
The scientific rigor of artificial intelligence research has become increasingly critical as machine learning applications permeate every aspect of modern technology and society. Establishing robust experimental methodologies for AI studies ensures that research findings are reproducible, statistically valid, and contribute meaningfully to the advancement of the field. This comprehensive examination of AI research methodology provides researchers, practitioners, and institutions with the foundational principles necessary to conduct high-quality experimental studies that withstand peer review scrutiny and drive genuine scientific progress.
Explore cutting-edge AI research trends to understand the latest developments in experimental methodologies and research approaches that are shaping the future of artificial intelligence studies. The evolution of AI research methodology reflects the maturation of the field from ad-hoc empirical observations to systematic scientific investigation grounded in statistical principles and reproducible experimental design.
Foundational Principles of AI Research Design
The cornerstone of effective AI research methodology lies in understanding the fundamental principles that distinguish rigorous scientific investigation from anecdotal experimentation. Unlike traditional software engineering where functionality can be definitively verified, machine learning research operates in a probabilistic domain where statistical significance, generalizability, and reproducibility determine the validity of research claims. This probabilistic nature demands careful consideration of experimental design elements that might be overlooked in other computational disciplines.
The interdisciplinary nature of AI research requires methodological frameworks that accommodate insights from computer science, statistics, cognitive science, and domain-specific applications. Researchers must navigate the complexities of algorithmic innovation while adhering to established scientific principles that ensure their findings contribute to cumulative knowledge rather than isolated empirical observations. This balance between computational creativity and scientific rigor forms the foundation upon which all subsequent methodological decisions are built.
Hypothesis Formation and Research Question Development
Effective AI research begins with precise hypothesis formulation that clearly defines testable predictions about algorithmic performance, model behavior, or system capabilities. The process of transforming broad research interests into specific, measurable hypotheses requires careful consideration of the theoretical frameworks underlying machine learning approaches and the practical constraints of experimental validation. Researchers must articulate not only what they expect to observe but also why these observations would support or refute their theoretical propositions.
The development of research questions in AI studies involves multiple levels of inquiry, from fundamental algorithmic properties to applied performance characteristics in specific domains. Primary research questions typically focus on core algorithmic capabilities, such as learning efficiency, generalization performance, or computational complexity. Secondary questions often examine the interaction between algorithmic choices and environmental factors, including dataset characteristics, hardware constraints, and application requirements. This hierarchical approach to question development ensures comprehensive investigation while maintaining focus on the most critical aspects of the research problem.
Enhance your AI research capabilities with Claude for advanced analysis, hypothesis generation, and experimental design validation that ensures your research meets the highest scientific standards. The integration of AI tools in research methodology itself represents a fascinating recursion that demonstrates the self-improving nature of artificial intelligence development.
Dataset Construction and Management Strategies
The quality and characteristics of datasets fundamentally determine the validity and generalizability of AI research findings. Proper dataset construction requires systematic attention to sampling methodologies, annotation protocols, and bias mitigation strategies that ensure experimental results reflect genuine algorithmic performance rather than artifacts of data collection or preprocessing decisions. The increasing recognition of dataset quality issues has elevated data curation from a preprocessing step to a central methodological concern that demands the same rigor applied to algorithmic development.
Contemporary AI research faces unique challenges in dataset management due to the scale and complexity of modern machine learning applications. Researchers must balance the desire for comprehensive datasets with practical constraints of annotation costs, privacy considerations, and computational requirements. The establishment of standardized benchmarks has partially addressed these challenges by providing common evaluation frameworks, but the selection and application of appropriate benchmarks requires careful consideration of their alignment with research objectives and their potential limitations or biases.
The temporal dynamics of dataset relevance present additional methodological considerations for AI researchers. Unlike static mathematical problems, machine learning applications often operate in evolving environments where the relevance and representativeness of training data changes over time. Longitudinal studies and temporal validation methodologies have emerged as essential tools for understanding the stability and adaptability of AI systems across different time periods and environmental conditions.
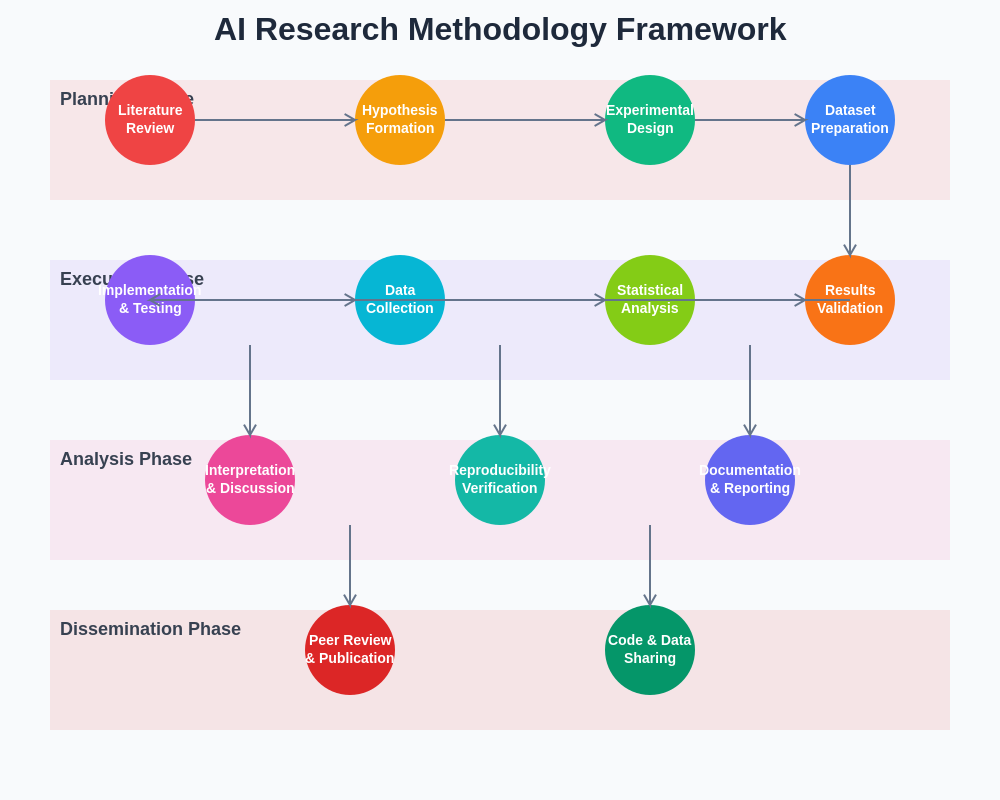
The systematic approach to AI research methodology encompasses multiple interconnected phases that ensure scientific rigor while accommodating the unique characteristics of machine learning experimentation. This framework provides a structured pathway from initial hypothesis formation through final validation and publication.
Experimental Design Paradigms for Machine Learning
The selection of appropriate experimental design paradigms represents one of the most critical decisions in AI research methodology. Cross-validation techniques, while fundamental to machine learning practice, must be carefully adapted to research contexts to ensure that statistical conclusions remain valid across different experimental conditions. The choice between k-fold cross-validation, leave-one-out validation, or custom validation schemes depends on dataset characteristics, computational constraints, and the specific research questions being investigated.
Controlled experimental design in AI research requires careful attention to confounding variables that might influence algorithmic performance independently of the factors under investigation. These confounding factors can include hardware variations, software version differences, random seed selection, and hyperparameter optimization procedures. The establishment of controlled experimental conditions often requires significant additional effort compared to applied machine learning projects, but this investment is essential for generating scientifically valid conclusions.
The emergence of multi-objective optimization in AI systems has complicated traditional experimental design approaches that assume single performance metrics. Modern AI research increasingly requires experimental frameworks capable of evaluating trade-offs between competing objectives such as accuracy versus fairness, performance versus interpretability, or efficiency versus robustness. These multi-dimensional evaluation spaces demand sophisticated statistical analysis techniques and visualization methods that can effectively communicate complex experimental results.
Statistical Analysis and Significance Testing
Statistical rigor in AI research extends far beyond reporting average performance metrics and requires comprehensive analysis of variance, confidence intervals, and significance testing appropriate for the experimental design and research questions. The selection of appropriate statistical tests depends on data characteristics, sample sizes, and the distributional assumptions underlying different algorithmic approaches. Parametric tests may be appropriate for normally distributed performance metrics, while non-parametric alternatives become necessary when dealing with skewed distributions or ordinal performance measures.
The multiple comparison problem presents particular challenges in AI research where researchers often evaluate numerous algorithmic variants, hyperparameter configurations, or dataset conditions simultaneously. Proper correction for multiple comparisons using techniques such as Bonferroni correction, false discovery rate control, or family-wise error rate management ensures that reported significance levels accurately reflect the probability of Type I errors across the entire experimental investigation.
Effect size analysis provides crucial context for interpreting statistical significance in AI research by quantifying the practical importance of observed performance differences. Small effect sizes may achieve statistical significance with large sample sizes but lack practical relevance for real-world applications. Conversely, large effect sizes observed in small samples may indicate practically important improvements that warrant further investigation despite limited statistical power.
Reproducibility and Experimental Validation
The reproducibility crisis in scientific research has particularly significant implications for AI studies where computational complexity, stochastic algorithms, and environmental dependencies create numerous opportunities for irreproducible results. Establishing reproducible AI research requires systematic documentation of experimental conditions, including software versions, hardware specifications, random seeds, and detailed algorithmic implementations. The creation of reproducible research artifacts often requires significantly more effort than the initial experimental investigation but represents an essential investment in scientific integrity.
Version control systems and containerization technologies have emerged as essential tools for ensuring reproducible AI research by capturing complete computational environments and enabling exact replication of experimental conditions. Docker containers, virtual machines, and cloud-based research platforms provide mechanisms for sharing complete experimental setups that include not only source code but also system dependencies, library versions, and configuration parameters necessary for exact reproduction.
Utilize advanced research tools like Perplexity for comprehensive literature reviews and methodological validation that ensures your research builds appropriately upon existing scientific knowledge while avoiding common methodological pitfalls. The integration of research assistance tools can significantly improve the quality and comprehensiveness of experimental design while reducing the likelihood of methodological oversights.
Benchmarking and Comparative Analysis
Effective benchmarking in AI research requires careful selection of baseline methods that provide meaningful comparisons for evaluating algorithmic contributions. The choice of baseline algorithms should reflect the current state-of-the-art in the relevant research domain while also including simpler methods that help establish the minimum performance improvements necessary to justify increased algorithmic complexity. Historical baselines provide context for understanding the cumulative progress in specific research areas, while contemporary baselines establish the immediate practical relevance of proposed improvements.
The design of fair comparison protocols ensures that algorithmic evaluations reflect genuine performance differences rather than implementation quality variations or optimization effort disparities. This fairness requires standardized implementation practices, equivalent computational budgets, and consistent evaluation metrics across all compared approaches. The increasing complexity of modern AI systems has made fair comparison increasingly challenging, as different algorithms may require specialized implementation strategies or domain-specific optimizations that complicate direct performance comparisons.
Meta-analysis techniques provide powerful tools for synthesizing results across multiple studies and identifying robust patterns that transcend individual experimental conditions. The application of meta-analysis to AI research requires careful attention to study quality, methodological consistency, and potential publication bias that might skew the apparent effectiveness of different approaches. Systematic reviews and meta-analyses represent increasingly important contributions to AI research literature by providing comprehensive assessments of research domains and identifying areas where additional investigation is needed.
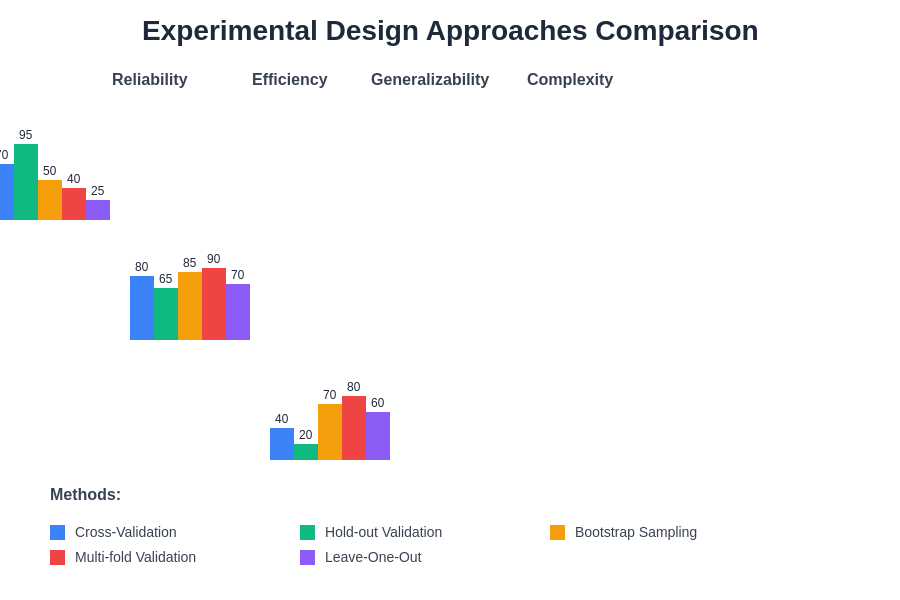
The effectiveness of different experimental design approaches varies significantly based on research objectives, available resources, and the specific characteristics of the machine learning problems being investigated. Understanding these trade-offs enables researchers to select optimal methodological approaches for their specific research contexts.
Ethical Considerations in AI Research Design
The ethical dimensions of AI research methodology extend beyond traditional research ethics to encompass questions of algorithmic fairness, privacy protection, and societal impact assessment. Experimental design decisions can inadvertently encode biases or overlook important ethical considerations that affect the validity and appropriateness of research conclusions. The integration of ethical analysis into experimental methodology ensures that research contributions advance scientific knowledge while respecting important societal values and protecting vulnerable populations.
Privacy-preserving research methodologies have become essential for AI studies involving sensitive data or human subjects. Differential privacy, federated learning, and synthetic data generation techniques provide mechanisms for conducting rigorous research while protecting individual privacy and complying with regulatory requirements. These privacy-preserving approaches often require modifications to traditional experimental designs and may introduce additional sources of variation that must be accounted for in statistical analysis.
The assessment of algorithmic fairness requires experimental designs that explicitly evaluate performance across different demographic groups and social categories. Traditional experimental approaches that focus solely on aggregate performance metrics may obscure important disparities that have significant ethical and practical implications. Fairness-aware experimental design incorporates multiple evaluation metrics, disaggregated analysis, and sensitivity testing that reveals potential bias issues before algorithms are deployed in real-world applications.
Validation Across Diverse Domains and Contexts
The generalizability of AI research findings depends critically on validation across diverse domains, datasets, and application contexts that demonstrate the robustness and broad applicability of proposed approaches. Single-domain evaluation may yield misleading conclusions about algorithmic effectiveness if the chosen evaluation context happens to align particularly well with the algorithmic assumptions or design choices. Multi-domain validation provides stronger evidence for the general utility of research contributions while revealing important limitations or boundary conditions that affect practical applicability.
Cross-cultural validation represents an increasingly important aspect of AI research methodology as machine learning systems are deployed globally across different cultural, linguistic, and social contexts. Algorithms trained and evaluated primarily on data from specific geographic regions or cultural groups may exhibit reduced performance or inappropriate behavior when applied in different cultural contexts. Cross-cultural experimental design requires careful attention to cultural sensitivity, local relevance, and the availability of appropriate evaluation frameworks for different cultural contexts.
Temporal validation addresses the important question of whether research findings remain valid as conditions change over time. Many AI applications operate in dynamic environments where the underlying data distributions, user behaviors, or system requirements evolve continuously. Longitudinal studies and temporal robustness testing provide insights into the stability and adaptability of AI systems that are essential for understanding their long-term viability and maintenance requirements.
Advanced Statistical Techniques for AI Research
Modern AI research increasingly requires sophisticated statistical techniques that can handle the complexity and scale of contemporary machine learning systems. Bayesian analysis provides powerful tools for incorporating prior knowledge, quantifying uncertainty, and making probabilistic statements about algorithmic performance that extend beyond simple point estimates and confidence intervals. The application of Bayesian methods to AI research enables more nuanced interpretation of experimental results while providing frameworks for sequential experimental design and adaptive hypothesis testing.
Causal inference techniques offer valuable insights into the mechanisms underlying algorithmic performance by distinguishing correlation from causation in complex experimental systems. The identification of causal relationships between algorithmic design choices and performance outcomes provides deeper understanding that can guide future research directions and inform theoretical development. Causal analysis requires careful attention to confounding variables, instrumental variables, and experimental design choices that enable valid causal conclusions.
Machine learning techniques applied to experimental analysis itself represent an emerging area of methodological innovation where AI methods are used to analyze and interpret AI research results. Meta-learning approaches can identify patterns across multiple studies, automated hyperparameter optimization can improve experimental efficiency, and neural architecture search can explore algorithmic design spaces more systematically than traditional manual approaches.
Documentation and Reporting Standards
Comprehensive documentation of AI research methodology requires detailed reporting of experimental procedures, implementation details, and analytical choices that enable reproduction and critical evaluation of research findings. The complexity of modern AI systems makes complete documentation particularly challenging, as seemingly minor implementation details or parameter choices can significantly affect experimental outcomes. Standardized reporting frameworks provide guidance for documenting essential experimental information while maintaining reasonable manuscript length constraints.
Code availability and documentation standards have become central requirements for credible AI research publication. The provision of complete, well-documented source code enables direct reproduction of experimental results while facilitating extension and adaptation by other researchers. Version-controlled repositories, automated testing frameworks, and comprehensive documentation systems represent best practices for maintaining high-quality research code that supports the scientific mission of knowledge sharing and cumulative progress.
The development of research artifacts beyond traditional publications, including datasets, model checkpoints, experimental logs, and analysis scripts, provides valuable resources for the broader research community while demonstrating commitment to open science principles. These artifacts often require significant additional effort to prepare and maintain but represent important contributions to scientific infrastructure that enable more efficient and effective research across the entire community.
Future Directions in AI Research Methodology
The evolution of AI research methodology continues to accelerate as the field matures and new challenges emerge from increasingly sophisticated applications and larger-scale deployments. Automated experimental design represents one promising direction where AI systems themselves could assist in designing, conducting, and analyzing research experiments. These automated approaches could potentially explore experimental design spaces more systematically than human researchers while identifying optimal trade-offs between experimental cost and statistical power.
The integration of theoretical analysis with empirical investigation represents another important frontier for AI research methodology. Traditional theoretical computer science and statistical learning theory provide important foundations for understanding algorithmic behavior, but the complexity of modern AI systems often makes purely theoretical analysis intractable. Hybrid approaches that combine theoretical insights with carefully designed empirical investigation offer promising pathways for advancing both theoretical understanding and practical capabilities.
The scaling challenges of AI research methodology reflect the increasing computational requirements of state-of-the-art systems and the growing complexity of real-world applications. Future methodological development must address questions of how to conduct rigorous research when experiments require substantial computational resources, how to validate systems that operate at unprecedented scales, and how to maintain scientific rigor while accommodating the practical constraints of modern AI development.
Collaborative Research and Community Standards
The collaborative nature of modern AI research requires methodological frameworks that facilitate effective cooperation while maintaining scientific rigor across different institutions, research groups, and disciplinary backgrounds. Standardized experimental protocols, shared evaluation frameworks, and common benchmarking initiatives enable meaningful comparison and synthesis of results across different research efforts while reducing duplicated effort and increasing the cumulative impact of individual contributions.
Community-driven initiatives for establishing methodological standards represent important mechanisms for ensuring that AI research maintains high scientific quality while adapting to evolving technological capabilities and application domains. Professional organizations, conference committees, and journal editorial boards play crucial roles in promoting best practices and establishing expectations for experimental rigor that guide the research community toward more effective and reliable scientific investigation.
The globalization of AI research presents both opportunities and challenges for maintaining consistent methodological standards across different cultural and institutional contexts. International collaboration enables access to diverse expertise, datasets, and perspectives that can improve research quality and generalizability, but also requires coordination mechanisms that ensure consistent application of scientific principles while respecting different research traditions and regulatory requirements.
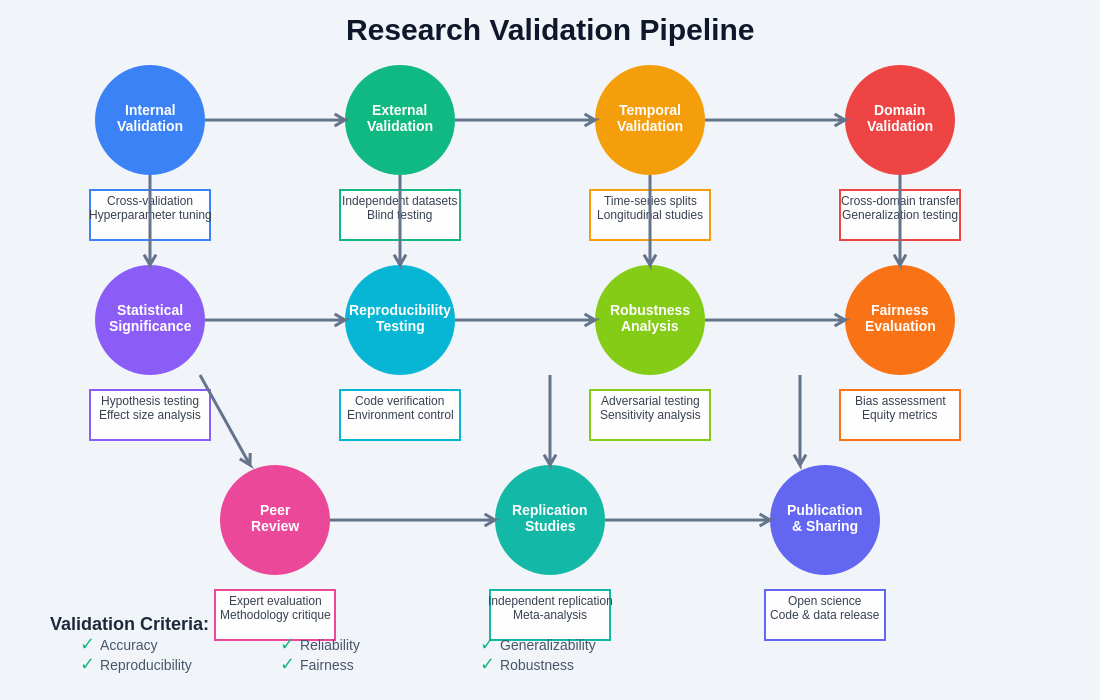
The comprehensive validation pipeline for AI research encompasses multiple stages of verification and testing that ensure research findings are robust, reproducible, and generalizable across different contexts and applications. This systematic approach to validation provides confidence in research conclusions while identifying potential limitations or boundary conditions.
Technology Infrastructure for Research
The technological infrastructure supporting AI research methodology has become increasingly sophisticated, requiring researchers to develop expertise in computational platforms, data management systems, and collaborative tools that enable large-scale experimental investigation. Cloud computing platforms provide access to substantial computational resources while offering standardized environments that facilitate reproducible research, but also require careful attention to cost management and resource optimization that can affect experimental design decisions.
Distributed computing frameworks enable AI research at scales that would be impossible with traditional computational approaches, but also introduce new sources of variation and complexity that must be accounted for in experimental methodology. The management of distributed experiments requires sophisticated coordination mechanisms, fault tolerance strategies, and result aggregation approaches that maintain experimental validity while taking advantage of parallel processing capabilities.
Version control and experiment tracking systems have evolved to accommodate the specific needs of AI research, including support for large datasets, model checkpoints, and complex dependency management. These specialized tools provide essential infrastructure for maintaining experimental reproducibility while enabling efficient collaboration and result sharing across research teams and institutions.
The democratization of advanced AI research through improved tooling and infrastructure has lowered barriers to entry while raising expectations for methodological rigor across the broader research community. This democratization creates opportunities for more diverse participation in AI research while requiring educational initiatives and community support systems that ensure new researchers understand and apply appropriate methodological standards.
Understanding the foundational principles of rigorous AI research methodology empowers researchers to conduct studies that contribute meaningfully to scientific knowledge while avoiding common methodological pitfalls that can undermine research validity. The investment in proper experimental design, statistical analysis, and validation procedures represents essential scientific infrastructure that ensures the continued advancement of artificial intelligence research toward increasingly sophisticated and reliable systems that benefit society as a whole.
Disclaimer
This article is for educational and informational purposes only and does not constitute professional research advice. The methodological approaches described should be adapted to specific research contexts and institutional requirements. Researchers should consult with methodological experts, statistical advisors, and institutional review boards as appropriate for their specific research projects. The effectiveness of different methodological approaches may vary depending on research domains, available resources, and specific experimental objectives.