
The transition from artificial intelligence proof of concept to production represents one of the most challenging phases in modern technology development, where theoretical possibilities must confront the harsh realities of real-world constraints, enterprise requirements, and operational complexities. This critical juncture often determines whether innovative AI solutions will deliver transformative business value or become costly experiments that never realize their potential impact.
The journey from prototype to production involves navigating a complex landscape of technical, operational, and business challenges that extend far beyond the initial model development phase. Organizations frequently discover that the skills, infrastructure, and processes required for successful AI scaling differ dramatically from those needed for proof of concept development, creating gaps that can derail even the most promising AI initiatives.
Stay informed about the latest AI scaling techniques and trends to understand how industry leaders are addressing these challenges and implementing successful production AI systems. The evolution of AI scaling methodologies continues to accelerate, requiring organizations to adapt their approaches based on emerging best practices and technological advances.
Understanding the Scaling Complexity Spectrum
The complexity of scaling AI systems manifests across multiple dimensions that compound exponentially as systems move from controlled laboratory environments to dynamic production ecosystems. Data complexity increases dramatically when models must process diverse, real-time inputs from multiple sources rather than carefully curated training datasets. Performance requirements shift from acceptable research metrics to stringent service level agreements that demand consistent, low-latency responses under varying load conditions.
Infrastructure considerations evolve from simple development environments to sophisticated production architectures that must handle failover scenarios, geographic distribution, regulatory compliance, and integration with existing enterprise systems. The human element introduces additional complexity as organizations must develop new operational procedures, train staff on AI system management, and establish governance frameworks that ensure responsible and effective AI deployment.
Security and privacy requirements become paramount concerns in production environments, where AI systems must protect sensitive data while maintaining transparency and auditability. These multifaceted challenges require coordinated solutions that address technical architecture, organizational processes, and strategic business alignment simultaneously.
Data Pipeline Architecture and Scalability
Production AI systems demand robust data pipeline architectures capable of handling massive volumes of information while maintaining data quality, consistency, and availability. The transition from batch processing suitable for research environments to real-time or near-real-time processing required for production applications introduces significant technical complexity that must be carefully managed throughout the scaling process.
Data ingestion mechanisms must evolve to accommodate multiple input sources, varying data formats, and different quality levels while implementing comprehensive validation, cleaning, and transformation procedures. The challenge extends beyond technical implementation to encompass data governance frameworks that ensure compliance with privacy regulations, establish clear data lineage tracking, and maintain audit trails for regulatory and operational requirements.
Storage and retrieval systems must scale elastically to handle fluctuating demand patterns while optimizing for both cost efficiency and performance requirements. The implementation of effective caching strategies, distributed storage solutions, and intelligent data partitioning becomes critical for maintaining system responsiveness as data volumes and user bases expand exponentially.
Leverage advanced AI platforms like Claude for sophisticated data processing and analysis capabilities that can help address complex scaling challenges through intelligent automation and optimization strategies. The integration of multiple AI tools creates synergistic effects that enhance overall system capabilities and operational efficiency.
Model Performance and Optimization at Scale
The performance characteristics of AI models often change dramatically when deployed at production scale, revealing optimization opportunities and bottlenecks that were not apparent during initial development phases. Memory usage patterns, computational requirements, and inference latency can exhibit unexpected behaviors when models encounter diverse real-world inputs and concurrent processing demands that exceed laboratory testing conditions.
Model optimization for production environments requires sophisticated approaches including quantization techniques, pruning strategies, and architectural modifications that balance accuracy with performance requirements. The implementation of model ensembles, A/B testing frameworks, and gradual rollout procedures enables organizations to maintain service quality while continuously improving model capabilities through iterative refinement processes.
Monitoring and observability systems become essential components of production AI architectures, providing real-time insights into model behavior, performance metrics, and potential drift indicators. These systems must capture both technical metrics such as inference times and resource utilization, as well as business metrics that demonstrate the actual impact of AI implementations on organizational objectives and user experiences.
Infrastructure Scaling and Resource Management
The infrastructure requirements for production AI systems extend far beyond the computational resources needed for model training and inference, encompassing comprehensive ecosystems that support data processing, model serving, monitoring, and maintenance activities. Cloud computing platforms provide scalable infrastructure foundations, but effective utilization requires careful architectural planning that balances cost efficiency with performance requirements and availability guarantees.
Containerization and orchestration technologies enable flexible deployment strategies that can adapt to changing demand patterns while maintaining consistency across different environments. The implementation of auto-scaling mechanisms, load balancing strategies, and resource optimization algorithms becomes critical for managing operational costs while ensuring adequate performance under varying load conditions.
Edge computing considerations introduce additional complexity as organizations seek to reduce latency and improve reliability by deploying AI capabilities closer to data sources and end users. This distributed approach requires sophisticated coordination mechanisms, data synchronization strategies, and remote management capabilities that can maintain system coherence across geographically dispersed deployments.
Operational Excellence and MLOps Integration
The establishment of robust MLOps practices represents a fundamental requirement for successful AI scaling, encompassing automated deployment pipelines, comprehensive testing frameworks, and continuous integration processes specifically designed for machine learning systems. These operational frameworks must address the unique challenges of AI systems including model versioning, experiment tracking, and reproducibility requirements that extend beyond traditional software development practices.
Monitoring and alerting systems for production AI require specialized approaches that can detect model drift, performance degradation, and data quality issues that might not be apparent through conventional application monitoring tools. The implementation of automated retraining pipelines, model validation procedures, and gradual rollout mechanisms ensures that AI systems can adapt to changing conditions while maintaining service quality and reliability.
Documentation and knowledge management become critical success factors as AI systems increase in complexity and organizational reliance on these systems grows. Comprehensive documentation must cover not only technical implementation details but also business logic, operational procedures, and troubleshooting guides that enable effective system maintenance and evolution over time.
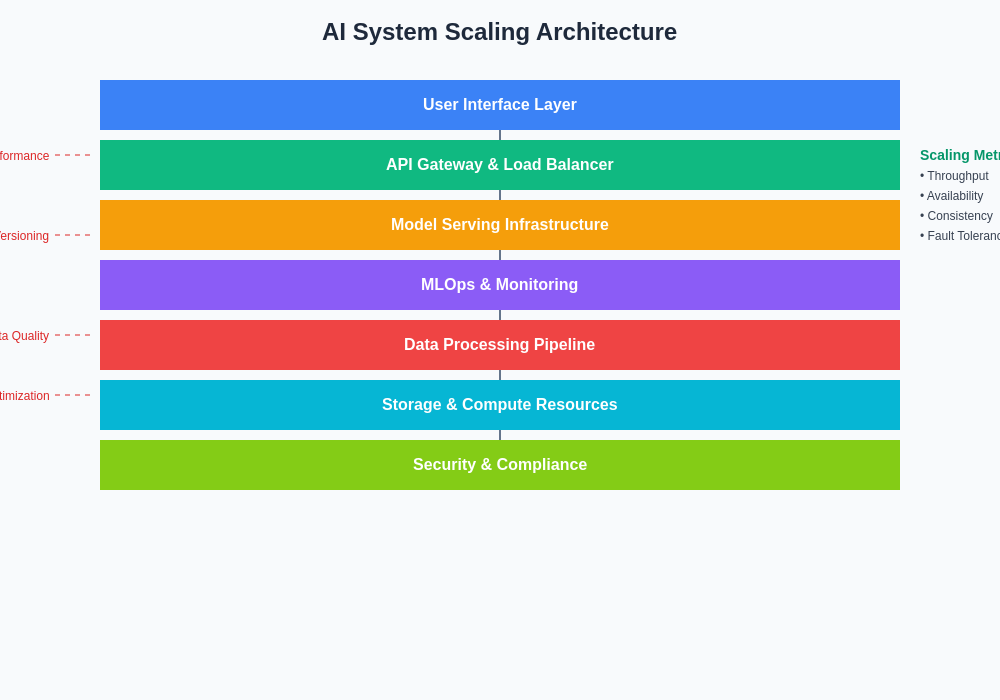
The architectural evolution from proof of concept to production involves multiple layers of complexity that must be carefully orchestrated to achieve successful scaling outcomes. Each component must be designed with scalability, reliability, and maintainability in mind while supporting the overall system objectives.
Security, Privacy, and Compliance Frameworks
Production AI systems must implement comprehensive security frameworks that protect against various threat vectors including adversarial attacks, data poisoning, model extraction, and privacy breaches. The implementation of robust authentication, authorization, and encryption mechanisms becomes essential for maintaining system integrity and protecting sensitive information throughout the AI pipeline.
Privacy-preserving techniques such as differential privacy, federated learning, and secure multi-party computation enable organizations to leverage sensitive data for AI training while maintaining compliance with privacy regulations and ethical guidelines. These approaches require specialized expertise and careful implementation to balance privacy protection with model effectiveness and system performance.
Regulatory compliance frameworks must address industry-specific requirements as well as emerging AI governance standards that are being developed by regulatory bodies worldwide. The implementation of audit trails, explainability mechanisms, and bias detection systems ensures that AI systems can demonstrate compliance with relevant regulations while providing transparency into decision-making processes.
Explore comprehensive AI research capabilities with Perplexity to stay informed about evolving regulatory requirements and best practices for secure AI deployment in production environments. The regulatory landscape for AI continues to evolve rapidly, requiring ongoing attention and adaptation of compliance strategies.
Performance Monitoring and Optimization Strategies
Effective performance monitoring for production AI systems requires multi-dimensional approaches that capture technical performance metrics, business impact indicators, and user experience measures. The implementation of comprehensive observability platforms enables organizations to understand system behavior across all operational aspects while identifying optimization opportunities and potential issues before they impact users.
Real-time monitoring systems must track model accuracy, inference latency, resource utilization, and data quality metrics while providing automated alerting mechanisms that can trigger appropriate responses to performance degradation or system anomalies. The correlation of technical metrics with business outcomes enables organizations to make informed decisions about system optimization priorities and resource allocation strategies.
Continuous optimization processes leverage monitoring data to implement automated improvements including dynamic resource allocation, intelligent caching strategies, and adaptive model serving techniques. These optimization systems must balance competing objectives including performance, cost, accuracy, and reliability while maintaining system stability and user experience quality.
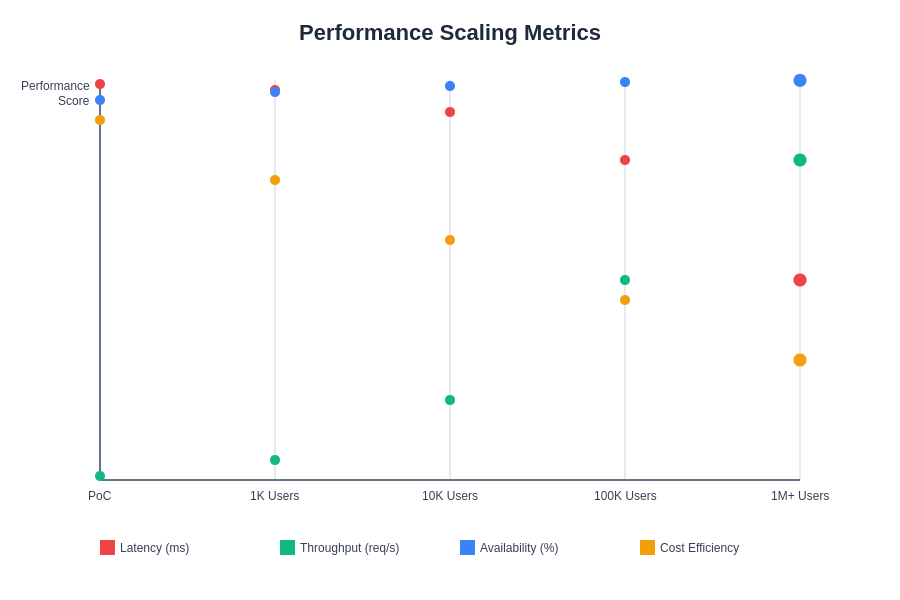
The relationship between system scale and performance metrics reveals critical insights into optimization opportunities and potential bottlenecks that must be addressed during the scaling process. Understanding these patterns enables proactive system management and strategic planning for future growth requirements.
Cost Optimization and Resource Efficiency
The financial implications of scaling AI systems can be substantial, requiring careful consideration of computational costs, storage requirements, data transfer expenses, and human resource investments. Cost optimization strategies must balance immediate operational expenses with long-term strategic investments in infrastructure and capabilities that will support continued growth and system evolution.
Resource efficiency optimization involves implementing intelligent scheduling algorithms, workload optimization techniques, and cost-aware deployment strategies that minimize unnecessary expenses while maintaining required performance levels. The adoption of spot computing, reserved instances, and hybrid cloud strategies can significantly reduce operational costs for appropriate workloads and usage patterns.
The implementation of comprehensive cost monitoring and allocation systems enables organizations to understand the true cost of AI operations while identifying optimization opportunities and ensuring appropriate budget planning for scaling activities. These systems must provide visibility into both direct computational costs and indirect expenses associated with data management, monitoring, and operational overhead.
Team Structure and Organizational Scaling
Successful AI scaling requires organizational structures that can effectively manage the complex interdisciplinary challenges associated with production AI systems. The development of specialized roles including MLOps engineers, AI product managers, and AI ethics specialists becomes essential for addressing the diverse requirements of scaled AI implementations while maintaining operational effectiveness and strategic alignment.
Cross-functional collaboration frameworks enable effective coordination between data science teams, engineering organizations, business stakeholders, and operational support groups. The establishment of clear communication protocols, shared accountability mechanisms, and aligned incentive structures ensures that scaling efforts remain focused on organizational objectives while maintaining technical excellence and operational reliability.
Knowledge management and skills development programs become critical success factors as organizations build internal capabilities for AI system management and evolution. The implementation of comprehensive training programs, documentation standards, and knowledge sharing mechanisms ensures that organizational learning keeps pace with system complexity and technological advancement.
Risk Management and Mitigation Strategies
Production AI systems introduce unique risk profiles that require specialized mitigation strategies addressing technical failures, model drift, adversarial attacks, and unintended consequences. The implementation of comprehensive risk assessment frameworks enables organizations to identify potential issues proactively while developing appropriate mitigation and response strategies.
Business continuity planning for AI systems must address scenarios including model failures, data pipeline disruptions, infrastructure outages, and regulatory changes that could impact system operation. The development of fallback mechanisms, disaster recovery procedures, and graceful degradation strategies ensures that critical business functions can continue operating even when AI systems experience problems.
The establishment of ethical AI frameworks and bias monitoring systems addresses reputational and regulatory risks associated with AI deployment while ensuring that systems operate fairly and responsibly across different user populations and use cases. These frameworks must be integrated into operational procedures and continuously monitored to maintain effectiveness as systems and contexts evolve.
Future-Proofing and Continuous Evolution
The rapid pace of AI technological advancement requires scaling strategies that can adapt to new capabilities, changing requirements, and evolving best practices without requiring complete system redesign. The implementation of modular architectures, standardized interfaces, and flexible deployment frameworks enables organizations to incorporate new technologies and approaches while maintaining operational continuity.
Strategic planning for AI scaling must consider emerging trends including edge AI, quantum computing, neuromorphic processing, and advanced AI architectures that may significantly impact future system requirements and capabilities. The development of technology roadmaps and migration strategies ensures that current investments support long-term organizational objectives while maintaining flexibility for future adaptations.
Continuous learning and improvement processes enable organizations to leverage operational experience, industry developments, and technological advances to enhance system capabilities and operational effectiveness over time. The establishment of feedback loops, experimentation frameworks, and strategic review processes ensures that AI scaling efforts remain aligned with organizational objectives while incorporating lessons learned and emerging best practices.
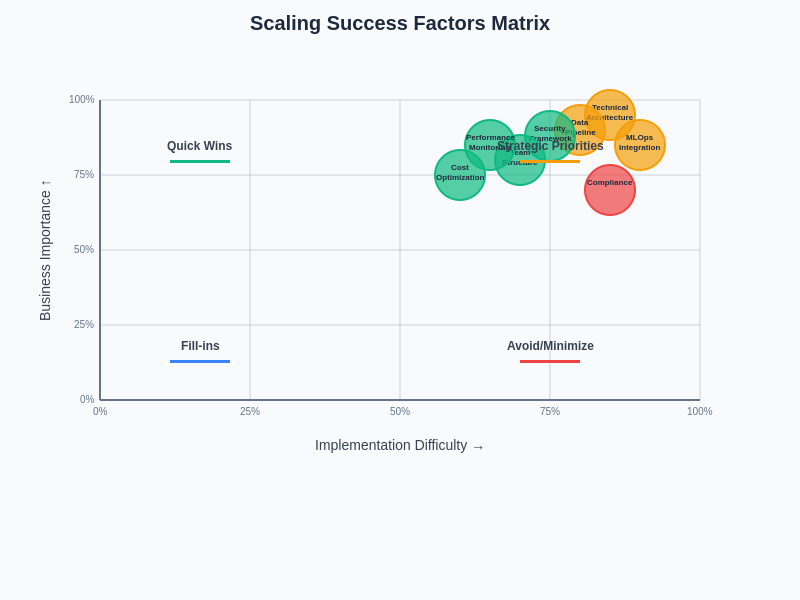
The interconnected nature of scaling success factors demonstrates the importance of holistic approaches that address technical, organizational, and strategic considerations simultaneously. Success in AI scaling requires coordinated efforts across all these dimensions to achieve sustainable production deployment outcomes.
Strategic Recommendations for Scaling Success
Organizations embarking on AI scaling initiatives should prioritize the development of comprehensive scaling strategies that address technical architecture, operational processes, and organizational capabilities simultaneously. The implementation of proof-of-concept validation frameworks ensures that scaling decisions are based on realistic assessments of system requirements, organizational capabilities, and market conditions.
Investment in MLOps capabilities and infrastructure should be prioritized early in the scaling process to establish foundations for sustainable growth and operational excellence. The development of comprehensive monitoring, testing, and deployment frameworks enables organizations to scale AI systems while maintaining quality, reliability, and compliance with organizational standards and regulatory requirements.
The establishment of cross-functional collaboration mechanisms and organizational learning programs ensures that AI scaling efforts benefit from diverse expertise while building internal capabilities for long-term system management and evolution. These investments in human capital and organizational processes often determine the ultimate success of AI scaling initiatives more than purely technical considerations.
The journey from AI proof of concept to production represents a complex transformation that requires careful planning, comprehensive preparation, and sustained organizational commitment. Success in this endeavor enables organizations to realize the transformative potential of AI technologies while building foundations for continued innovation and competitive advantage in an increasingly AI-driven business environment.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of AI scaling challenges and best practices. Organizations should conduct thorough assessments of their specific requirements, constraints, and objectives when developing AI scaling strategies. The effectiveness of scaling approaches may vary significantly based on organizational context, technical requirements, and market conditions.