
The exponential growth of machine learning datasets and model complexity has necessitated sophisticated approaches to data management and distributed training architectures. Data partitioning and sharding strategies have emerged as fundamental techniques for enabling scalable machine learning training across distributed systems, allowing organizations to process massive datasets efficiently while maintaining model performance and training stability. These methodologies represent the backbone of modern ML infrastructure, enabling the training of large-scale models that would be impossible to handle on single-node systems.
Explore the latest AI infrastructure trends to understand how distributed training is evolving with cutting-edge hardware and software innovations. The strategic implementation of data partitioning techniques directly impacts training efficiency, resource utilization, and the overall feasibility of large-scale machine learning projects in production environments.
Fundamentals of Data Partitioning in Machine Learning
Data partitioning in machine learning contexts involves the systematic division of training datasets across multiple computational nodes or storage systems to enable parallel processing and distributed training workflows. This approach addresses the fundamental challenge of handling datasets that exceed the memory or processing capacity of individual machines while maintaining data integrity and ensuring consistent model convergence across distributed training environments.
The core principles of effective data partitioning extend beyond simple data splitting, encompassing considerations such as data locality, load balancing, fault tolerance, and communication overhead optimization. Modern machine learning frameworks require sophisticated partitioning strategies that can adapt to varying data distributions, handle imbalanced datasets, and maintain statistical properties essential for model convergence and generalization performance.
Effective partitioning strategies must account for the specific characteristics of machine learning workloads, including the iterative nature of training algorithms, the need for consistent gradient aggregation, and the importance of maintaining data locality to minimize network communication overhead during distributed training processes.
Understanding Sharding Architectures for ML Systems
Sharding represents a specialized form of data partitioning that distributes data across multiple database instances or storage systems based on predetermined partitioning keys or algorithms. In machine learning contexts, sharding enables horizontal scaling of data storage and access patterns, allowing training systems to handle petabyte-scale datasets while maintaining acceptable query performance and data retrieval speeds.
Enhance your ML infrastructure with advanced AI tools like Claude for intelligent system design and optimization strategies that can guide your sharding implementation decisions. The architectural decisions surrounding sharding implementation directly impact training throughput, fault tolerance, and system maintainability across distributed ML environments.
Modern sharding architectures for machine learning systems incorporate intelligent routing mechanisms, dynamic rebalancing capabilities, and sophisticated caching strategies that optimize data access patterns for training workloads. These systems must handle the unique requirements of ML training, including sequential data access, random sampling patterns, and the need for consistent data versioning across training epochs.
The implementation of effective sharding strategies requires careful consideration of data characteristics, access patterns, and computational requirements specific to different types of machine learning models and training algorithms.
Horizontal vs Vertical Partitioning Strategies
The choice between horizontal and vertical partitioning strategies fundamentally shapes the architecture and performance characteristics of distributed machine learning systems. Horizontal partitioning, also known as row-based sharding, divides datasets by distributing complete records across multiple nodes based on partitioning keys or hash functions, making it particularly suitable for scenarios where training algorithms require access to complete feature vectors.
Vertical partitioning distributes different feature subsets or columns across multiple nodes, enabling specialized processing of different feature types and supporting scenarios where feature engineering or preprocessing can be parallelized across different computational resources. This approach proves particularly valuable for high-dimensional datasets where different feature groups may require distinct processing pipelines or computational resources.
The selection between these approaches depends heavily on model architecture requirements, data access patterns, and the specific computational characteristics of the machine learning algorithms being employed. Many modern distributed training systems implement hybrid approaches that combine both horizontal and vertical partitioning strategies to optimize performance across different phases of the training pipeline.
Advanced partitioning strategies often incorporate dynamic switching between horizontal and vertical approaches based on training phase requirements, data characteristics, and available computational resources, enabling adaptive optimization of distributed training performance.
Hash-Based Sharding Implementation Patterns
Hash-based sharding represents one of the most widely adopted approaches for distributing machine learning datasets across distributed storage and computational systems. This methodology employs hash functions to deterministically assign data records to specific shards based on key attributes, ensuring uniform data distribution and predictable access patterns across the distributed system.
The implementation of effective hash-based sharding requires careful selection of hash functions that provide uniform distribution while minimizing data skew and hotspot formation. Consistent hashing algorithms have gained popularity in ML systems due to their ability to handle dynamic node additions and removals with minimal data redistribution requirements, making them particularly suitable for elastic cloud environments.
Modern hash-based sharding implementations incorporate sophisticated hash function selection, key space partitioning, and load balancing mechanisms that adapt to changing data distributions and access patterns throughout the training process. These systems must handle the unique challenges of machine learning workloads, including batch processing requirements, epoch-based data access, and the need for reproducible data ordering across training runs.
The effectiveness of hash-based sharding strategies directly impacts training performance, resource utilization, and system scalability, making careful implementation and tuning essential for optimal distributed training outcomes.
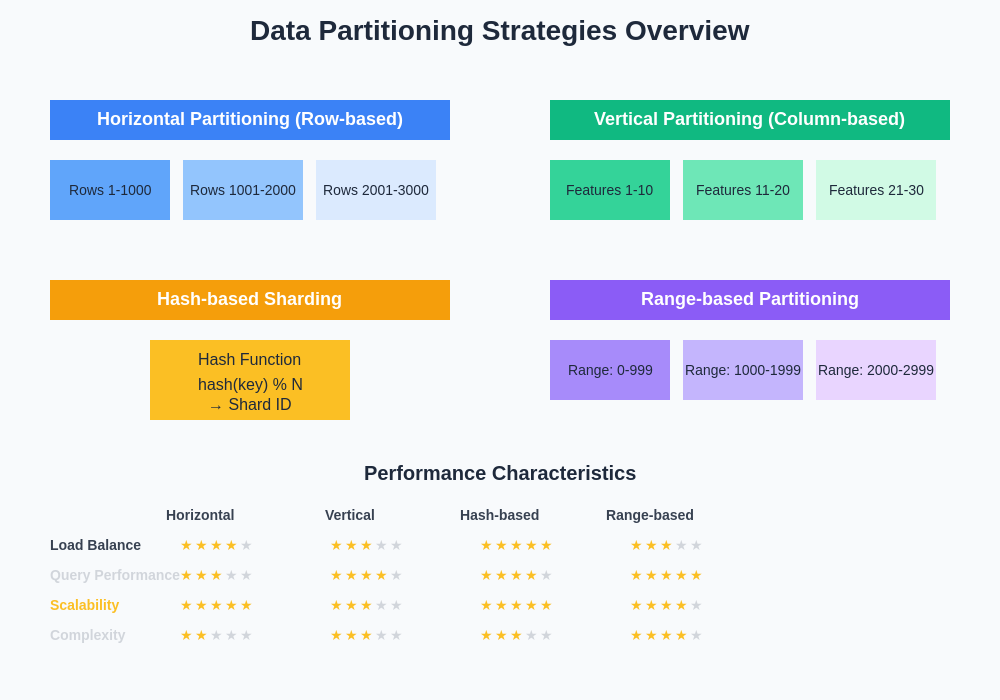
The landscape of data partitioning strategies encompasses multiple approaches, each optimized for specific use cases and system architectures. Understanding the trade-offs between different partitioning methods enables informed decision-making for distributed ML system design and implementation.
Range-Based Partitioning for Sequential Data
Range-based partitioning strategies prove particularly effective for machine learning datasets with inherent ordering or temporal characteristics, such as time series data, sequential models, or datasets where maintaining data locality based on key ranges provides performance benefits. This approach divides data based on value ranges of partitioning keys, enabling efficient range queries and sequential access patterns common in many ML training scenarios.
The implementation of range-based partitioning requires careful analysis of data distribution patterns and access requirements to ensure balanced partition sizes and optimal query performance. Uneven data distributions can lead to hotspots and load imbalancing, necessitating dynamic partition boundary adjustment mechanisms and intelligent load redistribution strategies.
Leverage advanced research capabilities with Perplexity to stay current with the latest developments in distributed systems and partitioning strategies for machine learning applications. Modern range-based partitioning systems incorporate predictive analytics to anticipate data growth patterns and proactively adjust partition boundaries to maintain optimal performance characteristics.
Advanced range partitioning implementations often combine multiple partitioning dimensions, creating hierarchical partitioning schemes that optimize for both sequential access patterns and parallel processing requirements common in distributed ML training environments.
Directory-Based Sharding and Metadata Management
Directory-based sharding approaches utilize centralized or distributed metadata management systems to maintain mapping information between data records and their corresponding storage locations across the distributed system. This methodology provides flexible data placement strategies and supports complex query patterns while enabling dynamic data redistribution and load balancing operations.
The implementation of directory-based sharding requires sophisticated metadata management architectures that can handle high-frequency lookups, maintain consistency across distributed updates, and provide fault tolerance mechanisms to prevent single points of failure. Modern implementations often employ distributed hash tables, consistent hashing, or blockchain-based approaches for metadata management and synchronization.
Directory-based systems excel in scenarios requiring complex data relationships, multi-dimensional partitioning strategies, or dynamic data placement optimization based on access patterns and system performance metrics. These approaches enable advanced features such as data locality optimization, intelligent caching, and adaptive resource allocation based on training workload characteristics.
The scalability and performance of directory-based sharding systems depend heavily on the efficiency of metadata operations and the ability to minimize metadata lookup overhead during high-frequency data access operations common in machine learning training workflows.
Load Balancing and Data Skew Mitigation
Effective load balancing represents a critical challenge in distributed machine learning systems, where uneven data distribution or skewed access patterns can create performance bottlenecks and underutilize available computational resources. Data skew mitigation strategies encompass both proactive partitioning design decisions and reactive load redistribution mechanisms that maintain optimal system performance throughout training processes.
Modern load balancing approaches employ sophisticated monitoring and analytics systems that track partition access patterns, computational load distribution, and system performance metrics to identify and address load imbalances before they impact training performance. These systems implement dynamic partition splitting, data migration, and resource reallocation strategies that adapt to changing workload characteristics.
The implementation of effective load balancing requires careful consideration of the trade-offs between data locality optimization and load distribution, as well as the overhead costs associated with data migration and system reconfiguration operations. Advanced systems employ predictive modeling to anticipate load imbalances and proactively implement corrective measures.
Machine learning workloads present unique load balancing challenges due to their iterative nature, batch processing requirements, and the need for synchronized operations across distributed nodes, necessitating specialized load balancing strategies optimized for ML training characteristics.
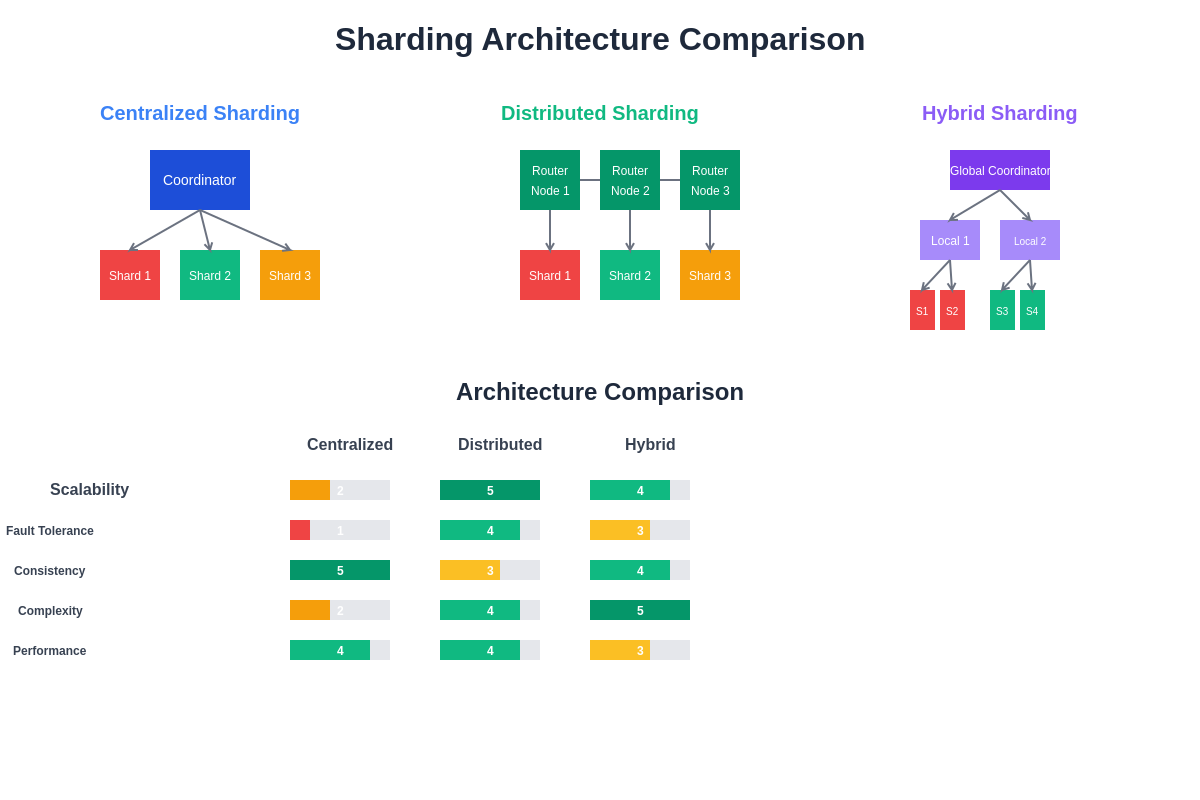
Different sharding architectures offer distinct advantages and trade-offs for machine learning applications. Understanding these architectural differences enables optimal system design decisions based on specific use case requirements and performance objectives.
Distributed Training Coordination Strategies
The coordination of distributed training processes across sharded datasets requires sophisticated synchronization mechanisms that ensure consistent model convergence while maximizing parallel processing efficiency. Coordination strategies encompass gradient aggregation protocols, parameter synchronization mechanisms, and fault tolerance procedures that maintain training stability across distributed environments.
Synchronous training approaches require coordination mechanisms that ensure all nodes complete their processing before proceeding to the next training step, providing consistent gradient updates but potentially suffering from stragglers and reduced overall system throughput. Asynchronous approaches allow nodes to proceed independently, improving system utilization but requiring sophisticated staleness tolerance and convergence guarantees.
Modern distributed training frameworks implement hybrid coordination strategies that adapt synchronization approaches based on network conditions, system performance characteristics, and model convergence requirements. These systems employ techniques such as elastic synchronization, adaptive batching, and intelligent straggler mitigation to optimize training performance.
The effectiveness of coordination strategies directly impacts training convergence speed, resource utilization, and system fault tolerance, making careful selection and implementation crucial for successful distributed ML training deployments.
Fault Tolerance and Data Recovery Mechanisms
Fault tolerance represents a fundamental requirement for distributed machine learning systems handling large-scale datasets across multiple nodes and storage systems. Effective fault tolerance strategies encompass data replication protocols, checkpoint management systems, and recovery mechanisms that ensure training continuity despite hardware failures, network partitions, or software errors.
Data replication strategies must balance fault tolerance requirements with storage overhead and network communication costs, implementing intelligent replication policies that adapt to data access patterns and system reliability characteristics. Modern systems employ erasure coding, distributed consensus protocols, and intelligent placement algorithms to optimize fault tolerance while minimizing resource overhead.
Checkpoint management systems provide mechanisms for preserving training state and enabling recovery from various failure scenarios, implementing efficient serialization protocols and distributed storage strategies that minimize checkpoint overhead while ensuring rapid recovery capabilities. These systems must handle the unique requirements of machine learning training, including model state preservation, optimizer state management, and data iterator synchronization.
Advanced fault tolerance implementations incorporate predictive failure detection, proactive data migration, and intelligent resource allocation strategies that minimize the impact of failures on training performance and system availability.
Performance Optimization and Caching Strategies
Performance optimization in sharded machine learning systems requires sophisticated caching strategies that account for data access patterns, memory hierarchy characteristics, and network communication overhead. Effective caching implementations employ multi-level cache architectures, intelligent prefetching algorithms, and adaptive cache replacement policies optimized for ML training workloads.
Local caching strategies focus on optimizing data access within individual nodes, implementing memory-efficient data structures and algorithms that minimize data movement and maximize computational throughput. These approaches must handle the unique characteristics of ML training data, including batch processing patterns, epoch-based access cycles, and the need for consistent data ordering.
Distributed caching systems coordinate cache operations across multiple nodes, implementing coherence protocols and consistency mechanisms that ensure data integrity while maximizing cache hit rates and minimizing network communication overhead. Modern implementations employ intelligent cache partitioning and replication strategies that adapt to training workload characteristics.
The effectiveness of caching strategies directly impacts training throughput, resource utilization, and system scalability, making careful design and implementation essential for optimal distributed ML system performance.
Cloud-Native Partitioning Solutions
Cloud-native partitioning solutions leverage managed cloud services, containerization technologies, and orchestration platforms to provide scalable and flexible data partitioning capabilities for machine learning workloads. These approaches enable organizations to implement sophisticated partitioning strategies without managing underlying infrastructure complexity while benefiting from cloud provider optimization and scaling capabilities.
Modern cloud platforms provide specialized services for distributed data processing, including managed storage systems, distributed computing frameworks, and ML-specific orchestration tools that simplify the implementation and management of partitioned training systems. These services often incorporate built-in fault tolerance, automatic scaling, and performance optimization features.
Container-based partitioning strategies employ orchestration platforms such as Kubernetes to manage distributed training workloads, implementing dynamic resource allocation, intelligent scheduling, and automated scaling policies that adapt to changing workload requirements. These approaches enable portable and reproducible distributed training environments across different cloud providers and infrastructure configurations.
The adoption of cloud-native partitioning solutions requires careful consideration of cost optimization, data locality, network performance, and vendor lock-in implications while leveraging the benefits of managed services and automated scaling capabilities.
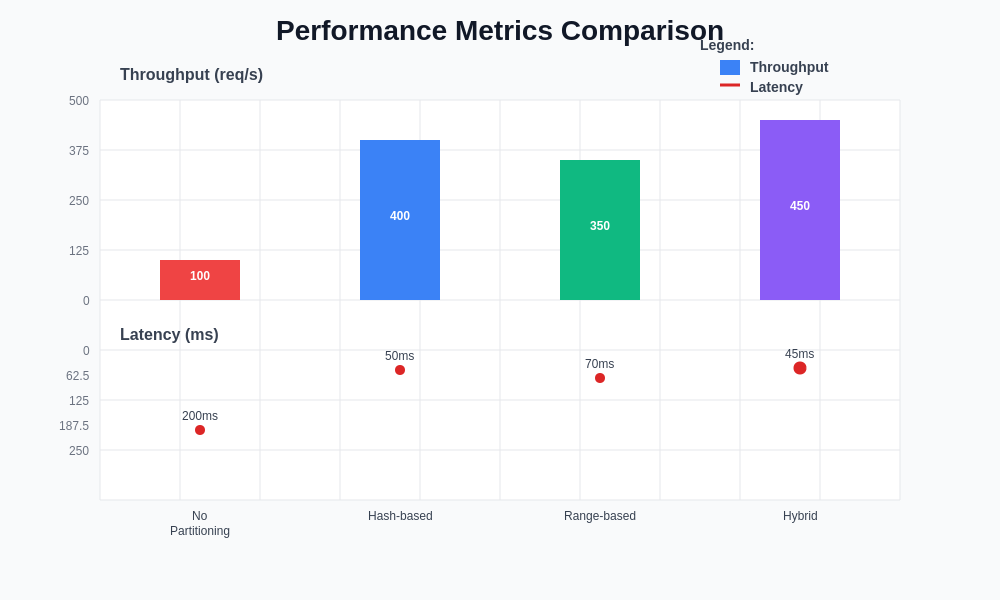
The performance characteristics of different partitioning strategies vary significantly across key metrics including throughput, latency, scalability, and resource utilization. Understanding these performance trade-offs enables informed architectural decisions for distributed ML systems.
Emerging Trends and Future Directions
The landscape of data partitioning and sharding for machine learning continues to evolve with advances in hardware architectures, distributed systems technologies, and machine learning methodologies. Emerging trends include the integration of edge computing paradigms, specialized hardware optimization, and intelligent adaptive partitioning systems that leverage machine learning techniques to optimize their own performance.
The development of quantum-classical hybrid computing systems presents new opportunities and challenges for data partitioning strategies, requiring novel approaches to data distribution and computation coordination across fundamentally different computational paradigms. These developments may reshape the fundamental assumptions underlying current partitioning methodologies.
Advances in network technologies, including high-speed interconnects and software-defined networking, enable new partitioning strategies that were previously impractical due to communication overhead constraints. These technological improvements open possibilities for more dynamic and flexible partitioning approaches that can adapt in real-time to changing system conditions.
The continued growth in dataset sizes and model complexity drives ongoing research into more sophisticated partitioning strategies that can handle extreme-scale systems while maintaining efficiency and reliability standards required for production machine learning applications.
Implementation Best Practices and Guidelines
Successful implementation of data partitioning and sharding strategies requires adherence to established best practices that encompass system design, operational procedures, and monitoring methodologies. Key principles include thorough workload characterization, careful performance testing, and incremental deployment strategies that minimize risks while enabling optimization opportunities.
Monitoring and observability represent critical components of effective partitioning implementations, requiring comprehensive metrics collection, alerting systems, and diagnostic tools that enable rapid identification and resolution of performance issues. Modern implementations employ sophisticated monitoring frameworks that provide real-time visibility into system performance and health indicators.
Documentation and knowledge management practices ensure successful long-term operation and maintenance of complex distributed systems, encompassing architectural documentation, operational procedures, and troubleshooting guides that enable effective system management and evolution.
The establishment of clear governance policies, security protocols, and compliance procedures ensures that distributed ML systems meet organizational requirements while maintaining data integrity and privacy protections throughout the training and deployment lifecycle.
Conclusion and Strategic Considerations
The strategic implementation of data partitioning and sharding strategies represents a foundational element of scalable machine learning infrastructure that enables organizations to leverage large-scale datasets effectively while maintaining system performance and reliability. The selection and implementation of appropriate partitioning approaches require careful analysis of workload characteristics, system requirements, and organizational constraints.
The continued evolution of machine learning methodologies and infrastructure technologies necessitates adaptive partitioning strategies that can evolve with changing requirements while maintaining backward compatibility and operational stability. Organizations must balance innovation opportunities with proven approaches to ensure successful long-term outcomes.
The integration of partitioning strategies with broader ML infrastructure components, including model serving systems, data pipeline orchestration, and monitoring frameworks, creates comprehensive platforms that support the full machine learning lifecycle from data ingestion through model deployment and maintenance.
Successful distributed machine learning implementations require ongoing optimization, monitoring, and adaptation to ensure continued effectiveness as datasets grow, models become more complex, and organizational requirements evolve in response to changing business needs and technological capabilities.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The implementation of distributed systems and data partitioning strategies involves complex technical considerations that may vary based on specific use cases, infrastructure requirements, and organizational constraints. Readers should conduct thorough testing and consultation with qualified professionals before implementing production distributed machine learning systems. The effectiveness of partitioning strategies may vary depending on specific workloads, data characteristics, and system configurations.