
The rapidly evolving landscape of artificial intelligence has created unprecedented challenges in maintaining robust and resilient machine learning infrastructure. As AI systems become increasingly critical to business operations and decision-making processes, the need for systematic resilience testing has never been more crucial. Chaos engineering, originally developed to test the fault tolerance of distributed systems, has emerged as a powerful methodology for ensuring the reliability and stability of AI infrastructure under adverse conditions.
The complexity of modern AI systems extends far beyond traditional software applications, encompassing distributed training clusters, real-time inference pipelines, data preprocessing workflows, and sophisticated model serving architectures. Each component represents a potential point of failure that could cascade through the entire system, leading to degraded performance, incorrect predictions, or complete service outages. Stay informed about the latest AI infrastructure trends to understand how chaos engineering is becoming essential for maintaining reliable AI systems in production environments.
Understanding Chaos Engineering in the AI Context
Chaos engineering represents a disciplined approach to discovering system weaknesses through controlled experimentation and deliberate failure injection. When applied to AI infrastructure, this methodology takes on additional complexity due to the statistical nature of machine learning models, the continuous evolution of training data, and the intricate dependencies between various system components. Unlike traditional software systems where failures often manifest as binary states of functionality, AI systems can experience gradual degradation in performance, biased predictions, or subtle accuracy losses that may go undetected without proper monitoring and testing frameworks.
The application of chaos engineering principles to AI systems requires a deep understanding of both the technical infrastructure supporting machine learning workloads and the statistical behavior of the models themselves. This dual perspective enables teams to design experiments that test not only the resilience of the underlying compute and storage infrastructure but also the robustness of the AI models under various failure conditions. The goal extends beyond merely ensuring system availability to encompass maintaining prediction accuracy, minimizing bias amplification, and preserving model performance across diverse operational scenarios.
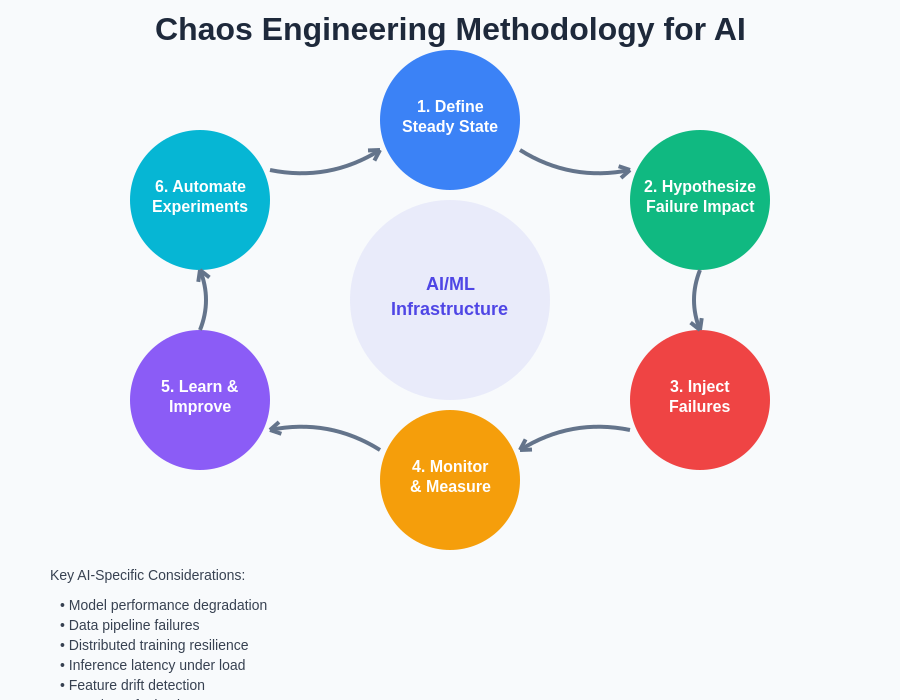
The systematic approach to chaos engineering for AI infrastructure follows a structured methodology that emphasizes continuous learning and improvement. This cyclical process ensures that resilience testing evolves with the system architecture and addresses emerging failure modes as AI infrastructure becomes more complex and distributed.
The Unique Challenges of AI Infrastructure Resilience
Machine learning infrastructure presents distinct challenges that differentiate it from conventional distributed systems. The computational intensity of training large models creates dependencies on specialized hardware such as GPUs and TPUs, which have different failure modes compared to traditional CPU-based systems. Training jobs that may run for days or weeks become vulnerable to hardware failures, network partitions, and resource contention issues that could result in significant time and cost losses if not properly addressed through resilient design patterns.
Data pipelines in AI systems introduce another layer of complexity, as they must handle massive volumes of information while maintaining data quality and consistency. Chaos engineering experiments targeting these pipelines must consider the impact of data corruption, missing features, schema evolution, and temporal inconsistencies on model performance. The statistical nature of machine learning means that some data quality issues may not immediately manifest as system failures but could gradually degrade model accuracy over time, making detection and mitigation particularly challenging.
Explore advanced AI capabilities with Claude to understand how sophisticated AI systems handle resilience challenges and implement robust error handling mechanisms. The interaction between multiple AI components requires careful orchestration and failure handling strategies that go beyond traditional retry mechanisms and circuit breakers.
Model Serving Infrastructure and Fault Tolerance
The serving infrastructure for AI models presents unique resilience requirements that must balance latency constraints with fault tolerance mechanisms. Real-time inference systems often operate under strict service level agreements that require sub-millisecond response times, making traditional failover mechanisms potentially inadequate. Chaos engineering experiments in this domain must carefully consider the trade-offs between redundancy, performance, and resource utilization while ensuring that failures in individual components do not compromise the overall system’s ability to serve predictions.
Load balancing strategies for model serving infrastructure must account for the varying computational requirements of different models and the potential for model-specific failures. Unlike web services where requests are generally homogeneous, AI inference requests may vary significantly in complexity and resource requirements. Chaos experiments should simulate scenarios where specific model types become unavailable or experience performance degradation, testing the system’s ability to gracefully handle heterogeneous workloads under stress conditions.
Data Quality and Pipeline Resilience Testing
Data quality represents a critical aspect of AI system resilience that extends beyond traditional system reliability concerns. Chaos engineering experiments targeting data pipelines must systematically introduce various types of data corruption, missing values, and schema inconsistencies to understand how these issues propagate through the machine learning workflow. The goal is not only to ensure that the system continues to operate but also to maintain acceptable levels of model performance and prediction accuracy.
Feature engineering pipelines are particularly susceptible to cascading failures when upstream data sources experience issues. Chaos experiments should simulate scenarios where feature stores become unavailable, data transformations fail, or real-time feature computation encounters performance bottlenecks. Understanding how these failures impact model predictions enables teams to implement appropriate fallback mechanisms and monitoring strategies that preserve system functionality even under adverse data conditions.
The temporal aspects of data in AI systems add another dimension to resilience testing. Machine learning models often rely on historical data for training and real-time data for inference, creating dependencies on data freshness and consistency across time windows. Chaos experiments should explore scenarios where data delivery is delayed, historical data becomes corrupted, or real-time streams experience interruptions to validate the system’s ability to maintain acceptable performance levels under various data availability conditions.
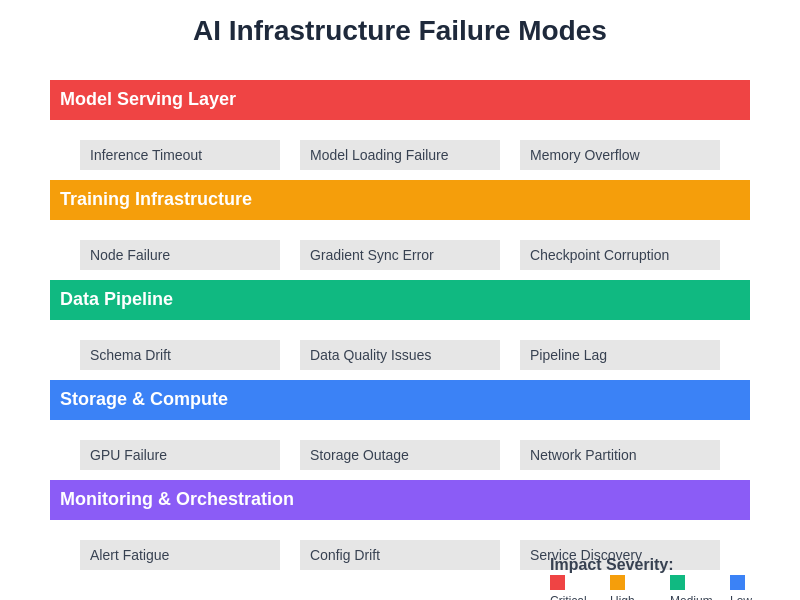
Understanding the various failure modes across different layers of AI infrastructure is essential for designing effective chaos experiments. Each layer presents unique challenges and failure patterns that require specialized testing approaches and monitoring strategies to ensure comprehensive resilience validation.
Distributed Training Infrastructure Resilience
The distributed nature of modern machine learning training infrastructure creates numerous potential points of failure that must be systematically tested through chaos engineering principles. Training clusters consisting of hundreds or thousands of compute nodes must coordinate complex synchronization operations while maintaining high utilization rates and fault tolerance. Chaos experiments targeting training infrastructure should simulate node failures, network partitions, and resource contention scenarios to validate the system’s ability to continue training operations or gracefully recover from failures.
Parameter server architectures and gradient synchronization mechanisms represent critical components that require specific resilience testing approaches. Chaos experiments should systematically introduce failures in parameter servers, simulate network latency variations between training nodes, and test the impact of partial gradient updates on model convergence. Understanding how these failures affect training stability and final model quality enables teams to implement robust checkpointing strategies and failure recovery mechanisms.
Enhance your research capabilities with Perplexity to stay current with the latest developments in distributed training resilience and fault-tolerant machine learning architectures. The evolution of training methodologies continues to introduce new failure modes and resilience requirements that must be addressed through systematic chaos engineering practices.
Model Performance Degradation Testing
Unlike traditional software systems where failures often manifest as clear error conditions, AI systems can experience subtle performance degradation that may not trigger conventional monitoring alerts. Chaos engineering experiments for AI infrastructure must include systematic testing of model performance under various stress conditions, including resource constraints, data quality issues, and partial system failures. This approach requires sophisticated monitoring and evaluation frameworks that can detect gradual changes in prediction accuracy, bias levels, and statistical properties of model outputs.
Adversarial conditions represent another category of chaos experiments specific to AI systems. Testing model robustness against adversarial inputs, distribution shifts, and edge cases helps validate the system’s ability to maintain acceptable performance levels under challenging operational conditions. These experiments should systematically introduce various types of input perturbations and monitor how the system responds in terms of prediction confidence, error rates, and fallback mechanism activation.
Infrastructure Monitoring and Observability
Effective chaos engineering for AI systems requires comprehensive monitoring and observability capabilities that extend beyond traditional system metrics to include model-specific performance indicators. Monitoring frameworks must track not only infrastructure health metrics such as CPU utilization, memory consumption, and network throughput but also AI-specific metrics including prediction latency, model accuracy, feature drift, and data quality indicators. This holistic monitoring approach enables teams to understand the full impact of chaos experiments on both system infrastructure and AI model performance.
The statistical nature of machine learning introduces challenges in defining appropriate alerting thresholds and anomaly detection rules. Unlike traditional systems where specific error conditions can trigger clear alerts, AI systems may experience gradual degradation that requires statistical analysis to detect. Chaos experiments should validate the effectiveness of monitoring and alerting systems in detecting both sudden failures and gradual performance degradation across various failure scenarios.
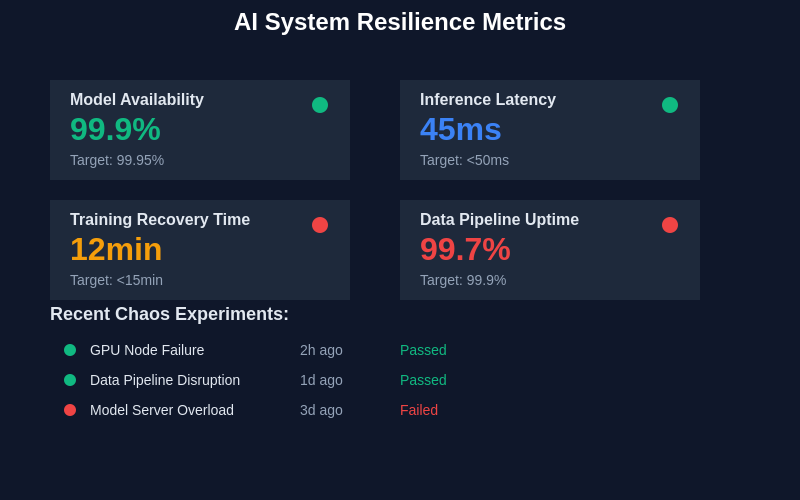
Comprehensive monitoring and metrics collection enable teams to assess the impact of chaos experiments and validate system resilience across multiple dimensions. Real-time dashboards provide visibility into both infrastructure health and AI-specific performance indicators during controlled failure scenarios.
Recovery and Rollback Strategies
AI systems require specialized recovery and rollback strategies that account for the complexity of machine learning workflows and the potential impact of reverting to previous model versions. Chaos engineering experiments should systematically test various recovery scenarios, including model rollback procedures, data pipeline restoration, and training job resumption from checkpoints. The goal is to validate that recovery mechanisms can restore system functionality within acceptable timeframes while minimizing the impact on ongoing operations.
Model versioning and deployment strategies play crucial roles in system resilience and must be thoroughly tested through chaos experiments. Rolling deployments, canary releases, and A/B testing mechanisms for AI models require specific failure handling approaches that consider both technical failures and statistical performance degradation. Chaos experiments should simulate various deployment failure scenarios to validate that rollback procedures can quickly restore system functionality without compromising data consistency or model performance.
Security and Privacy Implications
Chaos engineering for AI systems must carefully consider security and privacy implications that are particularly relevant to machine learning workloads. Experiments involving data corruption or injection must ensure that sensitive training data or model parameters are not inadvertently exposed or compromised. Privacy-preserving techniques such as differential privacy and federated learning introduce additional complexity to chaos experiments, requiring specialized approaches to test resilience while maintaining privacy guarantees.
Model extraction and inversion attacks represent security concerns specific to AI systems that should be considered in chaos engineering experiments. Testing the system’s resilience against various attack vectors while maintaining normal operations helps validate security mechanisms and incident response procedures. These experiments should be conducted in controlled environments with appropriate safeguards to prevent actual security breaches while validating the effectiveness of protective measures.
Automation and Continuous Testing
The complexity and scale of modern AI infrastructure necessitate automated chaos engineering approaches that can systematically test various failure scenarios without manual intervention. Automation frameworks for AI chaos engineering must account for the unique characteristics of machine learning workloads, including long-running training jobs, complex data dependencies, and statistical validation requirements. Implementing continuous chaos testing as part of the MLOps pipeline ensures that system resilience is regularly validated as infrastructure and models evolve.
Integration with existing CI/CD pipelines requires careful consideration of the time and resources required for chaos experiments, particularly for tests involving model training or large-scale data processing. Automated experiments should be designed to provide meaningful validation of system resilience while minimizing impact on development productivity and operational costs. This balance requires sophisticated scheduling and resource management capabilities that can coordinate chaos experiments with normal operational activities.
Cost Optimization and Resource Management
Chaos engineering experiments for AI infrastructure must carefully balance the need for comprehensive testing with the significant computational and storage costs associated with machine learning workloads. Experiments involving distributed training or large-scale data processing can consume substantial resources, making cost optimization a critical consideration in designing effective chaos testing strategies. Resource management approaches should prioritize high-impact experiments that provide maximum validation of system resilience while minimizing unnecessary resource consumption.
Cloud-based AI infrastructure introduces additional complexity in resource management for chaos experiments, as experiments may need to span multiple availability zones, regions, or cloud providers. Testing multi-cloud resilience scenarios requires coordination across different platforms while managing costs and ensuring that experiments do not interfere with production workloads. Effective resource management strategies should include automated provisioning and cleanup mechanisms that prevent resource waste while enabling comprehensive resilience testing.
Regulatory Compliance and Governance
AI systems operating in regulated industries face additional compliance requirements that must be considered in chaos engineering practices. Experiments involving healthcare data, financial information, or other regulated data types must comply with relevant privacy and security regulations while still providing meaningful validation of system resilience. Governance frameworks for AI chaos engineering should include clear guidelines for experiment approval, data handling, and incident reporting that satisfy regulatory requirements.
Documentation and audit trails for chaos experiments become particularly important in regulated environments where system reliability and failure response procedures may be subject to regulatory scrutiny. Comprehensive logging and reporting mechanisms should capture not only the technical aspects of experiments but also their impact on compliance posture and risk management objectives. This documentation serves both operational and regulatory purposes while supporting continuous improvement of resilience testing practices.
Future Directions and Emerging Technologies
The evolution of AI technologies continues to introduce new challenges and opportunities for chaos engineering practices. Emerging technologies such as quantum machine learning, neuromorphic computing, and edge AI deployment create novel failure modes and resilience requirements that must be addressed through innovative chaos engineering approaches. Understanding these emerging trends enables teams to proactively develop testing strategies that ensure system resilience as AI technologies continue to evolve.
The integration of chaos engineering principles with emerging AI governance frameworks and responsible AI practices represents another important direction for future development. As AI systems become more prevalent in critical applications, the need for systematic resilience testing that considers both technical and ethical implications will continue to grow. Chaos engineering methodologies must evolve to address not only technical failures but also bias amplification, fairness degradation, and other AI-specific concerns that impact system reliability and trustworthiness.
Conclusion and Best Practices
Chaos engineering for AI infrastructure represents a critical discipline for ensuring the reliability and resilience of machine learning systems in production environments. The unique challenges presented by AI workloads, including statistical behavior, complex data dependencies, and distributed training requirements, necessitate specialized approaches that extend beyond traditional chaos engineering practices. Successful implementation requires careful consideration of model performance, data quality, infrastructure resilience, and operational procedures that collectively ensure system reliability under adverse conditions.
The implementation of effective chaos engineering practices for AI systems requires a holistic approach that considers both technical infrastructure and machine learning model behavior. Teams should prioritize experiments that provide maximum insight into system resilience while maintaining acceptable operational costs and compliance requirements. Continuous improvement of chaos engineering practices, driven by lessons learned from both planned experiments and real-world failures, ensures that AI infrastructure can reliably support critical business operations as technology continues to evolve.
Disclaimer
This article is for informational purposes only and does not constitute professional advice regarding system architecture, security practices, or regulatory compliance. The implementation of chaos engineering practices should be carefully planned and executed with appropriate safeguards to prevent unintended system disruption or data compromise. Organizations should consult with qualified professionals and consider their specific operational requirements, regulatory obligations, and risk tolerance when implementing chaos engineering practices for AI infrastructure.