
The relentless pursuit of computational efficiency in artificial intelligence applications has driven developers to explore the deepest layers of computer architecture, where assembly language optimization emerges as the ultimate frontier for achieving unprecedented inference performance. In an era where milliseconds can determine the success or failure of real-time AI applications, the ability to craft hand-tuned assembly code that leverages every available CPU cycle becomes not merely an academic exercise but a critical competitive advantage that separates exceptional systems from merely adequate ones.
Discover the latest AI optimization trends that are pushing the boundaries of what’s possible in high-performance computing and machine learning acceleration. The intersection of traditional assembly programming with modern AI workloads represents a fascinating convergence of classical computer science principles and cutting-edge artificial intelligence requirements, demanding a unique blend of low-level hardware understanding and high-level algorithmic insight.
The Critical Performance Imperative
Modern AI inference workloads operate under increasingly stringent performance constraints that traditional high-level programming languages and even optimized compilers cannot adequately address. The computational demands of neural network inference, particularly in edge computing environments where power consumption and thermal constraints add additional complexity, require optimization strategies that extend far beyond conventional software engineering practices. Assembly language optimization provides direct access to processor-specific instruction sets, enabling developers to exploit specialized features such as SIMD vector operations, advanced memory prefetching mechanisms, and hardware-specific acceleration capabilities that remain inaccessible through higher-level programming abstractions.
The performance benefits achievable through assembly optimization are not merely incremental improvements but can represent order-of-magnitude gains in specific computational kernels that form the backbone of AI inference operations. Matrix multiplication routines, convolution operations, activation functions, and memory access patterns can be optimized to achieve theoretical hardware limits, transforming inference latency from prohibitive bottlenecks into negligible overheads that enable real-time AI applications previously considered impossible.
Understanding Modern CPU Architecture for AI Workloads
Contemporary processor architectures have evolved to include sophisticated features specifically designed to accelerate the types of mathematical operations fundamental to artificial intelligence computations. Modern CPUs incorporate multiple levels of parallelism, from instruction-level parallelism through out-of-order execution and speculative execution, to data-level parallelism through SIMD instruction sets such as AVX-512, NEON, and various vendor-specific extensions that can process multiple data elements simultaneously within a single instruction cycle.
The memory hierarchy in modern processors represents another critical optimization target, with multiple levels of cache memory, sophisticated prefetching mechanisms, and non-uniform memory access patterns that can dramatically impact performance when properly understood and exploited. Assembly language programming provides direct control over these architectural features, enabling developers to craft code that minimizes cache misses, maximizes memory bandwidth utilization, and leverages advanced features such as memory streaming and software prefetching to maintain consistent data flow to computational units.
Experience advanced AI development with Claude for comprehensive assistance in understanding complex optimization strategies and architectural considerations. The synergy between human expertise in low-level optimization and AI assistance in analyzing performance characteristics creates unprecedented opportunities for achieving optimal system performance.
SIMD Instruction Sets and Vector Operations
Single Instruction, Multiple Data operations represent the cornerstone of efficient AI inference implementation at the assembly level, enabling the simultaneous processing of multiple data elements that characterizes the parallel nature of neural network computations. Modern SIMD instruction sets provide increasingly sophisticated capabilities, with AVX-512 supporting 512-bit vector operations that can process sixteen single-precision floating-point values or eight double-precision values in a single instruction cycle, effectively multiplying computational throughput by factors that directly translate to inference performance improvements.
The effective utilization of SIMD instructions requires careful attention to data alignment, memory access patterns, and instruction scheduling that goes beyond simple vectorization concepts. Advanced techniques such as data interleaving, register blocking, and instruction pipelining become essential for achieving peak performance, particularly when dealing with the irregular memory access patterns and varying computational requirements characteristic of different neural network architectures and layer types.
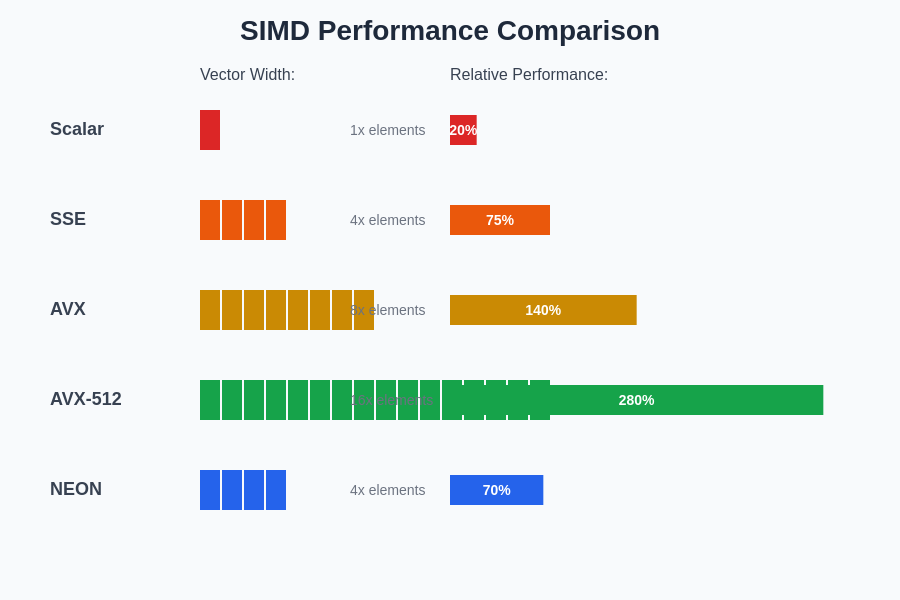
The performance advantages of different SIMD instruction sets demonstrate the substantial computational throughput gains achievable through vectorized operations. Modern processors offer increasingly sophisticated vector processing capabilities that can dramatically accelerate AI inference workloads when properly utilized through assembly-level optimization techniques.
Memory Optimization Strategies
Memory access optimization represents perhaps the most critical aspect of assembly-level AI inference optimization, as the disparity between processor computational capacity and memory bandwidth continues to widen with each generation of hardware improvements. The careful orchestration of memory access patterns, cache utilization, and data prefetching can determine whether computational units remain fully utilized or suffer from memory-bound performance limitations that severely constrain overall system throughput.
Advanced memory optimization techniques include software-controlled prefetching, cache-aware data structures, memory access coalescing, and the strategic use of different memory types and access modes available in modern processor architectures. The implementation of custom memory management strategies that align with specific AI workload characteristics can yield substantial performance improvements, particularly in scenarios involving large model parameters, extensive intermediate computations, or complex data dependency patterns that challenge conventional memory optimization approaches.
Matrix Operations and Linear Algebra Kernels
The foundation of neural network inference rests upon highly optimized linear algebra operations, with matrix multiplication serving as the computational kernel that determines overall system performance in most AI applications. Assembly-level optimization of matrix operations involves sophisticated techniques such as register tiling, cache blocking, loop unrolling, and instruction scheduling that transform theoretical algorithmic complexity into practical performance characteristics that approach hardware theoretical limits.
The optimization of matrix multiplication routines requires deep understanding of both the mathematical properties of linear algebra operations and the architectural characteristics of target processors, including register file organization, functional unit availability, memory hierarchy behavior, and instruction latency considerations. Advanced implementations often incorporate multiple optimization strategies simultaneously, with different code paths optimized for different matrix sizes, data types, and computational requirements to ensure optimal performance across diverse inference scenarios.
Leverage Perplexity for research into the latest developments in hardware acceleration and optimization techniques that continue to push the boundaries of what’s achievable in high-performance computing applications. The rapid evolution of processor architectures and instruction sets demands continuous learning and adaptation of optimization strategies.
Activation Function Optimization
Neural network activation functions, while conceptually simple mathematical operations, present unique optimization challenges when implemented at the assembly level due to their diverse computational requirements and the frequency with which they are executed throughout inference processes. The optimization of activation functions such as ReLU, sigmoid, tanh, and more complex variants like swish and GELU requires careful consideration of mathematical approximation techniques, SIMD instruction utilization, and branch prediction optimization to achieve maximum throughput.
Advanced activation function implementations often employ lookup tables, polynomial approximations, or specialized instruction sequences that balance computational accuracy with performance requirements. The choice of optimization strategy depends on the specific accuracy requirements of the target application, available processor features, and the broader context of the inference pipeline within which these functions operate.
Convolution Operation Acceleration
Convolutional neural networks present particularly interesting optimization challenges at the assembly level, as convolution operations involve complex data access patterns, varying computational requirements based on kernel sizes and stride parameters, and opportunities for sophisticated optimization techniques such as im2col transformations, Winograd algorithms, and FFT-based convolution methods that can dramatically alter computational requirements and memory access characteristics.
The implementation of optimized convolution kernels requires careful analysis of data reuse patterns, memory access optimization, and the exploitation of spatial locality characteristics inherent in image and signal processing applications. Advanced implementations often incorporate multiple algorithmic approaches with dynamic selection based on convolution parameters, input dimensions, and available computational resources to ensure optimal performance across diverse network architectures and input conditions.
Branch Prediction and Control Flow Optimization
The control flow characteristics of AI inference operations present unique challenges for assembly-level optimization, as neural networks often incorporate conditional operations, dynamic routing mechanisms, and data-dependent computational paths that can significantly impact processor pipeline efficiency and branch prediction accuracy. The careful structuring of conditional operations, loop constructs, and function call patterns becomes critical for maintaining high instruction throughput and avoiding pipeline stalls that can severely degrade performance.
Advanced control flow optimization techniques include branch elimination through mathematical transformations, predicated execution using conditional instructions, and the strategic use of lookup tables or computed gotos to replace complex conditional logic with more predictable execution patterns. The optimization of control flow requires deep understanding of target processor pipeline characteristics and branch prediction mechanisms to ensure that code structure aligns with hardware capabilities.
Cache Optimization and Memory Hierarchy Management
The effective utilization of processor cache hierarchies represents a critical success factor in assembly-level AI inference optimization, as the multi-level cache systems in modern processors can either accelerate or severely constrain computational performance depending on how effectively code and data access patterns align with cache organization and replacement policies. The optimization of cache utilization requires careful attention to data structures, access patterns, prefetching strategies, and memory layout decisions that directly impact cache hit rates and memory bandwidth utilization.
Advanced cache optimization techniques include cache-aware algorithm design, data structure padding and alignment, software-controlled prefetching, and the strategic use of cache hints and memory access instructions that provide explicit control over cache behavior. The implementation of cache-friendly data layouts and access patterns often requires fundamental reconsideration of algorithmic approaches to ensure that computational efficiency aligns with memory system capabilities.

Understanding the performance characteristics of different memory hierarchy levels enables developers to craft optimization strategies that maximize data throughput and minimize access latency. The dramatic differences in bandwidth and latency between memory levels underscore the critical importance of cache-aware programming in assembly-level optimization.
Processor-Specific Optimization Techniques
Different processor architectures offer unique optimization opportunities that require specialized knowledge and implementation strategies to fully exploit available performance potential. Intel processors provide features such as AVX-512 instructions, advanced vector extensions, and sophisticated prefetching mechanisms, while ARM processors offer NEON SIMD capabilities, efficient power management features, and architectural characteristics optimized for mobile and embedded applications that present different optimization trade-offs and opportunities.
The development of processor-specific optimization strategies requires deep understanding of architectural documentation, performance characteristics, and the subtle differences in instruction behavior, memory system organization, and execution unit capabilities that distinguish different processor families. Advanced implementations often incorporate runtime detection of processor capabilities with dynamic code path selection to ensure optimal performance across diverse hardware platforms while maintaining code maintainability and portability.
Performance Measurement and Profiling
The validation and refinement of assembly-level optimizations require sophisticated performance measurement and profiling techniques that go beyond traditional software profiling tools to provide detailed insights into processor behavior, memory system utilization, and instruction-level performance characteristics. Hardware performance counters, specialized profiling tools, and custom measurement frameworks become essential for understanding the impact of optimization decisions and identifying remaining performance bottlenecks that may not be apparent through high-level analysis.
Advanced profiling techniques include cycle-accurate performance analysis, cache miss characterization, branch prediction analysis, and instruction throughput measurement that provide the detailed feedback necessary for iterative optimization refinement. The development of effective profiling strategies often requires custom tooling and measurement frameworks tailored to specific optimization objectives and performance requirements.
Integration with High-Level AI Frameworks
The practical deployment of assembly-optimized AI inference kernels requires careful integration with existing AI frameworks and development ecosystems that typically operate at much higher levels of abstraction. The development of effective integration strategies involves creating appropriate interfaces, maintaining compatibility with existing APIs, and ensuring that low-level optimizations can be effectively utilized within broader AI application architectures without compromising development productivity or system maintainability.
Advanced integration techniques include the development of optimized kernel libraries, dynamic dispatch mechanisms, and hybrid approaches that combine assembly-optimized critical paths with higher-level framework functionality for non-critical operations. The successful integration of assembly optimizations often requires careful architectural design that balances performance benefits with development complexity and long-term maintainability considerations.
Future Directions and Emerging Technologies
The landscape of processor architectures and AI acceleration technologies continues to evolve rapidly, with emerging technologies such as specialized AI accelerators, quantum computing capabilities, and advanced memory technologies presenting new optimization opportunities and challenges that will shape future assembly-level optimization strategies. The development of forward-looking optimization approaches requires understanding of technological trends, architectural evolution, and the changing requirements of AI applications that will determine future performance requirements and optimization opportunities.
The continued advancement of AI model architectures, computational requirements, and deployment scenarios ensures that assembly-level optimization will remain a critical capability for achieving optimal performance in demanding applications. The intersection of traditional processor optimization techniques with emerging AI acceleration technologies presents exciting opportunities for achieving unprecedented levels of computational efficiency and performance that will enable new classes of AI applications and use cases.
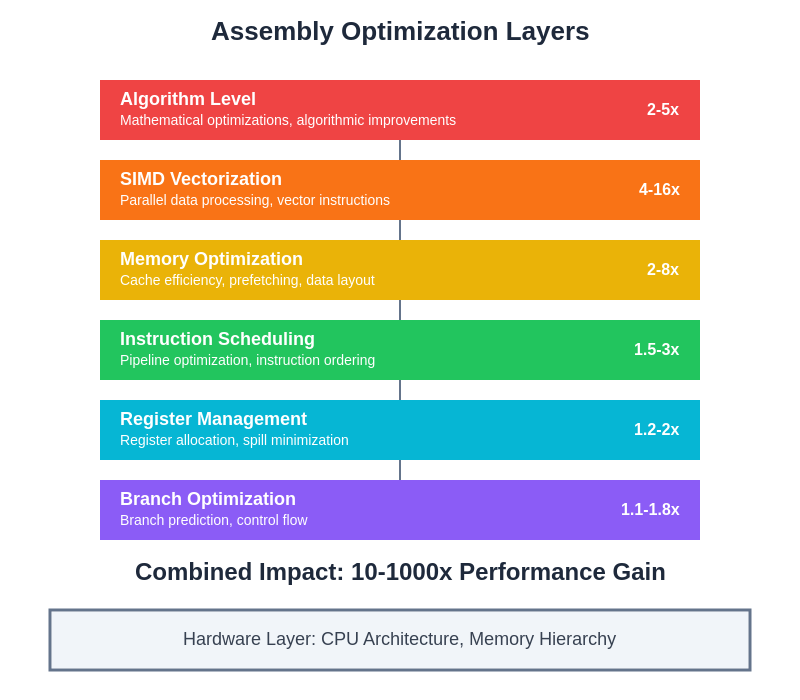
The systematic application of multiple optimization layers creates compounding performance improvements that can achieve dramatic speedups in AI inference applications. Each optimization level contributes unique performance benefits that combine to deliver transformational improvements in computational efficiency and system throughput.
The mastery of assembly-level optimization for AI inference represents a unique combination of traditional computer science principles and cutting-edge artificial intelligence requirements that demands continuous learning, experimentation, and adaptation to evolving technological landscapes. The developers who can effectively navigate this complex optimization space will be positioned to create AI systems that push the boundaries of what’s possible in terms of performance, efficiency, and capability, ultimately enabling the next generation of intelligent applications that seamlessly integrate advanced AI capabilities into everyday computing experiences.
Disclaimer
This article is for educational and informational purposes only and does not constitute professional advice. The techniques described require advanced programming expertise and thorough testing before production deployment. Performance results may vary significantly based on specific hardware configurations, software environments, and application requirements. Readers should conduct comprehensive testing and validation before implementing assembly-level optimizations in production systems. The author assumes no responsibility for any issues arising from the implementation of techniques discussed in this article.