
The relentless pursuit of computational efficiency in artificial intelligence has led to a paradigm shift from traditional CPU-based processing to massively parallel GPU acceleration. CUDA (Compute Unified Device Architecture) programming represents the cornerstone of this transformation, enabling developers to harness the unprecedented computational power of Graphics Processing Units for custom AI algorithm development. This revolutionary approach has fundamentally altered the landscape of machine learning and deep learning applications, making previously computationally prohibitive algorithms both feasible and practical for real-world deployment.
Explore the latest AI development trends to understand how GPU acceleration is shaping the future of artificial intelligence and machine learning applications. The integration of CUDA programming into AI development workflows represents a critical skill for modern data scientists and machine learning engineers who seek to push the boundaries of what is computationally possible in artificial intelligence research and production systems.
Understanding CUDA Architecture and Parallel Computing Fundamentals
CUDA programming operates on a fundamentally different paradigm compared to traditional sequential CPU programming, leveraging the massively parallel architecture of modern GPUs to execute thousands of threads simultaneously. The GPU architecture consists of multiple Streaming Multiprocessors (SMs), each containing numerous CUDA cores that can execute arithmetic operations in parallel. This architectural design makes GPUs exceptionally well-suited for the matrix operations and vectorized computations that form the backbone of most AI algorithms.
The memory hierarchy in CUDA programming plays a crucial role in optimizing performance for AI applications. Global memory provides the largest storage capacity but with higher latency, while shared memory offers faster access times for data that needs to be accessed by multiple threads within the same block. Understanding how to effectively utilize different memory types, including constant memory for read-only data and texture memory for spatial locality, becomes essential for achieving optimal performance in custom AI algorithm implementations.
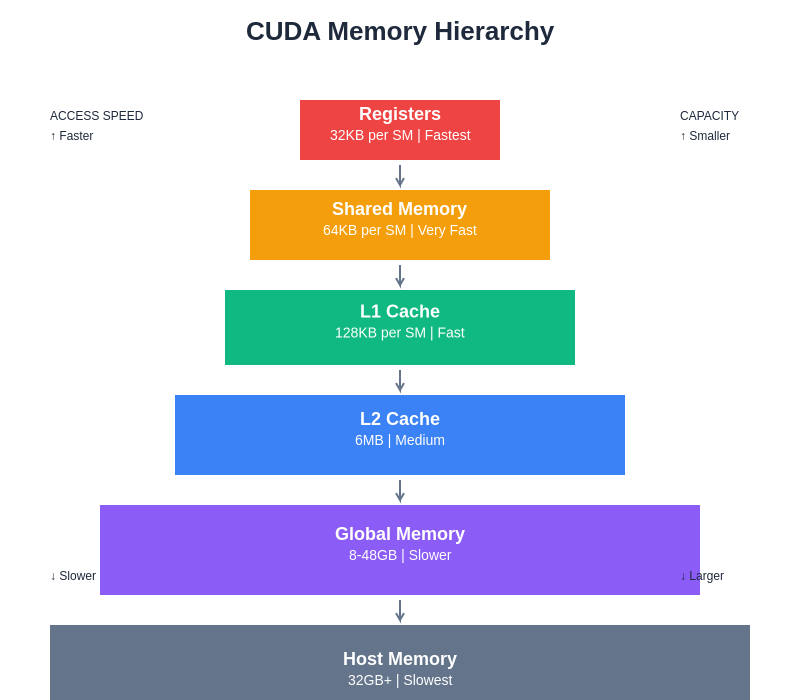
The CUDA memory hierarchy presents a trade-off between access speed and capacity, with registers providing the fastest access for thread-local data while global memory offers the largest capacity for dataset storage. Effective memory management strategies leverage this hierarchy to minimize access latency and maximize computational throughput.
Thread organization in CUDA follows a hierarchical structure consisting of grids, blocks, and individual threads. This organization allows developers to map AI algorithm components naturally to the parallel execution model, where each thread can handle individual data elements or contribute to collective computations. The ability to synchronize threads within blocks and coordinate memory access patterns enables the implementation of complex AI algorithms that require both parallel execution and coordinated data sharing.
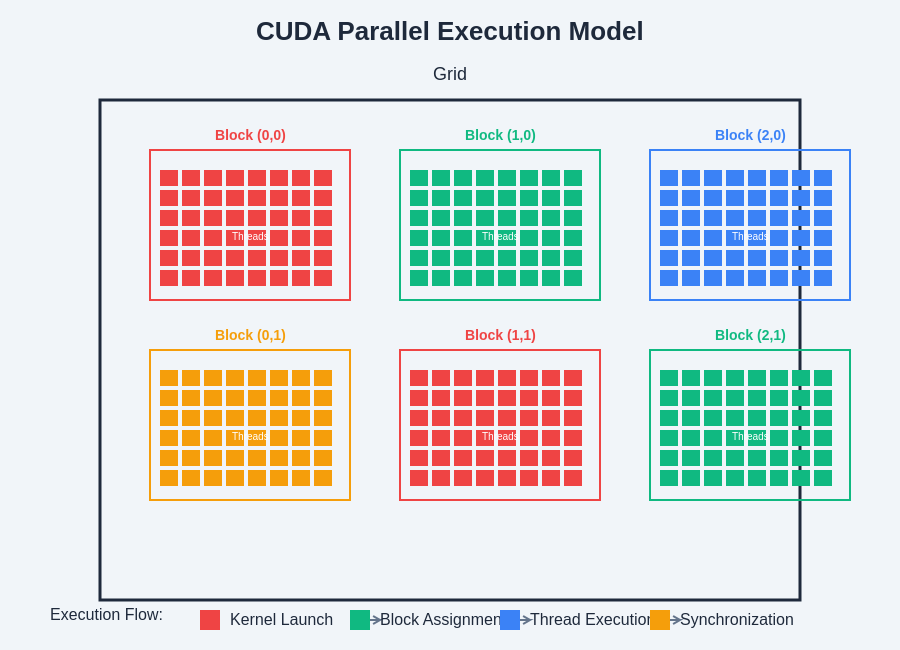
The hierarchical organization of CUDA threads provides a flexible framework for mapping computational tasks to GPU hardware, enabling efficient parallel execution of AI algorithms across thousands of processing cores simultaneously.
Implementing Matrix Operations and Linear Algebra Acceleration
Matrix operations form the computational foundation of virtually all AI algorithms, from basic linear regression to complex neural network architectures. CUDA programming excels at accelerating these operations through parallel execution of element-wise computations and optimized memory access patterns. Implementing efficient matrix multiplication using CUDA involves careful consideration of memory coalescing, shared memory utilization, and thread block organization to maximize throughput and minimize memory bandwidth limitations.
The implementation of custom CUDA kernels for matrix operations requires understanding of optimal thread mapping strategies and memory access patterns. Tiled matrix multiplication algorithms can achieve significant performance improvements by loading matrix tiles into shared memory and performing multiple computations on cached data. These optimizations become particularly important when dealing with large matrices commonly encountered in deep learning applications where even modest performance improvements can result in substantial reductions in training and inference times.
Leverage advanced AI tools like Claude for assistance in developing and optimizing CUDA implementations for complex AI algorithms. The combination of AI-assisted development and GPU acceleration creates powerful synergies that enable rapid prototyping and optimization of custom machine learning solutions.
Advanced linear algebra operations such as eigenvalue decomposition, singular value decomposition, and matrix factorizations can benefit significantly from CUDA acceleration when implemented with careful attention to numerical stability and parallel algorithm design. Libraries such as cuBLAS and cuSOLVER provide optimized implementations of common linear algebra operations, but custom algorithms often require bespoke CUDA implementations that can be tailored to specific problem requirements and data characteristics.
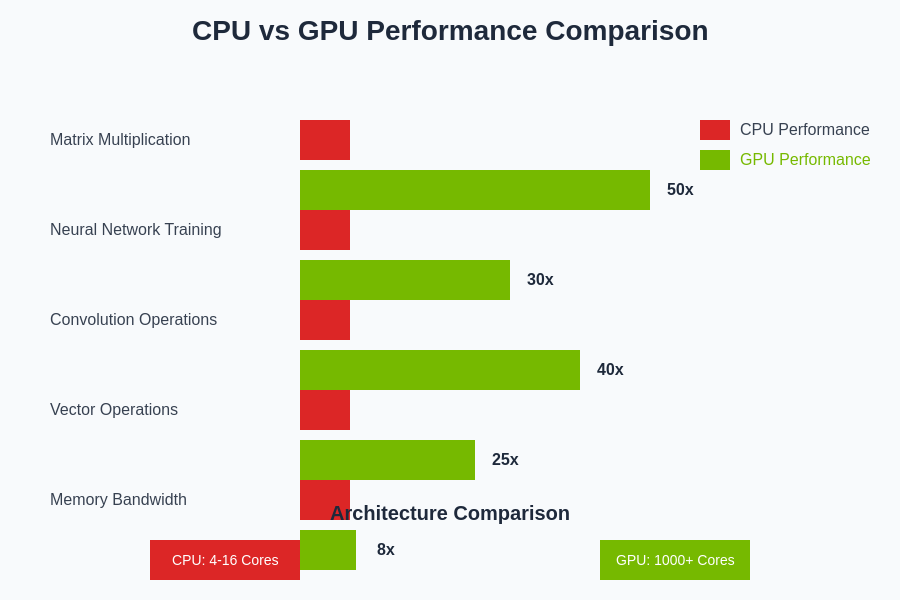
The performance advantages of GPU acceleration become particularly pronounced in computationally intensive AI operations, where the massive parallelism of modern GPUs can deliver order-of-magnitude improvements over traditional CPU implementations across various algorithm types and computational patterns.
Accelerating Neural Network Training and Inference
Neural network training presents unique challenges and opportunities for CUDA acceleration due to the iterative nature of gradient-based optimization algorithms and the complex computational graphs involved in backpropagation. Forward propagation in neural networks involves sequential matrix multiplications and activation function applications that can be efficiently parallelized across GPU cores. Each layer’s computations can be distributed across multiple thread blocks, with careful attention to memory management and inter-layer data dependencies.
Backpropagation algorithms require careful implementation of gradient computations and parameter updates that maintain numerical precision while maximizing parallel execution efficiency. The implementation of custom activation functions, loss functions, and regularization techniques in CUDA enables fine-tuned control over computational performance and memory utilization. Optimizing memory bandwidth utilization becomes critical when dealing with large parameter sets and batch processing requirements common in modern deep learning applications.
The implementation of custom training loops in CUDA allows for integration of advanced optimization techniques such as adaptive learning rates, momentum-based updates, and custom regularization schemes. Memory management strategies become particularly important when handling large datasets that exceed GPU memory capacity, requiring efficient data streaming and batch processing implementations that maintain high GPU utilization throughout the training process.
Optimizing Convolutional Neural Networks with CUDA
Convolutional Neural Networks present specific optimization opportunities due to their structured computational patterns and data locality characteristics. The convolution operation itself is inherently parallel, with each output element being computed independently through a series of multiply-accumulate operations. CUDA implementations can exploit this parallelism by assigning individual threads to output elements or input/output channels, depending on the specific optimization strategy and hardware characteristics.
Memory access patterns in CNN implementations require careful consideration of spatial locality and data reuse opportunities. Shared memory can be effectively utilized to cache frequently accessed input data, filter weights, and intermediate results, reducing global memory bandwidth requirements and improving overall computational efficiency. The implementation of efficient padding, stride, and dilation operations requires attention to boundary conditions and memory alignment considerations.
Advanced CNN architectures such as residual networks, dense networks, and attention mechanisms introduce additional complexity in CUDA implementations due to skip connections, concatenation operations, and dynamic computational graphs. Custom CUDA kernels can be developed to fuse multiple operations and reduce memory bandwidth requirements while maintaining the flexibility needed for complex network architectures.
Implementing Custom Loss Functions and Optimization Algorithms
Custom loss functions often require specialized CUDA implementations to achieve optimal performance, particularly when dealing with complex mathematical formulations or domain-specific requirements. The implementation of differentiable loss functions in CUDA involves careful attention to numerical stability, gradient computation accuracy, and parallel reduction operations for computing loss values across batch dimensions.
Advanced optimization algorithms such as Adam, RMSprop, and custom variants can benefit from CUDA acceleration through parallel parameter updates and momentum computation. The implementation of these algorithms requires careful management of optimizer state variables and efficient computation of adaptive learning rates. Memory optimization becomes crucial when dealing with large parameter sets where optimizer states can consume significant GPU memory resources.
Enhance your research capabilities with Perplexity to stay updated on the latest optimization techniques and CUDA programming best practices for AI algorithm development. The rapid evolution of optimization algorithms and GPU architectures requires continuous learning and adaptation of implementation strategies.
The integration of custom regularization techniques and constraint optimization methods into CUDA-accelerated training loops enables the development of specialized AI algorithms tailored to specific problem domains. These implementations often require careful balance between computational efficiency and algorithmic flexibility to accommodate evolving research requirements and production deployment constraints.
Memory Management and Performance Optimization Strategies
Effective memory management represents a critical aspect of successful CUDA programming for AI applications, requiring careful consideration of memory allocation patterns, data transfer optimization, and cache utilization strategies. Global memory allocation and deallocation operations can introduce significant overhead in iterative algorithms, making memory pool management and buffer reuse strategies essential for maintaining high performance throughout extended training or inference sessions.
Unified memory features in modern CUDA versions provide simplified programming models while maintaining performance optimization opportunities through careful attention to memory access patterns and data locality. The implementation of efficient data streaming mechanisms enables processing of datasets that exceed available GPU memory while maintaining high computational throughput through overlapped computation and data transfer operations.
Memory bandwidth optimization requires understanding of coalesced memory access patterns and alignment requirements that maximize throughput of memory operations. The implementation of efficient data structures and memory layouts can significantly impact performance, particularly in algorithms that require frequent memory access or data reorganization operations.
Advanced Parallel Computing Patterns for AI Algorithms
Complex AI algorithms often require sophisticated parallel computing patterns that go beyond simple data parallelism to include task parallelism, pipeline parallelism, and hybrid approaches that combine multiple parallelization strategies. The implementation of parallel reduction operations, parallel prefix sums, and scattered memory access patterns enables the development of advanced algorithms such as tree-based learning methods, graph neural networks, and reinforcement learning algorithms.
Dynamic parallelism features in modern CUDA architectures enable the implementation of algorithms with data-dependent computation patterns and recursive structures. These capabilities open new possibilities for implementing adaptive algorithms and complex decision-making processes directly on the GPU without requiring frequent synchronization with CPU-based control logic.
The integration of multi-GPU programming techniques enables scaling of custom AI algorithms across multiple devices and nodes, requiring careful attention to load balancing, communication patterns, and synchronization mechanisms. These implementations often require hybrid approaches that combine CUDA programming with communication libraries such as NCCL for efficient multi-device coordination.
Debugging and Profiling CUDA-Accelerated AI Applications
Debugging CUDA applications requires specialized tools and techniques due to the parallel nature of GPU execution and the complexity of memory access patterns in AI algorithms. CUDA-GDB provides debugging capabilities for GPU kernels, while tools such as cuda-memcheck help identify memory access violations and race conditions that can be difficult to detect through traditional debugging methods.
Performance profiling of CUDA applications involves analysis of multiple metrics including kernel execution times, memory bandwidth utilization, occupancy levels, and instruction throughput. NVIDIA Nsight tools provide comprehensive profiling capabilities that enable identification of performance bottlenecks and optimization opportunities in custom AI algorithm implementations.
The implementation of effective testing strategies for CUDA-accelerated AI algorithms requires careful consideration of numerical precision, race condition detection, and validation against reference implementations. Automated testing frameworks can be developed to verify correctness across different input datasets and parameter configurations while monitoring performance metrics and resource utilization.
Integration with Deep Learning Frameworks and Libraries
Modern deep learning frameworks such as PyTorch, TensorFlow, and JAX provide mechanisms for integrating custom CUDA kernels and operations into existing neural network architectures. The implementation of custom CUDA extensions enables seamless integration of specialized algorithms while maintaining compatibility with automatic differentiation systems and distributed training capabilities.
The development of efficient data loading and preprocessing pipelines using CUDA can significantly improve overall training performance by reducing data transfer overhead and enabling concurrent execution of data preparation and model computation tasks. These implementations often require careful coordination between CPU-based data loading operations and GPU-based preprocessing kernels.
Library integration strategies enable leveraging optimized implementations from cuDNN, cuBLAS, and other NVIDIA libraries while maintaining the flexibility to implement custom operations for specialized requirements. The balance between using pre-optimized libraries and developing custom implementations depends on specific performance requirements and algorithmic constraints.
Future Directions and Emerging Technologies
The evolution of GPU architectures and CUDA programming capabilities continues to create new opportunities for AI algorithm acceleration, with emerging features such as tensor cores, mixed-precision computing, and specialized AI instruction sets opening new possibilities for performance optimization. The integration of these advanced features into custom AI algorithm implementations requires understanding of their capabilities and limitations.
Quantum computing integration and neuromorphic computing approaches represent emerging areas where CUDA programming skills can be adapted to new computational paradigms. The development of hybrid classical-quantum algorithms and neuromorphic network implementations may benefit from GPU acceleration for classical components and interface operations.
The continued evolution of multi-instance GPU capabilities and container-based deployment strategies creates new opportunities for efficient resource utilization and algorithm scaling. These developments require adaptation of CUDA programming practices to support dynamic resource allocation and multi-tenant deployment scenarios.
Conclusion and Best Practices
CUDA programming for custom AI algorithms represents a powerful approach to achieving significant performance improvements in machine learning and artificial intelligence applications. The successful implementation of GPU-accelerated AI algorithms requires careful attention to parallel algorithm design, memory optimization, and performance profiling while maintaining algorithmic correctness and numerical stability.
The development of maintainable and efficient CUDA code for AI applications benefits from systematic approaches to code organization, testing, and optimization that can accommodate evolving research requirements and production deployment needs. The integration of CUDA acceleration into existing development workflows requires careful consideration of tool integration, debugging strategies, and performance monitoring capabilities.
The future of AI algorithm development increasingly depends on the effective utilization of parallel computing resources and GPU acceleration capabilities. Mastering CUDA programming techniques provides a foundation for developing cutting-edge AI solutions that can scale to meet the computational demands of modern artificial intelligence research and applications.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. CUDA programming requires careful attention to hardware compatibility, driver requirements, and development environment setup. Readers should thoroughly test implementations and consider their specific performance and accuracy requirements when developing custom AI algorithms. The effectiveness of GPU acceleration may vary depending on algorithm characteristics, data sizes, and hardware configurations.