
The convergence of artificial intelligence and DevOps methodologies has created an entirely new paradigm in software development that demands sophisticated testing strategies specifically designed for machine learning systems. Continuous testing in AI represents a fundamental shift from traditional software testing approaches, requiring comprehensive validation of data quality, model performance, and deployment reliability throughout the entire machine learning lifecycle. This integration of DevOps practices with ML pipelines has become essential for organizations seeking to deploy reliable, scalable, and maintainable AI solutions in production environments.
The complexity inherent in machine learning systems extends far beyond conventional software applications, encompassing data pipelines, feature engineering processes, model training workflows, and inference services that must all work harmoniously together. Stay updated with the latest AI development trends to understand how continuous testing practices are evolving alongside rapidly advancing AI technologies. The implementation of continuous testing in AI systems requires a deep understanding of both traditional DevOps principles and the unique challenges presented by machine learning workflows, including data drift, model degradation, and the inherently probabilistic nature of AI predictions.
Understanding the Unique Testing Challenges in AI Systems
Machine learning systems present testing challenges that are fundamentally different from those encountered in traditional software development. Unlike conventional applications where deterministic inputs produce predictable outputs, AI systems operate with probabilistic models that generate results based on statistical patterns learned from training data. This probabilistic nature introduces uncertainty that must be carefully managed through comprehensive testing strategies that account for model variance, data distribution changes, and performance degradation over time.
The testing pyramid concept, widely adopted in traditional software development, requires significant adaptation when applied to machine learning systems. While unit tests remain important for validating individual components such as data preprocessing functions and utility methods, the emphasis shifts toward integration tests that validate entire data pipelines and model performance tests that assess prediction accuracy across diverse scenarios. The traditional approach of mocking dependencies becomes particularly challenging in AI systems where the quality and characteristics of data significantly impact system behavior, requiring more sophisticated testing methodologies that incorporate realistic data scenarios and edge cases.
Data quality represents perhaps the most critical aspect of AI system testing, as the fundamental principle of machine learning dictates that model quality is directly dependent on training data quality. Traditional software testing focuses primarily on code logic and functionality, but AI systems require extensive validation of data schemas, distribution characteristics, completeness, and consistency across different data sources and time periods. This expanded scope of testing necessitates specialized tools and frameworks designed specifically for data validation and quality assessment.
Implementing Continuous Integration for ML Pipelines
The implementation of continuous integration practices in machine learning pipelines requires careful orchestration of multiple interconnected components that must be validated at each stage of the development process. Unlike traditional CI/CD pipelines that primarily focus on code compilation, unit testing, and deployment, ML pipelines must incorporate data validation, feature engineering verification, model training automation, and performance benchmarking into the continuous integration workflow.
Enhance your AI development workflow with advanced tools like Claude to streamline the integration of continuous testing practices into your machine learning development processes. The integration of AI-powered development tools can significantly improve the efficiency and reliability of continuous testing implementations by providing intelligent analysis of test results, automated detection of performance regressions, and sophisticated debugging capabilities for complex ML systems.
The containerization of machine learning workflows has become essential for ensuring consistency and reproducibility across different environments. Docker containers provide isolated environments that encapsulate not only the application code but also the specific versions of machine learning frameworks, dependencies, and system libraries required for consistent model behavior. This containerization strategy enables reliable testing across development, staging, and production environments while facilitating automated deployment processes that can be triggered by successful test completion.
Model versioning represents another critical aspect of continuous integration for ML pipelines, as machine learning models must be treated as first-class artifacts that require systematic tracking, validation, and deployment management. Unlike traditional software artifacts that are primarily text-based and can be efficiently managed through conventional version control systems, ML models often consist of large binary files containing trained parameters that require specialized versioning strategies and storage solutions designed to handle the unique characteristics of machine learning artifacts.
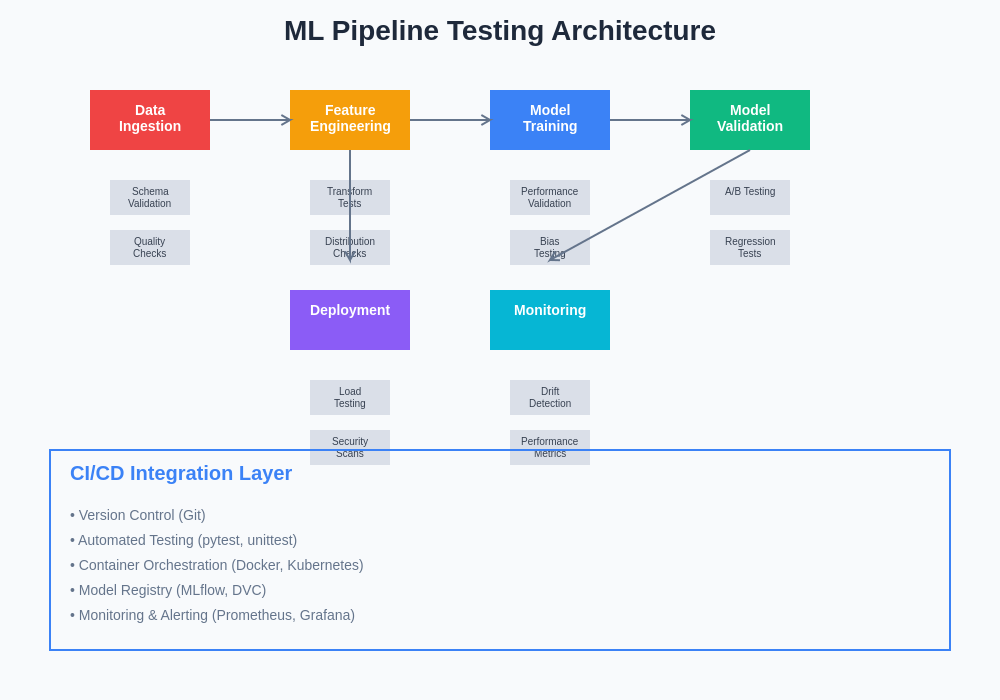
The architectural complexity of machine learning testing systems requires careful consideration of component interactions, data flow validation, and performance monitoring across multiple stages of the pipeline. This comprehensive approach ensures that quality gates are maintained throughout the entire ML lifecycle from data ingestion to model serving.
Automated Data Quality Validation
Data quality validation forms the foundation of reliable machine learning systems, as the accuracy and reliability of AI predictions depend entirely on the quality and characteristics of the input data. Automated data quality validation systems must continuously monitor data schemas, statistical properties, and distribution characteristics to detect anomalies, drift, and quality degradation that could negatively impact model performance. These validation systems typically implement a multi-layered approach that includes schema validation, statistical profiling, data completeness checks, and consistency verification across different data sources.
The implementation of data quality validation requires sophisticated monitoring systems that can detect subtle changes in data distribution that might not be immediately apparent through traditional testing approaches. Statistical tests such as the Kolmogorov-Smirnov test, Mann-Whitney U test, and Population Stability Index can be automated to continuously assess whether incoming data maintains the same statistical characteristics as the training data used to develop machine learning models. These statistical validations provide early warning signals that can prevent model degradation before it impacts production performance.
Real-time data quality monitoring presents unique challenges that require streaming analytics capabilities and low-latency validation systems. Unlike batch processing scenarios where comprehensive data quality analysis can be performed on complete datasets, real-time systems must implement efficient validation algorithms that can assess data quality within strict latency constraints while maintaining the accuracy and comprehensiveness of quality assessments. This balance between speed and thoroughness requires careful optimization of validation algorithms and strategic selection of quality metrics that provide maximum insight with minimal computational overhead.
The integration of data quality validation with alerting and remediation systems ensures that quality issues are promptly detected and addressed before they can impact downstream systems. Automated remediation strategies might include data cleaning procedures, alternative data source activation, or graceful degradation mechanisms that maintain system functionality while quality issues are resolved. These automated responses must be carefully designed to avoid introducing bias or systematic errors that could compromise model performance.
Model Performance Testing and Validation
Model performance testing in continuous integration environments requires comprehensive evaluation frameworks that assess not only overall accuracy metrics but also performance across different data segments, edge cases, and operational conditions. Traditional software testing focuses on functional correctness, but machine learning model testing must evaluate statistical performance, fairness across different demographic groups, robustness to input variations, and stability under different operational conditions.
The establishment of performance baselines and regression testing for machine learning models presents unique challenges due to the inherent variability in model training processes. Unlike deterministic software functions that produce identical outputs given the same inputs, machine learning model training involves random initialization, stochastic optimization algorithms, and data sampling procedures that introduce variance in model performance even when trained on identical datasets. Continuous integration systems must account for this variance by implementing statistical significance testing and confidence interval analysis to distinguish between meaningful performance changes and natural variation.
A/B testing frameworks integrated into continuous integration pipelines enable automated comparison of model variants and performance validation before production deployment. These frameworks must be carefully designed to ensure statistical rigor while providing timely feedback to development teams. The implementation of multi-armed bandit algorithms can optimize the allocation of traffic between different model versions while gathering sufficient statistical evidence to make informed deployment decisions.
Model explainability and interpretability testing has become increasingly important as organizations deploy AI systems in regulated industries and high-stakes applications. Automated testing of model explanations ensures that feature importance rankings remain consistent, prediction confidence scores are properly calibrated, and explanation quality meets established standards. These explainability tests help maintain trust and regulatory compliance while providing valuable insights into model behavior changes over time.
Infrastructure Testing for AI Systems
The infrastructure supporting machine learning systems requires specialized testing approaches that account for the unique resource requirements, scaling patterns, and performance characteristics of AI workloads. Unlike traditional web applications that primarily consume CPU and memory resources in predictable patterns, machine learning systems often require GPU acceleration, large memory allocations for model loading, and significant storage capacity for data and model artifacts. Infrastructure testing must validate that these resources are properly provisioned, scaled, and managed throughout the deployment lifecycle.
Container orchestration platforms such as Kubernetes provide powerful capabilities for managing machine learning workloads, but they also introduce complexity that must be thoroughly tested. Infrastructure tests must validate that pod scheduling correctly considers GPU requirements, memory constraints are properly enforced, and storage volumes are correctly mounted and accessible to ML containers. The dynamic scaling behavior of machine learning services must be tested to ensure that auto-scaling policies respond appropriately to traffic patterns and resource utilization metrics specific to AI workloads.
Leverage advanced AI research capabilities with Perplexity to stay current with emerging infrastructure testing methodologies and tools specifically designed for machine learning systems. The rapidly evolving landscape of AI infrastructure requires continuous learning and adaptation of testing strategies to accommodate new technologies, deployment patterns, and operational requirements.
Network performance testing becomes particularly critical for machine learning systems that serve real-time predictions or process large volumes of data. Latency testing must account for model inference time, data serialization overhead, and network transmission delays to ensure that service level objectives are met under various load conditions. Load testing frameworks must simulate realistic traffic patterns that reflect the specific characteristics of AI workloads, including batch prediction requests, streaming data processing, and interactive query patterns.
Monitoring and Observability in Production
Production monitoring for machine learning systems extends far beyond traditional application performance monitoring to include model-specific metrics, data quality indicators, and business impact assessments. Effective monitoring strategies must provide visibility into model prediction accuracy, feature drift, data quality degradation, and system performance while correlating these technical metrics with business outcomes and user experience indicators.
The implementation of model performance monitoring requires sophisticated metrics collection and analysis systems that can detect subtle changes in model behavior that might indicate quality degradation or drift. These monitoring systems must track prediction confidence distributions, feature importance changes, and performance variations across different data segments to provide comprehensive visibility into model health and reliability.
Real-time alerting systems for machine learning applications must be carefully tuned to provide meaningful notifications while avoiding alert fatigue. The probabilistic nature of machine learning systems means that some degree of prediction variance is normal and expected, requiring alerting systems that can distinguish between normal operational variance and meaningful performance degradation. Advanced alerting strategies might incorporate statistical process control techniques, anomaly detection algorithms, and trend analysis to provide more intelligent and actionable alerts.
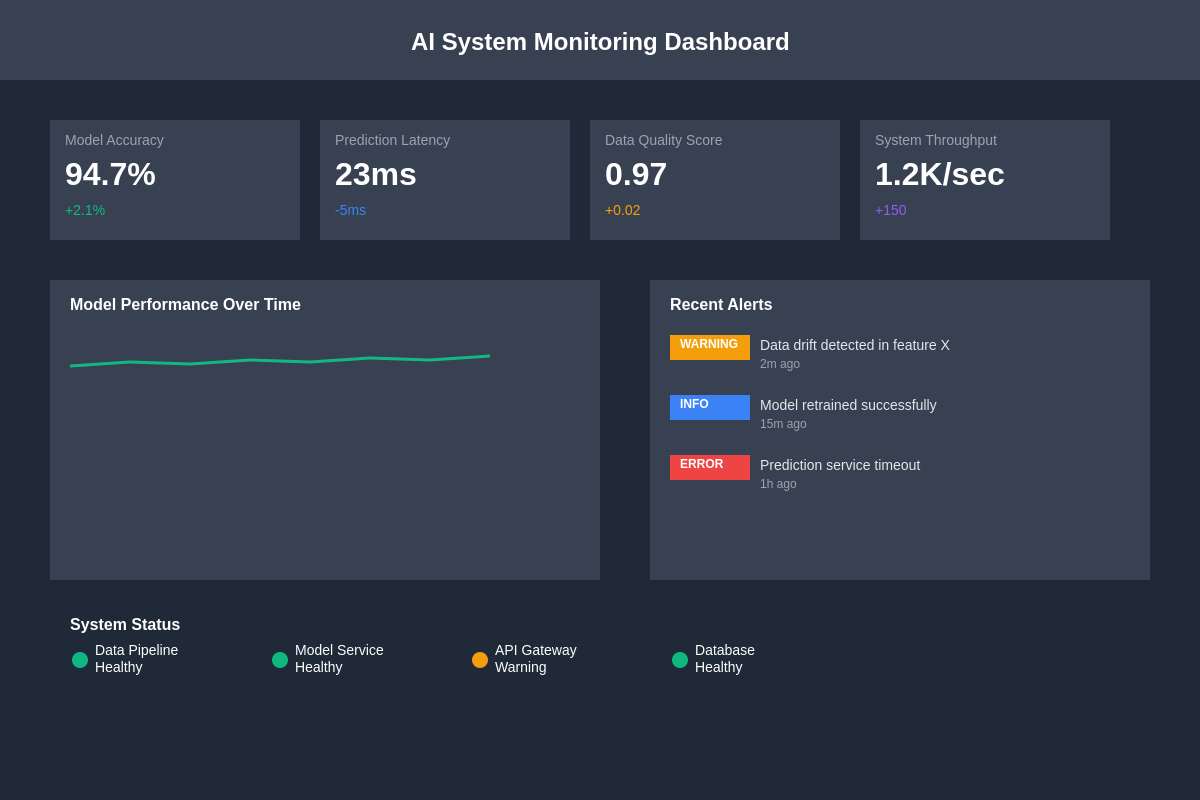
Comprehensive monitoring dashboards provide stakeholders with real-time visibility into system health, performance trends, and business impact metrics. These visualization tools must present complex technical information in accessible formats that enable both technical teams and business stakeholders to understand system performance and make informed decisions about optimization and maintenance activities.
The correlation of technical metrics with business outcomes provides crucial insights into the real-world impact of machine learning systems and helps prioritize improvement efforts. Business impact monitoring might track conversion rates, user satisfaction scores, operational efficiency metrics, or other key performance indicators that directly reflect the value delivered by AI systems. This correlation helps organizations make data-driven decisions about model updates, infrastructure investments, and feature development priorities.
Advanced Testing Strategies for ML Systems
Advanced testing methodologies for machine learning systems incorporate sophisticated techniques such as adversarial testing, mutation testing, and property-based testing that are specifically designed to validate the robustness and reliability of AI systems under challenging conditions. Adversarial testing involves deliberately crafting inputs designed to expose weaknesses in model behavior, helping identify vulnerabilities that could be exploited by malicious actors or encountered in unexpected operational scenarios.
Mutation testing for machine learning systems involves systematically modifying training data, model architectures, or hyperparameters to assess the sensitivity and robustness of the overall system. This approach helps identify critical dependencies and potential points of failure while providing insights into the stability of model performance under various conditions. The implementation of mutation testing requires careful consideration of the types of mutations that are most relevant to the specific machine learning domain and application requirements.
Property-based testing extends traditional unit testing concepts to machine learning systems by defining invariant properties that should hold across different inputs and conditions. For example, a recommendation system might be tested to ensure that the ordering of recommendations remains consistent for identical user profiles, or an image classification system might be validated to ensure that small perturbations to input images do not dramatically change prediction confidence scores.
The integration of chaos engineering principles into machine learning testing introduces controlled failures and stress conditions to validate system resilience and recovery capabilities. Chaos testing for ML systems might involve simulating data source failures, introducing network latency, corrupting model files, or overwhelming inference services with traffic to assess how gracefully the system handles various failure modes.
Continuous Delivery and Deployment Strategies
The implementation of continuous delivery for machine learning systems requires sophisticated deployment strategies that can safely transition between model versions while maintaining service availability and performance standards. Blue-green deployments, canary releases, and feature flagging techniques must be adapted to account for the unique characteristics of machine learning models and the potential impact of model changes on user experience and business metrics.
Canary deployment strategies for machine learning models involve gradually routing traffic to new model versions while continuously monitoring performance metrics and business impact indicators. The success criteria for canary deployments must include both technical metrics such as prediction accuracy and latency, as well as business metrics such as conversion rates and user engagement. Automated rollback mechanisms must be implemented to quickly revert to previous model versions if performance degradation is detected.
The management of model artifacts throughout the deployment pipeline requires specialized tools and processes that can handle the unique characteristics of machine learning models. Model registries provide centralized repositories for storing, versioning, and managing model artifacts while maintaining metadata about training procedures, performance metrics, and deployment history. These registries integrate with continuous delivery pipelines to enable automated model promotion through different environment stages.
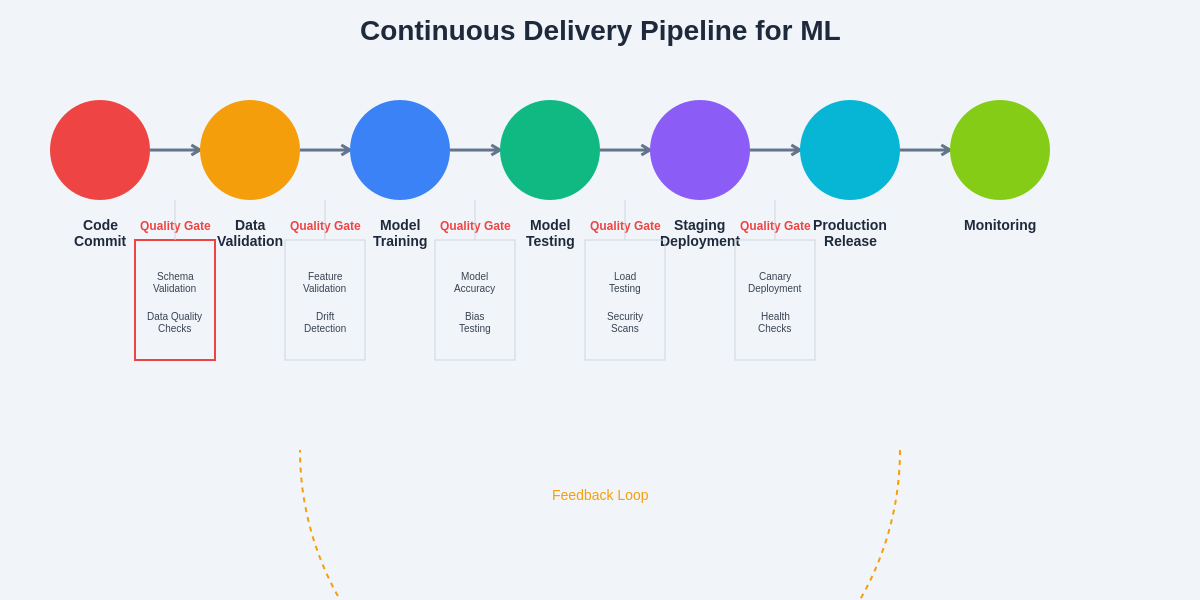
The continuous delivery pipeline for machine learning systems encompasses multiple stages of validation, testing, and deployment that ensure quality and reliability throughout the model lifecycle. This comprehensive approach provides multiple quality gates that prevent low-quality models from reaching production while enabling rapid iteration and improvement of AI systems.
Feature store management represents a critical component of continuous delivery for machine learning systems, as consistent and reliable access to features across training and serving environments is essential for model performance and reliability. Feature stores must be integrated into continuous delivery pipelines to ensure that feature definitions, transformations, and quality checks are consistently applied across all environments and deployment stages.
Security Testing for AI Applications
Security testing for artificial intelligence applications requires specialized approaches that address unique vulnerabilities and attack vectors specific to machine learning systems. Traditional application security testing focuses on common vulnerabilities such as injection attacks, authentication bypasses, and data exposure, but AI systems introduce additional security concerns including model extraction attacks, adversarial input manipulation, and training data poisoning that require specialized testing methodologies.
Model extraction attacks attempt to reverse-engineer machine learning models by analyzing their outputs and behavior patterns. Security testing must validate that sufficient protections are in place to prevent unauthorized access to model parameters, training procedures, and proprietary algorithms. This might involve implementing query limitations, response obfuscation techniques, and access controls that prevent systematic probing of model behavior.
Adversarial input testing involves systematically generating inputs designed to fool machine learning models into making incorrect predictions or revealing sensitive information. These tests help identify vulnerabilities that could be exploited by malicious actors while providing insights into model robustness and reliability. The implementation of adversarial testing requires sophisticated tools and techniques that can generate realistic adversarial examples relevant to the specific application domain.
Privacy testing for machine learning systems must validate that models do not inadvertently leak sensitive information about training data or individual users. Differential privacy techniques, membership inference attack testing, and data anonymization validation help ensure that AI systems comply with privacy regulations and protect user information. These testing approaches are particularly important for machine learning systems that process personal or sensitive data.
Organizational Integration and Culture
The successful implementation of continuous testing in AI systems requires significant organizational changes that extend beyond technical implementations to encompass cultural shifts, role definitions, and cross-functional collaboration patterns. Traditional software development organizations must evolve to accommodate the unique requirements of machine learning development, including the need for close collaboration between data scientists, machine learning engineers, DevOps specialists, and domain experts.
The establishment of clear roles and responsibilities for AI system testing requires careful consideration of the diverse skill sets required for effective machine learning operations. Data scientists bring deep expertise in statistical analysis and model development, while DevOps engineers contribute infrastructure automation and deployment expertise. The integration of these complementary skill sets requires new organizational structures and communication patterns that facilitate effective collaboration and knowledge sharing.
Training and skill development programs must be implemented to help traditional software developers and operations teams acquire the specialized knowledge required for AI system testing and deployment. This educational investment includes technical training on machine learning concepts, statistical analysis techniques, and specialized tools, as well as process training on AI-specific development methodologies and quality assurance practices.
The measurement and optimization of AI development processes requires new metrics and key performance indicators that reflect the unique characteristics of machine learning development lifecycles. Traditional software development metrics such as lines of code, defect density, and deployment frequency must be supplemented with AI-specific metrics such as model accuracy trends, data quality scores, and prediction serving latency to provide comprehensive visibility into development effectiveness and system performance.
Future Directions and Emerging Trends
The evolution of continuous testing practices for artificial intelligence systems continues to accelerate as new technologies, methodologies, and tools emerge to address the growing complexity and scale of machine learning deployments. Emerging trends in AI testing include the integration of automated testing with machine learning techniques that can intelligently generate test cases, predict failure modes, and optimize testing strategies based on historical performance data and system behavior patterns.
The development of standardized testing frameworks and industry best practices for machine learning systems represents a significant opportunity to improve the reliability and quality of AI applications across different domains and organizations. Industry consortiums, standards organizations, and open-source communities are actively working to establish common testing methodologies, quality metrics, and certification processes that can provide consistency and interoperability across different AI development platforms and deployment environments.
The integration of edge computing and distributed AI systems introduces new testing challenges that require innovative approaches to validation and quality assurance. Edge AI systems must be tested across diverse hardware platforms, network conditions, and operational environments while maintaining consistent performance and reliability standards. This distributed testing challenge requires new tools and methodologies that can efficiently validate AI systems across heterogeneous deployment scenarios.
The continued advancement of AI technologies, including large language models, computer vision systems, and autonomous decision-making platforms, will require corresponding evolution in testing methodologies and quality assurance practices. These advanced AI systems present new categories of risks and failure modes that must be carefully addressed through comprehensive testing strategies that can keep pace with the rapid advancement of artificial intelligence capabilities.
The future of continuous testing in AI lies in the intelligent automation of quality assurance processes that can adapt to changing requirements, learn from historical testing data, and provide predictive insights into system reliability and performance. This vision of self-improving testing systems represents the natural convergence of DevOps practices with artificial intelligence capabilities, creating testing frameworks that become more effective and efficient over time through the application of machine learning techniques to the testing process itself.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The implementation of continuous testing strategies for AI systems should be tailored to specific organizational requirements, regulatory constraints, and technical environments. Readers should conduct thorough research and consider consulting with qualified professionals when implementing AI testing frameworks and DevOps practices. The effectiveness of testing strategies may vary depending on specific use cases, data characteristics, and system architectures.