
The artificial intelligence landscape for programming assistance has evolved dramatically with the emergence of sophisticated language models that can understand, generate, and debug code with remarkable proficiency. Two titans dominate this space: Anthropic’s Claude and OpenAI’s GPT-4, each bringing unique strengths and capabilities to the developer’s toolkit. The question of which AI writes better code has become increasingly relevant as developers seek to maximize their productivity and code quality through intelligent automation.
Stay updated with the latest AI programming trends to understand how these powerful tools are continuously evolving and reshaping the software development landscape. The choice between Claude and GPT-4 for programming tasks involves multiple considerations including code accuracy, contextual understanding, debugging proficiency, and the ability to handle complex architectural challenges across diverse programming environments.
Understanding the Fundamentals: Architecture and Approach
Both Claude and GPT-4 represent cutting-edge achievements in large language model development, yet they approach code generation and programming assistance through distinctly different philosophical and technical frameworks. Claude, developed by Anthropic, emphasizes constitutional AI principles that prioritize helpful, harmless, and honest responses, which translates into more cautious and thoroughly considered code suggestions. This approach often results in code that includes comprehensive error handling, security considerations, and detailed explanations of implementation choices.
GPT-4, created by OpenAI, leverages its extensive training on diverse codebases and programming documentation to provide rapid, contextually aware code generation across virtually every programming language and framework. The model excels at understanding nuanced programming concepts and can seamlessly transition between different coding paradigms, making it particularly valuable for developers working on complex, multi-language projects that require deep integration between various technologies and systems.
The fundamental difference in training approaches becomes apparent when examining how each model handles edge cases, security vulnerabilities, and performance optimization. Claude tends to be more conservative in its suggestions, often providing multiple implementation alternatives with detailed trade-off analyses, while GPT-4 typically offers more direct solutions that prioritize functionality and immediate problem resolution over comprehensive risk assessment.
Code Quality and Accuracy Assessment
When evaluating code quality, both models demonstrate exceptional capabilities, but their strengths manifest in different areas of software development. Claude consistently produces code that adheres to established best practices, incorporates comprehensive error handling, and includes detailed documentation that explains the reasoning behind specific implementation choices. This approach results in more maintainable codebases that are easier for teams to understand and modify over time.
GPT-4 excels in generating syntactically correct code across a broader range of programming languages and can handle more complex algorithmic challenges with remarkable accuracy. The model demonstrates superior performance in mathematical computations, data structure implementations, and algorithm optimization tasks. However, GPT-4 sometimes produces code that prioritizes functionality over security considerations, requiring additional review and hardening for production environments.
Experience Claude’s advanced reasoning capabilities for programming tasks that require deep analysis and comprehensive solution development. The model’s ability to provide detailed explanations and consider multiple implementation approaches makes it particularly valuable for educational purposes and complex problem-solving scenarios where understanding the underlying logic is as important as the final implementation.
Debugging and Problem Resolution Capabilities
The debugging capabilities of both models reveal significant differences in their approaches to identifying and resolving programming issues. Claude demonstrates exceptional skill in analyzing error messages, stack traces, and problematic code segments, often providing step-by-step debugging strategies that help developers understand not just what went wrong, but why specific issues occurred and how to prevent similar problems in the future.
GPT-4’s debugging approach tends to be more direct and solution-focused, quickly identifying the most likely causes of issues and providing targeted fixes that resolve immediate problems. The model excels at recognizing common programming patterns that lead to bugs and can suggest refactoring approaches that improve overall code reliability and performance.
Both models show remarkable proficiency in handling language-specific debugging challenges, from memory management issues in C++ to asynchronous programming complications in JavaScript. However, Claude’s more methodical approach often results in more comprehensive solutions that address root causes rather than merely treating symptoms, making it particularly valuable for maintaining large, complex codebases where stability and reliability are paramount.
Language-Specific Performance Analysis
The performance of both models varies significantly across different programming languages, with each demonstrating particular strengths in specific development environments. Claude shows exceptional proficiency in Python development, consistently generating clean, readable code that follows PEP 8 guidelines and incorporates appropriate error handling and documentation. The model’s understanding of Python’s ecosystem, including popular frameworks like Django, Flask, and FastAPI, enables it to generate production-ready code that integrates seamlessly with existing projects.
GPT-4 demonstrates superior performance in JavaScript and TypeScript development, particularly in modern frameworks like React, Vue, and Angular. The model’s ability to understand complex state management patterns, asynchronous programming concepts, and modern JavaScript features makes it invaluable for front-end and full-stack development projects. Additionally, GPT-4 shows remarkable proficiency in systems programming languages like Rust and Go, generating efficient, idiomatic code that takes advantage of each language’s unique features and performance characteristics.
Both models handle Java development competently, but with different emphases. Claude tends to generate more enterprise-focused solutions with comprehensive logging, error handling, and documentation, while GPT-4 often produces more concise implementations that prioritize performance and modern Java features. For mobile development, GPT-4 generally provides better assistance with Swift and Kotlin, while Claude excels in cross-platform solutions using frameworks like Flutter and React Native.
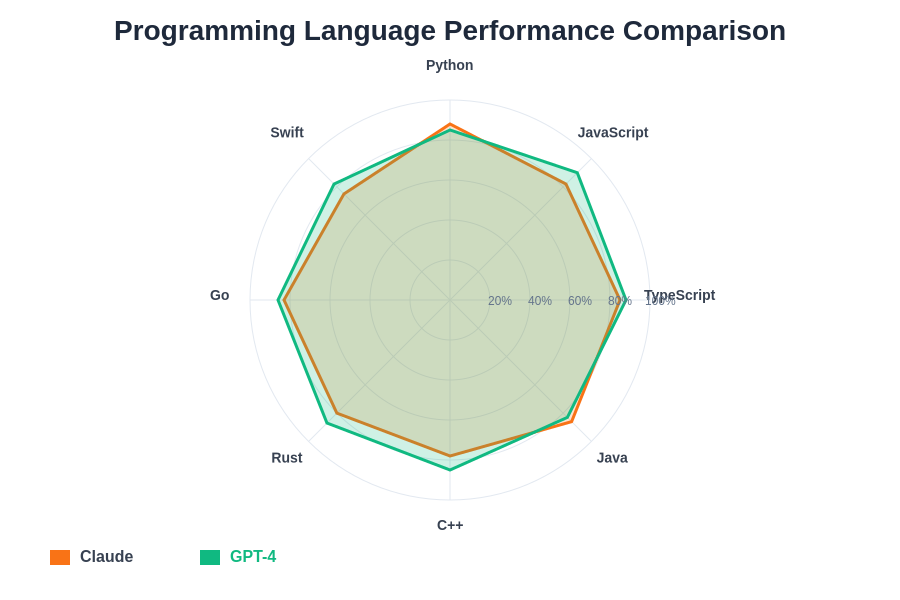
The language-specific performance analysis demonstrates how each model’s strengths align with different programming paradigms and use cases. Claude shows particular excellence in Python development, while GPT-4 demonstrates superior capabilities across JavaScript ecosystems and systems programming languages.
Framework and Library Integration
The ability to work effectively with popular frameworks and libraries represents a crucial differentiator between the two models. Claude demonstrates exceptional understanding of web development frameworks, consistently generating code that follows framework conventions and best practices. When working with Django, for example, Claude produces models, views, and templates that adhere to Django’s philosophy of explicit configuration and maintainable code architecture.
GPT-4 excels in modern JavaScript framework development, particularly with React and its ecosystem. The model demonstrates deep understanding of hooks, context management, and state libraries like Redux and Zustand. It can generate complex component hierarchies, implement advanced patterns like render props and higher-order components, and integrate seamlessly with popular libraries for routing, form handling, and API communication.
Enhance your research capabilities with Perplexity to stay current with the latest framework updates and best practices that both AI models incorporate into their code generation processes. The rapidly evolving nature of web development frameworks requires constant learning and adaptation, making comprehensive research tools essential for effective AI-assisted development.
Security and Best Practices Implementation
Security considerations represent one of the most significant differentiators between Claude and GPT-4 in programming contexts. Claude consistently demonstrates superior awareness of security vulnerabilities and implements defensive programming practices by default. When generating database interaction code, Claude typically includes parameterized queries to prevent SQL injection attacks, implements proper input validation, and includes appropriate error handling that doesn’t expose sensitive system information.
GPT-4, while capable of generating secure code when specifically prompted, often prioritizes functionality over security in its default responses. The model may generate code that works correctly but lacks comprehensive input validation, proper authentication checks, or adequate protection against common attack vectors. However, when security requirements are explicitly specified, GPT-4 can produce highly secure implementations that incorporate advanced security patterns and industry best practices.
Both models demonstrate understanding of modern security frameworks and libraries, but Claude’s constitutional AI training results in more consistent application of security principles across all generated code. This makes Claude particularly valuable for enterprise development environments where security compliance and risk mitigation are primary concerns.
Performance Optimization and Efficiency
Performance optimization capabilities reveal interesting differences in how each model approaches code efficiency and scalability concerns. Claude typically generates code that balances readability with performance, often including comments that explain optimization choices and trade-offs. The model demonstrates strong understanding of algorithmic complexity and consistently suggests implementations that avoid common performance pitfalls like unnecessary loops, inefficient data structure choices, and memory leaks.
GPT-4 often produces more aggressively optimized code, particularly for mathematical computations and data processing tasks. The model can generate highly efficient algorithms and data structures, implement advanced optimization techniques like memoization and caching, and suggest performance improvements for existing code. However, this focus on optimization sometimes comes at the expense of code readability and maintainability.
Both models show proficiency in database optimization, suggesting appropriate indexing strategies, query optimization techniques, and caching implementations. Claude tends to provide more comprehensive explanations of why specific optimizations are beneficial, while GPT-4 focuses on implementing the most effective optimization strategies for immediate performance gains.
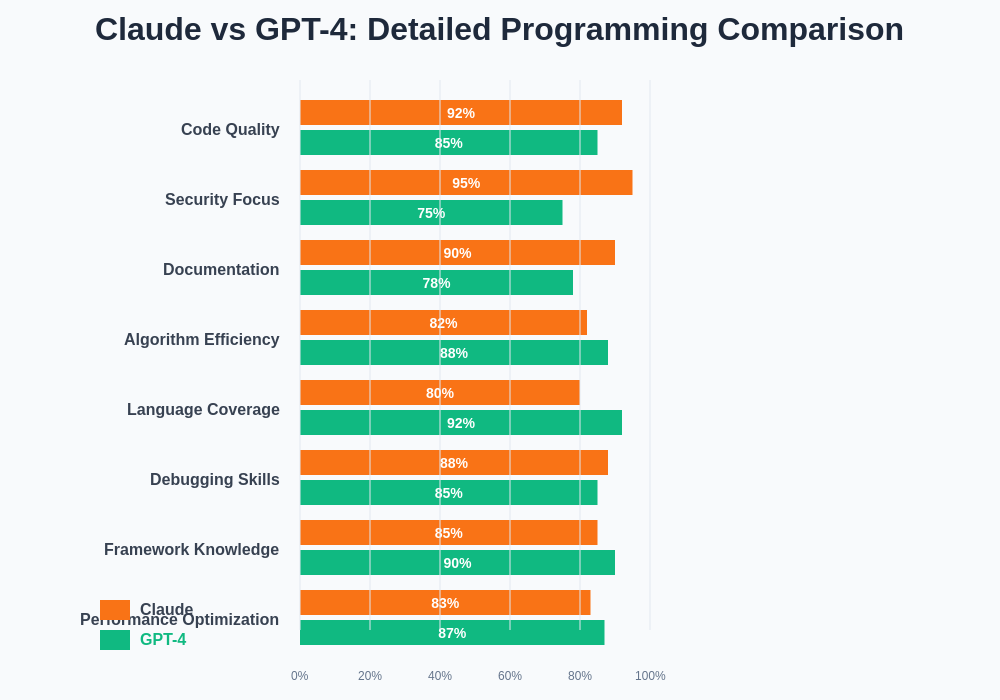
The comprehensive analysis across multiple programming dimensions reveals distinct patterns in how Claude and GPT-4 approach different aspects of software development. Claude consistently excels in areas requiring careful consideration and comprehensive analysis, while GPT-4 demonstrates superior performance in scenarios demanding broad technical knowledge and rapid implementation capabilities.
Testing and Quality Assurance Integration
The approach to testing and quality assurance represents another area where the models show distinct philosophical differences. Claude consistently generates code that includes comprehensive testing strategies, often suggesting unit tests, integration tests, and edge case scenarios that should be considered during development. The model demonstrates strong understanding of testing frameworks across multiple languages and can generate complete test suites that provide meaningful coverage of functionality and error conditions.
GPT-4 excels at generating specific test cases and implementing complex testing scenarios, particularly for challenging edge cases and performance testing requirements. The model can create sophisticated mocking strategies, implement property-based testing approaches, and generate load testing scenarios that thoroughly evaluate system performance under various conditions.
Both models understand modern continuous integration and deployment practices, but Claude typically provides more comprehensive guidance on integrating testing into development workflows, while GPT-4 focuses on generating the most effective test implementations for specific scenarios and requirements.
Documentation and Code Explanation
Documentation quality represents a significant strength for Claude, which consistently generates comprehensive, well-structured documentation that explains not only what code does but why specific implementation choices were made. The model excels at creating API documentation, inline comments, and architectural decision records that help teams understand and maintain complex codebases over time.
GPT-4 produces functional documentation that covers essential usage information and implementation details, but with less emphasis on the reasoning behind design decisions. The model excels at generating quick reference materials, code examples, and troubleshooting guides that help developers quickly understand and implement specific functionality.
Both models can generate documentation in various formats, from simple markdown files to comprehensive technical specifications, but Claude’s approach tends to be more educational and thorough, while GPT-4 focuses on practical implementation guidance and immediate usability.
Real-World Application Scenarios
In practical development scenarios, the choice between Claude and GPT-4 often depends on specific project requirements and team dynamics. Claude proves particularly valuable for enterprise development environments where code maintainability, security compliance, and comprehensive documentation are essential. The model’s conservative approach and emphasis on best practices make it ideal for teams working on mission-critical applications where reliability and long-term maintainability outweigh rapid development speed.
GPT-4 excels in startup environments and rapid prototyping scenarios where speed of development and ability to quickly iterate on complex ideas are paramount. The model’s broad knowledge base and ability to generate functional code across diverse technology stacks make it invaluable for small teams that need to work across multiple domains and technologies without deep specialization in every area.
Both models prove effective for educational purposes, but with different strengths. Claude’s detailed explanations and emphasis on best practices make it excellent for teaching proper programming techniques and helping developers understand complex concepts. GPT-4’s ability to generate diverse examples and handle complex algorithmic challenges makes it valuable for advanced computer science education and research applications.
Integration with Development Workflows
The integration of both models into existing development workflows requires consideration of team processes, code review practices, and quality assurance standards. Claude’s emphasis on comprehensive documentation and best practices makes it easier to integrate into teams with established code review processes, as the generated code typically requires less modification to meet enterprise standards.
GPT-4’s rapid code generation capabilities make it particularly valuable for teams following agile development methodologies where quick iteration and frequent feature delivery are prioritized. The model’s ability to quickly generate functional prototypes and proof-of-concept implementations can significantly accelerate the development cycle.
Both models benefit from integration with modern development tools like IDEs, code review systems, and continuous integration pipelines. However, the specific integration approach should be tailored to take advantage of each model’s strengths while mitigating potential weaknesses through appropriate human oversight and quality assurance processes.
Future Evolution and Capabilities
The ongoing development of both Claude and GPT-4 suggests continued improvement in programming assistance capabilities, with each model likely to maintain its distinctive strengths while addressing current limitations. Claude’s constitutional AI approach will likely result in even more comprehensive security analysis and best practice implementation, making it increasingly valuable for enterprise and mission-critical applications.
GPT-4’s evolution will likely focus on expanding its already impressive breadth of knowledge while improving code optimization and efficiency capabilities. The model’s ability to handle complex, multi-domain programming challenges will continue to make it valuable for innovative projects that require deep technical expertise across diverse technology stacks.
Both models will likely benefit from improved integration with development tools, better understanding of emerging programming languages and frameworks, and enhanced ability to work with large, complex codebases. The future of AI-assisted programming will likely involve using both models in complementary ways, leveraging each model’s strengths for different aspects of the development process.
Making the Right Choice for Your Development Needs
The decision between Claude and GPT-4 for programming assistance ultimately depends on specific project requirements, team dynamics, and development priorities. Teams prioritizing code security, maintainability, and comprehensive documentation will find Claude’s approach more aligned with their needs, while teams focused on rapid development, broad technology coverage, and algorithmic complexity will benefit more from GPT-4’s capabilities.
The most effective approach may involve using both models strategically, leveraging Claude for architecture planning, security analysis, and documentation while utilizing GPT-4 for rapid prototyping, complex algorithm implementation, and diverse technology integration. This hybrid approach maximizes the benefits of both models while mitigating their individual limitations through complementary strengths.
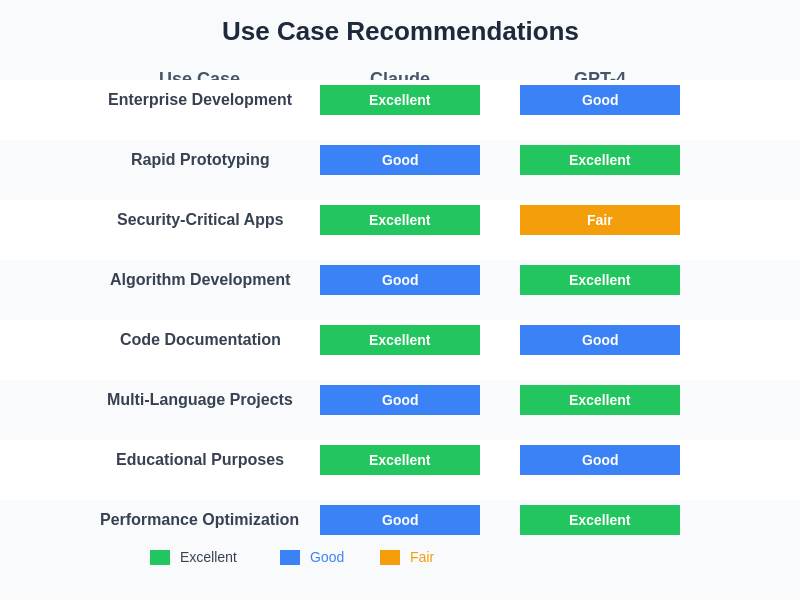
The strategic application of each model depends heavily on project requirements and development priorities. Understanding when to leverage Claude’s methodical approach versus GPT-4’s rapid implementation capabilities enables development teams to optimize their AI-assisted workflows for maximum effectiveness and quality outcomes.
Understanding the specific strengths and characteristics of each model enables development teams to make informed decisions about which AI assistant best supports their particular development goals and constraints. The choice between Claude and GPT-4 should be based on careful consideration of project requirements, team expertise, and long-term maintenance considerations rather than simply defaulting to the most popular or widely available option.
Disclaimer
This article provides analysis based on current understanding of Claude and GPT-4 capabilities for programming tasks. Individual experiences may vary depending on specific use cases, programming languages, and project requirements. Readers should evaluate both models based on their particular needs and conduct their own testing to determine which tool best supports their development objectives. The effectiveness of AI programming assistance depends on proper integration with existing development processes and appropriate human oversight for quality assurance and security validation.