
Amazon SageMaker represents one of the most comprehensive and powerful machine learning platforms available in the cloud computing ecosystem, providing data scientists and machine learning engineers with a complete suite of tools for building, training, and deploying machine learning models at scale. This comprehensive tutorial will guide you through the entire process of creating an end-to-end machine learning pipeline using SageMaker, from initial data ingestion and preparation through model training, evaluation, deployment, and ongoing monitoring in production environments.
Discover the latest AI and ML trends to stay current with rapidly evolving machine learning technologies and best practices that are shaping the future of data science and artificial intelligence applications. The journey from experimental machine learning models to production-ready systems requires careful consideration of numerous factors including data quality, model performance, scalability, cost optimization, and operational reliability.
Understanding AWS SageMaker Architecture
AWS SageMaker provides a fully managed machine learning service that eliminates the complexity of managing underlying infrastructure while providing powerful tools for every stage of the machine learning lifecycle. The platform consists of several key components that work together to create a seamless development and deployment experience for machine learning practitioners working on projects of any scale or complexity.
The SageMaker architecture includes SageMaker Studio for interactive development, SageMaker Notebooks for exploratory data analysis, SageMaker Processing for data preprocessing and feature engineering, SageMaker Training for model development, SageMaker Endpoints for real-time inference, SageMaker Batch Transform for batch predictions, and SageMaker Pipelines for orchestrating complete machine learning workflows. This comprehensive ecosystem ensures that every aspect of machine learning development is supported with enterprise-grade tools and capabilities.
Understanding the relationships between these components is crucial for designing effective machine learning pipelines that can handle the demands of production environments while maintaining flexibility for experimentation and iteration. The modular nature of SageMaker allows teams to adopt individual components as needed or implement complete end-to-end solutions depending on their specific requirements and organizational constraints.
Setting Up Your SageMaker Environment
Before diving into pipeline development, establishing a properly configured SageMaker environment is essential for ensuring smooth development workflows and maintaining security best practices. The setup process involves creating appropriate IAM roles, configuring VPC settings if required, setting up S3 buckets for data storage, and initializing SageMaker Studio or notebook instances for development work.
The IAM role configuration is particularly critical as it determines what AWS services and resources your SageMaker instances can access during training and inference operations. The role must include permissions for S3 access, CloudWatch logging, ECR for custom container images, and any additional services your specific use case requires. Proper security configuration at this stage prevents many common issues that can arise during model development and deployment phases.
Experience advanced AI capabilities with Claude for assistance with complex AWS configurations and machine learning architecture decisions that require careful analysis and strategic planning. The initial environment setup phase often determines the success and efficiency of subsequent development work, making it worth investing time to establish robust foundations.
Data Ingestion and Storage Strategy
Effective data management forms the cornerstone of successful machine learning pipelines, and SageMaker provides multiple approaches for handling data ingestion, storage, and access patterns depending on your specific requirements and constraints. The platform supports various data sources including S3, databases, streaming data sources, and external APIs, allowing for flexible integration with existing data infrastructure and workflows.
S3 serves as the primary data lake for most SageMaker implementations, providing scalable, durable, and cost-effective storage for training datasets, model artifacts, and pipeline outputs. Organizing data in S3 with appropriate folder structures, lifecycle policies, and access controls ensures efficient data access during training while managing storage costs effectively. The S3 integration with SageMaker supports both file-based and streaming data access patterns, enabling optimization for different types of machine learning workloads.
Data versioning and lineage tracking become increasingly important as machine learning projects mature and require reproducible results across different experiments and model iterations. SageMaker integrates with AWS services like AWS Glue for data cataloging and lineage tracking, providing comprehensive visibility into data transformations and dependencies throughout the machine learning pipeline.
Data Preprocessing and Feature Engineering
Data preprocessing and feature engineering represent critical stages in the machine learning pipeline where raw data is transformed into features suitable for model training. SageMaker Processing provides a managed service for running data processing workloads at scale, supporting both built-in processors and custom processing scripts written in popular frameworks like Pandas, Spark, and scikit-learn.
The preprocessing stage typically involves data cleaning, handling missing values, outlier detection and treatment, categorical variable encoding, numerical feature scaling, and feature selection or dimensionality reduction. SageMaker Processing allows these operations to be performed on large datasets using distributed computing resources, ensuring that preprocessing steps can scale with your data volume and complexity requirements.
Feature engineering often requires domain expertise and iterative experimentation to identify the most predictive features for your specific use case. SageMaker provides tools for feature store management through SageMaker Feature Store, enabling teams to create, share, and reuse features across multiple projects and models. This centralized approach to feature management promotes consistency, reduces duplication of effort, and enables better collaboration between data science teams.
Model Development and Training
The model development phase in SageMaker offers flexibility in choosing between built-in algorithms, framework-based training with popular libraries like TensorFlow and PyTorch, or completely custom algorithms packaged in Docker containers. This flexibility ensures that data scientists can use their preferred tools and techniques while benefiting from SageMaker’s managed infrastructure and optimization capabilities.
SageMaker’s built-in algorithms are optimized for performance and cost-effectiveness, covering common use cases such as linear regression, XGBoost, image classification, natural language processing, and recommendation systems. These algorithms are designed to work efficiently with large datasets and can automatically handle many optimization tasks such as hyperparameter tuning and distributed training across multiple instances.
For more complex or specialized models, SageMaker supports custom training scripts and containers, allowing complete control over the training process while still benefiting from managed infrastructure. The platform handles resource provisioning, monitoring, and cleanup automatically, enabling data scientists to focus on model development rather than infrastructure management. Training jobs can be configured to use spot instances for cost optimization, automatic model tuning for hyperparameter optimization, and distributed training for handling large datasets or complex models.
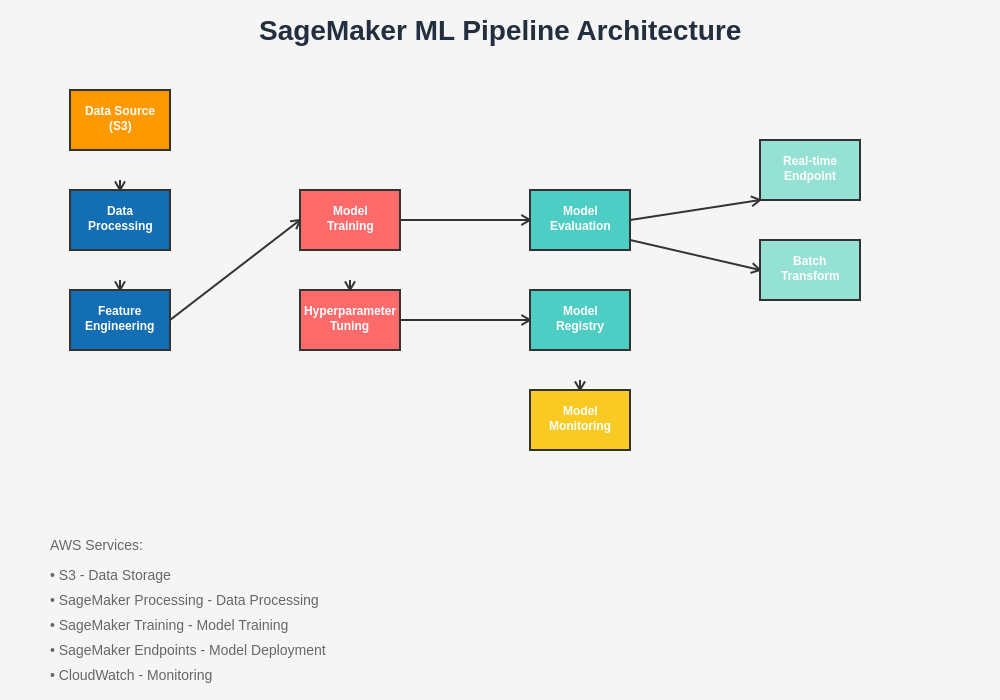
The comprehensive SageMaker architecture demonstrates how different components work together to create a seamless machine learning development and deployment experience. This visual representation illustrates the flow from data ingestion through model training, evaluation, and deployment, highlighting the integration points and data flow between different services and components.
Hyperparameter Optimization and Model Tuning
Hyperparameter optimization represents one of the most time-consuming aspects of machine learning model development, often requiring extensive experimentation to identify optimal configurations. SageMaker Automatic Model Tuning automates this process by intelligently searching the hyperparameter space using Bayesian optimization techniques, significantly reducing the time and computational resources required to achieve optimal model performance.
The hyperparameter tuning process in SageMaker can be configured to optimize various metrics including accuracy, precision, recall, F1-score, or custom business metrics depending on your specific objectives. The service automatically manages the training job orchestration, resource allocation, and early stopping criteria to maximize efficiency while exploring the hyperparameter space effectively.
Advanced tuning strategies such as multi-objective optimization, warm start tuning using previous tuning job results, and conditional hyperparameters for complex model architectures are supported, enabling sophisticated optimization approaches for complex machine learning problems. The tuning process generates comprehensive reports and visualizations that provide insights into hyperparameter sensitivity and model behavior across different configurations.
Model Evaluation and Validation
Comprehensive model evaluation goes beyond simple accuracy metrics to include bias detection, fairness assessment, explainability analysis, and performance evaluation across different data segments. SageMaker Clarify provides tools for detecting bias in training data and model predictions, ensuring that machine learning models meet ethical and regulatory requirements for fairness and transparency.
The evaluation process should include both offline evaluation using holdout datasets and online evaluation through A/B testing or shadow deployment strategies. SageMaker supports various evaluation approaches including cross-validation, time-series validation for temporal data, and custom evaluation metrics tailored to specific business objectives and constraints.
Model interpretability and explainability have become increasingly important for regulatory compliance and stakeholder trust. SageMaker Clarify provides SHAP (SHapley Additive exPlanations) values and other explainability techniques that help understand feature importance and model decision-making processes. This capability is particularly crucial for applications in regulated industries such as finance, healthcare, and legal services where model transparency is required.
Enhance your research capabilities with Perplexity to stay informed about the latest developments in model evaluation techniques, bias detection methods, and regulatory requirements that impact machine learning deployment in various industries and use cases.
Model Deployment Strategies
SageMaker provides multiple deployment options to accommodate different use cases, performance requirements, and cost constraints. Real-time endpoints provide low-latency inference for applications requiring immediate predictions, while batch transform jobs offer cost-effective processing for large datasets that don’t require real-time responses. Multi-model endpoints enable hosting multiple models on a single endpoint, optimizing resource utilization for scenarios with multiple related models.
The deployment process includes considerations for auto-scaling policies, instance types, and geographical distribution for global applications. SageMaker endpoints can automatically scale based on traffic patterns, ensuring optimal performance during peak usage while minimizing costs during low-traffic periods. The platform supports both CPU and GPU instances, allowing optimization for different types of models and inference requirements.
Advanced deployment patterns such as blue-green deployments, canary releases, and A/B testing are supported through SageMaker’s integration with other AWS services. These deployment strategies enable safe rollouts of new model versions while minimizing risk and maintaining service availability. The platform also supports real-time model updates and rollback capabilities for rapid response to issues or performance changes.
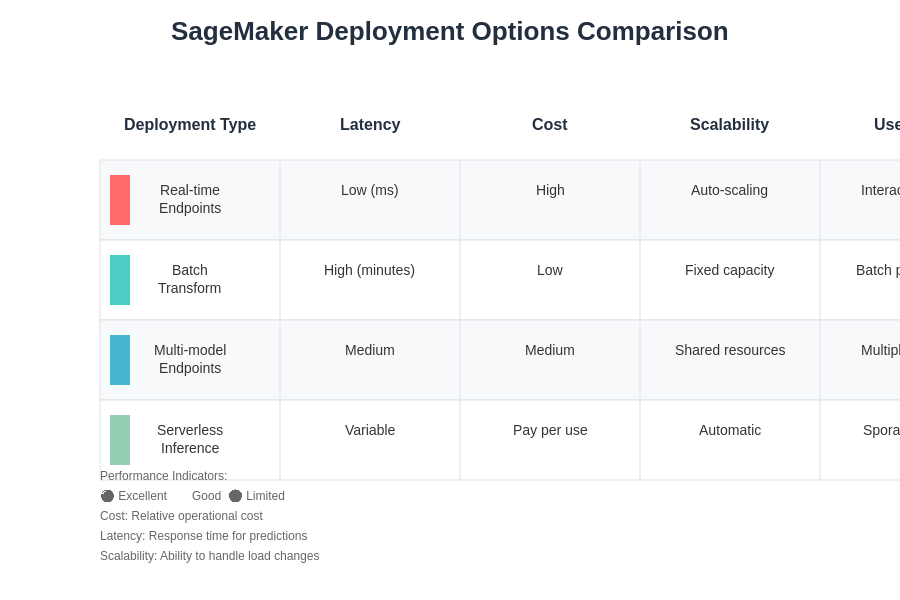
Different deployment strategies offer various trade-offs between cost, latency, scalability, and operational complexity. Understanding these trade-offs is essential for selecting the most appropriate deployment approach for your specific use case and operational requirements.
Pipeline Orchestration with SageMaker Pipelines
SageMaker Pipelines provides a purpose-built workflow orchestration service for machine learning that enables the creation of repeatable, automated ML workflows. Unlike general-purpose workflow tools, SageMaker Pipelines is specifically designed for machine learning use cases and provides native integration with all SageMaker services and capabilities.
Pipeline definitions are created using Python code, making them familiar to data scientists and easily integrated with existing development workflows. The pipelines support conditional execution, parallel processing, and parameter passing between steps, enabling complex workflow logic while maintaining readability and maintainability. Version control integration ensures that pipeline definitions can be managed alongside model code using standard software development practices.
The pipeline execution engine provides comprehensive monitoring, logging, and debugging capabilities that are essential for production machine learning workflows. Failed pipeline steps can be investigated and rerun individually, and the entire pipeline execution history is maintained for auditing and troubleshooting purposes. Integration with SageMaker Model Registry enables automatic model versioning and deployment approval workflows.
Monitoring and Observability
Production machine learning systems require comprehensive monitoring to detect data drift, model performance degradation, and operational issues that can impact business outcomes. SageMaker Model Monitor provides automated monitoring capabilities for detecting changes in data quality and model performance over time, enabling proactive maintenance and optimization of deployed models.
Data drift detection compares incoming inference data with the training data distribution to identify when the model may be operating outside its intended domain. Model performance monitoring tracks prediction accuracy and other business metrics over time, alerting teams when model retraining or intervention may be required. These monitoring capabilities can be configured with custom thresholds and alert mechanisms to ensure timely response to issues.
Operational monitoring includes tracking endpoint performance, resource utilization, error rates, and latency metrics through integration with Amazon CloudWatch. Custom metrics can be defined and tracked to monitor business-specific KPIs and ensure that machine learning systems are delivering expected value. Log aggregation and analysis capabilities provide detailed visibility into system behavior and support troubleshooting and optimization efforts.
Cost Optimization and Resource Management
Managing costs in machine learning workloads requires understanding the different pricing models and optimization strategies available in SageMaker. Training costs can be optimized through the use of spot instances, which can provide significant savings for fault-tolerant workloads, and managed spot training, which handles spot instance interruptions automatically while maintaining training continuity.
Inference costs depend on the deployment strategy chosen, with real-time endpoints providing consistent performance at higher cost, and batch transform offering cost-effective processing for non-real-time use cases. Multi-model endpoints can significantly reduce costs when hosting multiple related models by sharing underlying compute resources. Auto-scaling policies ensure that resources are allocated efficiently based on actual demand patterns.
Storage costs in S3 can be managed through lifecycle policies that automatically transition data to lower-cost storage classes based on access patterns. Data compression, efficient file formats like Parquet, and data partitioning strategies can reduce both storage costs and data transfer costs during training and inference operations.
Security and Compliance Considerations
Security in machine learning pipelines encompasses data protection, model security, access control, and compliance with regulatory requirements. SageMaker provides comprehensive security features including encryption at rest and in transit, VPC isolation, IAM-based access control, and integration with AWS security services like AWS CloudTrail for audit logging.
Data privacy and protection are particularly important when working with sensitive datasets such as personally identifiable information or healthcare data. SageMaker supports various privacy-preserving techniques including differential privacy, federated learning approaches, and secure multi-party computation for scenarios requiring enhanced privacy protection.
Compliance with regulations such as GDPR, HIPAA, and industry-specific requirements requires careful consideration of data handling, model explainability, and audit trail maintenance. SageMaker provides tools and features that support compliance efforts, including comprehensive logging, data lineage tracking, and bias detection capabilities that help demonstrate adherence to regulatory requirements.
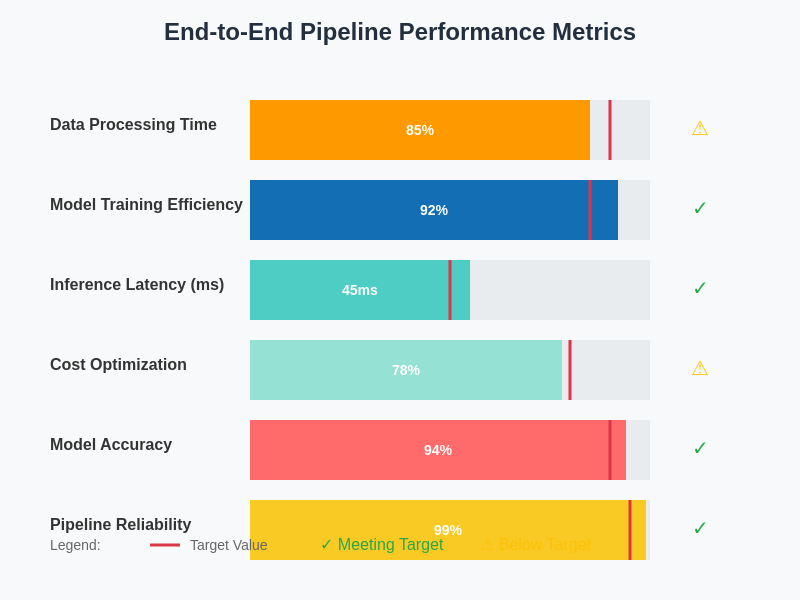
Comprehensive performance monitoring across the entire machine learning pipeline provides visibility into system efficiency, resource utilization, and business impact. These metrics enable data-driven optimization decisions and ensure that machine learning systems deliver expected value while operating within acceptable cost and performance parameters.
Best Practices and Common Pitfalls
Successful implementation of machine learning pipelines requires adherence to established best practices while avoiding common pitfalls that can impact system reliability, performance, and maintainability. Version control for both code and data is essential for reproducibility and collaboration, requiring integration of ML-specific versioning tools with traditional software development practices.
Data quality validation should be implemented at multiple stages of the pipeline to catch issues early and prevent poor-quality data from impacting model performance. Automated testing of data schemas, statistical properties, and business logic helps maintain system reliability and reduces the likelihood of production issues caused by data problems.
Model performance monitoring and automated retraining strategies are crucial for maintaining model effectiveness over time as data distributions and business conditions change. Establishing clear criteria for model retraining and deployment helps ensure that models remain accurate and valuable while avoiding unnecessary computational costs and operational complexity.
Advanced SageMaker Features and Integration
SageMaker continues to evolve with advanced features that support sophisticated machine learning use cases and integration with the broader AWS ecosystem. SageMaker Ground Truth provides managed data labeling services for creating high-quality training datasets, while SageMaker Neo optimizes trained models for deployment on edge devices and various hardware platforms.
Integration with other AWS services expands the capabilities of SageMaker pipelines, including AWS Lambda for serverless processing, Amazon Kinesis for real-time data streaming, AWS Glue for data integration and ETL operations, and Amazon QuickSight for visualization and business intelligence. These integrations enable comprehensive solutions that address end-to-end business requirements.
Emerging capabilities such as SageMaker JumpStart for pre-trained models and solutions, SageMaker Data Wrangler for visual data preparation, and SageMaker Autopilot for automated machine learning provide additional tools for accelerating machine learning development and democratizing access to advanced capabilities across organizations with varying levels of machine learning expertise.
Future Considerations and Roadmap
The machine learning landscape continues to evolve rapidly, with new techniques, tools, and best practices emerging regularly. Staying current with these developments while maintaining stable production systems requires a balanced approach that embraces innovation while managing risk and maintaining reliability.
Organizations should consider their long-term machine learning strategy and how SageMaker fits into their broader technology roadmap and business objectives. Factors such as multi-cloud strategies, hybrid cloud deployments, edge computing requirements, and evolving regulatory landscapes will influence architecture decisions and implementation approaches.
The democratization of machine learning through automated tools and simplified interfaces will continue to expand access to machine learning capabilities across organizations, requiring consideration of governance, quality control, and collaboration frameworks that ensure effective utilization of these powerful tools while maintaining standards for reliability, security, and business value delivery.
Building successful end-to-end machine learning pipelines with AWS SageMaker requires careful planning, attention to detail, and adherence to best practices across all stages of the machine learning lifecycle. The comprehensive capabilities provided by SageMaker enable organizations to build sophisticated, scalable, and reliable machine learning systems that deliver significant business value while managing complexity and operational overhead effectively.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. The information provided is based on current AWS SageMaker capabilities and best practices, which may evolve over time. Readers should consult official AWS documentation and consider their specific requirements, security needs, and compliance obligations when implementing machine learning solutions. Costs and performance characteristics may vary based on usage patterns, data characteristics, and configuration choices.