
The exponential growth of machine learning applications has fundamentally transformed how we approach performance testing, particularly when dealing with AI-powered API endpoints that exhibit unique characteristics and challenges not found in traditional web services. Unlike conventional APIs that primarily handle simple data retrieval and manipulation, machine learning endpoints must process complex computational workloads involving model inference, feature preprocessing, and result postprocessing, all while maintaining acceptable response times under varying load conditions.
Explore the latest AI performance optimization trends to understand cutting-edge techniques for scaling machine learning systems and maintaining optimal performance under demanding production workloads. The complexity of modern AI systems requires sophisticated testing methodologies that account for computational intensity, memory consumption patterns, and the stochastic nature of machine learning model outputs.
Understanding ML API Performance Characteristics
Machine learning API endpoints present distinct performance challenges that differentiate them significantly from traditional REST APIs. These endpoints typically involve computationally intensive operations that can vary dramatically based on input complexity, model architecture, and underlying hardware capabilities. The inference process itself may require substantial memory allocation for model weights, intermediate calculations, and output generation, creating unique bottlenecks that traditional performance testing approaches may not adequately address.
The temporal characteristics of ML API performance also differ substantially from conventional web services. While traditional APIs often exhibit relatively predictable response times based on database query complexity or business logic execution, ML endpoints may demonstrate high variance in processing times depending on input characteristics, model complexity, and resource availability. This variability necessitates specialized testing strategies that can accurately simulate real-world usage patterns while identifying performance degradation under various load conditions.
Furthermore, the resource utilization patterns of ML APIs tend to be more intensive and sustained compared to typical web services. GPU memory consumption, CPU utilization for preprocessing tasks, and network bandwidth requirements for large model outputs create multidimensional performance considerations that must be carefully monitored and optimized throughout the testing process.
Designing Comprehensive Load Testing Strategies
Effective load testing for ML API endpoints requires a multifaceted approach that considers both the unique characteristics of machine learning workloads and the diverse usage patterns typically encountered in production environments. The foundation of any robust testing strategy begins with establishing realistic baseline performance metrics that account for the inherent variability in ML model inference times and resource consumption patterns.
The selection of appropriate test scenarios must encompass a wide range of input variations that accurately reflect real-world usage patterns. This includes testing with different input sizes, complexity levels, and data types that the model is designed to process. For example, a computer vision API might require testing with images of various resolutions, file formats, and content complexity, while a natural language processing endpoint would need evaluation across different text lengths, languages, and linguistic complexity levels.
Concurrent user simulation for ML APIs requires careful consideration of the computational overhead associated with each request. Unlike traditional web APIs where hundreds or thousands of concurrent connections might be manageable, ML endpoints may reach saturation at much lower concurrency levels due to their resource-intensive nature. Test scenarios should gradually increase load while monitoring key performance indicators to identify the optimal operating ranges and potential breaking points.
Enhance your AI development workflow with Claude for intelligent test case generation and performance optimization strategies that leverage advanced reasoning capabilities to identify potential bottlenecks and optimization opportunities in complex ML systems.
Infrastructure Considerations for ML Performance Testing
The infrastructure requirements for comprehensive ML API performance testing extend far beyond traditional web service testing environments. GPU availability, memory capacity, and specialized hardware configurations significantly impact both the testing environment setup and the interpretation of performance results. Testing environments must closely mirror production infrastructure to ensure that performance characteristics observed during testing accurately predict real-world behavior.
Container orchestration and resource allocation strategies play crucial roles in ML API performance testing. Kubernetes deployments with GPU node pools, memory-optimized instance types, and autoscaling configurations must be thoroughly tested under various load conditions to ensure reliable performance scaling. The testing infrastructure itself must be capable of generating sufficient load while monitoring detailed resource utilization metrics across CPU, GPU, memory, and network dimensions.
Network considerations become particularly important when testing ML APIs that handle large input payloads or generate substantial output volumes. Image classification APIs, video processing endpoints, and large language model services may require significant bandwidth for request and response handling, necessitating network performance testing alongside computational load testing to identify potential bottlenecks in data transfer phases.
Monitoring and Metrics Collection
Comprehensive performance monitoring for ML API endpoints requires tracking metrics that extend beyond traditional web service indicators such as response time and throughput. GPU utilization, memory consumption patterns, model loading times, and inference-specific metrics provide critical insights into system behavior under load conditions. These specialized metrics help identify resource constraints and optimization opportunities that might not be apparent through conventional monitoring approaches.
Real-time monitoring during load testing should encompass both system-level metrics and application-specific indicators. GPU memory usage, CUDA kernel execution times, batch processing efficiency, and model-specific performance indicators provide granular visibility into the computational pipeline performance. This detailed monitoring enables precise identification of bottlenecks and optimization targets within the complex ML inference workflow.
The temporal aspects of ML API performance require sophisticated monitoring approaches that can capture performance variations over time. Model warm-up effects, cache behavior, and resource contention patterns may manifest differently under sustained load conditions compared to isolated performance tests. Long-duration load testing with continuous monitoring helps identify performance degradation patterns and resource leak scenarios that could impact production stability.
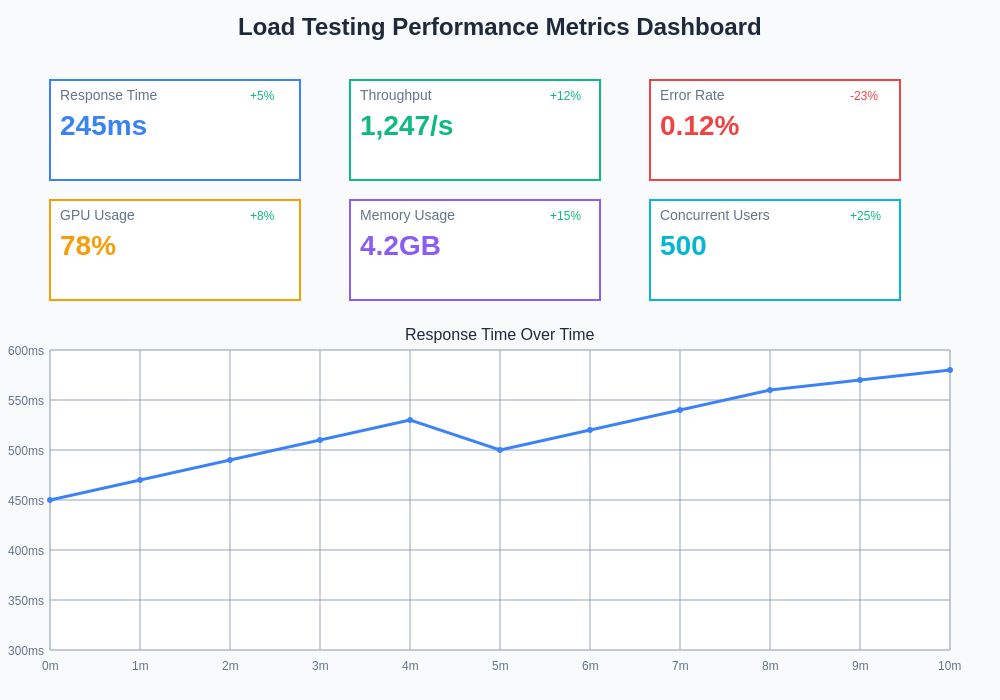
Modern load testing for ML APIs requires sophisticated monitoring dashboards that provide real-time visibility into both infrastructure performance and model-specific metrics. These comprehensive monitoring solutions enable rapid identification of performance bottlenecks and facilitate data-driven optimization decisions throughout the testing process.
Automated Testing Frameworks and Tools
The complexity of ML API performance testing necessitates sophisticated automation frameworks that can handle the unique requirements of machine learning workloads while providing comprehensive reporting and analysis capabilities. Modern testing frameworks must support GPU-aware resource monitoring, variable input generation, and specialized metrics collection tailored to ML inference performance characteristics.
Popular load testing tools like Apache JMeter, Gatling, and K6 can be extended with custom plugins and scripts to handle ML-specific testing requirements. These extensions might include GPU monitoring capabilities, specialized result validation for ML outputs, and advanced reporting features that provide insights into model performance characteristics under load conditions. The integration of these tools with container orchestration platforms enables automated scaling and resource allocation during performance testing campaigns.
Cloud-native testing solutions offer particular advantages for ML API performance testing due to their ability to provision specialized hardware configurations and scale testing resources dynamically. Services like AWS Load Testing Solution, Google Cloud Load Testing, and Azure Load Testing provide managed infrastructure for large-scale performance testing while integrating with ML-specific monitoring and analytics services.
Leverage Perplexity for comprehensive research into the latest performance testing methodologies and tools specifically designed for machine learning applications, ensuring access to cutting-edge techniques and industry best practices for optimal testing outcomes.
Input Data Management and Test Case Generation
Effective ML API performance testing requires carefully curated test datasets that accurately represent production usage patterns while covering edge cases and performance-critical scenarios. The generation and management of test data for ML APIs involves considerations beyond traditional API testing, including data privacy, model accuracy validation, and computational load variation based on input characteristics.
Synthetic data generation techniques play a crucial role in creating comprehensive test datasets that can thoroughly exercise ML API endpoints across various performance scenarios. These techniques must balance realistic input characteristics with the need for controlled testing conditions that enable reproducible performance measurements. Advanced data generation approaches may include adversarial examples, stress-testing inputs designed to maximize computational load, and boundary condition scenarios that test model robustness under extreme conditions.
Data preprocessing requirements for ML APIs often represent significant computational overhead that must be accounted for during performance testing. Image resizing, text tokenization, feature normalization, and other preprocessing steps can contribute substantially to overall API response times and resource consumption. Performance testing strategies must include comprehensive evaluation of preprocessing pipeline performance alongside model inference characteristics.
Scalability Testing and Auto-scaling Validation
ML API endpoints require specialized scalability testing approaches that account for the resource-intensive nature of machine learning inference and the unique scaling characteristics of GPU-accelerated workloads. Traditional horizontal scaling strategies may not apply directly to ML services due to GPU resource constraints, model loading overhead, and batch processing optimizations that affect scaling efficiency.
Auto-scaling validation for ML APIs involves testing the system’s ability to dynamically adjust resources based on demand while maintaining acceptable performance levels throughout scaling transitions. This includes evaluating scaling trigger thresholds, resource provisioning times, and performance stability during scale-up and scale-down operations. The testing must account for GPU instance startup times, model loading procedures, and warm-up periods that can significantly impact scaling responsiveness.
Load balancing strategies for ML APIs require careful consideration of stateful processing requirements, batch optimization opportunities, and resource affinity constraints. Performance testing should evaluate different load balancing algorithms and their impact on overall system performance, including session affinity requirements for stateful ML services and the effectiveness of request routing strategies in optimizing resource utilization.
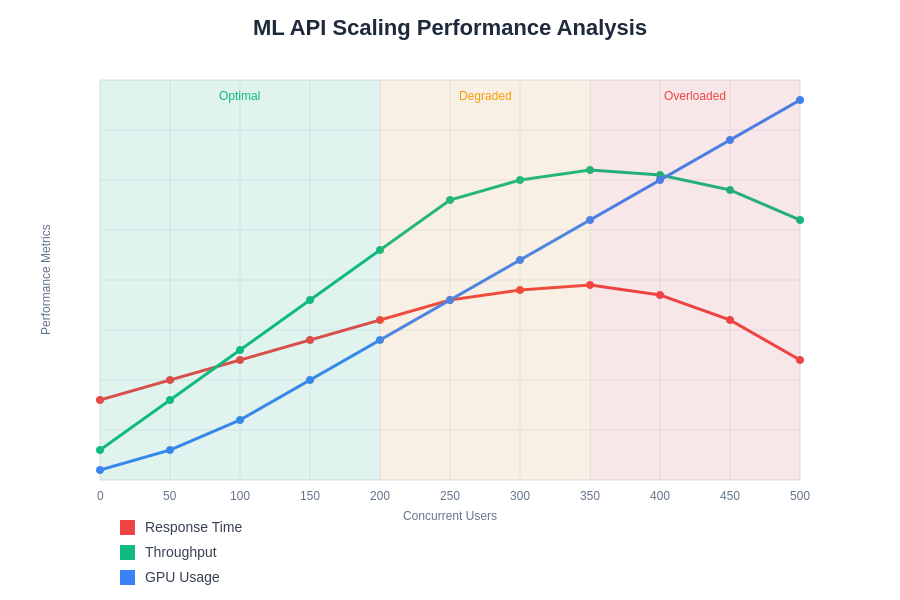
Comprehensive scaling analysis for ML APIs reveals the complex relationships between load patterns, resource utilization, and performance characteristics. This data-driven approach enables optimization of auto-scaling policies and resource allocation strategies for optimal production performance.
Security and Performance Trade-offs
ML API performance testing must carefully balance security requirements with performance optimization goals, as security measures can significantly impact API response times and resource utilization. Authentication and authorization overhead, encryption and decryption processes, and input validation procedures represent potential performance bottlenecks that must be thoroughly evaluated under load conditions.
Rate limiting and abuse prevention mechanisms designed to protect ML APIs from malicious usage can substantially impact legitimate user experience if not properly configured and tested. Performance testing should evaluate the effectiveness of these protective measures while ensuring they don’t unnecessarily constrain system performance or create artificial bottlenecks during peak usage periods.
Data privacy and compliance requirements may necessitate additional processing steps that impact ML API performance. Techniques such as differential privacy, data anonymization, and secure multiparty computation can introduce computational overhead that must be accounted for in performance testing strategies. These security-performance trade-offs require careful evaluation to ensure optimal system design.
Optimization Strategies and Performance Tuning
Performance optimization for ML APIs requires a multifaceted approach that addresses bottlenecks across the entire inference pipeline, from input preprocessing through model execution to output generation and delivery. Optimization strategies must consider both computational efficiency and resource utilization patterns to achieve optimal performance characteristics under various load conditions.
Model optimization techniques such as quantization, pruning, and knowledge distillation can significantly improve inference performance while maintaining acceptable accuracy levels. Performance testing should evaluate the effectiveness of these optimization techniques under realistic load conditions, measuring both performance improvements and any associated accuracy trade-offs that might impact user experience.
Caching strategies for ML APIs can provide substantial performance improvements by avoiding redundant computations for similar inputs or frequently requested predictions. However, cache design for ML services must consider the unique characteristics of model inputs and outputs, including similarity thresholds for cache hits, memory requirements for cached results, and cache invalidation strategies that account for model updates and retraining cycles.
Batch processing optimization represents another critical performance enhancement opportunity for ML APIs. Dynamic batching strategies that aggregate multiple requests for simultaneous processing can significantly improve throughput while reducing per-request resource consumption. Performance testing should evaluate optimal batch sizes, timeout configurations, and load balancing strategies that maximize the benefits of batch processing.
Continuous Performance Monitoring
Production performance monitoring for ML APIs requires sophisticated observability solutions that provide real-time insights into system behavior while enabling proactive identification of performance degradation patterns. Continuous monitoring strategies must encompass both infrastructure metrics and model-specific performance indicators to ensure comprehensive visibility into system health and performance characteristics.
Performance regression detection becomes particularly important for ML APIs due to the potential impact of model updates, infrastructure changes, and evolving usage patterns on system performance. Automated monitoring systems should include baseline performance tracking, anomaly detection capabilities, and alert mechanisms that enable rapid response to performance issues before they impact user experience.
The integration of performance monitoring with deployment pipelines enables continuous validation of system performance throughout the development and deployment lifecycle. This integration supports practices such as performance-gated deployments, automated rollback triggers based on performance thresholds, and continuous performance optimization through data-driven insights and recommendations.
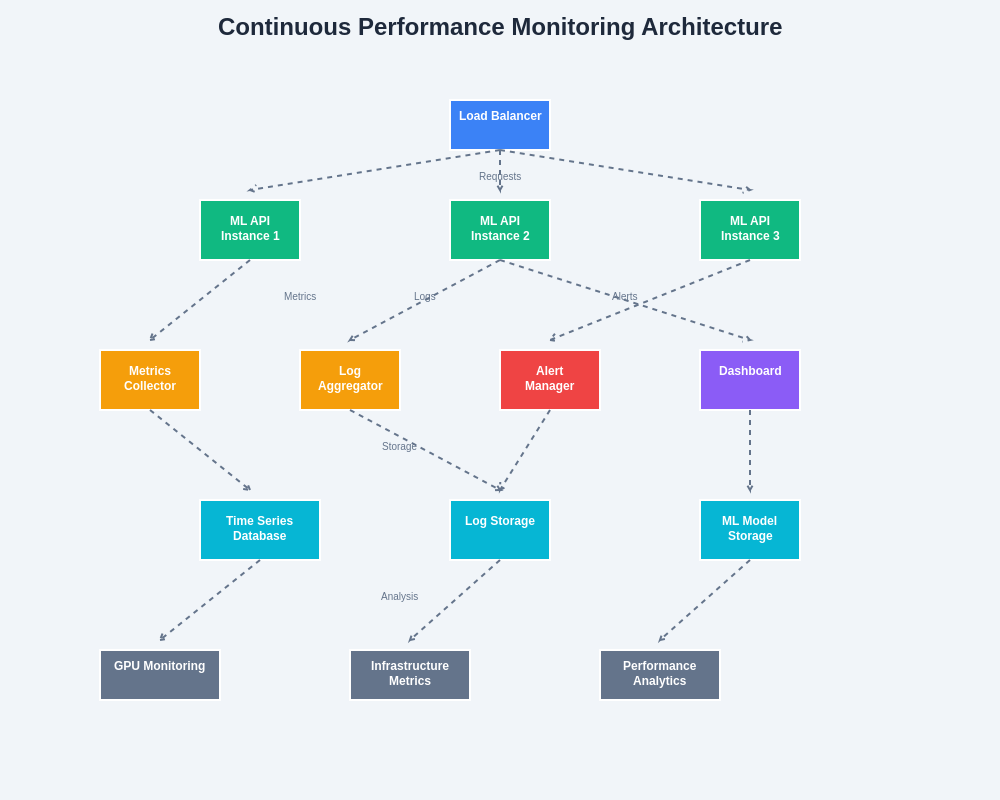
Modern ML API monitoring architectures integrate multiple data sources and analysis capabilities to provide comprehensive visibility into system performance and enable proactive optimization. These sophisticated monitoring solutions support both real-time alerting and long-term performance trend analysis for optimal system management.
Troubleshooting and Performance Debugging
Performance debugging for ML APIs requires specialized techniques and tools that can provide detailed insights into the complex computational processes involved in machine learning inference. Traditional application profiling approaches may not adequately capture the nuances of GPU-accelerated computations, batch processing optimizations, and model-specific performance characteristics that define ML API behavior.
GPU profiling tools such as NVIDIA Nsight, CUDA profilers, and specialized ML framework profilers provide essential visibility into computational bottlenecks within ML inference pipelines. These tools enable detailed analysis of kernel execution times, memory transfer patterns, and resource utilization characteristics that are crucial for identifying optimization opportunities in GPU-accelerated ML workloads.
Memory profiling for ML APIs must account for the unique memory usage patterns associated with model inference, including weight loading, intermediate computation storage, and batch processing memory requirements. Memory leak detection and optimization in ML services require specialized approaches that understand the lifecycle of ML model components and the memory allocation patterns typical of various ML frameworks and libraries.
Future Trends and Emerging Technologies
The evolution of ML API performance testing continues to be shaped by advances in hardware acceleration, distributed computing architectures, and specialized optimization techniques designed for machine learning workloads. Edge computing deployments, federated learning systems, and quantum computing applications represent emerging areas that will require novel performance testing approaches and methodologies.
Hardware acceleration trends including specialized AI chips, neuromorphic processors, and advanced GPU architectures will necessitate corresponding evolution in performance testing tools and techniques. These new hardware platforms may exhibit different performance characteristics, resource utilization patterns, and optimization opportunities that require specialized testing approaches and monitoring capabilities.
The increasing adoption of multi-model architectures, ensemble methods, and complex ML pipelines creates new performance testing challenges that require sophisticated testing strategies capable of evaluating system-level performance across multiple interconnected ML components. These complex architectures require comprehensive testing approaches that can identify bottlenecks and optimization opportunities across the entire ML system ecosystem.
Conclusion and Best Practices
Successful ML API performance testing requires a comprehensive approach that acknowledges the unique characteristics and challenges associated with machine learning workloads while leveraging appropriate tools, methodologies, and monitoring capabilities. The integration of specialized testing techniques with robust infrastructure management and continuous monitoring enables organizations to deliver reliable, high-performance ML services that meet demanding production requirements.
The key to effective ML API performance testing lies in understanding the specific performance characteristics of machine learning workloads and designing testing strategies that accurately simulate real-world usage patterns while providing actionable insights for optimization. This requires careful consideration of infrastructure requirements, monitoring capabilities, and optimization strategies that address the full spectrum of ML API performance considerations.
As machine learning continues to evolve and mature as a core technology component, the importance of sophisticated performance testing approaches will only continue to grow. Organizations that invest in comprehensive ML API performance testing capabilities will be better positioned to deliver reliable, scalable, and high-performance AI services that meet the demanding requirements of modern applications and user expectations.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The performance testing strategies and recommendations discussed should be adapted to specific use cases, infrastructure requirements, and organizational needs. Readers should conduct thorough evaluation and testing of any performance optimization techniques before implementing them in production environments. The effectiveness of performance testing approaches may vary significantly based on specific ML models, infrastructure configurations, and application requirements.