
The rapid advancement of artificial intelligence and machine learning technologies has brought unprecedented capabilities to countless applications, from healthcare diagnostics to financial lending decisions. However, alongside these remarkable achievements comes a critical responsibility to ensure that AI systems operate fairly and equitably across all demographic groups and use cases. The challenge of bias in artificial intelligence represents one of the most pressing ethical and technical concerns in modern technology development, requiring systematic approaches to identification, measurement, and mitigation.
Understanding and addressing bias in AI systems is not merely a technical challenge but a fundamental requirement for building trustworthy and socially responsible technology. As machine learning models increasingly influence decisions that affect people’s lives, careers, and opportunities, the imperative to create fair and unbiased systems becomes paramount. This comprehensive exploration examines the multifaceted nature of AI bias, provides practical frameworks for building equitable models, and offers actionable strategies for maintaining fairness throughout the machine learning lifecycle.
Explore the latest developments in AI ethics and fairness to stay informed about emerging research and best practices in responsible AI development. The intersection of technology and social responsibility requires continuous learning and adaptation as our understanding of bias and fairness evolves with new research findings and real-world applications.
Understanding the Nature of AI Bias
Bias in artificial intelligence systems manifests in numerous forms, each presenting unique challenges and requiring specific approaches for identification and mitigation. At its core, AI bias refers to systematic and unfair discrimination against certain individuals or groups, often reflecting and amplifying existing societal prejudices present in training data or embedded within algorithmic design choices. This bias can emerge from various sources throughout the machine learning pipeline, from data collection and preprocessing to model architecture selection and deployment strategies.
The complexity of AI bias stems from its multidimensional nature, encompassing statistical bias, social bias, and cognitive bias that can interact in unexpected ways to produce unfair outcomes. Statistical bias refers to systematic errors in data representation or sampling that lead to skewed model predictions, while social bias reflects broader societal inequalities and stereotypes that become encoded in training data. Cognitive bias, introduced by human developers and data scientists, can influence design decisions and evaluation criteria in ways that perpetuate unfairness.
Historical bias represents one of the most pervasive forms of bias in AI systems, occurring when training data reflects past discriminatory practices or unequal treatment of different groups. This type of bias is particularly challenging because it appears statistically valid while perpetuating systemic inequalities. Representation bias occurs when certain groups are underrepresented or misrepresented in training data, leading to models that perform poorly for these populations. Measurement bias arises from differences in data quality, collection methods, or feature definitions across different groups, resulting in systematically different model performance.
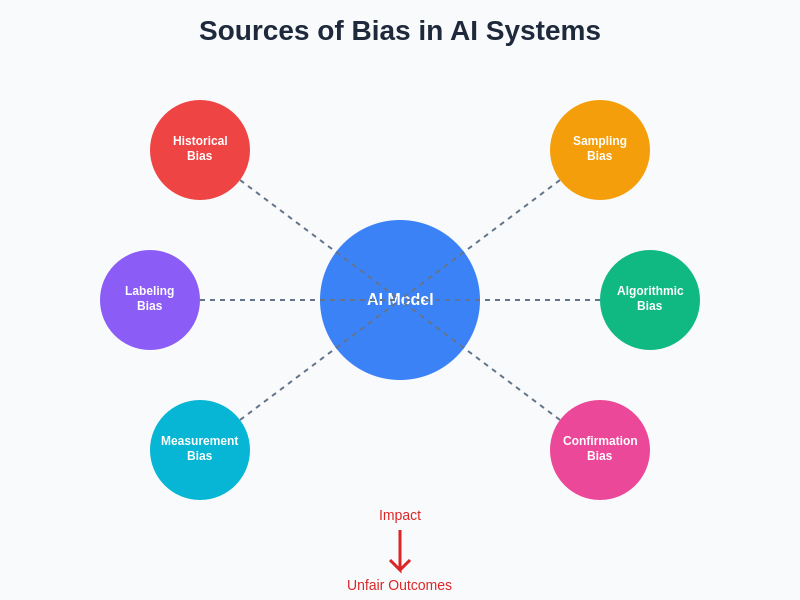
The interconnected nature of bias sources demonstrates how multiple factors can simultaneously contribute to unfair AI outcomes. Understanding these relationships is crucial for developing comprehensive mitigation strategies that address root causes rather than merely treating symptoms of algorithmic discrimination.
Sources and Origins of Bias in Machine Learning
The origins of bias in machine learning systems are diverse and often interconnected, requiring comprehensive understanding to develop effective mitigation strategies. Data collection processes represent a primary source of bias, as the methods used to gather training data can systematically exclude or misrepresent certain populations. Sampling bias occurs when the data collection process fails to capture representative samples from all relevant populations, leading to models that perform well for majority groups but poorly for underrepresented communities.
Labeling bias emerges during the data annotation process, where human annotators may unconsciously apply different standards or criteria when labeling data from different demographic groups. This type of bias is particularly problematic in supervised learning scenarios where model performance depends heavily on the quality and consistency of labeled training data. Confirmation bias can lead annotators to make labeling decisions that confirm their existing beliefs or expectations, rather than objective assessment of the data.
Discover advanced AI research and development insights to access cutting-edge resources for building more equitable AI systems. The collaborative nature of addressing AI bias requires diverse perspectives and interdisciplinary approaches that combine technical expertise with social science insights and domain-specific knowledge.
Feature selection and engineering processes also introduce potential sources of bias, as the choice of which attributes to include or exclude from models can significantly impact fairness outcomes. Proxy discrimination occurs when seemingly neutral features correlate with protected attributes, allowing models to make biased decisions indirectly. For example, zip codes may serve as proxies for race or socioeconomic status, enabling discriminatory outcomes even when race is not explicitly included as a feature.
Algorithmic bias can arise from the choice of machine learning algorithms, optimization objectives, and evaluation metrics used during model development. Different algorithms may exhibit varying degrees of bias depending on their underlying assumptions and mathematical formulations. The selection of optimization objectives that prioritize overall accuracy without considering fairness across subgroups can lead to models that perform well on average while discriminating against minority populations.
Types and Categories of AI Bias
Understanding the various types of bias that can affect AI systems is essential for developing comprehensive mitigation strategies. Individual fairness focuses on ensuring that similar individuals receive similar treatment from AI systems, regardless of their membership in protected groups. This approach requires defining meaningful similarity metrics and ensuring that the model’s decisions remain consistent across individuals who should be treated equally according to relevant criteria.
Group fairness, also known as statistical parity, aims to ensure that different demographic groups receive positive outcomes at equal rates. This approach focuses on achieving equal treatment across groups rather than individuals, which can be particularly important in contexts where historical discrimination has created systematic disadvantages for certain populations. However, achieving group fairness may sometimes conflict with individual fairness, requiring careful consideration of trade-offs and context-specific definitions of fairness.
Equality of opportunity represents a nuanced approach to fairness that focuses on ensuring equal true positive rates across different groups. This metric is particularly relevant in scenarios where positive predictions correspond to beneficial outcomes, such as loan approvals or job recommendations. Equalized odds extends this concept by requiring equal true positive and false positive rates across groups, providing a more comprehensive measure of fairness that considers both beneficial and harmful prediction errors.
Counterfactual fairness examines whether an individual would receive the same decision in a counterfactual world where they belonged to a different demographic group, holding all other relevant factors constant. This approach requires careful consideration of causal relationships and the identification of legitimate versus illegitimate factors that should influence decision-making. Treatment fairness focuses on ensuring that protected attributes do not directly influence model decisions, while impact fairness considers the broader effects of AI systems on different groups, even when no direct discrimination occurs.
Measuring and Detecting Bias in AI Systems
Effective bias detection requires systematic measurement approaches that can identify unfairness across different dimensions and demographic groups. Statistical parity difference measures the difference in positive prediction rates between different groups, providing a straightforward metric for identifying disparate impact. A value of zero indicates perfect statistical parity, while larger absolute values suggest greater disparities between groups.
Equalized odds difference measures disparities in both true positive and false positive rates across groups, offering a more comprehensive assessment of fairness that considers both beneficial and harmful prediction errors. This metric is particularly valuable for understanding how model errors are distributed across different populations and whether certain groups face systematically higher rates of false positives or false negatives.
Access comprehensive AI research tools and analysis to support rigorous bias detection and fairness evaluation in your machine learning projects. The measurement of bias requires sophisticated analytical approaches that can capture subtle forms of discrimination and provide actionable insights for model improvement.
Individual fairness metrics assess whether similar individuals receive similar treatment, requiring the definition of appropriate similarity measures and fairness constraints. These metrics often involve computing distances between individuals in feature space and ensuring that prediction differences remain proportional to relevant dissimilarities. Consistency metrics evaluate whether the model produces similar predictions for individuals who differ only in protected attributes, helping identify direct discrimination.
Calibration metrics examine whether prediction probabilities accurately reflect true outcome rates across different groups. Poor calibration can indicate bias even when other fairness metrics appear satisfactory, as it suggests that the model’s confidence levels vary systematically across populations. Disparate impact ratios compare outcome rates between protected and unprotected groups, with values significantly different from one indicating potential discrimination.
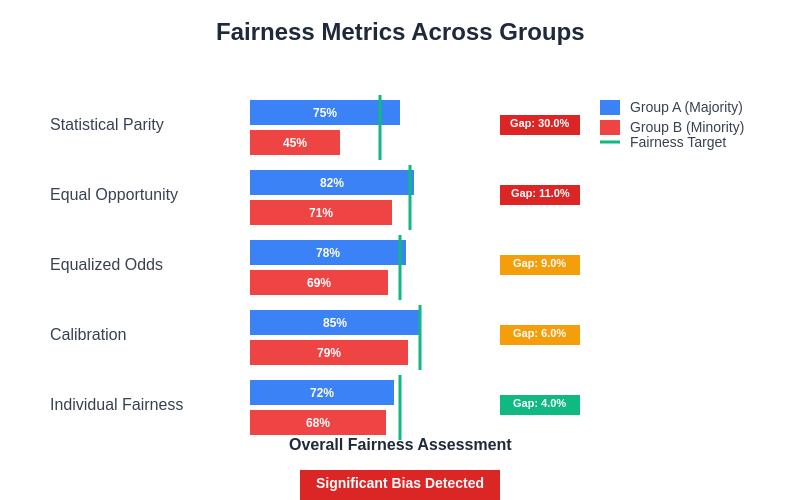
This comprehensive analysis of fairness metrics reveals the multidimensional nature of bias measurement, where different metrics may highlight varying aspects of discrimination. The systematic evaluation across multiple fairness criteria provides a more complete picture of model equity and helps identify specific areas requiring intervention.
Strategies for Bias Mitigation and Prevention
Bias mitigation strategies can be implemented at various stages of the machine learning pipeline, each offering distinct advantages and addressing different sources of unfairness. Pre-processing approaches focus on modifying training data to reduce bias before model training begins. Data augmentation techniques can address representation bias by generating synthetic samples for underrepresented groups, while reweighting methods can adjust the importance of different samples to achieve better balance across demographic groups.
Fairness-aware sampling strategies actively seek to collect more representative training data by identifying and addressing gaps in current datasets. This approach requires careful planning and resource allocation but can provide long-term benefits by creating more equitable foundational datasets. Data preprocessing techniques such as disparate impact remover and learning fair representations can transform features to reduce correlation with protected attributes while preserving predictive utility.
In-processing methods incorporate fairness constraints directly into the model training process, ensuring that fairness considerations are optimized alongside predictive performance. Adversarial debiasing uses adversarial networks to learn representations that are predictive of the target variable but uninformative about protected attributes. Multi-task learning approaches can simultaneously optimize for prediction accuracy and fairness metrics, allowing for explicit trade-off management during training.
Regularization techniques can penalize model complexity or discourage reliance on features that correlate with protected attributes. Fairness constraints can be incorporated into optimization objectives through Lagrangian methods or constrained optimization algorithms that ensure fairness requirements are satisfied during training. Meta-learning approaches can learn to adapt quickly to new populations or demographic groups, potentially improving fairness in scenarios with limited training data for certain groups.
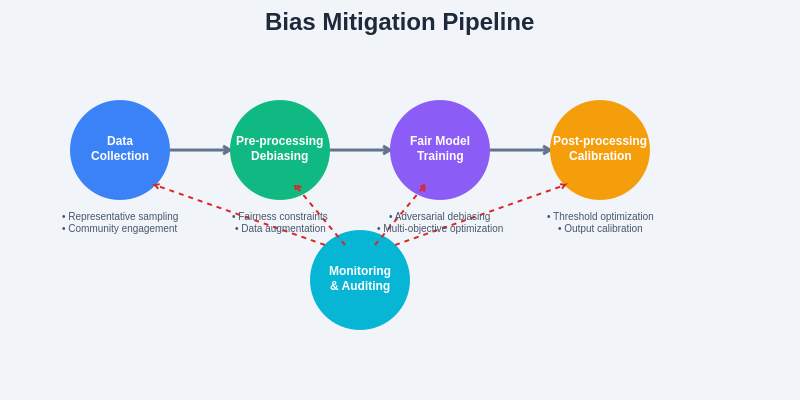
The systematic approach to bias mitigation requires intervention at multiple stages of the machine learning pipeline, with continuous monitoring and feedback loops ensuring that fairness improvements are maintained throughout the system lifecycle. This comprehensive framework demonstrates how different mitigation techniques can be integrated into a cohesive strategy for building equitable AI systems.
Post-Processing Approaches to Fairness
Post-processing methods modify model outputs after training to achieve desired fairness properties while preserving the underlying model structure. Threshold optimization techniques adjust decision thresholds for different groups to achieve equalized odds or other fairness criteria. This approach is particularly useful when the underlying model cannot be retrained but fairness improvements are still required.
Calibration methods ensure that prediction probabilities accurately reflect true outcome rates across different demographic groups. Platt scaling and isotonic regression can be applied separately to different groups to achieve better calibration, though care must be taken to avoid overfitting on small subgroups. Output redistribution techniques can modify the distribution of positive and negative predictions to achieve statistical parity while minimizing overall changes to model outputs.
Fairness-aware ranking algorithms can reorder model predictions to ensure that different groups receive equitable representation in top-k selections or recommendation lists. These methods are particularly relevant for applications such as hiring, lending, or content recommendation where the relative ordering of candidates or items significantly impacts outcomes. Multi-criteria optimization approaches can balance fairness and utility objectives in post-processing steps, allowing for flexible trade-off management.
Building Inclusive Data Collection Practices
Developing fair AI systems begins with implementing inclusive data collection practices that ensure representative sampling across all relevant demographic groups and use cases. Stratified sampling techniques can guarantee adequate representation of minority groups that might otherwise be undersampled in conventional data collection approaches. Community engagement and participatory design methods can help identify potential blind spots and ensure that data collection efforts address the needs and concerns of all stakeholders.
Data governance frameworks should establish clear guidelines for ethical data collection, including informed consent procedures, privacy protections, and community benefit sharing agreements. These frameworks should explicitly address potential sources of bias and include mechanisms for ongoing monitoring and improvement. Collaborative data collection efforts that involve multiple institutions or organizations can help create more diverse and representative datasets while distributing the costs and benefits of data creation.
Quality assurance processes should include systematic checks for representation bias, measurement bias, and other forms of systematic unfairness. Regular audits of data collection processes can identify emerging biases and enable prompt corrective action. Documentation and provenance tracking can help maintain transparency about data sources, collection methods, and potential limitations that might affect fairness outcomes.
Algorithmic Auditing and Continuous Monitoring
Establishing robust algorithmic auditing processes is essential for maintaining fairness in deployed AI systems over time. Regular fairness assessments should evaluate model performance across different demographic groups and application contexts, using multiple metrics to capture various dimensions of fairness. These assessments should include both quantitative measurements and qualitative evaluations that consider broader social impacts and unintended consequences.
Monitoring systems should track key fairness metrics in real-time and alert stakeholders when bias thresholds are exceeded or when concerning trends emerge. Automated monitoring can identify gradual shifts in model behavior that might indicate emerging bias, while human oversight can provide contextual interpretation and guide appropriate responses. Feedback loops should enable continuous improvement by incorporating new data, addressing identified biases, and adapting to changing social contexts.
External auditing processes can provide independent validation of fairness claims and help identify blind spots that internal teams might miss. Third-party auditors bring fresh perspectives and specialized expertise in bias detection and fairness evaluation. Transparency reports and public disclosure of fairness metrics can build trust with users and stakeholders while creating accountability for maintaining equitable AI systems.
Legal and Regulatory Considerations
The legal landscape surrounding AI bias and algorithmic fairness continues to evolve, with new regulations and guidelines emerging at local, national, and international levels. Compliance with anti-discrimination laws requires careful consideration of how AI systems might perpetuate or amplify existing forms of discrimination, even when no explicit intent to discriminate exists. Legal frameworks often focus on disparate impact and treatment, requiring organizations to demonstrate that their AI systems do not unfairly disadvantage protected groups.
Privacy regulations such as GDPR and CCPA include provisions that affect AI bias mitigation efforts, particularly regarding the use of demographic information for fairness monitoring and the right to explanation for automated decision-making. Organizations must balance fairness objectives with privacy requirements, often requiring innovative approaches to bias detection and mitigation that do not rely on explicit collection of protected attributes.
Industry-specific regulations may impose additional requirements for fairness and transparency in AI systems used for hiring, lending, healthcare, or criminal justice applications. These regulations often specify particular fairness metrics or auditing procedures that must be followed, requiring organizations to adapt their bias mitigation strategies to meet sector-specific requirements. International variations in legal frameworks require global organizations to implement comprehensive approaches that satisfy the most stringent applicable requirements.
Ethical Frameworks and Responsible AI Development
Developing ethical frameworks for responsible AI development requires integrating technical capabilities with moral reasoning and social responsibility considerations. Principle-based approaches such as beneficence, non-maleficence, autonomy, and justice provide foundational guidance for making ethical decisions throughout the AI development lifecycle. These principles must be translated into concrete practices and evaluation criteria that can guide technical implementation decisions.
Stakeholder engagement processes should include affected communities, domain experts, ethicists, and other relevant parties in the design and evaluation of AI systems. Participatory design methods can help ensure that fairness definitions and mitigation strategies align with community values and needs. Regular consultation and feedback collection can help identify emerging ethical concerns and guide adaptive responses to changing social contexts.
Value-sensitive design approaches explicitly consider human values and their implications for technology design from the earliest stages of development. This methodology requires systematic identification of stakeholders, analysis of value tensions, and integration of value considerations into technical design decisions. Documentation of ethical reasoning and decision-making processes can support accountability and enable learning across projects and organizations.
Future Directions and Emerging Challenges
The field of AI fairness continues to evolve rapidly, with new research directions and emerging challenges requiring ongoing attention and adaptation. Intersectionality considerations highlight the need to address bias across multiple protected attributes simultaneously, recognizing that individuals may face unique forms of discrimination based on the intersection of multiple identity categories. Traditional fairness metrics often fail to capture these complex interactions, requiring development of new measurement approaches and mitigation strategies.
Dynamic fairness addresses the challenge of maintaining fairness over time as both AI systems and social contexts evolve. Models that appear fair at deployment may become biased as data distributions shift, social norms change, or new forms of discrimination emerge. Adaptive fairness techniques must balance stability with responsiveness, maintaining consistent treatment while adapting to legitimate changes in underlying relationships.
Global fairness considerations recognize that fairness definitions and social values vary across different cultural contexts and geographical regions. AI systems deployed across multiple countries or cultural contexts must navigate these differences while maintaining core commitments to equity and non-discrimination. This challenge requires developing more flexible and culturally-aware approaches to fairness that can adapt to local contexts while preserving universal principles of human dignity and equal treatment.
The integration of fairness considerations with other AI governance challenges such as privacy, security, and interpretability creates complex optimization problems that require sophisticated technical and policy solutions. Multi-objective approaches must balance competing objectives while maintaining transparency about trade-offs and limitations. The development of comprehensive governance frameworks that address these interactions holistically represents a critical area for future research and development.
Disclaimer
This article is for informational and educational purposes only and does not constitute legal, ethical, or technical advice. The field of AI bias and fairness is rapidly evolving, and practices should be adapted based on current research, applicable regulations, and specific organizational contexts. Readers should consult with qualified experts and conduct thorough evaluations when implementing bias mitigation strategies. The effectiveness of fairness interventions may vary depending on specific applications, data characteristics, and social contexts.