The evolution of artificial intelligence from experimental research projects to mission-critical production systems has created an urgent need for sophisticated operational frameworks that can manage the unique complexities of machine learning workloads. AI Operations, commonly referred to as MLOps, represents the convergence of machine learning engineering, data engineering, and traditional DevOps practices, creating a comprehensive discipline focused on the reliable deployment, monitoring, and maintenance of AI systems at scale.
Stay updated with the latest AI operational trends and best practices as the field continues to evolve rapidly with new tools, methodologies, and industry standards emerging regularly. The transformation from traditional software operations to AI-centric operational models requires a fundamental reimagining of how we approach system reliability, performance monitoring, and continuous improvement in environments where data quality, model drift, and algorithmic fairness become primary concerns alongside traditional infrastructure metrics.
The Foundation of Modern MLOps Architecture
The architectural foundation of effective MLOps extends far beyond traditional software deployment pipelines to encompass the entire machine learning lifecycle from data ingestion and model training through deployment, monitoring, and iterative improvement. This comprehensive approach recognizes that machine learning systems exhibit unique characteristics that distinguish them from conventional software applications, including their dependency on high-quality training data, sensitivity to distributional shifts in input data, and the need for continuous retraining to maintain optimal performance over time.
Modern MLOps architectures integrate sophisticated data versioning systems that track not only code changes but also dataset modifications, feature engineering transformations, and model artifact evolution. These systems enable reproducible experimentation and provide the foundation for regulatory compliance in industries where model transparency and auditability are critical requirements. The architecture typically encompasses automated data validation pipelines that continuously monitor incoming data for quality issues, schema drift, and anomalous patterns that could adversely impact model performance.
The integration of continuous integration and continuous deployment principles into machine learning workflows has revolutionized how organizations approach model development and deployment. Unlike traditional software where code changes are the primary concern, MLOps pipelines must account for data changes, hyperparameter modifications, and model architecture updates, creating a multi-dimensional optimization space that requires sophisticated automation and monitoring capabilities.
Data Pipeline Management and Engineering Excellence
Data pipeline management represents one of the most critical aspects of successful MLOps implementation, as the quality and reliability of machine learning models fundamentally depend on the consistency and accuracy of the underlying data infrastructure. Modern data engineering practices for machine learning environments emphasize real-time data validation, automated quality checks, and robust error handling mechanisms that ensure data integrity throughout the entire pipeline from source systems to model training environments.
Enhance your AI development capabilities with advanced tools like Claude that can assist in designing robust data processing architectures and implementing sophisticated validation logic for complex machine learning pipelines. The evolution of data pipeline orchestration has moved beyond simple batch processing systems to embrace streaming architectures that can handle high-velocity data sources while maintaining the data quality standards required for reliable model performance.
Feature engineering pipelines have become increasingly sophisticated, incorporating automated feature selection algorithms, dimensionality reduction techniques, and real-time feature computation capabilities that enable low-latency model serving while maintaining feature consistency across training and inference environments. These pipelines often implement advanced caching mechanisms and distributed computing frameworks that can handle the computational demands of feature-rich machine learning applications operating at enterprise scale.
The implementation of data lineage tracking and governance frameworks ensures that organizations can maintain comprehensive visibility into data transformations, feature derivations, and model input dependencies. This visibility becomes crucial for debugging model performance issues, conducting impact analysis for upstream data changes, and ensuring compliance with data protection regulations that require detailed audit trails for personal information processing.
Model Development and Experimentation Workflows
The model development lifecycle in production MLOps environments requires sophisticated experiment management systems that can track thousands of model iterations, hyperparameter combinations, and performance metrics while maintaining reproducibility and enabling collaborative development across distributed teams. Modern experimentation platforms integrate with version control systems to create comprehensive snapshots of model training environments, including code dependencies, data versions, and computational resource configurations.
Advanced experimentation workflows incorporate automated hyperparameter optimization techniques, including Bayesian optimization, genetic algorithms, and sophisticated search strategies that can explore high-dimensional parameter spaces more efficiently than traditional grid search approaches. These optimization systems often integrate with distributed computing frameworks that can parallelize training across multiple GPUs or compute clusters, dramatically reducing the time required for model development and validation.
The integration of automated model validation and testing frameworks ensures that newly trained models meet quality thresholds before progression to production environments. These frameworks implement comprehensive test suites that evaluate model performance across diverse data distributions, edge cases, and adversarial examples, providing confidence in model robustness and reliability under varying operational conditions.
Deployment Strategies and Infrastructure Management
Modern MLOps deployment strategies encompass a diverse range of architectural patterns designed to address different performance, scalability, and reliability requirements. Blue-green deployments enable zero-downtime model updates by maintaining parallel production environments, while canary deployments allow gradual rollout of new models with continuous monitoring and automatic rollback capabilities based on performance metrics and business objectives.
Containerization technologies have revolutionized machine learning model deployment by providing consistent runtime environments that eliminate dependency conflicts and enable seamless scaling across different infrastructure platforms. Container orchestration systems like Kubernetes provide sophisticated resource management capabilities that can automatically scale model serving infrastructure based on demand patterns while maintaining cost efficiency through dynamic resource allocation.
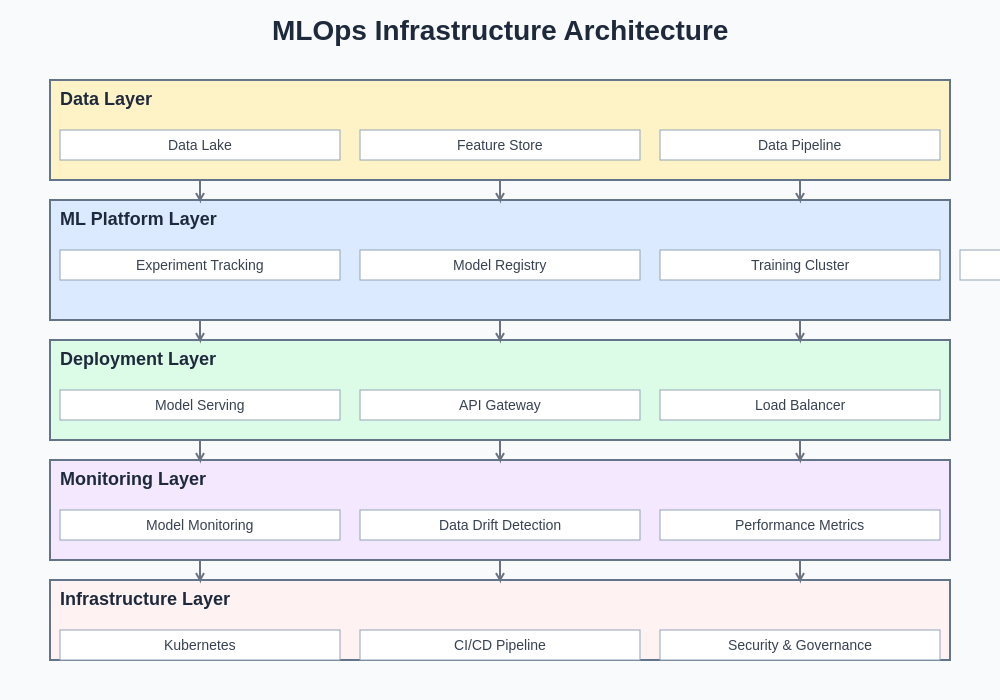
The modern MLOps infrastructure landscape integrates multiple specialized components working in concert to provide comprehensive model lifecycle management. From automated training pipelines and model registries to sophisticated monitoring systems and feedback loops, each component plays a crucial role in maintaining production machine learning systems that can adapt and evolve with changing business requirements. This layered architecture approach ensures separation of concerns while maintaining seamless integration across all operational aspects of machine learning systems.
Edge deployment scenarios require specialized approaches that account for resource constraints, network connectivity limitations, and the need for autonomous operation in distributed environments. These deployments often implement model compression techniques, quantization strategies, and efficient inference frameworks that can deliver acceptable performance within the constraints of edge computing environments.
Monitoring and Observability in Production ML Systems
Production machine learning systems require monitoring strategies that extend beyond traditional infrastructure metrics to encompass model-specific performance indicators, data quality metrics, and business impact measurements. Comprehensive observability frameworks track model prediction accuracy, input data distribution drift, and feature importance changes over time, providing early warning systems for potential model degradation or failure scenarios.
Real-time monitoring systems implement statistical tests that can detect distributional shifts in incoming data, alerting operations teams to potential model drift before it significantly impacts business outcomes. These systems often incorporate adaptive thresholds that account for expected seasonal variations and business cycle patterns while remaining sensitive to unexpected changes that might indicate data pipeline failures or external environmental shifts.
Leverage advanced AI research capabilities with Perplexity to stay informed about the latest developments in machine learning monitoring techniques and observability best practices that can enhance your MLOps implementation. The integration of business metrics monitoring ensures that technical model performance metrics align with actual business value creation, enabling data-driven decisions about model retraining schedules and performance optimization priorities.
Advanced monitoring frameworks implement automated alerting systems that can distinguish between normal operational variations and genuine system issues requiring immediate attention. These systems often incorporate machine learning techniques to model normal system behavior and identify anomalous patterns that might indicate emerging problems or opportunities for system optimization.
Model Governance and Compliance Management
Model governance frameworks address the growing regulatory and ethical requirements surrounding machine learning systems in production environments. These frameworks implement comprehensive audit trails that track model development decisions, data usage patterns, and deployment history, enabling organizations to demonstrate compliance with industry regulations and internal governance policies.
Bias detection and fairness monitoring systems continuously evaluate model outputs across different demographic groups and protected characteristics, implementing automated alerts when statistical disparities exceed acceptable thresholds. These systems often integrate with model retraining pipelines to ensure that bias mitigation strategies are automatically incorporated into model updates and improvements.
The implementation of model explainability and interpretability frameworks provides stakeholders with insights into model decision-making processes, enabling better understanding of model behavior and building confidence in automated decision systems. These frameworks often generate automated reports that summarize model performance, highlight important features, and provide business-friendly explanations of complex algorithmic behavior.
Version control and change management systems for machine learning models implement sophisticated approval workflows that require multiple stakeholders to review and approve model changes before deployment. These workflows often integrate with automated testing systems to ensure that proposed changes meet quality, performance, and compliance requirements before reaching production environments.
Scaling Challenges and Infrastructure Optimization
Scaling machine learning systems presents unique challenges that require specialized infrastructure design and optimization strategies. Auto-scaling systems must account for model loading times, memory requirements, and computational complexity when making scaling decisions, often implementing sophisticated prediction algorithms that can anticipate demand patterns and pre-provision resources accordingly.
Resource optimization in MLOps environments requires careful consideration of the trade-offs between model accuracy, inference latency, and computational cost. Advanced optimization techniques include model pruning, quantization, and knowledge distillation strategies that can reduce computational requirements while maintaining acceptable performance levels for specific use cases and business requirements.
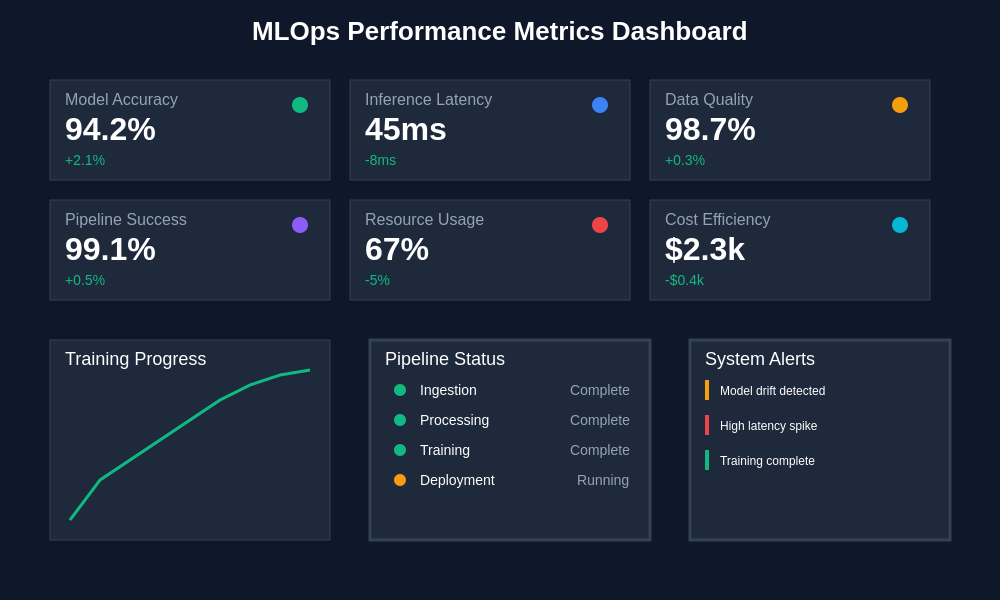
Comprehensive performance monitoring across the entire MLOps pipeline provides visibility into bottlenecks, resource utilization patterns, and optimization opportunities. These metrics enable data-driven decisions about infrastructure scaling, model optimization, and operational efficiency improvements that can significantly reduce costs while maintaining service quality standards. Real-time dashboards integrate multiple data sources to provide holistic views of system health, model performance, and business impact metrics in unified interfaces that enable rapid issue identification and resolution.
Multi-cloud and hybrid deployment strategies provide flexibility and resilience in MLOps implementations, enabling organizations to optimize for cost, performance, and regulatory compliance across different infrastructure providers. These strategies often implement sophisticated workload distribution algorithms that can automatically route inference requests to optimal computing environments based on current performance characteristics and business requirements.
Continuous Integration and Delivery for ML Systems
Continuous integration pipelines for machine learning systems implement comprehensive testing frameworks that validate not only code quality but also data quality, model performance, and integration compatibility across the entire system stack. These pipelines often incorporate automated data validation tests, model benchmark comparisons, and integration smoke tests that ensure system reliability throughout the development and deployment process.
Advanced CI/CD systems for MLOps implement sophisticated branching strategies that can handle parallel development of multiple model versions while maintaining data consistency and experiment reproducibility. These systems often integrate with feature flags and progressive rollout mechanisms that enable safe deployment of experimental features and model improvements with minimal risk to production systems.
The automation of model retraining pipelines ensures that production models remain current and effective as underlying data distributions evolve over time. These automated systems implement intelligent triggering mechanisms that can initiate retraining based on performance degradation signals, data drift detection, or scheduled maintenance windows while optimizing computational resource utilization and minimizing system downtime.
Quality gates in ML CI/CD pipelines implement comprehensive validation criteria that must be satisfied before models can progress through different stages of the deployment pipeline. These gates often include automated performance benchmarking, bias testing, explainability validation, and business metric verification to ensure that deployed models meet all technical and business requirements.
Security and Privacy in MLOps Environments
Security frameworks for MLOps environments address unique vulnerabilities associated with machine learning systems, including adversarial attacks, data poisoning, model stealing, and privacy leakage through inference patterns. These frameworks implement comprehensive threat modeling approaches that identify potential attack vectors and implement appropriate countermeasures to protect both model assets and underlying training data.
Privacy-preserving machine learning techniques, including differential privacy, federated learning, and secure multi-party computation, enable organizations to develop and deploy machine learning models while maintaining strict data protection standards. These techniques are particularly important in industries handling sensitive personal information or operating under stringent regulatory requirements.
Access control and authentication systems in MLOps platforms implement fine-grained permission models that can restrict access to different components of the machine learning pipeline based on user roles, data sensitivity levels, and operational requirements. These systems often integrate with existing enterprise identity management platforms to provide seamless user experience while maintaining security standards.
Data encryption and secure model serving architectures protect machine learning assets both at rest and in transit, implementing sophisticated key management systems and secure communication protocols that prevent unauthorized access to sensitive model parameters and training data.
Team Collaboration and Organizational Structure
Successful MLOps implementation requires organizational structures that facilitate effective collaboration between data scientists, machine learning engineers, infrastructure specialists, and business stakeholders. These cross-functional teams implement collaborative workflows that balance the need for experimentation and innovation with operational reliability and business value creation.
Communication frameworks and documentation standards ensure that knowledge sharing occurs effectively across different technical specialties and organizational levels. These frameworks often implement automated documentation generation systems that can create comprehensive technical documentation from code, experiments, and deployment configurations while maintaining accuracy and currency.
Training and skill development programs help traditional software engineers transition to MLOps specializations while enabling data scientists to develop operational awareness and infrastructure management capabilities. These programs often emphasize hands-on experience with production systems and collaborative problem-solving approaches that bridge the gap between research and operational environments.
Future Directions and Emerging Trends
The evolution of MLOps continues to accelerate with the emergence of new technologies and methodologies that promise to further simplify and enhance machine learning operations. Serverless machine learning platforms are beginning to abstract away much of the infrastructure complexity while providing automatic scaling and cost optimization capabilities that reduce operational overhead.
AutoML and automated machine learning pipeline generation tools are democratizing access to sophisticated machine learning capabilities while maintaining the operational discipline and monitoring capabilities required for production environments. These tools often integrate with existing MLOps frameworks to provide end-to-end automation from data ingestion through model deployment and monitoring.
The integration of large language models and generative AI capabilities into MLOps workflows is creating new opportunities for automated code generation, documentation creation, and intelligent system optimization that can significantly reduce the manual effort required to maintain complex machine learning systems.
Edge computing and distributed machine learning architectures are expanding the scope of MLOps to encompass globally distributed systems that must operate reliably across diverse network conditions and computational constraints while maintaining centralized monitoring and management capabilities.
The continued advancement of MLOps practices and tools represents a fundamental shift in how organizations approach machine learning implementation, moving from experimental and ad-hoc approaches toward systematic, reliable, and scalable operational frameworks that can support the growing importance of artificial intelligence in business operations and decision-making processes.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of MLOps practices and their applications in production machine learning environments. Readers should conduct their own research and consider their specific requirements when implementing MLOps frameworks and tools. The effectiveness of MLOps practices may vary depending on organizational context, technical requirements, and business objectives.