
The convergence of artificial intelligence and privacy protection represents one of the most critical challenges in modern technology development, demanding sophisticated approaches that safeguard individual privacy while maintaining the innovative potential of machine learning systems. Privacy by Design principles have evolved from theoretical frameworks into practical necessities for organizations developing AI applications that handle sensitive data, personal information, and confidential business intelligence across diverse industries and regulatory environments.
Explore the latest developments in AI privacy and security to understand emerging trends and technologies that are shaping the future of privacy-preserving machine learning implementations. The integration of privacy considerations into AI development workflows has become not merely a compliance requirement but a competitive advantage that builds user trust and enables sustainable business growth in an increasingly privacy-conscious global marketplace.
Understanding Privacy by Design in AI Context
Privacy by Design represents a comprehensive methodology that embeds privacy protection mechanisms directly into the architecture and operational framework of AI systems from the earliest design phases through deployment and maintenance. This proactive approach contrasts sharply with traditional reactive privacy measures that attempt to address privacy concerns after systems have been developed and deployed, often resulting in costly retrofitting and incomplete protection coverage.
The application of Privacy by Design principles to artificial intelligence requires deep understanding of how machine learning models process, store, and potentially expose sensitive information throughout their lifecycle. Modern AI systems collect vast amounts of data for training purposes, create internal representations that may inadvertently encode sensitive patterns, and generate outputs that could potentially reveal information about individual data subjects or proprietary business processes.
The seven foundational principles of Privacy by Design take on unique significance in AI contexts, where traditional privacy protection mechanisms may prove insufficient for addressing the complex data flows and inference capabilities inherent in machine learning systems. These principles must be adapted and extended to account for the dynamic nature of AI models, their ability to learn and generalize from data, and their potential for creating unexpected correlations and insights that could compromise privacy even when individual data points appear anonymized.
Fundamental Principles for AI Privacy Protection
The implementation of effective privacy protection in AI systems requires comprehensive understanding and application of several interconnected principles that work together to create robust defense mechanisms against privacy violations and data breaches. These principles extend beyond traditional data protection measures to address the unique challenges posed by machine learning algorithms, automated decision-making processes, and the complex data ecosystems that support modern AI applications.
Data minimization represents perhaps the most fundamental principle in AI privacy protection, requiring organizations to collect, process, and retain only the minimum amount of data necessary to achieve specific, well-defined objectives. In AI contexts, this principle challenges common practices of collecting vast datasets for potential future use, instead demanding careful consideration of what data is truly necessary for training effective models and achieving desired outcomes.
Enhance your AI development with advanced privacy-focused tools like Claude that incorporate privacy considerations into their design and operation, helping developers build more secure and compliant AI applications. The integration of privacy-aware AI tools into development workflows enables teams to maintain high privacy standards while leveraging powerful machine learning capabilities for legitimate business purposes.
Purpose limitation ensures that data collected for AI systems is used only for the specific purposes for which it was originally collected, preventing scope creep and unauthorized secondary uses that could compromise individual privacy or violate regulatory requirements. This principle requires organizations to clearly define and document the intended uses of AI systems, implement technical controls that prevent unauthorized access or misuse, and maintain ongoing governance processes that ensure continued compliance with stated purposes.
Technical Approaches to Privacy-Preserving Machine Learning
The technical implementation of privacy-preserving machine learning encompasses diverse methodologies and technologies designed to protect sensitive information while maintaining the utility and effectiveness of AI systems. These approaches range from data preprocessing techniques that remove or obscure identifying information to advanced cryptographic methods that enable computation on encrypted data without revealing underlying information to system operators or potential attackers.
Differential privacy has emerged as one of the most rigorous and mathematically sound approaches to privacy protection in machine learning contexts. This technique adds carefully calibrated noise to datasets or model outputs to prevent the identification of individual data points while preserving overall statistical properties that enable effective machine learning. The implementation of differential privacy requires sophisticated understanding of privacy budgets, noise mechanisms, and the trade-offs between privacy protection and model accuracy.
Federated learning represents another significant advancement in privacy-preserving AI, enabling multiple organizations to collaborate on training machine learning models without sharing raw data. This approach keeps sensitive data localized while still enabling the development of models that benefit from the diverse perspectives and larger effective dataset sizes that result from multi-party collaboration. The technical challenges of federated learning include managing communication overhead, handling heterogeneous data distributions, and ensuring that model updates do not inadvertently reveal sensitive information about local datasets.
Homomorphic encryption provides the theoretical foundation for performing computations on encrypted data without requiring decryption, enabling AI systems to process sensitive information while maintaining cryptographic protection throughout the computation process. While current homomorphic encryption implementations face significant performance challenges that limit their practical applicability to complex machine learning tasks, ongoing research continues to improve efficiency and expand the range of computations that can be performed under encryption.
Secure Data Collection and Storage Strategies
The foundation of any privacy-preserving AI system lies in implementing robust data collection and storage strategies that protect sensitive information from unauthorized access, inadvertent disclosure, and potential misuse throughout the data lifecycle. These strategies must address the unique challenges posed by AI systems, which often require large, diverse datasets for effective training while operating under strict privacy and security constraints that limit traditional data management approaches.
Data anonymization and pseudonymization techniques play crucial roles in protecting individual privacy while maintaining data utility for machine learning purposes. However, the effectiveness of these techniques in AI contexts requires careful consideration of the potential for re-identification through sophisticated inference attacks that leverage the pattern recognition capabilities of machine learning algorithms themselves. Modern anonymization approaches must account for the possibility that AI systems might identify individuals through subtle correlations and patterns that would not be apparent to human analysts.
Secure data storage architectures for AI systems require multi-layered protection mechanisms that address both traditional cybersecurity threats and AI-specific vulnerabilities such as model inversion attacks, membership inference attacks, and data extraction techniques that could compromise training data through careful analysis of model behavior. These architectures typically incorporate encryption at rest and in transit, access controls that implement least-privilege principles, and auditing mechanisms that provide comprehensive visibility into data access patterns and potential security incidents.
Model Training with Privacy Guarantees
The training phase of machine learning models presents unique privacy challenges that require specialized techniques and careful architectural decisions to ensure that sensitive information from training datasets does not become inadvertently encoded in model parameters or accessible through model outputs. Traditional machine learning approaches often create models that memorize specific details from training data, potentially enabling attackers to extract sensitive information through carefully crafted queries or analysis of model behavior patterns.
Private aggregation techniques enable the training of machine learning models on distributed datasets without centralizing sensitive information or revealing individual data points to model trainers or system administrators. These techniques typically involve local computation of model updates on individual datasets, followed by secure aggregation processes that combine updates while maintaining privacy protection for individual contributions to the overall model training process.
Secure multi-party computation protocols provide cryptographic foundations for collaborative model training scenarios where multiple organizations wish to benefit from shared model development while maintaining strict privacy protection for their individual datasets. These protocols enable computation of model updates without revealing underlying data to other participants, though they typically require significant computational overhead and careful protocol design to prevent information leakage through side channels or protocol vulnerabilities.
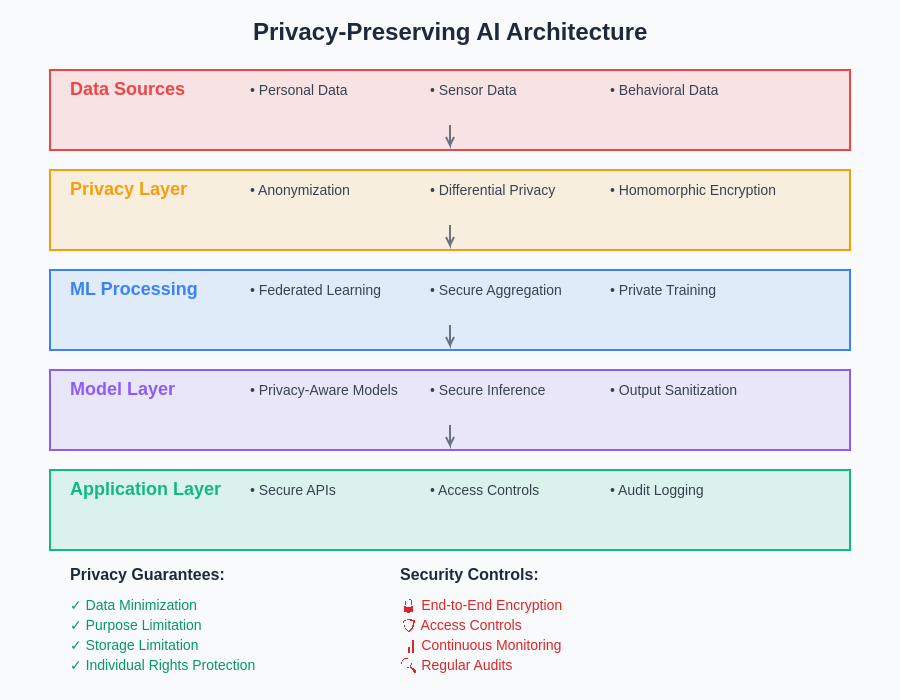
The comprehensive architecture for privacy-preserving AI systems integrates multiple layers of protection, from secure data ingestion through encrypted model training to privacy-aware inference and output sanitization. This holistic approach ensures that privacy protections are maintained throughout the entire AI system lifecycle.
Implementing Secure Model Inference
The deployment and inference phase of AI systems presents ongoing privacy challenges that extend beyond the initial training process, requiring continuous attention to how models process new data, generate outputs, and potentially reveal information about their training data or the individuals whose data is being processed. Secure inference implementations must balance the need for accurate, useful model outputs with strict privacy protection requirements that may limit the information available for processing or the detail level of generated results.
Output sanitization techniques help prevent AI models from inadvertently revealing sensitive information through their predictions, recommendations, or generated content. These techniques may involve post-processing model outputs to remove potentially identifying information, implementing confidence thresholds that prevent the system from making predictions when confidence levels suggest potential privacy risks, or using differential privacy mechanisms to add noise to outputs while preserving overall utility for legitimate users.
Query auditing and monitoring systems provide essential oversight capabilities for AI systems that process sensitive data, enabling organizations to detect potential privacy violations, identify unusual access patterns that might indicate security breaches or misuse, and maintain comprehensive records of system usage for compliance and accountability purposes. These systems must be carefully designed to provide effective monitoring without themselves becoming privacy risks through excessive data collection or inadequate protection of audit logs.
Leverage advanced AI research tools like Perplexity to stay current with rapidly evolving privacy preservation techniques and regulatory requirements that impact AI system design and implementation. The dynamic nature of both AI technology and privacy regulation requires continuous learning and adaptation to maintain effective privacy protection in evolving threat landscapes.
Regulatory Compliance and Legal Frameworks
The regulatory landscape surrounding AI privacy continues to evolve rapidly, with jurisdictions worldwide implementing comprehensive frameworks that impose specific requirements on organizations developing and deploying AI systems that process personal data. These regulations extend beyond traditional data protection laws to address the unique challenges posed by automated decision-making, algorithmic transparency, and the potential for AI systems to impact individual rights and societal outcomes through their processing of personal information.
The General Data Protection Regulation represents one of the most comprehensive and influential privacy frameworks affecting AI development, with specific provisions addressing automated decision-making, profiling, and the rights of individuals to understand and challenge AI-driven decisions that significantly impact them. Compliance with GDPR requirements in AI contexts requires careful attention to lawful bases for processing, data subject rights implementation, and the documentation of data processing activities that may span complex AI pipelines and model development workflows.
Regional variations in privacy regulation create additional complexity for organizations developing AI systems that operate across multiple jurisdictions, requiring careful analysis of applicable requirements and implementation of privacy protection measures that meet the most stringent standards across all relevant jurisdictions. These variations may affect data localization requirements, cross-border data transfer restrictions, and the specific technical measures required to demonstrate compliance with privacy protection obligations.
Emerging AI-specific regulations in various jurisdictions introduce additional requirements that go beyond traditional privacy protection to address issues such as algorithmic accountability, bias prevention, and transparency in automated decision-making processes. These regulations often require organizations to implement governance frameworks that ensure ongoing monitoring of AI system behavior, documentation of decision-making processes, and mechanisms for addressing individual complaints or concerns about AI-driven decisions.
Risk Assessment and Threat Modeling
Comprehensive risk assessment and threat modeling represent essential components of privacy-preserving AI system development, enabling organizations to identify potential privacy risks, evaluate the likelihood and impact of various threat scenarios, and implement appropriate countermeasures to mitigate identified risks. The unique characteristics of AI systems require specialized threat modeling approaches that account for the complex attack vectors and privacy risks inherent in machine learning systems.
Privacy impact assessments for AI systems must consider both traditional privacy risks associated with data collection and processing as well as AI-specific risks such as model inversion attacks, membership inference attacks, and the potential for unintended information disclosure through model outputs or behavior patterns. These assessments should evaluate the entire AI system lifecycle, from initial data collection through model deployment and ongoing operation, identifying potential privacy risks at each stage and ensuring that appropriate protections are implemented.
Adversarial threat modeling in AI contexts requires consideration of sophisticated attackers who may attempt to exploit the learning capabilities of AI systems to extract sensitive information, manipulate model behavior, or gain unauthorized access to training data or model parameters. These threat models must account for both external attackers seeking to compromise AI systems and insider threats from individuals with legitimate access to AI systems who may attempt to misuse their privileges for unauthorized purposes.
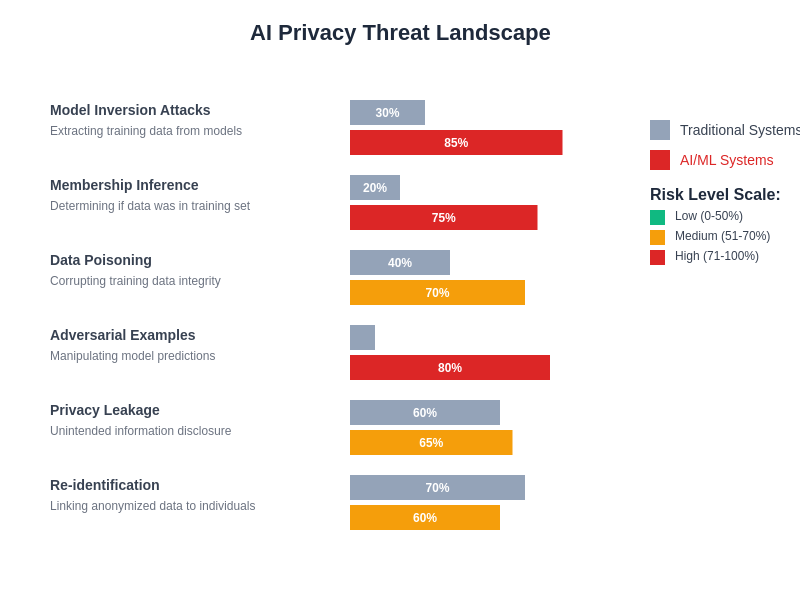
The evolving threat landscape for AI privacy encompasses traditional cybersecurity risks alongside emerging AI-specific vulnerabilities, requiring comprehensive defense strategies that address both technical and procedural aspects of privacy protection in machine learning environments.
Audit and Monitoring Frameworks
Effective audit and monitoring frameworks provide essential oversight capabilities for privacy-preserving AI systems, enabling organizations to detect potential privacy violations, assess the ongoing effectiveness of privacy protection measures, and demonstrate compliance with regulatory requirements through comprehensive documentation and reporting mechanisms. These frameworks must be carefully designed to provide thorough visibility into AI system behavior while avoiding the creation of additional privacy risks through excessive data collection or inadequate protection of monitoring data.
Continuous monitoring systems for AI privacy must track multiple dimensions of system behavior, including data access patterns, model performance metrics, output characteristics that might indicate privacy risks, and user interaction patterns that could suggest potential misuse or security compromises. These monitoring systems require sophisticated analytics capabilities that can identify subtle patterns indicating potential privacy violations while minimizing false positives that could disrupt legitimate system operations.
Privacy-preserving audit techniques enable organizations to assess the effectiveness of their privacy protection measures without compromising the privacy of the data and individuals they are designed to protect. These techniques may involve synthetic data generation for testing purposes, differential privacy mechanisms in audit processes, or cryptographic protocols that enable third-party auditors to assess system compliance without gaining access to sensitive data or proprietary system components.
Testing and Validation Methodologies
Comprehensive testing and validation methodologies for privacy-preserving AI systems require specialized approaches that evaluate both the effectiveness of privacy protection mechanisms and the utility of AI systems operating under privacy constraints. Traditional software testing approaches may be insufficient for validating privacy properties in AI systems, requiring new methodologies that can assess complex probabilistic guarantees and evaluate system behavior under adversarial conditions.
Privacy property testing involves developing and executing test cases that specifically evaluate the privacy protection capabilities of AI systems, including tests for information leakage through model outputs, resistance to various types of attacks, and compliance with specified privacy parameters such as differential privacy budgets. These tests must be carefully designed to provide meaningful evaluation of privacy properties without themselves compromising the privacy of test data or system operations.
Adversarial testing methodologies simulate various attack scenarios to evaluate the robustness of privacy protection mechanisms under realistic threat conditions. These methodologies may involve automated generation of adversarial inputs designed to trigger privacy violations, simulation of sophisticated attackers with various levels of system knowledge and access, and evaluation of system responses to coordinated attacks that might exploit multiple vulnerabilities simultaneously.
Red team exercises provide comprehensive evaluation of AI system privacy protection through structured attempts to identify and exploit potential vulnerabilities using realistic attack scenarios and sophisticated adversarial techniques. These exercises typically involve independent security experts who attempt to compromise system privacy protections using various attack vectors, providing valuable insights into potential weaknesses and areas for improvement in privacy protection mechanisms.
Emerging Technologies and Future Directions
The rapidly evolving landscape of privacy-preserving technologies continues to introduce new possibilities for enhancing privacy protection in AI systems while maintaining or improving system utility and performance. These emerging technologies range from advances in cryptographic techniques that enable new forms of privacy-preserving computation to novel approaches to machine learning that inherently provide stronger privacy guarantees than traditional methods.
Zero-knowledge proofs represent a promising direction for enabling AI systems to demonstrate specific properties or capabilities without revealing underlying data or model details that could compromise privacy or intellectual property protection. These cryptographic techniques could enable organizations to prove compliance with privacy requirements, demonstrate model accuracy or fairness properties, or verify system behavior without exposing sensitive implementation details or training data.
Quantum computing developments may significantly impact both the threats to AI privacy and the tools available for privacy protection, with quantum algorithms potentially enabling more efficient attacks on current cryptographic protections while also providing new possibilities for quantum-enhanced privacy-preserving computation. Organizations developing long-term AI privacy strategies must consider the potential impacts of quantum computing and begin preparing for post-quantum cryptographic requirements.
Advances in hardware security, including trusted execution environments, secure enclaves, and specialized privacy-preserving computation hardware, provide new architectural possibilities for implementing AI systems with strong privacy guarantees at the hardware level. These hardware-based approaches may enable more efficient privacy-preserving computation while providing additional protection against certain classes of attacks that target software-based privacy protection mechanisms.
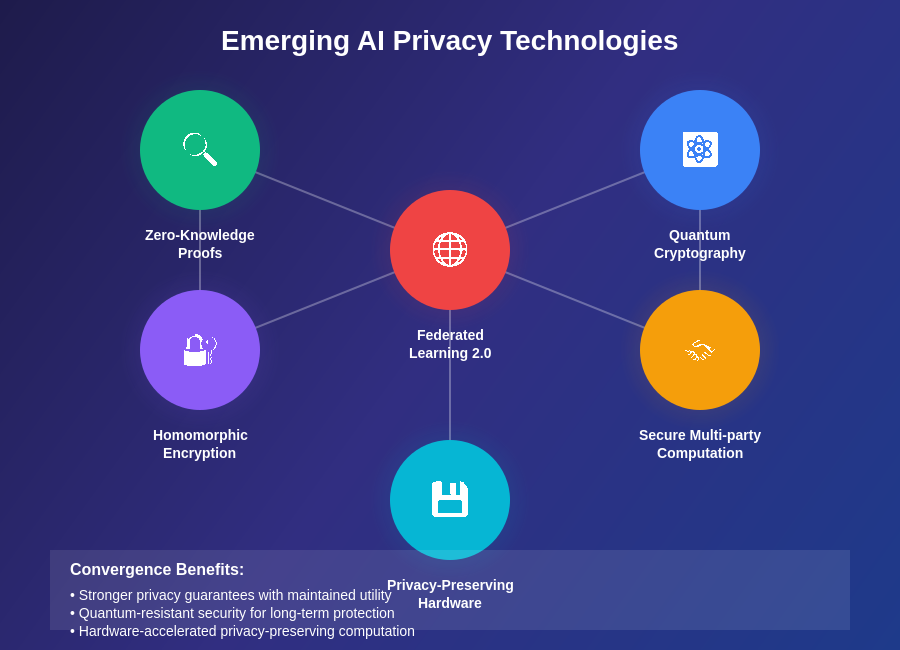
The convergence of emerging privacy technologies creates new possibilities for comprehensive privacy protection in AI systems, combining cryptographic advances, hardware security innovations, and novel machine learning approaches to enable unprecedented levels of privacy protection without sacrificing AI system capabilities.
Best Practices and Implementation Guidelines
Successful implementation of privacy-preserving AI systems requires adherence to established best practices that address both technical and organizational aspects of privacy protection, ensuring that privacy considerations are integrated throughout the development lifecycle and maintained through ongoing operations and system evolution. These best practices provide practical guidance for organizations seeking to implement effective privacy protection while maintaining the business value and technical capabilities of their AI systems.
Privacy-first design principles should guide all aspects of AI system development, from initial requirements gathering through system architecture, implementation, testing, and deployment. This approach requires organizations to consider privacy implications at every design decision, evaluate privacy trade-offs alongside performance and functionality considerations, and implement privacy protection mechanisms as core system components rather than optional add-ons or afterthoughts.
Cross-functional collaboration between privacy professionals, security experts, AI developers, and business stakeholders ensures that privacy considerations are properly balanced with technical requirements and business objectives throughout the development process. This collaboration requires establishing clear communication channels, shared understanding of privacy requirements and constraints, and decision-making processes that appropriately weight privacy considerations alongside other system requirements.
Documentation and governance frameworks provide essential support for privacy-preserving AI implementations by ensuring that privacy decisions are properly recorded, privacy protection mechanisms are maintained over time, and organizations can demonstrate compliance with regulatory requirements and internal privacy policies. These frameworks should address data lineage tracking, privacy impact assessment processes, incident response procedures, and regular review and updating of privacy protection measures as systems and regulatory requirements evolve.
Conclusion and Strategic Recommendations
The implementation of privacy by design principles in AI systems represents both a technical challenge and a strategic opportunity for organizations seeking to build trust, ensure regulatory compliance, and create sustainable competitive advantages in an increasingly privacy-conscious marketplace. Success in this domain requires comprehensive approaches that address technical, organizational, and regulatory dimensions of privacy protection while maintaining the innovation potential and business value that drive AI adoption.
Organizations embarking on privacy-preserving AI initiatives should prioritize building internal capabilities that span privacy engineering, security architecture, and regulatory compliance, ensuring that they have the expertise necessary to navigate the complex landscape of privacy-preserving AI development. This capability building should include ongoing education and training programs that keep pace with rapidly evolving technologies and regulatory requirements, as well as partnerships with external experts and vendors who specialize in privacy-preserving AI technologies.
The future of AI development will increasingly depend on organizations’ ability to demonstrate strong privacy protection capabilities, as users, regulators, and business partners place growing emphasis on privacy considerations in their technology adoption and partnership decisions. Organizations that invest early in developing robust privacy-preserving AI capabilities will be better positioned to capitalize on emerging opportunities while avoiding the risks and costs associated with privacy violations or regulatory non-compliance.
The continued evolution of privacy-preserving AI technologies promises to reduce the trade-offs between privacy protection and system utility, enabling organizations to achieve strong privacy guarantees while maintaining or improving AI system performance and capabilities. Staying current with these developments and investing in privacy-preserving AI research and development will be essential for organizations seeking to maintain competitive advantages in AI-driven markets while meeting growing expectations for privacy protection.
Disclaimer
This article is for informational and educational purposes only and does not constitute legal, technical, or professional advice. Privacy regulations and technical requirements vary significantly across jurisdictions and use cases. Organizations implementing privacy-preserving AI systems should consult with qualified legal counsel, privacy professionals, and technical experts to ensure compliance with applicable requirements and effective implementation of privacy protection measures. The effectiveness of privacy protection techniques may vary depending on specific implementation details, threat models, and regulatory contexts.