The foundation of successful artificial intelligence implementations lies not merely in sophisticated algorithms or powerful computing resources, but fundamentally in the strategic design and implementation of data storage architectures that can efficiently support the diverse and demanding requirements of modern machine learning workloads. As organizations increasingly recognize data as their most valuable asset, the choice between data lakes and data warehouses has become a critical decision that can determine the success or failure of AI initiatives across industries and application domains.
Explore the latest AI trends and technologies that are reshaping how organizations approach data storage and processing for artificial intelligence applications. The evolution of data storage architectures has accelerated dramatically in recent years, driven by the exponential growth of data volumes, the increasing complexity of AI workloads, and the need for real-time processing capabilities that can support everything from predictive analytics to large language model training and deployment.
Understanding Data Storage Architectures in the AI Era
The landscape of data storage has evolved significantly from the traditional relational database systems that dominated enterprise computing for decades. Modern AI applications require storage solutions that can accommodate massive volumes of structured and unstructured data, support rapid ingestion from diverse sources, enable flexible schema evolution, and provide the performance characteristics necessary for both training complex machine learning models and serving real-time predictions to end users and applications.
Data lakes and data warehouses represent two fundamentally different approaches to organizing and storing data for analytical and AI workloads. While both serve the ultimate goal of enabling data-driven decision making and supporting artificial intelligence applications, they differ dramatically in their architectural philosophies, implementation strategies, performance characteristics, and optimal use cases. Understanding these differences is crucial for organizations seeking to build robust, scalable, and cost-effective data infrastructures that can support current AI initiatives while remaining flexible enough to adapt to future technological developments and business requirements.
The choice between these architectures is rarely binary in practice, as many successful AI implementations leverage hybrid approaches that combine the strengths of both data lakes and data warehouses to create comprehensive data ecosystems that can support diverse analytical and machine learning workloads. However, understanding the core principles and characteristics of each approach provides the foundation for making informed decisions about data architecture that align with specific organizational needs, technical requirements, and strategic objectives.
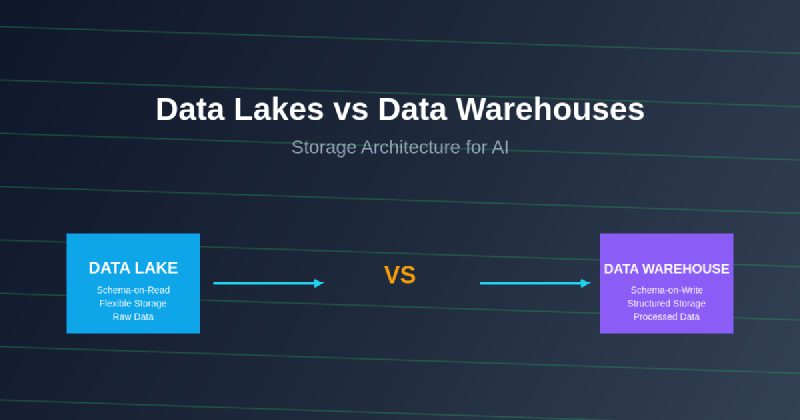
Data Lakes: Flexible Storage for Diverse AI Workloads
Data lakes represent a paradigm shift toward storing data in its raw, native format without imposing rigid structural constraints or requiring extensive upfront schema design. This approach, often described as “schema-on-read,” enables organizations to capture and retain vast amounts of data from diverse sources including structured databases, semi-structured logs and APIs, unstructured text documents, images, videos, and streaming sensor data that are increasingly common in AI applications.
The fundamental philosophy underlying data lake architecture is that the value of data cannot always be predicted at the time of collection, and that imposing premature structural constraints may limit future analytical possibilities and AI use cases. This approach has proven particularly valuable for machine learning applications, where the ability to experiment with different data combinations, feature engineering approaches, and model architectures often requires access to raw data that can be processed and transformed in multiple ways depending on specific analytical objectives.
Enhance your AI development with Claude’s advanced capabilities for data analysis, architecture design, and machine learning implementation across diverse data storage platforms. The flexibility of data lakes extends beyond simple storage to encompass the entire data processing pipeline, enabling data scientists and machine learning engineers to iterate rapidly on data preparation, feature extraction, and model development workflows without being constrained by rigid data structures or predetermined analytical frameworks.
Modern data lake implementations leverage distributed storage systems and cloud-native architectures that can scale horizontally to accommodate petabyte-scale datasets while providing cost-effective storage for infrequently accessed historical data. This scalability is particularly important for AI applications that may require access to years or decades of historical data for training purposes, or that generate massive amounts of intermediate data during model training and validation processes.
Data Warehouses: Structured Performance for AI Analytics
Data warehouses represent a more traditional approach to analytical data storage, emphasizing structured organization, optimized query performance, and reliable data consistency for business intelligence and analytical applications. The data warehouse approach involves extensive upfront data modeling, transformation, and quality assurance processes that ensure data is clean, consistent, and optimized for specific types of analytical queries and reporting requirements.
The strength of data warehouses lies in their ability to provide predictable, high-performance access to well-structured data that has been carefully curated and optimized for analytical workloads. This approach is particularly valuable for AI applications that require consistent, reliable access to high-quality data, such as financial forecasting models, customer segmentation algorithms, or operational optimization systems that must deliver reliable results for business-critical decision making.
Modern cloud-based data warehouses have evolved significantly from their traditional on-premises predecessors, incorporating advanced features such as automatic scaling, columnar storage optimization, advanced compression techniques, and sophisticated query optimization engines that can efficiently process complex analytical queries across massive datasets. These improvements have made data warehouses increasingly viable for supporting certain types of machine learning workloads, particularly those that involve structured data and require consistent performance characteristics.
The data warehouse approach excels in scenarios where data quality, consistency, and performance are paramount, and where the analytical requirements are well-understood and relatively stable over time. For AI applications that operate on carefully curated datasets and require predictable query performance, data warehouses can provide significant advantages in terms of reliability, performance optimization, and operational simplicity.
Performance Characteristics and Scalability Considerations
The performance characteristics of data lakes and data warehouses differ significantly across multiple dimensions that are critical for AI applications. Data lakes typically excel in scenarios requiring massive data ingestion rates, flexible data processing patterns, and cost-effective storage of diverse data types, while data warehouses optimize for consistent query performance, data quality assurance, and predictable resource utilization patterns that support mission-critical analytical workloads.
Storage scalability represents one of the most significant differentiators between these approaches. Data lakes can typically scale storage capacity almost indefinitely at relatively low cost, particularly when implemented using cloud-based object storage systems that can accommodate petabytes of data with minimal management overhead. This scalability is crucial for AI applications that generate or consume massive amounts of data, such as computer vision systems processing millions of images, natural language processing applications analyzing vast text corpora, or IoT analytics platforms ingesting streaming sensor data from thousands of devices.
Query performance characteristics vary significantly depending on the specific workload and implementation details. Data warehouses generally provide more predictable and optimized performance for well-defined analytical queries, particularly those involving complex joins, aggregations, and filtering operations across structured datasets. However, data lakes can achieve superior performance for certain types of AI workloads, particularly those involving large-scale parallel processing, feature extraction from unstructured data, or exploratory data analysis that requires flexible access patterns.
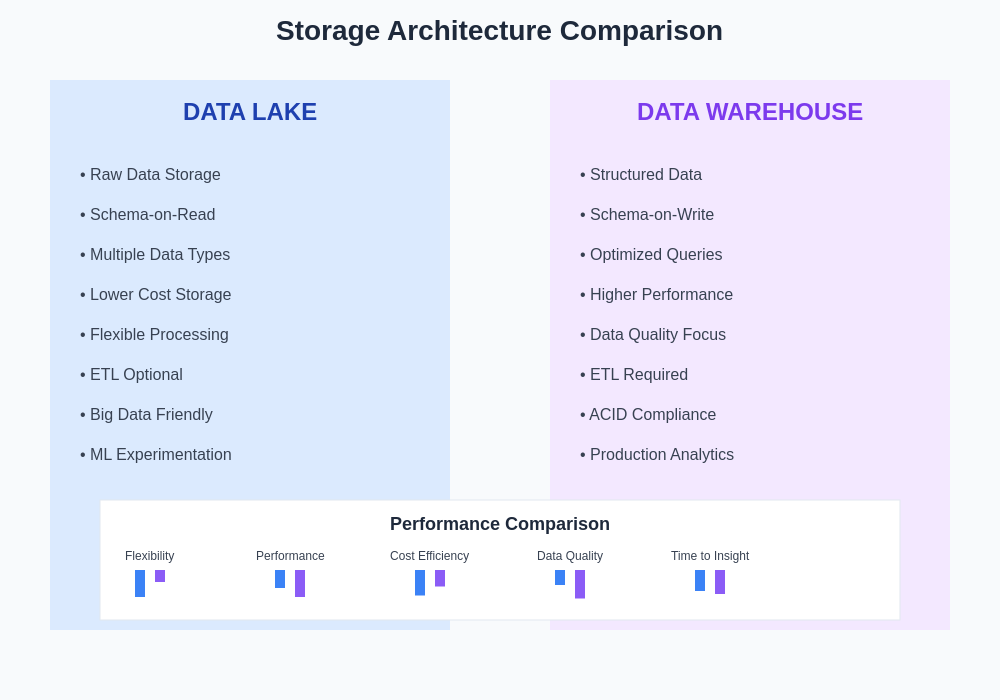
The architectural differences between data lakes and data warehouses create distinct performance profiles that align with different types of AI workloads and organizational requirements. Understanding these performance characteristics is essential for making informed decisions about data storage architecture that will support both current AI initiatives and future scalability requirements.
Cost Optimization Strategies for AI Data Storage
Cost considerations play a crucial role in data storage architecture decisions, particularly for organizations implementing large-scale AI systems that may require storing and processing massive amounts of data over extended periods. Data lakes typically offer significant cost advantages for storage-intensive applications, as they can leverage low-cost object storage systems and avoid the overhead associated with maintaining complex indexing and optimization structures required by traditional data warehouses.
The economic model of data lakes aligns well with the experimental and iterative nature of many AI development processes, where teams may need to store large amounts of raw data for extended periods while exploring different analytical approaches and model architectures. The ability to store data cheaply and scale storage capacity as needed without significant upfront investments makes data lakes particularly attractive for organizations with uncertain or rapidly evolving AI requirements.
Data warehouses, while typically more expensive for raw storage capacity, can provide superior cost efficiency for workloads that require frequent access to well-structured data and can benefit from query optimization and caching mechanisms. The higher upfront costs associated with data modeling, ETL processes, and system optimization can be justified when they enable more efficient processing of business-critical AI workloads and reduce ongoing operational costs through improved performance and resource utilization.
Hybrid approaches that combine data lakes and data warehouses can optimize costs by storing raw data cost-effectively in data lakes while maintaining frequently accessed, well-structured data in optimized data warehouses. This approach enables organizations to balance storage costs with performance requirements while maintaining the flexibility to adapt to changing AI workload requirements over time.
Security and Governance in AI Data Architectures
Data security and governance requirements have become increasingly critical considerations for AI data storage architectures, particularly as organizations deal with sensitive personal information, proprietary business data, and regulatory compliance requirements that vary across industries and geographical regions. Both data lakes and data warehouses can implement robust security measures, but they approach security and governance from different architectural perspectives.
Data lakes require comprehensive security frameworks that can manage access control across diverse data types and formats while maintaining the flexibility that makes data lakes valuable for AI applications. This typically involves implementing fine-grained access controls, data encryption at rest and in transit, audit logging capabilities, and data lineage tracking systems that can monitor how data flows through complex processing pipelines and machine learning workflows.
Data warehouses traditionally implement security through well-established database security mechanisms including role-based access control, data masking and anonymization capabilities, and comprehensive audit trails that track data access and modification patterns. The structured nature of data warehouse environments can make it easier to implement consistent security policies and ensure compliance with regulatory requirements, particularly for organizations operating in highly regulated industries such as healthcare, finance, or government sectors.
Leverage Perplexity’s research capabilities to stay current with evolving data security regulations and best practices for AI data governance across different storage architectures. The regulatory landscape for AI and data privacy continues to evolve rapidly, requiring organizations to maintain flexible data governance frameworks that can adapt to changing requirements while supporting ongoing AI development and deployment activities.
Integration with Machine Learning Pipelines
The integration of data storage architectures with machine learning development and deployment pipelines represents a critical factor in determining the overall effectiveness and efficiency of AI systems. Data lakes and data warehouses each offer distinct advantages and challenges when it comes to supporting the complex workflows involved in developing, training, validating, and deploying machine learning models at scale.
Data lakes excel in supporting exploratory data analysis and experimental machine learning workflows where data scientists need flexible access to raw data for feature engineering, model prototyping, and iterative refinement processes. The ability to store and access diverse data types without rigid structural constraints enables rapid experimentation with different data combinations and processing approaches that are essential for developing innovative AI solutions.
The schema-on-read approach of data lakes aligns particularly well with modern machine learning frameworks and tools that can dynamically interpret and process data in various formats. This flexibility enables data science teams to iterate quickly on feature engineering pipelines, experiment with different data preprocessing approaches, and adapt their models to incorporate new data sources as they become available.
Data warehouses provide advantages for production machine learning workflows that require consistent, reliable access to well-curated datasets with predictable performance characteristics. The structured nature of data warehouse environments makes it easier to implement automated data quality checks, maintain data lineage documentation, and ensure that machine learning models have access to consistent, high-quality input data throughout their operational lifecycle.
Real-Time Processing and Streaming Data Integration
The ability to process streaming data and support real-time AI applications has become increasingly important as organizations seek to implement AI systems that can respond dynamically to changing conditions and provide immediate insights or recommendations. Both data lakes and data warehouses have evolved to support real-time data processing, but they approach streaming data integration from different architectural perspectives.
Modern data lake architectures can efficiently handle high-volume streaming data ingestion through distributed processing frameworks that can scale horizontally to accommodate massive data rates while maintaining low latency for downstream processing. This capability is particularly valuable for AI applications such as fraud detection systems, recommendation engines, or IoT analytics platforms that must process streaming data in real-time to provide timely insights and responses.
Data warehouses have incorporated streaming capabilities through various approaches including change data capture mechanisms, real-time ETL pipelines, and in-memory processing capabilities that can provide low-latency access to freshly ingested data. While traditionally optimized for batch processing workflows, modern cloud-based data warehouses increasingly support hybrid batch and streaming architectures that can accommodate diverse AI workload requirements.
The choice between data lake and data warehouse approaches for streaming data often depends on the specific latency requirements, data volume characteristics, and processing complexity of the AI applications being supported. Organizations implementing real-time AI systems may benefit from hybrid architectures that leverage the strengths of both approaches to optimize for different aspects of their streaming data requirements.
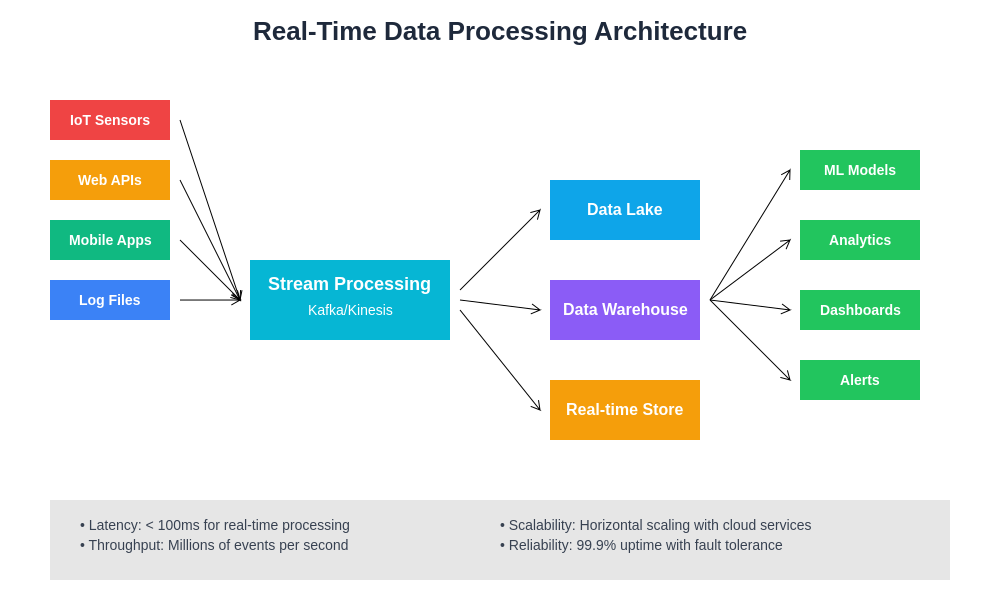
The integration of streaming data processing capabilities with AI storage architectures continues to evolve as organizations seek to implement more responsive and adaptive AI systems that can leverage real-time data for improved decision making and user experiences.
Cloud-Native Considerations and Multi-Cloud Strategies
The adoption of cloud-native data storage architectures has fundamentally transformed how organizations approach data lakes and data warehouses for AI applications. Cloud platforms provide managed services that can significantly reduce the operational complexity associated with implementing and maintaining large-scale data storage systems while providing virtually unlimited scalability and access to advanced AI and machine learning services.
Cloud-native data lakes leverage object storage services, serverless computing platforms, and managed data processing services that can automatically scale to accommodate varying workload demands while optimizing costs through dynamic resource allocation. This approach enables organizations to implement sophisticated AI data pipelines without the significant upfront infrastructure investments and ongoing operational overhead associated with traditional on-premises systems.
Cloud data warehouses offer fully managed services that provide enterprise-grade performance, reliability, and security while eliminating the need for organizations to manage complex database infrastructure. These services include automatic scaling, backup and disaster recovery, security management, and integration with cloud-based AI and machine learning platforms that can accelerate AI development and deployment processes.
Multi-cloud strategies are becoming increasingly common as organizations seek to avoid vendor lock-in, optimize costs across different cloud providers, and leverage best-of-breed services for different aspects of their AI data architecture. Implementing effective multi-cloud data strategies requires careful consideration of data movement costs, security implications, and integration complexity while maintaining the flexibility to adapt to changing business requirements and technological developments.
Future Trends and Emerging Technologies
The landscape of data storage architectures for AI continues to evolve rapidly as new technologies emerge and existing solutions mature to address the growing demands of artificial intelligence applications. Several key trends are shaping the future direction of data lakes, data warehouses, and hybrid architectures that combine elements of both approaches.
The convergence of data lake and data warehouse capabilities is leading to the emergence of “data lakehouses” that attempt to provide the flexibility and cost-effectiveness of data lakes while incorporating the performance optimization and data quality features traditionally associated with data warehouses. This hybrid approach aims to eliminate the need for organizations to choose between these architectures by providing unified platforms that can support diverse AI workloads with optimized performance characteristics.
Advances in storage technologies, including persistent memory systems, intelligent caching mechanisms, and adaptive data tiering solutions, are improving the performance characteristics of both data lakes and data warehouses while reducing costs and operational complexity. These technological improvements are making it possible to support increasingly demanding AI workloads with better price-performance ratios and more predictable resource utilization patterns.
The integration of artificial intelligence into data storage systems themselves is creating opportunities for intelligent data management, automated optimization, and predictive resource scaling that can improve the efficiency and effectiveness of AI data architectures. These AI-powered data management capabilities promise to reduce operational overhead while improving system performance and reliability for AI workloads.
Strategic Decision Framework for AI Data Architecture
Selecting the optimal data storage architecture for AI applications requires a comprehensive evaluation framework that considers multiple factors including data characteristics, workload requirements, performance objectives, cost constraints, security requirements, and long-term strategic goals. Organizations must balance immediate needs with future flexibility while ensuring that their chosen architecture can scale to support growing AI initiatives and evolving business requirements.
Data characteristics play a fundamental role in architecture selection, including data volume, variety, velocity, and veracity requirements that determine the storage and processing capabilities needed to support AI workloads effectively. Organizations dealing primarily with structured data and well-defined analytical requirements may find data warehouses more suitable, while those working with diverse, unstructured data sources may benefit from the flexibility of data lake architectures.
Workload patterns and performance requirements must be carefully analyzed to ensure that the chosen architecture can support both current AI applications and anticipated future needs. This includes consideration of query patterns, data access frequencies, latency requirements, and scalability projections that will influence the long-term effectiveness of the data storage solution.
Organizational factors including technical expertise, operational capabilities, budget constraints, and strategic priorities must also be considered when selecting data storage architectures. The success of any data architecture depends not only on its technical capabilities but also on the organization’s ability to implement, maintain, and evolve the system over time to support changing AI requirements and business objectives.
The decision between data lakes and data warehouses for AI applications is ultimately about aligning storage architecture capabilities with specific organizational needs, technical requirements, and strategic objectives while maintaining the flexibility to adapt to future developments in artificial intelligence and data management technologies. Organizations that carefully evaluate these factors and select appropriate architectures will be better positioned to leverage their data assets for competitive advantage and innovation in the AI-driven economy.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of data storage technologies and their applications in AI systems. Readers should conduct their own research and consider their specific requirements when implementing data storage architectures. The effectiveness and suitability of different approaches may vary depending on specific use cases, organizational constraints, and technological requirements.