
Data lineage has emerged as a fundamental pillar of modern artificial intelligence and machine learning operations, providing the critical foundation for understanding how data flows through complex ML pipelines from source to prediction. In an era where AI systems increasingly influence business decisions, regulatory compliance, and operational outcomes, the ability to trace data transformations, understand model dependencies, and maintain comprehensive audit trails has become not just beneficial but essential for successful AI implementations.
Stay updated with the latest AI infrastructure trends to understand how data lineage tools and techniques are evolving to meet the demands of increasingly sophisticated machine learning systems. The complexity of modern AI architectures, combined with stringent regulatory requirements and the need for explainable AI, has made data lineage tracking a mission-critical component of any serious machine learning deployment strategy.
Understanding Data Lineage in AI Context
Data lineage in artificial intelligence represents the comprehensive documentation and tracking of data as it moves through various stages of the machine learning lifecycle, from initial data collection and preprocessing through feature engineering, model training, validation, and eventual deployment. This end-to-end visibility enables organizations to understand not only where their data comes from and where it goes, but also how it transforms at each stage, which processes touch it, and what dependencies exist between different components of their ML infrastructure.
The significance of data lineage extends far beyond simple documentation. In machine learning contexts, data lineage serves as the foundation for model reproducibility, enabling data scientists and ML engineers to recreate specific model versions, understand the impact of data changes on model performance, and diagnose issues when models begin to drift or perform poorly in production. This traceability becomes particularly crucial when dealing with complex ensemble models, multi-stage pipelines, or distributed training processes where understanding the complete data flow can mean the difference between successful troubleshooting and costly production failures.
The Critical Role of Data Tracking in ML Operations
Modern machine learning operations depend on sophisticated data tracking mechanisms that provide visibility into every aspect of the data processing pipeline. Unlike traditional software applications where code changes are the primary concern, ML systems must contend with the reality that both code and data can change, and data changes often have more profound impacts on system behavior than code modifications. This dual nature of ML systems makes comprehensive data tracking not just useful but absolutely essential for maintaining system reliability and performance.
The operational benefits of robust data tracking extend across multiple dimensions of ML system management. Performance monitoring becomes significantly more effective when teams can correlate model degradation with specific data changes, enabling rapid identification of root causes for production issues. Compliance and audit requirements, particularly in regulated industries like healthcare and finance, demand comprehensive documentation of data processing activities, and data lineage provides the framework for meeting these stringent requirements while maintaining operational efficiency.
Enhance your ML workflows with advanced AI tools like Claude to implement sophisticated data lineage tracking strategies that scale with your organization’s growing AI ambitions. The integration of intelligent tracking systems with modern MLOps platforms creates powerful synergies that enhance both operational visibility and development productivity.
Fundamental Components of ML Data Lineage
Effective data lineage systems for machine learning encompass several critical components that work together to provide comprehensive visibility into data flow and transformations. Data source tracking forms the foundation, documenting not only the origins of datasets but also their characteristics, quality metrics, and historical changes over time. This includes tracking external data sources, internal databases, real-time streams, and any other data inputs that feed into the ML pipeline.
Transformation lineage represents another crucial component, capturing detailed information about how data changes as it moves through preprocessing steps, feature engineering processes, and model training procedures. This includes documentation of data cleaning operations, normalization techniques, feature selection methods, and any other transformations that alter the structure, content, or meaning of the original data. Understanding these transformations is essential for debugging issues, optimizing performance, and ensuring that models remain valid as underlying data evolves.
Dependency mapping creates a comprehensive view of relationships between different components of the ML system, showing how changes in one area might impact other parts of the pipeline. This includes dependencies between datasets, models, features, and even infrastructure components, enabling teams to assess the potential impact of changes before implementation and plan maintenance activities more effectively.
Data Lineage Architecture for Scalable ML Systems
Building scalable data lineage systems requires careful architectural consideration that balances comprehensiveness with performance, ensuring that tracking mechanisms do not become bottlenecks in high-throughput ML pipelines. Modern data lineage architectures typically employ event-driven approaches that capture lineage information asynchronously, minimizing impact on production processing while ensuring complete coverage of data flow activities.
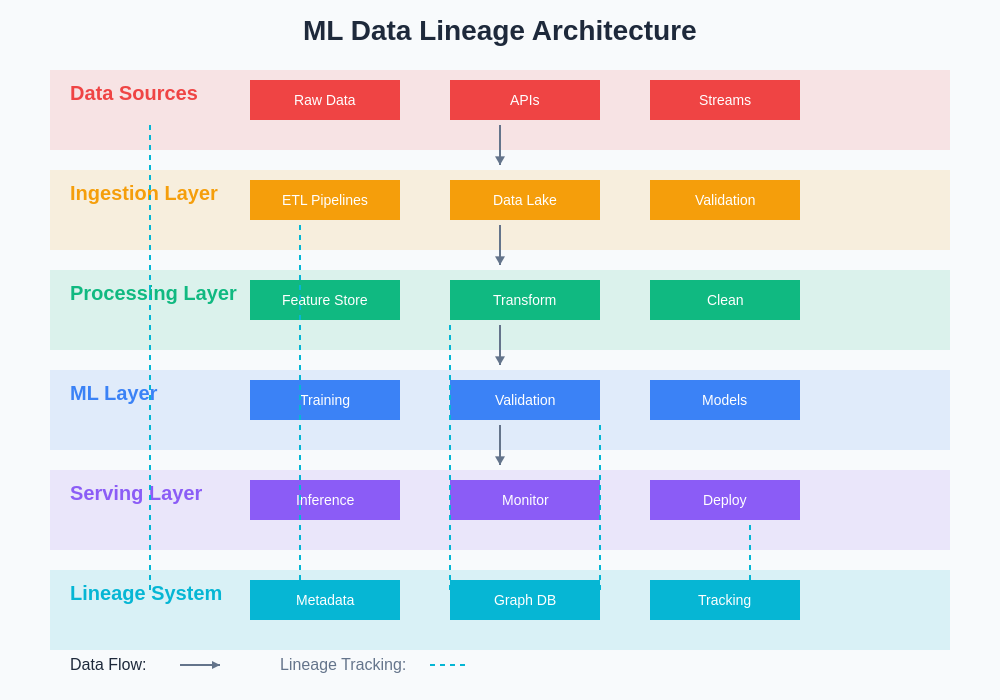
The architectural foundation of effective ML data lineage systems incorporates distributed tracking mechanisms that can handle the scale and complexity of modern machine learning operations. These systems must accommodate various data formats, processing frameworks, and deployment patterns while maintaining consistency and reliability across different environments and use cases.
Storage and retrieval systems for lineage data require specialized design considerations that prioritize both query performance and storage efficiency. Graph databases often provide optimal solutions for storing complex lineage relationships, while time-series databases excel at tracking changes over time. The choice of storage technology significantly impacts the system’s ability to answer complex lineage queries and provide real-time insights into data flow patterns.
Implementing Automated Lineage Capture
Automated lineage capture represents a critical advancement in data lineage technology, eliminating the manual overhead traditionally associated with comprehensive data tracking while ensuring complete coverage of ML pipeline activities. Modern automated systems leverage instrumentation at multiple levels, including data processing frameworks, orchestration tools, and infrastructure components, to capture lineage information without requiring explicit developer intervention.
The implementation of automated capture systems requires strategic integration with existing ML infrastructure, including data processing engines like Apache Spark and Kafka, orchestration platforms such as Airflow and Kubeflow, and cloud services including AWS, Google Cloud, and Azure ML. These integrations enable seamless capture of lineage information across diverse technology stacks while maintaining consistency in metadata format and quality.
Schema evolution tracking represents a particularly important aspect of automated lineage capture, as ML systems frequently encounter changes in data structure, format, and content that can significantly impact model performance. Automated systems must detect and document these changes, providing alerts when schema modifications might affect downstream processes and maintaining historical records of schema evolution for compliance and debugging purposes.
Advanced Lineage Visualization and Analysis
Data lineage visualization transforms complex data flow information into intuitive graphical representations that enable stakeholders across technical and business teams to understand ML system dependencies and data relationships. Advanced visualization tools provide multiple perspectives on lineage data, including high-level architectural views for strategic planning, detailed technical views for troubleshooting, and compliance-focused views for audit and regulatory requirements.
Interactive lineage exploration capabilities enable users to drill down from high-level system overviews to specific data transformations, following the path of individual records through complex processing pipelines. These capabilities prove invaluable during incident response situations where understanding the impact of data issues on downstream processes becomes critical for rapid resolution and prevention of similar problems in the future.
Leverage Perplexity’s research capabilities to stay informed about the latest developments in data lineage visualization techniques and emerging best practices for complex ML system management. The rapid evolution of visualization technologies continues to improve the accessibility and utility of lineage information across different organizational roles.
Compliance and Governance Through Data Lineage
Regulatory compliance in AI and machine learning increasingly demands comprehensive documentation of data processing activities, making data lineage systems essential infrastructure for organizations operating in regulated industries. Data lineage provides the foundation for demonstrating compliance with regulations such as GDPR, CCPA, HIPAA, and emerging AI-specific regulations that require organizations to document how personal data and sensitive information flows through their systems.
The governance capabilities enabled by comprehensive data lineage extend beyond regulatory compliance to include internal audit requirements, risk management processes, and quality assurance activities. Organizations can leverage lineage data to implement automated compliance checks, generate audit reports, and demonstrate adherence to internal data governance policies and external regulatory requirements.
Data retention and deletion policies become significantly more manageable with complete lineage visibility, enabling organizations to identify all locations where specific data exists and ensure comprehensive cleanup when required by regulatory or business requirements. This capability proves particularly valuable in machine learning contexts where data may be replicated, transformed, and stored across multiple systems and environments.
Performance Optimization Using Lineage Insights
Data lineage information provides valuable insights for optimizing ML pipeline performance, enabling teams to identify bottlenecks, eliminate redundant processing, and optimize resource utilization across their ML infrastructure. By analyzing lineage data, organizations can discover opportunities for caching intermediate results, parallelizing processing steps, and optimizing data movement between different system components.
Resource utilization analysis becomes more sophisticated when combined with lineage tracking, enabling organizations to understand how different data processing activities consume computational resources and identify opportunities for cost optimization. This analysis can reveal patterns in resource usage that inform decisions about infrastructure sizing, scheduling optimization, and architectural improvements.
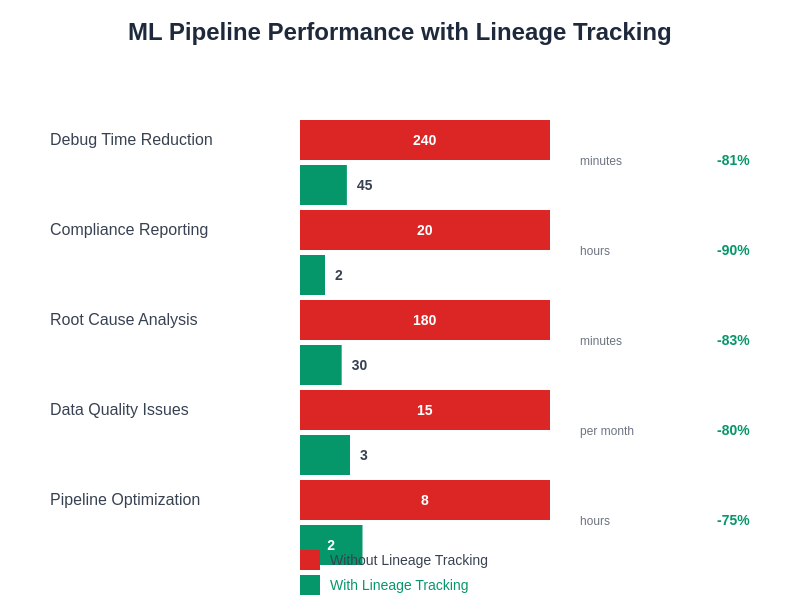
The correlation between data characteristics and processing performance becomes visible through comprehensive lineage tracking, enabling predictive optimization strategies that anticipate resource requirements based on data volume, complexity, and processing requirements. This predictive capability enables more efficient resource allocation and improved system reliability.
Integration with Modern MLOps Platforms
Modern MLOps platforms increasingly incorporate data lineage as a core capability, providing integrated tracking and visualization tools that work seamlessly with existing development and deployment workflows. These integrations eliminate the need for separate lineage systems while ensuring that tracking capabilities scale with the overall ML infrastructure and provide consistent user experiences across different tools and platforms.
Container and microservices architectures common in modern ML deployments require specialized approaches to lineage tracking that can handle dynamic service discovery, ephemeral computing resources, and distributed processing patterns. Modern MLOps platforms address these challenges through sophisticated instrumentation and metadata collection systems that maintain lineage visibility regardless of underlying infrastructure complexity.
The integration of lineage tracking with continuous integration and continuous deployment pipelines ensures that data flow documentation remains current with system changes, automatically updating lineage information as models are retrained, deployed, or modified. This integration eliminates manual maintenance overhead while ensuring that lineage information accurately reflects the current state of the ML system.
Real-Time Lineage for Streaming ML Systems
Streaming machine learning systems present unique challenges for data lineage tracking, requiring specialized approaches that can handle high-velocity data flows, real-time transformations, and dynamic processing topologies. Real-time lineage systems must balance the need for comprehensive tracking with the performance requirements of low-latency ML applications, often employing sampling strategies and asynchronous processing to minimize impact on stream processing performance.
Event-driven architectures provide natural foundations for real-time lineage tracking, enabling lineage information to flow alongside data through streaming pipelines. These approaches leverage message queues, event streams, and other distributed messaging systems to capture and propagate lineage metadata without disrupting primary data processing flows.
The complexity of real-time lineage tracking increases significantly in systems that employ dynamic scaling, load balancing, and fault tolerance mechanisms common in production streaming ML systems. Modern lineage platforms address these challenges through distributed tracking architectures that maintain consistency and completeness even in the face of system failures, network partitions, and other operational challenges.
Security and Access Control in Lineage Systems
Data lineage systems themselves become critical security assets that require careful protection, as they contain comprehensive information about organizational data assets, processing patterns, and system architectures. Security considerations include access control mechanisms that ensure lineage information is only available to authorized personnel, encryption of lineage metadata both in transit and at rest, and audit logging of lineage system access and modifications.
Role-based access control for lineage information enables organizations to provide appropriate visibility to different stakeholders while protecting sensitive information about system architecture and data processing patterns. Data scientists might need detailed technical lineage information for their specific projects, while business stakeholders require higher-level views that focus on data quality and compliance rather than technical implementation details.
The integration of lineage systems with existing identity and access management infrastructure ensures consistent security policies across the entire ML ecosystem, while specialized privacy controls can mask or redact sensitive information in lineage displays while maintaining the functional utility of the tracking system.
Future Directions in AI Data Lineage
The evolution of data lineage technology continues to accelerate, driven by increasing regulatory requirements, growing system complexity, and advancing capabilities in areas such as automated metadata discovery, intelligent lineage inference, and predictive impact analysis. Machine learning techniques are increasingly being applied to lineage systems themselves, enabling automated discovery of implicit data relationships, prediction of downstream impacts from system changes, and intelligent recommendations for optimization opportunities.
Federated lineage systems represent an emerging frontier that enables organizations to maintain comprehensive visibility across multi-cloud, hybrid, and partner-shared ML systems while respecting organizational boundaries and data sovereignty requirements. These systems enable collaborative ML development while maintaining appropriate security and governance controls.
The integration of lineage tracking with emerging technologies such as differential privacy, federated learning, and edge ML deployments presents both challenges and opportunities for advancing the state of the art in data tracking and governance. These emerging paradigms require new approaches to lineage tracking that can handle distributed training, privacy-preserving computations, and edge deployment scenarios.
Building a Data Lineage Strategy
Successful implementation of data lineage for AI requires a comprehensive strategy that addresses organizational, technical, and operational considerations while providing clear value to different stakeholders across the organization. The strategy must balance the need for comprehensive tracking with practical considerations around implementation complexity, performance impact, and ongoing maintenance requirements.
Organizational change management becomes a critical success factor for data lineage initiatives, as the benefits of comprehensive tracking only materialize when teams actually utilize lineage information in their daily workflows. Training programs, clear governance policies, and integration with existing processes help ensure that lineage systems provide practical value rather than becoming unused infrastructure.
The measurement of lineage system success requires careful definition of success metrics that align with organizational objectives, whether those focus on compliance requirements, operational efficiency, or system reliability improvements. Regular assessment and optimization of lineage systems ensures they continue to provide value as ML systems and organizational requirements evolve.
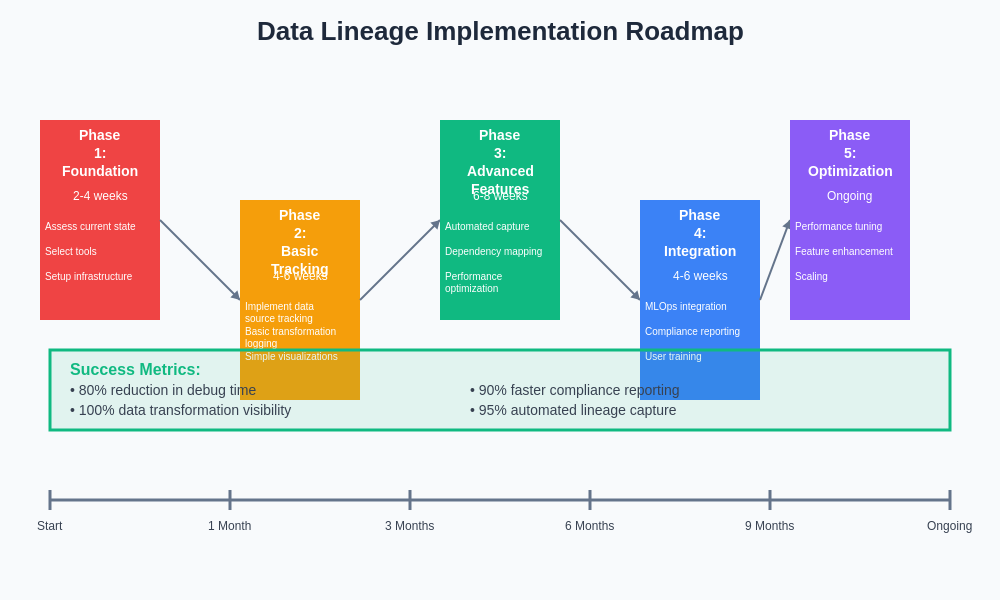
The roadmap for implementing comprehensive data lineage capabilities should account for the maturity of existing ML operations, available technical resources, and specific organizational requirements while providing clear milestones and success criteria for each implementation phase.
Conclusion
Data lineage for artificial intelligence represents a foundational capability that enables organizations to build reliable, compliant, and maintainable ML systems at scale. The comprehensive tracking of data flow through ML pipelines provides the visibility necessary for effective troubleshooting, compliance management, performance optimization, and strategic planning while supporting the growing sophistication of modern AI applications.
The investment in robust data lineage capabilities pays dividends across multiple dimensions of ML operations, from reduced incident response times and improved model reliability to enhanced compliance posture and more effective resource utilization. As AI systems continue to grow in complexity and business importance, the organizations that invest in comprehensive data lineage capabilities will be better positioned to realize the full potential of their ML initiatives while managing the associated risks and challenges.
The future of AI development depends on the ability to understand, manage, and govern complex data flows through sophisticated ML systems. Data lineage provides the foundation for this capability, enabling organizations to build AI systems that are not only powerful and effective but also transparent, accountable, and trustworthy in their operation and outcomes.
Disclaimer
This article provides general guidance on data lineage for AI systems and should not be considered as specific technical or compliance advice. Implementation approaches may vary based on specific organizational requirements, regulatory environments, and technical constraints. Organizations should consult with qualified professionals and conduct thorough assessments before implementing data lineage solutions in production environments.