
The performance demands of modern machine learning applications have made C++ optimization an essential skill for developers working with inference engines and real-time AI systems. As machine learning models become increasingly complex and deployment environments more resource-constrained, the ability to squeeze maximum performance from hardware through sophisticated C++ optimization techniques has become a critical differentiator in production systems. This comprehensive exploration delves into the advanced methodologies, architectural considerations, and implementation strategies that enable developers to achieve unprecedented levels of performance in machine learning model inference.
Stay updated with the latest AI optimization trends to understand how cutting-edge techniques are being applied across different industries and use cases. The intersection of high-performance computing and artificial intelligence continues to evolve rapidly, creating new opportunities for developers who master these optimization principles to build systems that can handle the most demanding computational workloads while maintaining exceptional efficiency and reliability.
Understanding the Performance Landscape
Machine learning inference presents unique challenges that distinguish it from traditional computational workloads. The mathematical operations underlying neural network inference involve massive amounts of matrix multiplication, convolution operations, and element-wise transformations that must be executed with minimal latency while maintaining numerical accuracy. Modern deep learning models often contain millions or billions of parameters, requiring careful orchestration of memory access patterns, computational resources, and data movement to achieve optimal performance across diverse hardware architectures.
The performance characteristics of machine learning inference are fundamentally different from training workloads, as inference typically prioritizes low latency and consistent throughput over raw computational power. This distinction requires specialized optimization approaches that focus on minimizing memory allocation overhead, maximizing cache utilization, and leveraging hardware-specific acceleration features such as vectorization instructions and specialized neural processing units. Understanding these performance requirements forms the foundation for implementing effective optimization strategies that can deliver substantial improvements in real-world applications.
Memory Management and Access Pattern Optimization
Efficient memory management represents one of the most critical aspects of C++ optimization for machine learning inference. The performance impact of memory allocation, deallocation, and access patterns can be profound, particularly when dealing with large tensor operations and frequent model inference calls. Modern C++ optimization techniques focus on minimizing dynamic memory allocation during inference by pre-allocating memory pools, implementing custom allocators, and utilizing stack-based storage for frequently accessed data structures.
Cache-friendly data structures and access patterns play a crucial role in achieving optimal performance. The hierarchical nature of modern memory systems means that data locality can have dramatic effects on performance, with cache misses potentially causing orders of magnitude performance degradation. Optimization strategies include restructuring data layouts to improve spatial locality, implementing cache-oblivious algorithms, and utilizing prefetching techniques to ensure that required data is available in fast memory before it is needed.
Explore advanced AI development tools like Claude to understand how modern AI systems implement sophisticated optimization techniques and learn from best practices in high-performance machine learning implementations. The synergy between algorithmic optimization and hardware-aware programming creates opportunities for achieving performance levels that were previously thought impossible.
SIMD Vectorization and Parallel Processing
Single Instruction Multiple Data vectorization represents one of the most powerful techniques for accelerating machine learning computations in C++. Modern processors provide extensive SIMD instruction sets such as AVX-512, which can perform multiple floating-point operations simultaneously, dramatically increasing computational throughput for suitable algorithms. Effective utilization of SIMD instructions requires careful consideration of data alignment, instruction selection, and algorithm restructuring to ensure that computations can be expressed in forms that leverage vector processing capabilities.
The implementation of efficient vectorized operations extends beyond simple loop vectorization to encompass sophisticated techniques such as data format conversion, mixed-precision arithmetic, and specialized algorithms designed specifically for vector execution. Advanced optimization approaches include utilizing compiler intrinsics for fine-grained control over instruction generation, implementing hand-optimized assembly code for critical computational kernels, and designing algorithms that can effectively utilize the full width of available vector units while maintaining numerical stability and accuracy.
Compiler Optimization and Code Generation
Modern C++ compilers provide sophisticated optimization capabilities that can dramatically improve machine learning inference performance when properly configured and utilized. Profile-guided optimization represents a particularly powerful technique where the compiler uses runtime profiling information to make informed decisions about code generation, instruction scheduling, and optimization trade-offs. This approach can result in significant performance improvements by optimizing the most frequently executed code paths while minimizing overhead for less critical operations.
Advanced compiler optimization techniques include link-time optimization, which enables cross-module optimizations that can eliminate function call overhead and enable more aggressive inlining decisions. Template metaprogramming and constexpr evaluation allow computations to be moved from runtime to compile time, reducing the computational burden during inference. Additionally, careful attention to compiler flags, optimization levels, and target-specific instruction generation can unlock substantial performance improvements that are often overlooked in standard optimization approaches.
Hardware-Specific Acceleration Strategies
The diversity of modern hardware architectures requires specialized optimization strategies that can effectively utilize the unique capabilities of different processing units. CPU optimization focuses on maximizing instruction-level parallelism, minimizing memory latency, and efficiently utilizing multi-core architectures through techniques such as thread-level parallelism and work-stealing algorithms. These approaches ensure that inference workloads can scale effectively across available CPU cores while maintaining load balance and minimizing synchronization overhead.
GPU acceleration presents additional opportunities for performance improvement through the utilization of thousands of parallel processing cores optimized for floating-point computations. Effective GPU optimization requires understanding of memory hierarchies, thread organization, and kernel optimization techniques that can maximize occupancy and computational throughput. Advanced strategies include implementing custom CUDA kernels for specialized operations, utilizing tensor core acceleration for mixed-precision arithmetic, and optimizing memory transfer patterns to minimize PCIe bandwidth limitations.
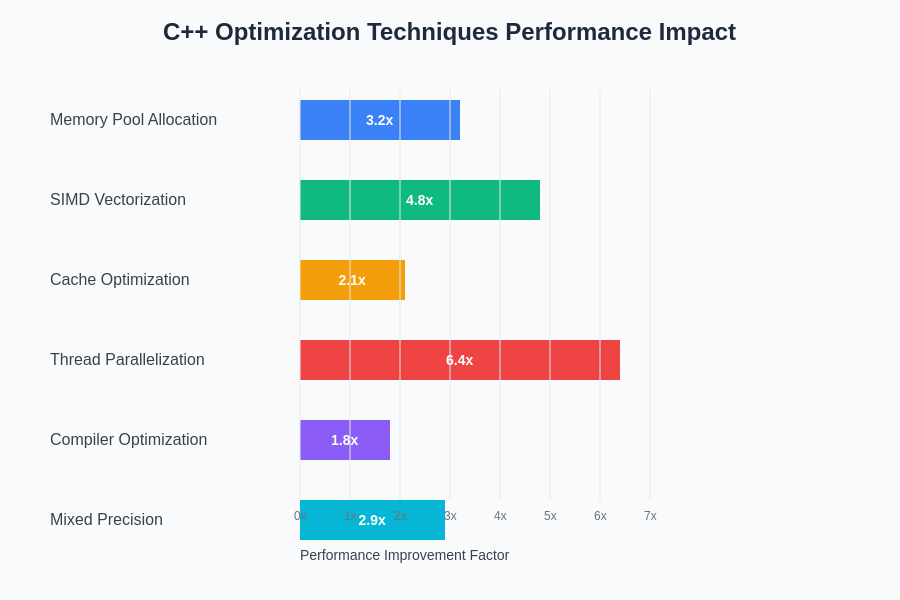
The quantitative impact of different optimization techniques varies significantly depending on the specific characteristics of the machine learning model and target hardware architecture. Comprehensive performance analysis demonstrates that memory optimization typically provides the most consistent improvements across different scenarios, while vectorization and parallelization techniques can deliver dramatic performance gains for computationally intensive operations.
Advanced Algorithmic Optimizations
Algorithmic optimization at the implementation level can provide substantial performance improvements that complement lower-level hardware optimizations. Techniques such as loop unrolling, loop fusion, and loop tiling can improve cache utilization and reduce instruction overhead while maintaining algorithmic correctness. These optimizations require careful analysis of data dependencies, memory access patterns, and computational complexity to ensure that modifications actually improve rather than degrade performance.
Specialized algorithms designed specifically for inference workloads can provide significant advantages over general-purpose implementations. Examples include optimized matrix multiplication routines that leverage specific matrix dimensions and sparsity patterns, custom convolution algorithms that exploit spatial locality in image processing tasks, and specialized numerical methods that trade off some numerical precision for dramatic performance improvements while maintaining acceptable accuracy levels.
Enhance your research capabilities with Perplexity to stay current with the latest developments in high-performance computing and machine learning optimization techniques. The rapid pace of innovation in this field requires continuous learning and adaptation to maintain competitive performance levels.
Model Quantization and Precision Optimization
Numerical precision optimization represents a sophisticated approach to improving inference performance through the strategic reduction of computational and memory requirements. Model quantization techniques can reduce memory bandwidth requirements, increase cache effectiveness, and enable the utilization of specialized hardware instructions designed for lower-precision arithmetic. The implementation of effective quantization strategies requires careful consideration of numerical stability, error propagation, and accuracy preservation across different model architectures and use cases.
Advanced precision optimization techniques include dynamic range analysis to determine optimal quantization parameters, mixed-precision implementations that use different precision levels for different operations, and custom data types optimized for specific hardware architectures. These approaches can deliver substantial performance improvements while maintaining acceptable accuracy levels, but require sophisticated implementation strategies to handle edge cases and ensure numerical stability across diverse input distributions.
Profiling and Performance Analysis
Effective optimization requires comprehensive profiling and performance analysis to identify bottlenecks, validate optimization effectiveness, and guide further improvement efforts. Modern profiling tools provide detailed insights into processor utilization, memory access patterns, cache performance, and instruction-level execution characteristics that enable data-driven optimization decisions. The systematic application of profiling techniques ensures that optimization efforts focus on the most impactful areas rather than pursuing theoretical improvements that may not translate to real-world performance gains.
Performance analysis extends beyond basic profiling to encompass sophisticated techniques such as statistical performance modeling, regression analysis for performance prediction, and automated benchmark generation for continuous performance monitoring. These approaches enable the development of optimization strategies that are robust across different input distributions, hardware configurations, and deployment environments while maintaining consistent performance characteristics.
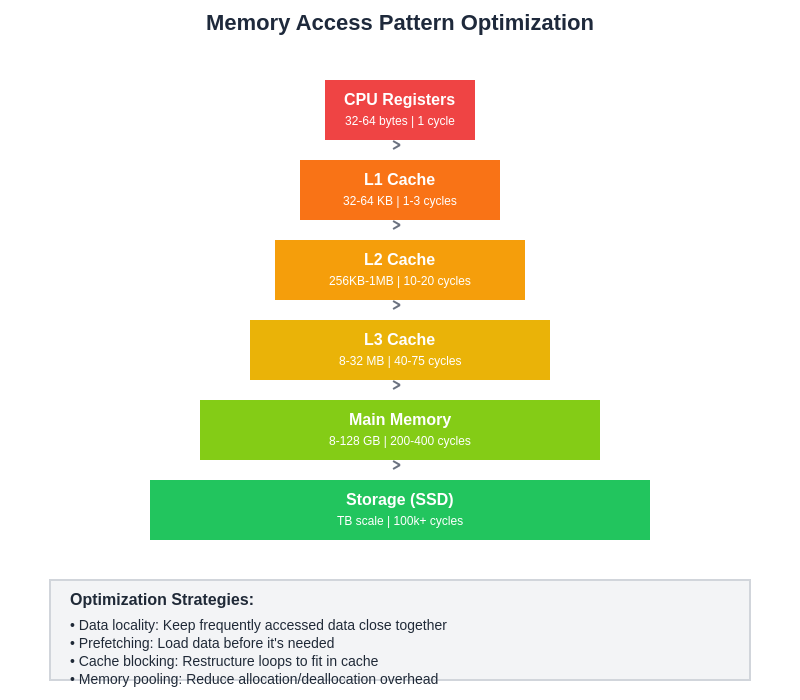
Understanding memory access patterns and their optimization represents one of the most critical aspects of C++ performance tuning for machine learning inference. The hierarchical nature of modern memory systems creates opportunities for substantial performance improvements through careful attention to data layout, access patterns, and cache utilization strategies.
Thread-Level Parallelization Strategies
Effective utilization of multi-core architectures requires sophisticated parallelization strategies that can distribute inference workloads across available processing cores while minimizing synchronization overhead and maintaining load balance. Thread-level parallelization for machine learning inference presents unique challenges due to the dependencies inherent in neural network computations and the need to maintain consistent latency characteristics across different levels of parallelism.
Advanced parallelization techniques include task-based parallelism that can adapt to different model architectures and input characteristics, lock-free data structures that minimize contention in multi-threaded environments, and specialized work-stealing algorithms optimized for the irregular workload patterns common in machine learning applications. These approaches enable effective scaling across multiple cores while maintaining the low-latency characteristics essential for real-time inference applications.
Understanding memory access patterns and their optimization represents one of the most critical aspects of C++ performance tuning for machine learning inference. The hierarchical nature of modern memory systems creates opportunities for substantial performance improvements through careful attention to data layout, access patterns, and cache utilization strategies.
Integration with Specialized Libraries and Frameworks
The ecosystem of high-performance computing libraries provides numerous opportunities for leveraging optimized implementations of common machine learning operations. Libraries such as Intel MKL, cuBLAS, and specialized neural network frameworks provide highly optimized implementations of fundamental operations that can serve as building blocks for custom inference engines. Effective integration with these libraries requires understanding their performance characteristics, memory management approaches, and optimization strategies to ensure seamless integration without introducing performance bottlenecks.
Custom integration strategies include developing specialized wrapper layers that can efficiently interface with multiple libraries, implementing adaptive algorithms that can select optimal implementations based on runtime characteristics, and creating hybrid approaches that combine multiple optimization strategies for maximum performance. These techniques enable the development of inference engines that can leverage the best aspects of different optimization approaches while maintaining flexibility and maintainability.
Deployment Optimization and Production Considerations
Production deployment of optimized machine learning inference systems requires consideration of additional factors beyond raw performance, including memory footprint, initialization time, and resource utilization characteristics. Deployment optimization focuses on minimizing startup latency, reducing memory requirements, and ensuring consistent performance across different operating conditions and hardware configurations.
Advanced deployment strategies include static linking to minimize runtime dependencies, custom initialization sequences that pre-warm caches and initialize data structures for optimal performance, and runtime adaptation mechanisms that can adjust optimization parameters based on observed performance characteristics. These approaches ensure that optimization benefits are maintained in production environments while providing the reliability and consistency required for mission-critical applications.
Emerging Technologies and Future Directions
The landscape of machine learning optimization continues to evolve rapidly with the introduction of new hardware architectures, programming models, and algorithmic approaches. Emerging technologies such as neuromorphic computing, quantum acceleration, and specialized AI chips present new opportunities and challenges for optimization experts. Understanding these trends and their implications for optimization strategy development is essential for maintaining competitive performance in rapidly evolving technology environments.
Future optimization approaches are likely to incorporate more sophisticated automation, machine learning-guided optimization parameter selection, and adaptive systems that can continuously optimize performance based on observed workload characteristics. The integration of these advanced techniques with traditional optimization approaches promises to unlock new levels of performance while reducing the complexity of optimization implementation and maintenance.
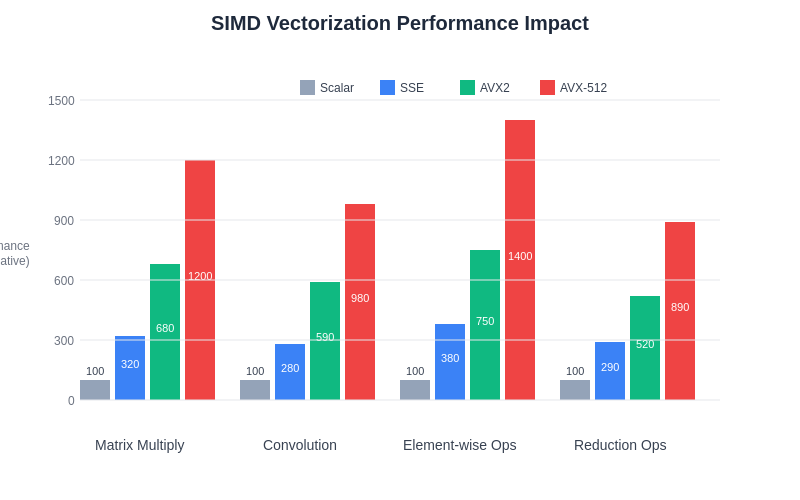
The performance impact of SIMD vectorization varies significantly depending on the specific computational patterns and data characteristics of different machine learning operations. Understanding these performance relationships enables developers to prioritize optimization efforts and select the most appropriate vectorization strategies for their specific use cases.
Quality Assurance and Validation Strategies
Optimization efforts must be balanced against the need to maintain numerical accuracy, algorithmic correctness, and system reliability. Comprehensive validation strategies ensure that performance improvements do not compromise the quality of inference results or introduce subtle bugs that could affect system behavior in production environments. These strategies include automated regression testing, numerical accuracy validation, and stress testing under various operating conditions.
Advanced validation approaches incorporate statistical methods for accuracy assessment, automated performance regression detection, and comprehensive error analysis to ensure that optimization modifications maintain acceptable quality levels. The systematic application of these validation techniques provides confidence that optimization improvements will deliver consistent benefits without introducing unacceptable risks or quality degradation.
The future of machine learning inference optimization lies in the continued refinement of these techniques combined with the development of new approaches that can adapt to evolving hardware architectures and algorithmic innovations. The developers who master these optimization principles will be positioned to create systems that can deliver exceptional performance while maintaining the reliability and accuracy required for production deployment in increasingly demanding application environments.
Disclaimer
This article is for informational and educational purposes only and does not constitute professional advice. The optimization techniques described should be carefully evaluated and tested for specific use cases and hardware configurations. Performance results may vary significantly depending on implementation details, hardware characteristics, and application requirements. Readers should conduct thorough testing and validation before implementing these techniques in production environments.