
The foundation of any successful machine learning initiative rests upon the computational infrastructure that powers model training, inference, and deployment. As artificial intelligence workloads continue to grow in complexity and scale, organizations face critical decisions about selecting the optimal server hardware configuration that can deliver the performance, reliability, and cost-effectiveness required for their specific AI applications. The choice between industry-leading server manufacturers such as Dell Technologies, Hewlett Packard Enterprise, and Supermicro Computer represents more than a simple hardware procurement decision; it fundamentally shapes the trajectory of an organization’s AI capabilities and long-term technological competitiveness.
Explore the latest AI hardware trends to understand how cutting-edge server technologies are evolving to meet the demands of increasingly sophisticated machine learning applications. The rapid advancement of AI algorithms, particularly in deep learning and large language models, has created unprecedented computational requirements that demand careful consideration of server architecture, GPU configurations, memory hierarchies, and networking capabilities.
The landscape of AI server configuration presents unique challenges that distinguish it from traditional enterprise computing environments. Machine learning workloads exhibit distinct characteristics including intensive parallel processing requirements, massive memory bandwidth demands, and complex data pipeline architectures that necessitate specialized hardware configurations optimized for these specific computational patterns. Understanding how Dell PowerEdge, HPE ProLiant, and Supermicro systems address these requirements provides the foundation for making informed infrastructure decisions that can significantly impact project outcomes and organizational AI success.
Dell PowerEdge: Enterprise-Grade AI Infrastructure
Dell Technologies has established itself as a dominant force in the enterprise server market through its PowerEdge series, which offers comprehensive AI-optimized configurations designed to address the full spectrum of machine learning workloads. The PowerEdge portfolio distinguishes itself through sophisticated thermal management systems, advanced remote management capabilities, and extensive ecosystem integration that appeals to organizations prioritizing reliability, support, and seamless integration with existing enterprise infrastructure.
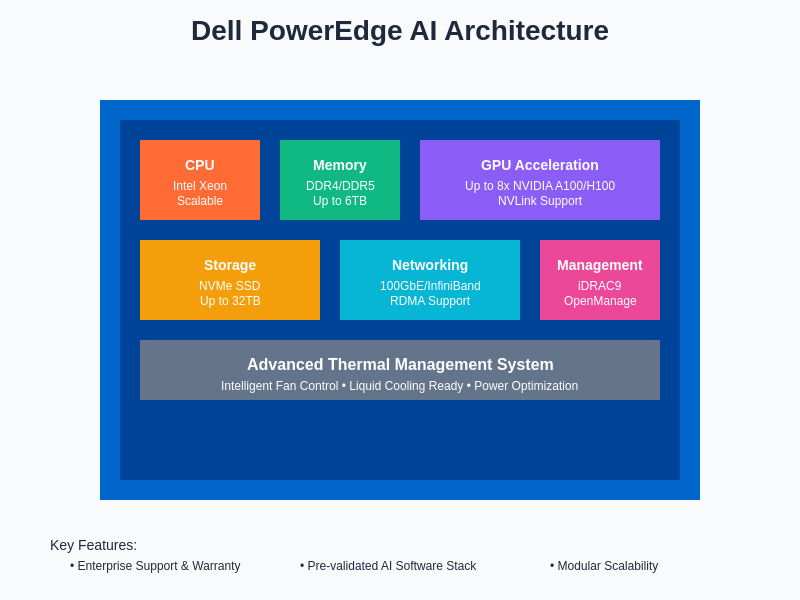
The PowerEdge R750xa and R7525 series represent Dell’s flagship AI-focused offerings, featuring support for up to eight NVIDIA A100 or H100 GPUs in configurations that maximize computational density while maintaining thermal efficiency. Dell’s approach to AI server design emphasizes modular scalability, allowing organizations to begin with modest configurations and expand computational capacity as machine learning initiatives mature and require additional processing power. This architectural flexibility proves particularly valuable for organizations navigating the uncertain terrain of AI adoption where computational requirements may evolve rapidly as models become more sophisticated.
Dell’s integration with NVIDIA’s software stack, including CUDA, cuDNN, and the NGC container registry, creates a streamlined deployment experience that reduces the complexity of setting up machine learning environments. The PowerEdge systems come pre-configured with optimized drivers and software frameworks that accelerate time-to-deployment for common machine learning applications. Additionally, Dell’s partnership with major cloud providers enables hybrid deployment scenarios where on-premises PowerEdge infrastructure can seamlessly integrate with cloud-based AI services for workload distribution and data processing optimization.
The enterprise support ecosystem surrounding Dell PowerEdge systems provides comprehensive coverage including proactive monitoring, predictive failure analysis, and rapid replacement services that minimize downtime in mission-critical AI applications. Dell’s ProSupport Plus offerings include AI-powered diagnostics that can identify potential hardware issues before they impact production workloads, a critical capability for organizations running continuous training or inference operations that cannot tolerate interruptions.
HPE ProLiant: High-Performance Computing Heritage
Hewlett Packard Enterprise brings decades of high-performance computing expertise to the AI server market through its ProLiant DL380 Gen10 Plus and Apollo systems, which leverage HPE’s deep understanding of parallel computing architectures and scientific workload optimization. The ProLiant series distinguishes itself through innovative cooling technologies, advanced memory architectures, and sophisticated workload management capabilities that excel in demanding computational environments requiring sustained high-performance operation.
The HPE Apollo 6500 Gen10 Plus system represents the pinnacle of HPE’s AI-focused engineering, supporting up to eight NVIDIA GPUs in a configuration optimized for maximum computational throughput while maintaining energy efficiency. HPE’s approach to AI server design emphasizes thermal optimization through advanced liquid cooling solutions that enable higher GPU densities and sustained performance under heavy computational loads. This thermal management capability proves particularly valuable for organizations running extended training sessions on large language models or computer vision applications that require sustained high-performance operation over extended periods.
HPE’s integration with the broader HPC ecosystem includes native support for popular machine learning frameworks such as TensorFlow, PyTorch, and specialized HPC programming models like MPI and OpenMP. The ProLiant systems feature optimized network architectures supporting high-bandwidth interconnects including InfiniBand and Ethernet configurations that facilitate efficient distributed training across multiple nodes. This networking capability becomes critical for organizations scaling machine learning operations beyond single-node configurations and requiring efficient communication between distributed computational resources.
The HPE OneView management platform provides centralized infrastructure management capabilities that simplify the deployment and maintenance of large-scale AI clusters. OneView’s automated provisioning, monitoring, and optimization features reduce the operational overhead associated with managing complex AI infrastructure while providing detailed performance analytics that help organizations optimize resource utilization and identify potential bottlenecks in their machine learning pipelines.
Leverage advanced AI capabilities with Claude to analyze and optimize your server configurations for maximum machine learning performance and efficiency. HPE’s focus on workload optimization and performance analytics creates opportunities for intelligent resource management that can significantly improve the efficiency of machine learning operations while reducing operational costs.
Supermicro: Specialized AI Optimization
Supermicro Computer has carved out a distinctive position in the AI server market by focusing on highly specialized configurations optimized specifically for machine learning workloads, offering innovative architectural approaches that prioritize computational density, energy efficiency, and cost-effectiveness. The company’s expertise in designing custom server solutions for specific applications has resulted in AI-optimized systems that often deliver superior performance-per-dollar ratios compared to more generalized enterprise server offerings.
The Supermicro SYS-420GP-TNAR and AS-4124GS-TNR systems exemplify the company’s approach to AI server design, featuring innovative GPU mounting architectures that maximize cooling efficiency while enabling high-density GPU configurations. Supermicro’s engineering philosophy emphasizes direct-to-chip cooling, advanced airflow management, and optimized power delivery systems that enable sustained high-performance operation while maintaining energy efficiency. This focus on thermal and power optimization proves particularly valuable for organizations operating large-scale AI training facilities where energy costs represent a significant portion of total operational expenses.
Supermicro’s modular architecture approach allows for extensive customization of server configurations to match specific machine learning workload requirements. Organizations can select from a wide range of CPU, memory, storage, and networking options to create tailored configurations that optimize performance for particular AI applications. This customization capability extends to support for emerging technologies such as CXL memory expansion, high-bandwidth memory configurations, and specialized accelerators beyond traditional GPUs.
The company’s focus on open standards and broad ecosystem compatibility ensures that Supermicro systems can integrate effectively with diverse software stacks and management platforms. This openness proves particularly valuable for organizations with heterogeneous infrastructure environments or those requiring integration with specialized machine learning tools and frameworks that may not be as well-supported on more proprietary platforms.

Performance Architecture Comparison
The architectural approaches taken by Dell, HPE, and Supermicro reflect different philosophies regarding AI server optimization, each offering distinct advantages that appeal to different organizational requirements and deployment scenarios. Understanding these architectural differences provides critical insight into how each platform addresses the fundamental challenges of machine learning workload acceleration, including computational throughput, memory bandwidth, storage performance, and networking efficiency.
Dell’s PowerEdge architecture prioritizes balanced performance across diverse workload types, implementing sophisticated power management and thermal control systems that maintain consistent performance under varying computational loads. The PowerEdge systems feature advanced BIOS and UEFI configurations that optimize system behavior for machine learning applications while maintaining compatibility with traditional enterprise workloads. This balanced approach proves particularly valuable for organizations running mixed workloads or those transitioning from traditional computing infrastructure to AI-focused deployments.
HPE’s ProLiant architecture emphasizes sustained high-performance operation through innovative cooling solutions and advanced memory hierarchies that minimize computational bottlenecks. The systems feature optimized PCIe configurations that maximize GPU-to-CPU communication bandwidth while supporting high-speed networking interfaces that facilitate efficient distributed computing. HPE’s approach to memory architecture includes support for persistent memory technologies and advanced caching strategies that accelerate data access patterns common in machine learning applications.
Supermicro’s architectural approach focuses on maximizing computational density and energy efficiency through innovative mechanical designs and optimized component selection. The systems feature custom motherboard layouts that minimize signal path lengths, reduce electromagnetic interference, and optimize power delivery to critical components. This attention to electrical and mechanical optimization results in systems that can sustain higher computational loads while consuming less energy than comparable configurations from other manufacturers.
The networking architectures implemented by each manufacturer reflect different approaches to supporting distributed machine learning workloads. Dell emphasizes integration with software-defined networking solutions and cloud connectivity, HPE focuses on high-performance interconnects optimized for scientific computing, and Supermicro provides flexible networking options that can be customized for specific deployment requirements.
GPU Integration and Acceleration
The integration of GPU acceleration represents perhaps the most critical aspect of modern AI server configuration, as the parallel processing capabilities of graphics processing units have become fundamental to efficient machine learning operations. Each manufacturer approaches GPU integration differently, with varying implications for performance, cooling, power consumption, and long-term scalability that organizations must carefully consider when selecting AI infrastructure.
Dell’s PowerEdge systems implement sophisticated GPU cooling solutions that maintain optimal operating temperatures while minimizing acoustic noise levels, a consideration that becomes important in office environments or co-located facilities. The PowerEdge architecture supports flexible GPU configurations ranging from single-GPU development systems to eight-GPU training powerhouses, with optimized PCIe lane allocation that ensures each GPU receives sufficient bandwidth for maximum performance. Dell’s partnership with NVIDIA includes pre-validation of hardware and software configurations that reduce deployment complexity and minimize compatibility issues.
HPE’s approach to GPU integration leverages the company’s extensive experience with high-performance computing applications, implementing cooling and power delivery systems optimized for sustained high-utilization scenarios. The ProLiant and Apollo systems feature advanced liquid cooling options that enable higher GPU densities than air-cooled alternatives while maintaining quiet operation. HPE’s GPU configurations include support for specialized accelerators such as NVIDIA’s DGX-compatible architectures that optimize communication between GPUs for distributed training applications.
Supermicro’s GPU integration strategy emphasizes maximum computational density through innovative chassis designs that optimize airflow and cooling efficiency. The company’s systems often support higher GPU densities than comparable offerings from other manufacturers while maintaining competitive pricing. Supermicro’s flexible architecture allows organizations to mix different GPU types within the same system, enabling cost optimization strategies that balance performance requirements with budget constraints.
The software integration aspects of GPU acceleration vary significantly between manufacturers, with implications for deployment complexity, optimization capabilities, and ongoing maintenance requirements. Dell provides comprehensive software stacks that include optimized drivers, container environments, and management tools. HPE emphasizes integration with HPC software ecosystems and workload managers. Supermicro focuses on providing flexible platforms that support diverse software environments while minimizing proprietary lock-in.
Enhance your AI research capabilities with Perplexity to stay current with the latest developments in GPU technologies and optimization techniques that can maximize the performance of your machine learning infrastructure. The rapid evolution of GPU architectures and software frameworks requires continuous monitoring of technological developments to ensure optimal system configurations.
Memory and Storage Optimization
The memory and storage subsystems in AI servers play crucial roles in determining overall system performance, as machine learning workloads often involve processing massive datasets that must be efficiently moved between storage, system memory, and GPU memory hierarchies. The architectural approaches taken by Dell, HPE, and Supermicro in optimizing these subsystems reflect different priorities and design philosophies that can significantly impact application performance and operational efficiency.
Dell PowerEdge systems implement advanced memory configurations that support high-bandwidth DDR4 and DDR5 memory modules with optimized channel configurations that maximize memory throughput. The PowerEdge architecture includes support for persistent memory technologies such as Intel Optane that can accelerate data access patterns common in machine learning applications by providing large-capacity, high-speed storage that bridges the performance gap between traditional storage and system memory. Dell’s storage integration includes native support for NVMe SSDs in various form factors, enabling flexible storage configurations that can be optimized for specific application requirements.
HPE ProLiant systems emphasize memory bandwidth optimization through advanced memory controller configurations and support for high-performance memory modules that minimize latency in memory-intensive operations. The HPE architecture includes innovative memory expansion technologies that allow organizations to configure systems with exceptionally large memory capacities that can accommodate entire datasets in system memory, eliminating storage bottlenecks that might otherwise limit performance. HPE’s storage solutions include integration with the company’s enterprise storage portfolio, enabling seamless connectivity to high-performance storage arrays and distributed file systems.
Supermicro’s approach to memory and storage optimization focuses on providing flexible configurations that can be tailored to specific workload requirements while maintaining cost-effectiveness. The company’s systems support a wide range of memory configurations and storage technologies, allowing organizations to optimize price-performance ratios for their particular applications. Supermicro’s innovative storage architectures include support for high-density storage configurations that can accommodate large datasets locally while maintaining fast access speeds.
The integration of emerging memory technologies such as CXL (Compute Express Link) represents an area where architectural differences between manufacturers become particularly apparent. These technologies promise to revolutionize memory hierarchies in AI systems by enabling flexible, high-bandwidth memory expansion that can dramatically improve performance for memory-intensive machine learning applications.
Cooling and Power Management
The thermal and power management capabilities of AI servers represent critical factors that directly impact sustained performance, operational costs, and system reliability. Machine learning workloads typically operate GPUs and CPUs at high utilization levels for extended periods, creating thermal challenges that require sophisticated cooling solutions and power management strategies. The approaches taken by Dell, HPE, and Supermicro in addressing these challenges reflect different engineering priorities and operational philosophies.
Dell PowerEdge systems implement intelligent thermal management through advanced fan control algorithms and optimized airflow designs that maintain optimal component temperatures while minimizing energy consumption. The PowerEdge architecture includes predictive thermal modeling that adjusts cooling strategies based on workload patterns and environmental conditions, enabling efficient operation across diverse deployment scenarios. Dell’s power management capabilities include advanced power capping and dynamic power allocation features that help organizations optimize energy usage while maintaining performance requirements.
HPE’s approach to cooling emphasizes support for liquid cooling solutions that enable higher computational densities and improved energy efficiency compared to traditional air cooling approaches. The ProLiant and Apollo systems feature innovative cooling architectures that can accommodate both air and liquid cooling in hybrid configurations that optimize thermal management for specific deployment requirements. HPE’s power management includes sophisticated workload-aware power allocation that automatically adjusts system behavior to optimize energy efficiency while maintaining performance targets.
Supermicro’s cooling solutions focus on maximizing thermal efficiency through innovative chassis designs and optimized component placement that enhance natural airflow patterns. The company’s systems often achieve superior cooling performance through careful attention to aerodynamic principles and thermal modeling that optimize heat dissipation. Supermicro’s power management capabilities include flexible power supply configurations that enable organizations to optimize power delivery for specific workload requirements while maintaining efficiency.
The environmental impact considerations associated with cooling and power management have become increasingly important as organizations face pressure to reduce carbon footprints and improve sustainability. Each manufacturer offers different approaches to addressing these environmental concerns through improved energy efficiency, renewable energy integration, and advanced monitoring capabilities that enable optimization of environmental impact.
Networking and Interconnect Technologies
The networking capabilities of AI servers play increasingly important roles as machine learning workloads scale beyond single-node configurations and require efficient communication between distributed computational resources. Modern AI applications often involve training distributed models across multiple GPUs or even multiple servers, creating networking requirements that differ significantly from traditional enterprise applications. The networking approaches implemented by Dell, HPE, and Supermicro reflect different strategies for addressing these distributed computing challenges.
Dell PowerEdge systems emphasize integration with software-defined networking technologies and cloud connectivity solutions that facilitate hybrid deployment scenarios. The PowerEdge networking architecture includes native support for high-bandwidth Ethernet configurations, InfiniBand options for high-performance computing applications, and advanced network interface cards optimized for machine learning workloads. Dell’s networking solutions include integration with major cloud providers and support for container networking technologies that simplify the deployment of distributed AI applications.
HPE’s networking approach leverages the company’s extensive experience with high-performance computing interconnects, implementing advanced networking architectures optimized for low-latency, high-bandwidth communication between computational nodes. The ProLiant systems feature support for specialized interconnect technologies including Slingshot networking and advanced InfiniBand configurations that minimize communication overhead in distributed training applications. HPE’s networking solutions include integration with the company’s broader networking portfolio and support for advanced routing and switching technologies.
Supermicro’s networking capabilities focus on providing flexible, cost-effective solutions that can be customized for specific deployment requirements. The company’s systems support a wide range of networking technologies and can be configured with multiple network interfaces to support complex networking topologies. Supermicro’s approach emphasizes open standards and broad compatibility with diverse networking equipment and protocols.
The emergence of specialized networking technologies for AI applications, such as NVIDIA’s NVLink and advanced GPU-to-GPU communication protocols, represents an area where manufacturer support and optimization capabilities can significantly impact application performance. Understanding how each platform supports these emerging technologies provides important insight into long-term scalability and performance potential.
Cost Analysis and Value Proposition
The financial considerations associated with AI server procurement extend beyond initial hardware costs to encompass operational expenses, maintenance requirements, upgrade pathways, and total cost of ownership over the system lifecycle. Organizations must carefully evaluate these comprehensive cost factors when selecting AI infrastructure, as the choice of server platform can significantly impact both immediate budget requirements and long-term financial commitments.
Dell PowerEdge systems typically command premium pricing that reflects the comprehensive enterprise support ecosystem, advanced management capabilities, and extensive validation testing that characterizes Dell’s approach to server design. However, this premium pricing often translates to lower operational costs through reduced maintenance requirements, improved reliability, and sophisticated management tools that minimize administrative overhead. Dell’s financing options and leasing programs provide flexibility for organizations managing capital expenditure constraints while requiring immediate access to AI infrastructure.
HPE ProLiant systems generally price competitively with Dell offerings while providing distinctive value through the company’s high-performance computing expertise and advanced cooling technologies. HPE’s value proposition emphasizes performance optimization and energy efficiency that can result in lower operational costs over the system lifecycle. The company’s support services and professional consulting capabilities provide additional value for organizations requiring assistance with complex AI deployments or optimization projects.
Supermicro systems typically offer the most aggressive pricing among the three manufacturers, reflecting the company’s focus on cost optimization and efficient manufacturing processes. This pricing advantage often enables organizations to deploy larger-scale AI infrastructure within constrained budgets or to achieve better price-performance ratios for specific applications. However, organizations must carefully evaluate the trade-offs associated with more limited support ecosystems and potentially higher operational complexity.
The consideration of cloud alternatives versus on-premises deployment represents an important factor in cost analysis, as cloud services may provide cost advantages for certain workload patterns while on-premises infrastructure may prove more economical for sustained, high-utilization applications. Each manufacturer offers different approaches to hybrid cloud integration that can influence these cost considerations.
Management and Orchestration Capabilities
The complexity of modern AI infrastructure requires sophisticated management and orchestration capabilities that can automate routine tasks, optimize resource utilization, and provide comprehensive monitoring of system health and performance. The management platforms offered by Dell, HPE, and Supermicro reflect different approaches to addressing these operational challenges, with varying implications for administrative overhead, operational efficiency, and long-term maintainability.
Dell’s OpenManage Enterprise platform provides centralized management capabilities that span individual servers, storage systems, and networking equipment, creating unified operational visibility across complex AI infrastructure deployments. The platform includes automated provisioning capabilities that can rapidly deploy new AI workloads, comprehensive monitoring that tracks system health and performance metrics, and predictive analytics that identify potential issues before they impact operations. Dell’s management approach emphasizes integration with popular orchestration platforms such as Kubernetes and container management systems that are increasingly common in AI deployments.
HPE OneView represents the company’s approach to infrastructure management, providing automated lifecycle management capabilities that span server provisioning, configuration management, and ongoing optimization. OneView includes sophisticated workload placement algorithms that optimize resource utilization across large server clusters and advanced analytics capabilities that provide insights into performance trends and optimization opportunities. HPE’s management platform emphasizes integration with the broader HPC software ecosystem and support for specialized workload managers commonly used in scientific computing environments.
Supermicro’s management approach focuses on providing flexible, standards-based management capabilities that integrate well with existing operational tools and processes. The company’s SuperDoctor and other management utilities provide comprehensive monitoring and configuration capabilities while maintaining compatibility with industry-standard management protocols. Supermicro’s approach emphasizes openness and flexibility, allowing organizations to integrate the systems with diverse management platforms and operational workflows.
The integration of artificial intelligence capabilities into infrastructure management represents an emerging trend that promises to revolutionize operational efficiency through intelligent automation, predictive maintenance, and adaptive optimization. Understanding how each manufacturer approaches AI-powered management provides insight into future operational capabilities and competitive advantages.
Security and Compliance Considerations
The security requirements associated with AI infrastructure encompass both traditional cybersecurity concerns and unique challenges related to protecting intellectual property, ensuring data privacy, and maintaining compliance with evolving regulatory requirements. The security approaches implemented by Dell, HPE, and Supermicro reflect different strategies for addressing these multifaceted security challenges while maintaining the performance and functionality required for effective AI operations.
Dell PowerEdge systems implement comprehensive security frameworks that include hardware-based root of trust technologies, encrypted storage capabilities, and advanced access control mechanisms that protect against unauthorized access and data breaches. Dell’s security approach includes integration with enterprise identity management systems, support for regulatory compliance frameworks such as GDPR and HIPAA, and sophisticated audit capabilities that track system access and configuration changes. The PowerEdge security architecture includes support for confidential computing technologies that protect data and algorithms during processing, a capability that becomes particularly important for organizations working with sensitive or proprietary AI models.
HPE ProLiant systems emphasize security through the company’s Silicon Root of Trust technology and comprehensive firmware protection capabilities that prevent unauthorized modifications to system software. HPE’s security approach includes advanced encryption capabilities that protect data both at rest and in transit, sophisticated access control mechanisms, and integration with security information and event management systems. The company’s focus on high-performance computing environments includes specialized security considerations for distributed computing scenarios where multiple nodes must communicate securely while maintaining performance requirements.
Supermicro’s security capabilities focus on providing fundamental security features while maintaining system flexibility and cost-effectiveness. The company’s systems include hardware-based security features such as TPM modules, secure boot capabilities, and encrypted storage options that provide protection against common security threats. Supermicro’s approach emphasizes compatibility with diverse security tools and frameworks, enabling organizations to implement customized security solutions that meet specific requirements.
The emerging regulatory landscape surrounding AI applications, including requirements for algorithm transparency, data protection, and bias prevention, creates additional compliance considerations that organizations must address through their infrastructure choices. Understanding how each manufacturer supports these evolving compliance requirements provides important insight into long-term regulatory risk management.
Future-Proofing and Scalability
The rapid pace of innovation in AI technologies creates significant challenges for organizations attempting to select infrastructure that will remain relevant and efficient as algorithms, software frameworks, and hardware technologies continue to evolve. The approaches taken by Dell, HPE, and Supermicro in designing scalable, upgradeable systems reflect different strategies for addressing these future-proofing challenges while maintaining current performance and cost-effectiveness.
Dell PowerEdge systems emphasize modular scalability through standardized expansion slots, flexible memory configurations, and support for emerging technologies such as CXL memory expansion and advanced accelerator cards. Dell’s future-proofing strategy includes regular firmware updates that add support for new technologies and optimize performance for evolving workloads. The PowerEdge architecture includes provisions for hardware upgrades that can extend system lifecycles and accommodate changing requirements without requiring complete system replacement.
HPE’s approach to future-proofing leverages the company’s research and development investments in emerging computing technologies, including quantum computing research, advanced memory architectures, and specialized AI accelerators. HPE ProLiant systems include support for emerging interconnect technologies and advanced cooling solutions that can accommodate future high-performance components. The company’s roadmap includes integration with emerging technologies such as neuromorphic computing and specialized AI chips that may become important in future AI applications.
Supermicro’s future-proofing strategy emphasizes flexible architectures that can accommodate diverse hardware configurations and emerging technologies through modular design principles. The company’s systems often support a wider range of component options than competitors, providing organizations with flexibility to adopt new technologies as they become available. Supermicro’s approach includes support for emerging form factors and connector standards that may become important as AI hardware continues to evolve.
The consideration of software compatibility and framework support represents an important aspect of future-proofing, as AI software ecosystems continue to evolve rapidly. Understanding how each manufacturer supports emerging software technologies and maintains compatibility with evolving frameworks provides insight into long-term operational sustainability and performance optimization opportunities.
Implementation Strategies and Best Practices
The successful deployment of AI server infrastructure requires careful planning, systematic implementation, and ongoing optimization to achieve optimal performance and operational efficiency. The complexity of modern AI applications and the specialized requirements of machine learning workloads create unique implementation challenges that benefit from strategic approaches tailored to specific organizational requirements and technical constraints.
Organizations embarking on AI infrastructure projects should begin with comprehensive workload analysis that identifies specific performance requirements, scalability needs, and operational constraints that will influence server selection and configuration decisions. This analysis should encompass current machine learning applications and anticipated future requirements, enabling selection of infrastructure that can accommodate growth and evolving technology needs. The workload analysis should consider factors such as training dataset sizes, model complexity, inference performance requirements, and expected user concurrency that will impact system sizing and configuration decisions.
The phased implementation approach often proves most effective for large-scale AI deployments, enabling organizations to validate performance characteristics, optimize configurations, and refine operational processes before committing to full-scale infrastructure deployment. Initial pilot deployments using representative workloads can provide valuable insights into performance characteristics, operational requirements, and potential optimization opportunities that inform subsequent scaling decisions. This phased approach also enables organizations to develop operational expertise and refine management processes before dealing with the complexity of large-scale deployments.
Performance optimization represents an ongoing process that requires continuous monitoring, analysis, and adjustment of system configurations to maintain optimal efficiency as workloads evolve and scale. Organizations should implement comprehensive monitoring systems that track key performance indicators including GPU utilization, memory bandwidth, storage throughput, and network performance. This monitoring data provides the foundation for identifying bottlenecks, optimizing resource allocation, and planning capacity expansion to maintain performance as demand grows.
The integration of automation technologies and orchestration platforms can significantly improve operational efficiency and reduce administrative overhead associated with managing complex AI infrastructure. Container technologies, Kubernetes orchestration, and automated provisioning systems enable organizations to deploy and manage AI workloads more efficiently while maintaining consistency and reliability across diverse deployment scenarios.
Conclusion and Strategic Recommendations
The selection of optimal AI server infrastructure represents a strategic decision that will impact organizational AI capabilities for years to come, requiring careful evaluation of technical requirements, operational constraints, and long-term objectives. Each manufacturer offers distinctive advantages that appeal to different organizational priorities and deployment scenarios, with no single solution providing optimal characteristics for all possible applications and requirements.

Dell PowerEdge systems excel in enterprise environments where reliability, comprehensive support, and seamless integration with existing infrastructure represent primary considerations. Organizations prioritizing operational stability, extensive vendor support, and proven enterprise-grade solutions will find Dell’s offerings particularly compelling despite premium pricing. The PowerEdge platform provides an excellent foundation for organizations transitioning from traditional enterprise computing to AI-focused infrastructure while maintaining operational consistency and support quality.
HPE ProLiant and Apollo systems provide exceptional value for organizations with high-performance computing backgrounds or those requiring sustained high-performance operation under demanding computational loads. The company’s expertise in thermal management, advanced cooling solutions, and HPC optimization creates advantages for computationally intensive applications that require sustained performance over extended periods. Organizations with scientific computing backgrounds or those planning large-scale distributed training operations should strongly consider HPE solutions.
Supermicro systems offer compelling value propositions for organizations prioritizing cost-effectiveness, customization flexibility, and maximum performance-per-dollar ratios. The company’s focus on specialized AI optimization and innovative engineering approaches often results in superior price-performance characteristics that enable larger-scale deployments within constrained budgets. Organizations with internal technical expertise and those requiring highly customized configurations will benefit from Supermicro’s flexible approach.
The future trajectory of AI server technology suggests continued evolution toward specialized architectures, improved energy efficiency, and enhanced integration with emerging technologies such as quantum computing and neuromorphic processing. Organizations should consider these technological trends when making infrastructure investments, selecting platforms that provide flexibility and upgrade pathways that can accommodate future innovations while maximizing the value of current investments.
Disclaimer
This article provides general information about AI server technologies and manufacturer capabilities for educational purposes. The information presented reflects publicly available specifications and general market conditions at the time of writing. Readers should conduct thorough evaluation of specific products, obtain current pricing and specifications directly from manufacturers, and consider their unique requirements when making infrastructure decisions. Performance characteristics may vary based on specific configurations, workloads, and deployment environments. Organizations should engage with qualified technical professionals and conduct proof-of-concept testing before making significant infrastructure investments.