The exponential growth of artificial intelligence and machine learning applications has created an unprecedented demand for vast, high-quality training datasets that serve as the foundation for intelligent systems. These datasets represent not merely collections of data points but invaluable intellectual property that embodies months or years of careful curation, labeling, preprocessing, and refinement efforts. The loss of critical AI training datasets can result in catastrophic setbacks for organizations, potentially eliminating millions of dollars in investment and setting back product development timelines by years.
Explore the latest AI infrastructure trends to understand how leading organizations are implementing robust data protection strategies that safeguard their most valuable digital assets. The complexity of modern AI training datasets, combined with their immense value and the devastating consequences of data loss, makes comprehensive backup strategies an absolute necessity for any organization serious about artificial intelligence development.
The Critical Importance of AI Dataset Protection
The value of AI training datasets extends far beyond their storage requirements or computational processing costs. These datasets represent carefully curated collections of information that have been meticulously cleaned, labeled, validated, and optimized for specific machine learning tasks. The process of creating high-quality training datasets often involves substantial human effort, domain expertise, and significant financial investment that cannot be easily replicated or recovered if lost.
Modern AI training datasets frequently contain proprietary information, unique data collection methodologies, and specialized annotations that provide competitive advantages to organizations. The loss of such datasets not only impacts immediate project timelines but can fundamentally compromise an organization’s ability to maintain its competitive position in rapidly evolving markets. Furthermore, many AI datasets include irreplaceable historical data, unique experimental conditions, or rare event captures that cannot be reconstructed once lost.
The scale and complexity of contemporary AI datasets present unique challenges for traditional backup approaches. Petabyte-scale datasets with millions of individual files require specialized storage architectures, sophisticated versioning systems, and carefully orchestrated backup procedures that account for the unique characteristics of machine learning workflows and the critical importance of data integrity throughout the AI development lifecycle.
Understanding Dataset Characteristics and Backup Requirements
AI training datasets exhibit distinct characteristics that differentiate them from traditional enterprise data and require specialized backup considerations. These datasets often contain a mixture of structured and unstructured data types, including images, videos, audio files, text documents, sensor readings, and complex multi-dimensional arrays that must be preserved with complete fidelity to maintain their utility for machine learning applications.
The temporal aspects of AI datasets add another layer of complexity to backup strategies. Training datasets frequently undergo continuous evolution through data augmentation, annotation updates, quality improvements, and version iterations that must be carefully tracked and preserved. Each version of a dataset may represent a significant milestone in model development, and the ability to revert to previous versions or compare different iterations becomes crucial for debugging model performance issues and ensuring reproducibility of research results.
Enhance your AI development workflow with advanced tools like Claude that can help analyze dataset characteristics and recommend appropriate backup strategies tailored to specific use cases and organizational requirements. The interdependencies between datasets, model architectures, and training configurations create complex relationships that must be preserved through comprehensive backup systems that maintain both data integrity and contextual information.
Multi-Tier Storage Architecture for AI Datasets
Implementing an effective backup strategy for AI training datasets requires a carefully designed multi-tier storage architecture that balances performance requirements, cost considerations, and accessibility needs across different stages of the machine learning development lifecycle. The most frequently accessed datasets require high-performance storage solutions that enable rapid training iterations, while archived versions and disaster recovery copies can utilize more cost-effective storage tiers with longer retrieval times.
Hot storage tiers typically employ high-speed solid-state drives or specialized storage appliances that provide the low-latency access patterns required for intensive training workloads. These storage systems often incorporate advanced features such as snapshot capabilities, real-time replication, and integrated backup scheduling that streamline data protection procedures while minimizing impact on training performance. The hot tier serves as the primary working environment for active datasets and maintains multiple recent backup copies for immediate recovery scenarios.
Warm storage tiers bridge the gap between high-performance active storage and long-term archival systems by providing moderate access speeds at reduced costs for datasets that may be needed for model validation, comparison studies, or periodic retraining activities. These systems often leverage hybrid storage technologies that combine solid-state and traditional magnetic storage to optimize the balance between performance and cost-effectiveness while maintaining reasonable recovery time objectives.
Cold storage tiers focus on long-term preservation and disaster recovery scenarios where datasets may remain dormant for extended periods but must be preserved indefinitely for compliance, research continuity, or potential future utilization. These systems prioritize storage density and cost-efficiency over access speed, often employing technologies such as tape storage, optical media, or specialized cloud archive services that provide extremely durable storage at minimal ongoing costs.
Cloud-Based Backup Solutions and Hybrid Approaches
Cloud storage platforms have revolutionized AI dataset backup strategies by providing virtually unlimited scalability, geographic redundancy, and sophisticated data management capabilities that would be prohibitively expensive for most organizations to implement independently. Leading cloud providers offer specialized storage classes designed specifically for large-scale data analytics and machine learning workloads that provide optimized performance characteristics and cost structures for AI training datasets.
The implementation of cloud-based backup solutions requires careful consideration of data transfer costs, bandwidth limitations, and compliance requirements that may affect the feasibility of moving large datasets to and from cloud storage systems. Organizations must evaluate the total cost of ownership for cloud storage solutions, including not only storage fees but also data egress charges, API request costs, and potential bandwidth upgrades required to support efficient backup and recovery operations.
Hybrid backup approaches that combine on-premises storage with cloud-based backup destinations offer compelling advantages for organizations that require both high-performance local access and robust disaster recovery capabilities. These architectures enable organizations to maintain primary datasets on local high-performance storage while automatically replicating backup copies to geographically distributed cloud storage locations that provide protection against site-wide disasters and infrastructure failures.
The selection of appropriate cloud storage classes and replication strategies requires detailed analysis of dataset access patterns, recovery time objectives, and cost constraints that vary significantly across different AI development workflows. Intelligent tiering systems can automatically migrate dataset copies between different storage classes based on age, access frequency, and predefined policies that optimize storage costs while maintaining appropriate recovery capabilities.
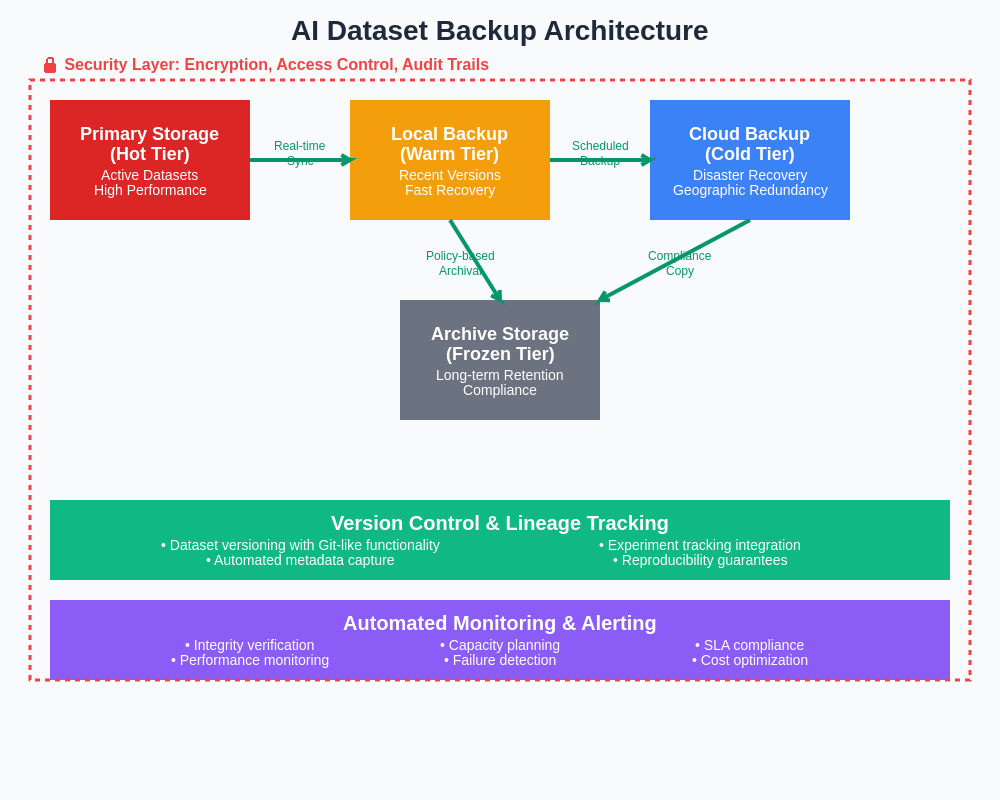
Modern AI dataset backup architectures integrate multiple storage tiers, cloud replication, and automated management systems to provide comprehensive protection while optimizing performance and cost-effectiveness. This multi-layered approach ensures that datasets remain accessible for active development while maintaining robust disaster recovery capabilities through geographically distributed backup copies.
Version Control and Dataset Lineage Management
The dynamic nature of AI development workflows necessitates sophisticated version control systems that can effectively manage the evolution of training datasets while preserving complete historical lineages and enabling precise reproducibility of experimental results. Traditional version control systems designed for source code management often prove inadequate for handling the scale and complexity of AI datasets that may contain millions of files and require specialized handling of large binary objects.
Dataset version control systems must capture not only the content changes within datasets but also the metadata, processing pipelines, and transformation histories that affect the final training data composition. This comprehensive tracking enables researchers and data scientists to understand exactly how datasets were created, modified, and processed at any point in time, which proves essential for debugging model performance issues and ensuring the reproducibility of scientific results.
The implementation of effective dataset lineage tracking requires integration with existing machine learning development tools and workflows to automatically capture version information, processing parameters, and dependency relationships without imposing significant overhead on researchers and data scientists. Modern dataset management platforms provide automated lineage tracking capabilities that can record detailed provenance information while seamlessly integrating with popular machine learning frameworks and development environments.
Branching and merging capabilities for datasets enable parallel development workflows where multiple researchers can work on different aspects of dataset improvement while maintaining the ability to integrate changes and resolve conflicts in a controlled manner. These collaborative features become particularly important for large-scale AI projects involving multiple teams working on different components of complex training pipelines.
Automated Backup Scheduling and Monitoring
The scale and complexity of modern AI training datasets make manual backup procedures impractical and error-prone, necessitating comprehensive automation systems that can reliably execute backup operations without human intervention while providing detailed monitoring and alerting capabilities for backup status and system health. Automated backup scheduling must account for the unique characteristics of AI workflows, including long-running training jobs that should not be interrupted and peak usage periods that may affect backup performance.
Intelligent backup scheduling systems analyze dataset usage patterns, training schedules, and system resource availability to optimize backup timing and minimize impact on active AI development activities. These systems can dynamically adjust backup windows based on real-time system utilization, automatically defer backup operations during critical training phases, and reschedule operations to avoid conflicts with high-priority computational workloads.
Discover advanced research and analysis capabilities with Perplexity to stay informed about emerging backup technologies and best practices that can enhance your AI dataset protection strategies. The integration of artificial intelligence technologies into backup management systems themselves enables predictive failure analysis, automated optimization of backup parameters, and intelligent resource allocation that improves backup reliability while reducing operational overhead.
Comprehensive monitoring systems provide real-time visibility into backup status, performance metrics, and potential issues that require attention before they escalate into critical failures. These monitoring platforms typically integrate with existing enterprise monitoring solutions and provide customizable alerting mechanisms that notify appropriate personnel of backup failures, performance degradation, or capacity planning requirements.
Data Integrity Verification and Corruption Detection
Ensuring the integrity of AI training datasets throughout the backup and recovery lifecycle requires sophisticated verification mechanisms that can detect subtle forms of data corruption that might not immediately affect system functionality but could gradually degrade model performance or introduce systematic biases into training processes. Traditional checksum-based integrity verification provides basic protection against obvious corruption but may not detect more sophisticated forms of data degradation that can occur during storage or transfer operations.
Advanced integrity verification systems employ multiple complementary approaches including cryptographic hashing, statistical analysis, and machine learning-based anomaly detection to identify potential data integrity issues across different types of dataset corruption. These systems can detect not only bit-level corruption but also semantic inconsistencies, metadata corruption, and systematic biases that might indicate underlying storage or transfer problems.
The implementation of continuous integrity monitoring enables early detection of data degradation issues before they propagate throughout backup copies and potentially compromise disaster recovery capabilities. Automated integrity verification should operate transparently during normal backup operations while providing detailed reporting on verification results and any detected anomalies that require investigation.
Dataset-specific integrity checks must account for the unique characteristics of different data types commonly found in AI training datasets, including specialized validation procedures for image data, audio files, time series data, and complex structured datasets that require domain-specific integrity verification approaches beyond generic file-level checksums.
Geographic Distribution and Disaster Recovery Planning
The critical importance of AI training datasets demands robust disaster recovery strategies that provide protection against a wide range of potential failure scenarios including site-wide disasters, regional infrastructure failures, and large-scale cybersecurity incidents that could compromise primary data storage systems. Geographic distribution of backup copies across multiple regions or continents provides essential protection against localized disasters while also improving data access performance for globally distributed AI development teams.
Disaster recovery planning for AI datasets must consider not only the technical aspects of data recovery but also the operational procedures, resource requirements, and time constraints associated with restoring large-scale datasets and resuming AI development activities after a significant disruption. Recovery time objectives and recovery point objectives must be carefully defined based on business requirements and the potential impact of extended downtime on AI development projects and production systems.
The complexity of modern AI training environments requires comprehensive disaster recovery testing procedures that validate not only the ability to restore datasets but also the functionality of associated infrastructure, software dependencies, and operational procedures required to resume normal AI development activities. Regular disaster recovery exercises help identify potential issues with recovery procedures and ensure that personnel are adequately trained to execute recovery operations under stress conditions.
Geographic distribution strategies must balance protection against regional disasters with practical considerations such as data transfer costs, regulatory compliance requirements, and the need to maintain reasonable recovery performance across different geographic regions. Multi-region backup architectures often employ intelligent data placement algorithms that optimize backup locations based on usage patterns, regulatory constraints, and disaster risk assessments.
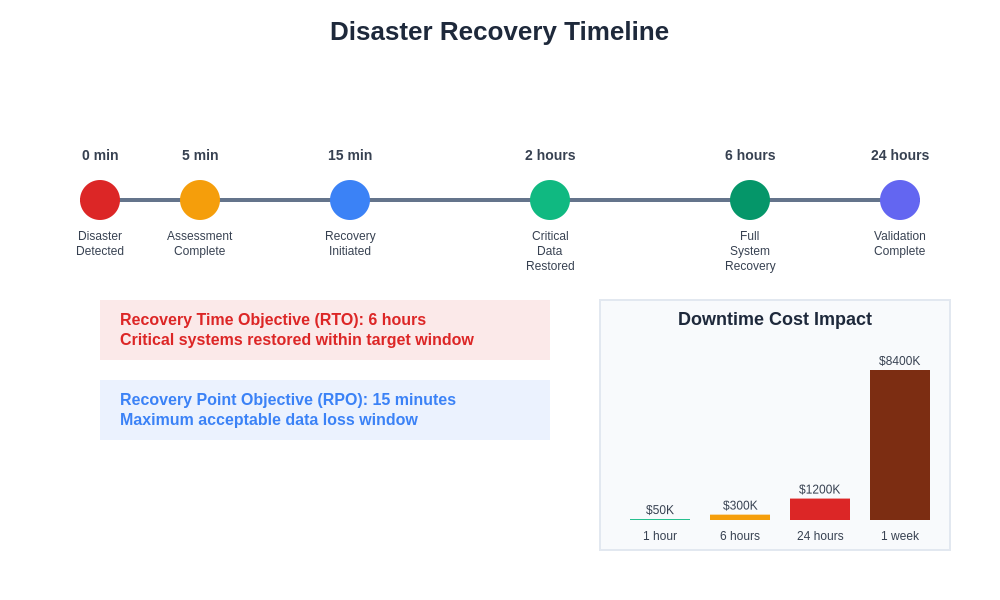
Comprehensive disaster recovery planning establishes clear timelines and procedures for different types of failure scenarios, ensuring that AI development teams can quickly resume operations with minimal data loss. The recovery process must account for dataset dependencies, infrastructure requirements, and validation procedures necessary to restore full functionality.
Security Considerations and Access Control
AI training datasets often contain sensitive information, proprietary algorithms, or valuable intellectual property that requires robust security measures throughout the backup and recovery lifecycle to prevent unauthorized access, industrial espionage, or compliance violations that could result in significant legal and financial consequences for organizations. Comprehensive security strategies must address threats at multiple levels including physical access to storage systems, network-based attacks on backup infrastructure, and insider threats from personnel with legitimate access to backup systems.
Encryption technologies play a crucial role in protecting AI datasets during storage and transit, requiring careful selection of encryption algorithms, key management strategies, and performance optimization approaches that maintain strong security while minimizing impact on backup and recovery performance. End-to-end encryption ensures that datasets remain protected throughout their journey from primary storage through backup systems to disaster recovery sites, even if intermediate storage or network infrastructure becomes compromised.
Access control systems for backup infrastructure must implement principle of least privilege approaches that limit personnel access to backup data based on legitimate business needs while maintaining detailed audit trails of all access activities. Role-based access control systems enable fine-grained permissions management that can restrict access to specific datasets, backup operations, or recovery procedures based on individual responsibilities and organizational requirements.
The implementation of comprehensive security monitoring for backup systems enables early detection of potential security incidents, unauthorized access attempts, or suspicious activities that might indicate compromise of backup infrastructure. Security monitoring systems should integrate with existing enterprise security operations centers and provide automated alerting capabilities that enable rapid response to potential threats.
Cost Optimization and Resource Planning
The substantial costs associated with backing up large-scale AI training datasets require careful resource planning and cost optimization strategies that balance protection requirements with budget constraints while ensuring that backup systems can scale effectively as dataset sizes and organizational AI initiatives continue to grow. Total cost of ownership calculations must consider not only storage costs but also bandwidth requirements, personnel time, infrastructure investments, and ongoing operational expenses associated with comprehensive backup strategies.
Intelligent data lifecycle management policies can significantly reduce backup storage costs by automatically identifying datasets that no longer require high-performance backup protection and migrating them to more cost-effective storage tiers based on age, access patterns, and business value assessments. These policies must be carefully designed to avoid inadvertently compromising protection for datasets that may become valuable again in the future or are required for regulatory compliance purposes.
Compression and deduplication technologies can substantially reduce storage requirements for AI dataset backups, particularly for datasets that contain repetitive patterns or similar content across multiple versions. However, the implementation of these technologies must carefully consider the trade-offs between storage savings and recovery performance, as highly compressed data may require significant computational resources and time to decompress during recovery operations.
Capacity planning for backup systems must account for the rapid growth of AI dataset sizes, the increasing frequency of backup operations, and the expanding retention requirements that result from growing AI development activities and evolving compliance obligations. Predictive capacity planning models can help organizations anticipate future storage requirements and make informed investment decisions that avoid costly emergency capacity upgrades.
Integration with Machine Learning Development Workflows
Effective backup strategies for AI training datasets must seamlessly integrate with existing machine learning development workflows to avoid disrupting researcher productivity while ensuring that backup operations occur consistently and reliably throughout the AI development lifecycle. Integration touchpoints include dataset creation pipelines, model training frameworks, experiment tracking systems, and collaborative development platforms that researchers use for their daily activities.
Automated backup integration with popular machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn enables transparent backup operations that occur automatically during dataset creation, preprocessing, and training activities without requiring manual intervention from researchers. These integrations can leverage framework APIs and event hooks to trigger backup operations at appropriate points in the development workflow while capturing relevant metadata and context information.
Experiment tracking platforms provide natural integration points for backup systems by automatically identifying valuable datasets associated with successful experiments and ensuring that these datasets receive appropriate backup protection. Integration with experiment tracking also enables automated retention policy management that can extend backup retention periods for datasets associated with particularly successful or important experiments.
Collaborative development environments require backup systems that can handle concurrent access patterns, version conflicts, and distributed development scenarios where multiple researchers may be modifying datasets simultaneously across different geographic locations. Version control integration ensures that backup systems maintain consistency with collaborative development workflows while preserving complete change histories and enabling conflict resolution.
Emerging Technologies and Future Considerations
The rapidly evolving landscape of AI and machine learning technologies continues to introduce new challenges and opportunities for dataset backup strategies, requiring organizations to stay informed about emerging trends and prepare for future requirements that may significantly impact existing backup architectures and procedures. Advances in storage technologies, networking capabilities, and data management platforms promise to enable more efficient and cost-effective backup solutions while introducing new complexity and integration requirements.
Edge AI deployments and distributed machine learning architectures create new backup requirements for datasets that may be processed across multiple geographic locations with varying connectivity, storage capabilities, and operational constraints. These distributed scenarios require backup strategies that can operate effectively in bandwidth-constrained environments while maintaining consistency and synchronization across multiple sites.
The increasing importance of real-time AI applications and streaming data processing introduces dynamic backup requirements for datasets that are continuously updated and modified during normal operations. Traditional batch-oriented backup approaches may prove inadequate for these scenarios, requiring the development of incremental backup strategies that can capture changes in near real-time while maintaining system performance and data consistency.
Quantum computing advances and neuromorphic computing architectures may introduce entirely new categories of AI datasets with unique storage requirements, processing characteristics, and backup challenges that current backup systems are not designed to address. Organizations must maintain awareness of these emerging technologies and their potential impact on data management requirements to ensure that backup strategies remain effective as AI technologies continue to evolve.
The integration of blockchain and distributed ledger technologies into AI development workflows may provide new approaches to dataset integrity verification, provenance tracking, and distributed backup management that could fundamentally change how organizations approach data protection for AI training datasets. These technologies offer potential solutions to challenges such as ensuring dataset authenticity, preventing unauthorized modifications, and creating immutable records of dataset lineage that could enhance trust and reproducibility in AI systems.

Strategic investment in comprehensive backup systems delivers substantial returns through reduced risk exposure, improved operational efficiency, and enhanced ability to recover from various failure scenarios. The analysis demonstrates that robust backup strategies provide significant value despite their initial implementation costs.
Regulatory Compliance and Legal Considerations
The increasing regulatory scrutiny of AI systems and data management practices introduces complex compliance requirements that significantly impact backup strategies for AI training datasets, particularly in regulated industries such as healthcare, financial services, and automotive applications where data protection and system reliability are subject to strict legal oversight. Organizations must ensure that backup systems meet applicable regulatory requirements while maintaining the flexibility and performance characteristics required for effective AI development.
Data residency requirements in various jurisdictions may restrict where backup copies of AI training datasets can be stored, requiring careful planning of geographic distribution strategies that balance disaster recovery protection with regulatory compliance obligations. These requirements often vary significantly between different types of data and different regulatory frameworks, creating complex compliance matrices that must be carefully managed throughout the backup lifecycle.
Privacy regulations such as GDPR, CCPA, and sector-specific privacy requirements introduce additional complexity for backup systems that must be capable of locating, modifying, or deleting specific individual records within large-scale AI datasets in response to privacy rights requests. The implementation of privacy-compliant backup systems requires sophisticated indexing and search capabilities that can efficiently locate individual records across multiple backup copies and storage tiers.
Audit trail requirements for regulated AI applications necessitate comprehensive logging and documentation of all backup and recovery operations, including detailed records of who accessed what data, when operations were performed, and what changes were made to datasets or backup configurations. These audit capabilities must be designed to meet the specific requirements of applicable regulatory frameworks while providing the detailed forensic capabilities that may be required during regulatory investigations.
Conclusion and Best Practice Recommendations
The protection of critical AI training datasets through comprehensive backup strategies represents one of the most important infrastructure investments that organizations can make to safeguard their artificial intelligence development efforts and ensure business continuity in an increasingly AI-dependent world. The unique characteristics of AI datasets, including their enormous scale, complex interdependencies, and irreplaceable value, demand specialized approaches that go far beyond traditional enterprise backup solutions.
Organizations embarking on comprehensive AI dataset protection initiatives should begin with thorough assessments of their existing datasets, development workflows, and risk tolerance levels to develop backup strategies that are appropriately tailored to their specific requirements and constraints. The implementation of effective backup systems requires significant planning, investment, and ongoing operational commitment, but the potential consequences of inadequate data protection far outweigh the costs of comprehensive backup infrastructure.
The rapidly evolving nature of AI technologies and the increasing scale of training datasets ensure that backup strategies must remain flexible and adaptable to accommodate future requirements and emerging technologies. Organizations should establish regular review cycles for their backup strategies and maintain awareness of emerging technologies, regulatory changes, and industry best practices that may impact their data protection requirements.
Success in protecting AI training datasets requires not only robust technical implementations but also comprehensive operational procedures, well-trained personnel, and organizational commitment to data protection as a critical business priority that deserves appropriate investment and attention throughout the AI development lifecycle.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of data backup technologies and best practices for AI dataset management. Readers should conduct their own research and consider their specific requirements, regulatory obligations, and risk tolerance when implementing backup strategies for AI training datasets. The effectiveness of backup strategies may vary depending on specific use cases, organizational requirements, and technological constraints.