly valuable for novel distributed training algorithms and large-scale model architectures where communication efficiency directly determines the feasibility of specific research approaches.
Hybrid deployment scenarios increasingly common in enterprise environments often combine both networking technologies to optimize for different aspects of machine learning workflows. High-performance InfiniBand networks may connect the most performance-critical compute nodes while Ethernet networks handle data ingestion, storage connectivity, and management traffic. This approach enables organizations to optimize performance where it matters most while controlling costs for less critical network segments.
The evolution of machine learning workload characteristics continues to influence networking technology selection decisions as models become larger and more complex while training techniques become more sophisticated. The growing importance of model parallelism and pipeline parallelism strategies places different demands on networking infrastructure compared to traditional data parallelism approaches, requiring careful evaluation of how different networking technologies support these evolving computational patterns.
Emerging Technologies and Future Considerations
The networking landscape for machine learning clusters continues to evolve rapidly as both traditional networking vendors and specialized technology companies develop new solutions specifically designed for AI workload requirements. Understanding these emerging technologies and their potential impact on future infrastructure decisions helps organizations make networking investments that will remain relevant as machine learning capabilities continue to advance.
The development of specialized AI networking protocols and hardware acceleration capabilities represents one of the most significant trends influencing future networking technology selection. These innovations aim to combine the performance advantages of specialized networking technologies with the economic and operational benefits of more standardized approaches, potentially reshaping the traditional trade-offs between InfiniBand and Ethernet solutions.
Software-defined networking capabilities are increasingly being applied to machine learning cluster environments, enabling more dynamic optimization of network resources for specific workload characteristics. These technologies potentially reduce the importance of underlying networking hardware selection by providing intelligent traffic management and resource allocation that can adapt to varying communication patterns and performance requirements.
The growing integration of networking and computing capabilities through technologies such as SmartNICs and data processing units creates new opportunities for optimizing machine learning cluster performance through more intelligent distribution of processing tasks between traditional CPUs and specialized networking hardware. These developments may influence the relative advantages of different networking technologies as the distinction between networking and computing capabilities becomes increasingly blurred.
The emergence of quantum networking technologies, while still in early development stages, represents a potential long-term disruption to traditional networking paradigms that could eventually impact machine learning cluster architectures. While practical quantum networking applications for machine learning remain speculative, organizations planning long-term infrastructure roadmaps should consider the potential implications of these revolutionary technologies.
Implementation Best Practices and Optimization Strategies
Successful deployment of either InfiniBand or Ethernet networking for machine learning clusters requires careful attention to configuration details, optimization techniques, and ongoing performance monitoring that extends beyond initial hardware selection decisions. The complexity of modern machine learning workloads demands sophisticated network tuning and optimization strategies that account for the specific characteristics of distributed training algorithms and data movement patterns.
Network topology optimization represents one of the most critical aspects of machine learning cluster networking deployment, regardless of the underlying technology selection. The physical and logical arrangement of network connections must account for the communication patterns exhibited by specific machine learning frameworks and training algorithms to minimize bottlenecks and ensure efficient utilization of available bandwidth. This optimization often requires detailed analysis of application communication patterns and iterative refinement of network configuration parameters.
Quality of service configuration and traffic prioritization become increasingly important in multi-tenant environments where different machine learning workloads compete for network resources. Proper configuration of traffic classes and bandwidth allocation policies ensures that critical synchronization operations receive adequate network resources while preventing lower-priority traffic from impacting training performance. These configuration requirements apply to both InfiniBand and Ethernet deployments but may be implemented through different mechanisms and management interfaces.
Performance monitoring and troubleshooting capabilities must be integrated into machine learning cluster networking deployments from the initial design phase rather than added as an afterthought. The complex interaction between application-level performance metrics and underlying network behavior requires sophisticated monitoring tools that can correlate machine learning training metrics with detailed network performance data. This visibility proves essential for identifying performance bottlenecks and optimizing system configuration for maximum efficiency.
The integration of networking performance optimization with machine learning framework configuration represents an often-overlooked aspect of cluster deployment that can significantly impact overall system performance. Different frameworks provide varying levels of control over communication patterns and network utilization strategies, requiring careful tuning to match framework capabilities with available networking infrastructure characteristics.
Strategic Decision Framework and Selection Criteria
Developing a systematic approach to networking technology selection for machine learning clusters requires consideration of multiple factors beyond simple performance benchmarks, encompassing organizational capabilities, long-term strategic objectives, and the specific characteristics of anticipated workloads. A structured decision framework helps organizations evaluate trade-offs systematically and make informed choices that align with both technical requirements and business objectives.
Performance requirements analysis should begin with detailed characterization of anticipated machine learning workloads including model architectures, training algorithms, data characteristics, and scaling requirements. Different types of machine learning applications exhibit significantly different network sensitivity profiles, with some workloads benefiting dramatically from ultra-low latency networking while others prove relatively insensitive to network performance variations within reasonable ranges.
Organizational capability assessment must consider available expertise, operational preferences, and integration requirements with existing infrastructure and management systems. The specialized nature of InfiniBand networking may require significant investment in training and expertise development, while Ethernet networking typically leverages existing organizational capabilities and infrastructure investments. These capability considerations often prove as important as technical performance factors in determining optimal technology selection.
Budget constraints and funding models significantly influence networking technology selection decisions, particularly for organizations with limited capital expenditure budgets or those operating under constrained operational expense models. The higher initial costs of InfiniBand solutions must be justified through quantifiable performance benefits or strategic advantages that offset the additional investment requirements.
Long-term technology roadmap alignment ensures that networking technology selections support anticipated future requirements rather than optimizing solely for current needs. The rapid evolution of machine learning techniques and infrastructure requirements demands networking solutions that can accommodate growth and adaptation over multi-year deployment lifecycles.
Risk tolerance and operational complexity preferences vary significantly between organizations and influence optimal networking technology selection. Some organizations prioritize maximum performance regardless of operational complexity, while others prefer solutions that minimize risk and operational overhead even at the cost of some performance optimization.
Conclusion and Future Outlook
The choice between InfiniBand and Ethernet networking technologies for machine learning clusters represents a complex decision that requires careful balance of performance requirements, cost considerations, operational capabilities, and strategic objectives. Both technologies offer compelling advantages in different scenarios, and the optimal selection depends heavily on specific organizational contexts and workload characteristics rather than universal performance superiority of either approach.
InfiniBand continues to provide the ultimate performance solution for latency-sensitive machine learning workloads and scenarios where maximum training throughput justifies premium infrastructure costs. The technology’s specialized design for high-performance computing applications delivers exceptional results for demanding AI research and development environments where performance limitations directly constrain research progress and competitive positioning.
Ethernet technology has evolved significantly to address many traditional performance limitations while maintaining its fundamental advantages in cost-effectiveness, operational simplicity, and ecosystem maturity. For many production machine learning environments, particularly those operated by organizations with strong Ethernet expertise and infrastructure, modern Ethernet solutions provide an attractive balance of performance and practicality.
The continued evolution of both technologies suggests that the performance gap between InfiniBand and Ethernet solutions will likely continue to narrow while their respective operational and economic characteristics remain differentiated. Organizations should focus on understanding their specific requirements and constraints rather than attempting to identify a universally superior networking technology.
The future of machine learning cluster networking will likely be shaped by emerging technologies that combine aspects of both traditional approaches while addressing new requirements created by evolving AI workloads and computational paradigms. Organizations making networking infrastructure investments should consider these emerging trends and maintain flexibility to adapt their networking strategies as technologies and requirements continue to evolve.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of networking technologies and their applications in machine learning infrastructure. Readers should conduct their own research and consider their specific requirements when selecting networking technologies for AI clusters. The effectiveness of different networking approaches may vary depending on specific use cases, workload characteristics, and deployment environments. Performance comparisons and recommendations should be validated through testing with actual workloads and infrastructure configurations.