The exponential growth of artificial intelligence applications and machine learning initiatives within modern organizations has exposed fundamental limitations in traditional centralized data architectures. As AI organizations scale their operations and diversify their data requirements, the monolithic data warehouse and lake approaches that once served as adequate solutions have become significant bottlenecks, creating dependencies that slow innovation and limit the autonomous operation of domain-specific teams. Data Mesh architecture emerges as a revolutionary paradigm that addresses these challenges through a decentralized approach to data ownership, management, and distribution, fundamentally reshaping how AI organizations structure their data infrastructure to support rapid innovation and scalable machine learning operations.
Discover the latest trends in AI data management to understand how leading organizations are implementing cutting-edge data architectures that support sophisticated artificial intelligence workflows. The transition from centralized to decentralized data management represents more than a technological shift; it embodies a fundamental reimagining of how data serves as the foundational substrate for artificial intelligence applications, enabling organizations to achieve unprecedented levels of agility, scalability, and domain-specific optimization in their machine learning initiatives.
Understanding Data Mesh Fundamentals
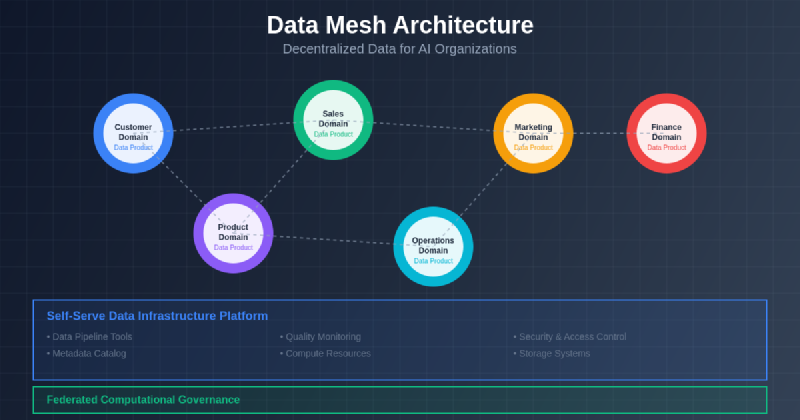
Data Mesh architecture represents a paradigmatic departure from traditional centralized data management approaches, introducing a sociotechnical framework that treats data as a product while distributing ownership and responsibility across domain-specific teams. This architectural philosophy recognizes that data expertise and context reside most naturally within the business domains that generate and consume data, rather than within centralized technical teams that lack deep understanding of domain-specific requirements and constraints. The fundamental premise of Data Mesh lies in the recognition that successful AI organizations require data architectures that can scale not just technologically, but organizationally, enabling autonomous teams to innovate rapidly while maintaining consistency and interoperability across the entire data ecosystem.
The architectural foundation of Data Mesh rests upon four core principles that collectively enable decentralized data management at scale. Domain ownership establishes clear responsibility boundaries where domain teams own their data throughout its lifecycle, from generation through consumption and eventual retirement. Data as a product transforms the traditional view of data from a byproduct of business operations into a carefully crafted asset designed to serve specific consumer needs with well-defined interfaces, quality guarantees, and service level agreements. Self-serve data infrastructure provides domain teams with the technological capabilities needed to independently manage their data products without requiring specialized data engineering expertise or dependencies on centralized teams. Federated computational governance ensures that while domains operate autonomously, they adhere to organization-wide standards for security, privacy, compliance, and interoperability that enable seamless data collaboration across domain boundaries.
Transforming AI Data Workflows
The implementation of Data Mesh architecture fundamentally transforms how AI organizations approach data workflows, moving from centralized extract-transform-load processes to distributed, domain-centric data pipelines that better align with the diverse requirements of machine learning applications. Traditional data warehouses and lakes often impose rigid schemas and processing patterns that fail to accommodate the varied data types, update frequencies, and quality requirements inherent in different AI use cases, leading to suboptimal compromises that limit the effectiveness of machine learning models and analytics applications. Data Mesh addresses these limitations by enabling each domain to optimize their data products according to their specific AI requirements, whether that involves real-time streaming data for fraud detection models, batch-processed historical data for recommendation systems, or carefully curated datasets for natural language processing applications.
Experience advanced AI assistance with Claude to navigate the complexities of implementing Data Mesh architectures and optimize your organization’s data infrastructure for machine learning success. The domain-centric approach inherent in Data Mesh enables AI teams to implement specialized data processing pipelines that leverage the most appropriate technologies for their specific use cases, whether that involves Apache Kafka for real-time event streaming, Apache Spark for large-scale batch processing, or specialized vector databases for embedding storage and similarity search operations.
Enabling Domain-Driven Data Products
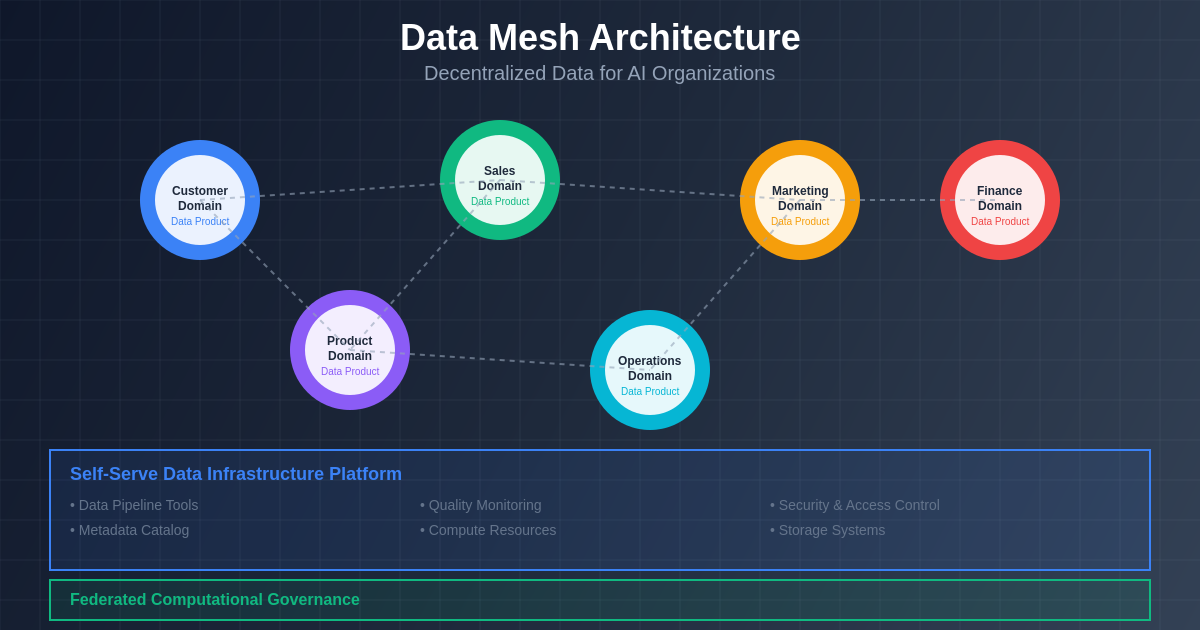
The conceptualization of data as products within the Data Mesh framework represents a fundamental shift in how AI organizations approach data management, transforming data from a raw resource into carefully designed assets that serve specific consumer needs with well-defined interfaces and quality guarantees. This product-oriented mindset requires domain teams to think beyond simply storing and processing their data to actively designing data experiences that enable downstream consumers, including machine learning engineers, data scientists, and business analysts, to efficiently discover, understand, and utilize data for their AI applications. The product approach necessitates clear documentation, versioning strategies, backward compatibility considerations, and comprehensive monitoring that ensures data products continue to meet consumer expectations as requirements evolve and scale.
The implementation of domain-driven data products requires sophisticated tooling and processes that enable domain teams to independently manage the full lifecycle of their data assets while adhering to organizational standards for quality, security, and interoperability. This includes implementing automated data quality monitoring that continuously validates data against predefined expectations, establishing clear schemas and APIs that enable programmatic access to data products, and providing comprehensive metadata that helps consumers understand data lineage, update frequencies, and appropriate use cases. The product-oriented approach also requires domain teams to establish clear service level agreements that define availability guarantees, update schedules, and support processes that enable consumers to reliably build AI applications on top of domain data products.
Decentralized Infrastructure for AI Scale
The infrastructure requirements for supporting Data Mesh architecture in AI organizations extend far beyond traditional data storage and processing capabilities, encompassing sophisticated platforms that enable domain teams to independently manage their data products while maintaining consistency and interoperability across the entire organizational data ecosystem. This infrastructure must provide self-service capabilities that allow domain teams with varying levels of technical expertise to implement sophisticated data processing pipelines, establish data quality monitoring, and expose their data products through standardized interfaces without requiring deep infrastructure expertise or dependencies on centralized platform teams.
The technological foundation for Data Mesh infrastructure typically involves cloud-native platforms that provide scalable compute and storage resources, container orchestration systems that enable flexible deployment of domain-specific data processing applications, and service mesh technologies that facilitate secure and reliable communication between different data products and consumers. Modern implementations often leverage Kubernetes as the underlying orchestration platform, enabling domain teams to deploy and manage their data processing applications using familiar development practices while benefiting from automated scaling, fault tolerance, and resource management capabilities that ensure reliable operation at scale.
The architectural complexity of Data Mesh infrastructure requires careful consideration of networking, security, and governance concerns that span multiple autonomous domains while maintaining the flexibility and independence that makes the decentralized approach valuable for AI organizations. This includes implementing zero-trust networking models that secure communication between data products and consumers, establishing identity and access management systems that enable fine-grained control over data access across domain boundaries, and providing observability platforms that enable both domain teams and central governance functions to monitor the health and performance of the distributed data ecosystem.
Machine Learning Integration Patterns
The integration of machine learning workflows within Data Mesh architecture requires sophisticated patterns that accommodate the unique requirements of AI applications while leveraging the benefits of decentralized data ownership and management. Machine learning applications often require access to data from multiple domains, creating complex dependency relationships that must be carefully managed to avoid recreating the bottlenecks and coupling issues that Data Mesh aims to address. Successful integration patterns typically involve establishing clear contracts between data-producing domains and ML-consuming applications, implementing robust data versioning strategies that enable reproducible model training and evaluation, and creating efficient data discovery mechanisms that help ML teams identify and access relevant data products across the organization.
The implementation of effective ML integration patterns within Data Mesh often involves creating specialized data products specifically designed to support machine learning use cases, such as feature stores that provide curated, ML-ready datasets with consistent schemas and quality guarantees. These specialized data products bridge the gap between raw domain data and the processed features required by machine learning models, enabling domain experts to contribute their knowledge about data semantics and business context while providing ML engineers with the standardized, high-quality inputs they need for successful model development and deployment.
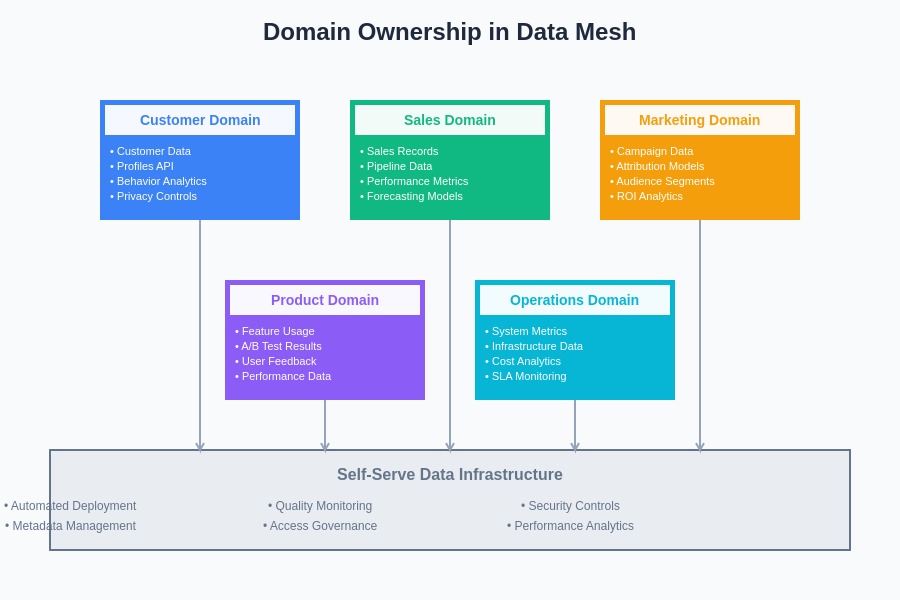
The domain-centric approach to data ownership establishes clear boundaries of responsibility where each business domain maintains complete control over their data products while leveraging shared infrastructure capabilities that enable autonomous operation without sacrificing organizational coherence or governance standards.
Enhance your research capabilities with Perplexity to stay current with the latest developments in Data Mesh implementation patterns and machine learning integration strategies that are shaping the future of AI data architecture. The evolution of ML integration patterns continues to advance with the development of automated feature engineering pipelines that can intelligently transform raw domain data into ML-ready features, automated data drift detection systems that monitor changes in domain data that might impact model performance, and sophisticated experimentation platforms that enable safe testing of model updates across distributed data environments.
Governance and Compliance Framework
The implementation of effective governance within Data Mesh architecture presents unique challenges that require balancing the autonomy and flexibility that make decentralized data management valuable with the consistency and compliance requirements that ensure organizational coherence and regulatory adherence. Federated computational governance emerges as the solution to this challenge, establishing automated systems and processes that embed governance requirements directly into the data infrastructure rather than relying on manual oversight and compliance checking that can become bottlenecks in decentralized environments.
The governance framework for Data Mesh typically encompasses multiple layers of control and oversight, ranging from automated policy enforcement at the infrastructure level to domain-specific governance practices that address the unique requirements of different business areas. Infrastructure-level governance includes automated security scanning that ensures data products comply with organizational security standards, privacy protection mechanisms that automatically apply appropriate data masking and access controls based on data classification, and compliance monitoring that tracks adherence to regulatory requirements across all data products and domains.
Domain-level governance enables individual domains to establish their own specific governance practices while ensuring alignment with organizational standards through federated oversight mechanisms. This includes domain-specific data quality standards that reflect the unique requirements of different business areas, specialized privacy and security controls that address domain-specific risks and regulatory requirements, and custom monitoring and alerting systems that provide domain teams with visibility into the health and compliance status of their data products.
Organizational Transformation Strategies
The successful implementation of Data Mesh architecture requires comprehensive organizational transformation that extends far beyond technological changes to encompass fundamental shifts in team structure, skill development, and cultural attitudes toward data ownership and responsibility. Organizations transitioning to Data Mesh must develop new roles and responsibilities that bridge traditional boundaries between business domains and technical data management functions, creating hybrid teams that combine domain expertise with sufficient technical capability to independently manage data products throughout their lifecycle.
The transformation process typically involves establishing new organizational structures that support domain autonomy while maintaining necessary coordination and oversight functions. This includes creating domain data product teams that combine business analysts, data engineers, and domain experts within cohesive units responsible for specific data products, establishing platform teams that provide self-service infrastructure capabilities and support services to domain teams, and implementing center of excellence functions that provide guidance, standards, and best practices for data product development across the organization.
The cultural transformation required for Data Mesh success involves shifting from traditional IT service models where business domains consume data services provided by centralized teams to product-oriented models where domains take ownership of their data and responsibility for serving other domains and consumers. This cultural shift requires significant investment in training and skill development, enabling domain teams to develop the technical capabilities needed to independently manage data products while maintaining their deep business context and domain expertise.
Performance and Scalability Optimization
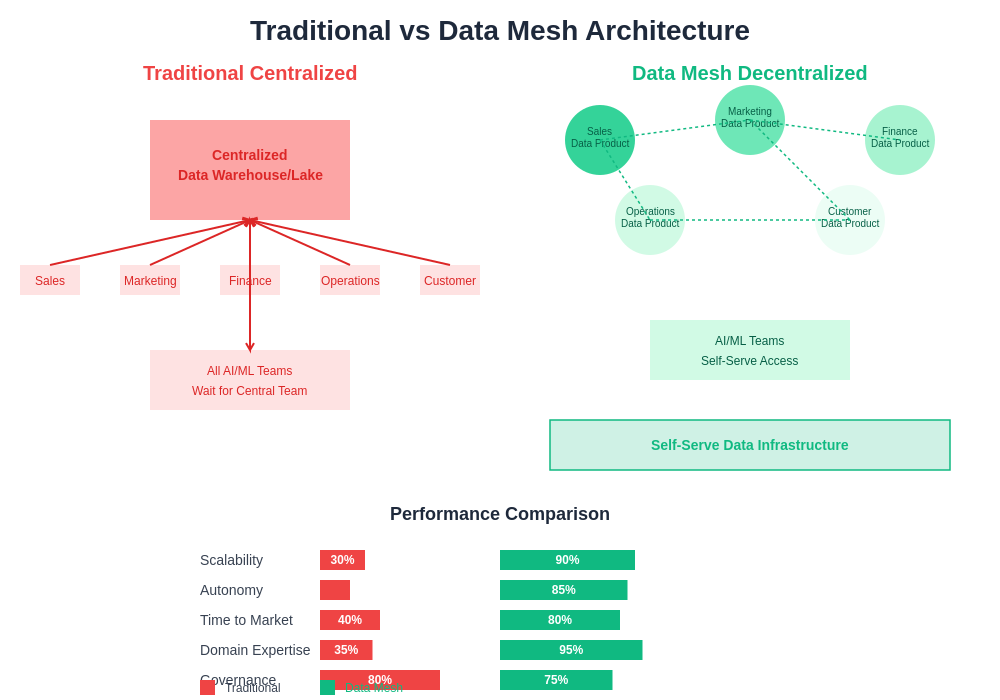
The performance characteristics of Data Mesh architecture present both opportunities and challenges for AI organizations seeking to optimize their data infrastructure for machine learning workloads at scale. The distributed nature of Data Mesh enables domain teams to optimize their data products for their specific performance requirements, potentially achieving better performance than centralized systems that must accommodate diverse use cases with compromised solutions. However, the distributed architecture also introduces complexity in areas such as cross-domain query optimization, data consistency management, and resource utilization that require careful design and implementation to avoid performance degradation.
Effective performance optimization within Data Mesh requires sophisticated monitoring and optimization strategies that operate at multiple levels of the architecture. Domain-level optimization focuses on ensuring that individual data products deliver optimal performance for their specific use cases and consumer requirements, involving techniques such as intelligent caching strategies, optimized data partitioning schemes, and specialized storage formats that maximize performance for particular access patterns. Cross-domain optimization addresses the performance challenges that arise when machine learning applications need to access and combine data from multiple domains, requiring efficient data federation techniques, intelligent query routing systems, and sophisticated caching strategies that minimize latency and maximize throughput for complex analytical workloads.
The scalability characteristics of Data Mesh architecture provide significant advantages for AI organizations that need to support rapidly growing data volumes and increasingly complex analytical workloads. The distributed nature of the architecture enables linear scaling by adding new domains and data products without creating bottlenecks in centralized systems, while the domain-specific optimization capabilities enable each part of the system to scale according to its specific requirements and constraints rather than being limited by the lowest common denominator performance characteristics of centralized systems.
Security and Privacy Implementation
The security and privacy requirements for Data Mesh architecture in AI organizations present complex challenges that require sophisticated approaches to identity management, access control, and data protection across distributed, autonomous domains. The decentralized nature of Data Mesh requires security models that can scale across multiple domains while maintaining consistency and effectiveness, typically involving zero-trust networking architectures that verify and authenticate every interaction between data products and consumers regardless of their location within the organizational network.
The implementation of effective security within Data Mesh requires comprehensive identity and access management systems that can handle the complex access patterns inherent in AI applications, where machine learning models and data processing pipelines may need to access data from multiple domains with different security requirements and constraints. This typically involves implementing sophisticated role-based access control systems that can express complex permissions across domain boundaries, automated credential management systems that handle the complexity of secure authentication across distributed systems, and comprehensive audit logging that provides visibility into data access patterns across the entire mesh architecture.
Privacy protection within Data Mesh requires specialized techniques that can automatically apply appropriate privacy controls based on data classification and consumer requirements without requiring manual intervention from centralized privacy teams. This includes automated data masking and anonymization systems that can intelligently protect sensitive information while preserving the utility of data for machine learning applications, differential privacy implementations that provide mathematical guarantees about privacy protection while enabling statistical analysis and model training, and sophisticated consent management systems that can track and enforce privacy preferences across complex data sharing scenarios.
Future Evolution and Innovation
The continued evolution of Data Mesh architecture for AI organizations promises significant advances in areas such as automated data product discovery, intelligent data quality management, and adaptive infrastructure scaling that will further enhance the benefits of decentralized data management. Emerging technologies such as machine learning-powered data cataloging systems that can automatically discover and classify data products across domains, intelligent data quality monitoring that can predict and prevent data quality issues before they impact downstream consumers, and adaptive infrastructure platforms that can automatically optimize resource allocation based on changing usage patterns represent significant opportunities for enhancing the effectiveness and efficiency of Data Mesh implementations.
The integration of advanced AI technologies into Data Mesh infrastructure itself presents exciting possibilities for creating self-managing data ecosystems that can automatically optimize performance, ensure compliance, and maintain quality standards with minimal human intervention. This includes the development of AI-powered governance systems that can automatically detect and remediate policy violations, intelligent data product recommendation systems that can help consumers discover relevant data across the organization, and automated data pipeline optimization systems that can continuously tune performance based on changing requirements and usage patterns.
The democratization of advanced data management capabilities through Data Mesh architecture is likely to accelerate innovation in AI applications by enabling more teams to develop sophisticated machine learning solutions without requiring specialized data engineering expertise or dependencies on centralized data teams. This democratization effect, combined with the scalability and flexibility benefits of the decentralized architecture, positions Data Mesh as a foundational enabling technology for the next generation of AI-powered organizations that can rapidly adapt to changing market conditions and customer requirements while maintaining the data quality and governance standards necessary for reliable and responsible AI deployment.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of Data Mesh architecture and its applications in AI organizations. Readers should conduct their own research and consider their specific requirements when implementing Data Mesh architectures. The effectiveness of Data Mesh may vary depending on organizational context, technical infrastructure, and specific use cases. Implementation should be undertaken with appropriate technical expertise and consideration of existing systems and processes.