
The foundation of successful artificial intelligence systems lies not merely in sophisticated algorithms or computational power, but fundamentally in the quality of the data used for training. Data quality metrics serve as the critical diagnostic tools that enable practitioners to assess, monitor, and optimize the health of datasets before they are fed into machine learning pipelines. Understanding and implementing comprehensive data quality measurement frameworks has become essential for organizations seeking to deploy reliable, accurate, and robust AI systems that perform consistently in production environments.
Explore cutting-edge AI development trends to understand how data quality considerations are evolving alongside advancing machine learning methodologies. The relationship between data quality and model performance is intricate and multifaceted, requiring systematic approaches to measurement and continuous monitoring throughout the entire machine learning lifecycle. Poor data quality can lead to biased models, unreliable predictions, and costly failures in production systems, making comprehensive quality assessment a non-negotiable component of responsible AI development.
The Critical Importance of Data Quality in AI Systems
Data quality assessment has evolved from a peripheral concern to a central pillar of machine learning engineering, as organizations have learned that even the most sophisticated algorithms cannot compensate for fundamentally flawed training data. The principle of “garbage in, garbage out” applies with particular force in machine learning contexts, where models learn to replicate and amplify the patterns present in their training data, including any systematic errors, biases, or inconsistencies that may be embedded within the dataset.
The financial and operational implications of poor data quality are substantial, with studies indicating that organizations can lose significant revenue and operational efficiency due to decisions based on models trained on suboptimal data. Beyond immediate performance concerns, data quality issues can lead to ethical problems, regulatory compliance failures, and reputational damage when AI systems exhibit unexpected or discriminatory behavior in real-world applications. This has driven the development of sophisticated frameworks for measuring and monitoring data quality that go far beyond simple completeness checks to encompass complex statistical, semantic, and contextual assessments.
Fundamental Dimensions of Data Quality Assessment
Effective data quality measurement requires a multidimensional approach that evaluates datasets across several critical dimensions, each contributing to the overall fitness of the data for machine learning applications. Completeness represents the most basic dimension, measuring the extent to which the dataset contains all required data points and features without missing values that could compromise model training or inference. However, completeness alone is insufficient, as complete datasets can still be fundamentally unsuitable for machine learning if they fail to meet other quality criteria.
Accuracy measures how closely the data values correspond to the true, real-world values they are intended to represent, encompassing both systematic errors that affect entire features and random errors that introduce noise into individual observations. Consistency ensures that data values are uniform across the dataset and do not contradict each other, particularly important when datasets are assembled from multiple sources or collected over extended time periods. Validity checks that data values conform to defined formats, ranges, and business rules, preventing obviously incorrect values from contaminating the training process.
Enhance your AI development workflow with Claude’s advanced capabilities for comprehensive data analysis and quality assessment tasks that require sophisticated reasoning and pattern recognition. The integration of AI-powered tools into data quality assessment workflows enables more thorough and efficient evaluation of large-scale datasets while maintaining the nuanced understanding necessary for complex quality determinations.
Statistical Metrics for Dataset Health Evaluation
Statistical analysis forms the backbone of quantitative data quality assessment, providing objective measures that can be tracked over time and compared across different datasets or data sources. Distributional analysis examines the statistical properties of individual features, identifying anomalies, outliers, and unusual patterns that may indicate data quality issues or collection problems. Measures such as skewness, kurtosis, and multimodality can reveal important characteristics about data distributions that impact model training effectiveness.
Correlation analysis helps identify relationships between features that may indicate data leakage, redundancy, or unexpected dependencies that could compromise model generalization. High correlations between features might suggest that some variables are derived from others or that the data collection process introduced artificial relationships that do not exist in the real world. Conversely, expected correlations that are absent might indicate measurement errors or data corruption that needs to be addressed before model training.
Variance analysis assesses the information content of individual features, identifying variables with extremely low variance that provide little discriminative power for machine learning models. Features with zero or near-zero variance often represent constants, errors in data collection, or categories that are not well-represented in the dataset. Similarly, features with excessive variance might indicate scaling issues, outliers, or measurement errors that need correction before effective model training can occur.
Bias Detection and Fairness Assessment
Modern data quality assessment must include comprehensive evaluation of potential biases that could lead to unfair or discriminatory model behavior, particularly as AI systems are increasingly deployed in high-stakes applications affecting human welfare. Demographic bias assessment examines whether protected attributes are proportionally represented in the dataset and whether the distribution of target variables varies systematically across different demographic groups in ways that could lead to unfair treatment.
Selection bias evaluation determines whether the data collection process systematically excluded or underrepresented certain populations, scenarios, or time periods that are important for the intended application of the machine learning model. This type of bias can be particularly subtle and difficult to detect, requiring careful analysis of the data collection methodology and comparison with known population statistics or external benchmarks.
Temporal bias assessment is crucial for datasets collected over time, as changing conditions, evolving measurement techniques, or shifts in population behavior can introduce systematic differences between data collected at different time periods. Such temporal inconsistencies can severely impact model performance when models trained on historical data are applied to current or future scenarios that differ systematically from the training period.
Automated Data Profiling and Quality Scoring
Automated data profiling tools have become essential for managing the scale and complexity of modern machine learning datasets, providing systematic analysis of data characteristics that would be impractical to assess manually. These tools generate comprehensive statistical summaries, identify patterns and anomalies, and flag potential quality issues that require human attention or additional investigation. Effective profiling encompasses both univariate analysis of individual features and multivariate analysis of relationships between features.
Quality scoring systems aggregate multiple individual metrics into composite scores that provide high-level assessments of overall dataset health while maintaining the ability to drill down into specific areas of concern. These scoring systems typically weight different quality dimensions based on their importance for specific machine learning applications, recognizing that the relative importance of completeness, accuracy, and other quality factors varies depending on the intended use of the model and the specific algorithm being employed.
Leverage Perplexity’s research capabilities to stay current with the latest developments in automated data quality assessment tools and methodologies. The rapid evolution of data profiling technologies requires continuous learning and adaptation to take advantage of new capabilities and approaches that can improve the efficiency and effectiveness of quality assessment processes.
Domain-Specific Quality Metrics
Different machine learning applications require specialized quality metrics that reflect the unique characteristics and requirements of specific domains. Computer vision datasets require assessment of image quality metrics such as resolution, brightness, contrast, and sharpness, as well as annotation quality metrics that evaluate the accuracy and consistency of bounding boxes, segmentation masks, or classification labels. Poor image quality or inconsistent annotations can significantly degrade model performance and lead to unreliable predictions in production environments.
Natural language processing datasets require evaluation of text quality metrics including linguistic diversity, grammatical correctness, semantic coherence, and annotation consistency for tasks such as sentiment analysis, named entity recognition, or machine translation. Text data presents unique challenges including handling of multiple languages, dialects, and writing styles, as well as assessment of potential biases in language use or representation of different communities and perspectives.
Time series datasets require specialized metrics that assess temporal consistency, sampling regularity, and the presence of trends, seasonality, and other temporal patterns that affect model training. Missing values in time series data are particularly problematic as they can disrupt temporal relationships and patterns that are essential for accurate forecasting or classification. Irregular sampling intervals, sudden changes in measurement frequency, or gaps in data collection can significantly impact model performance and require specialized handling techniques.
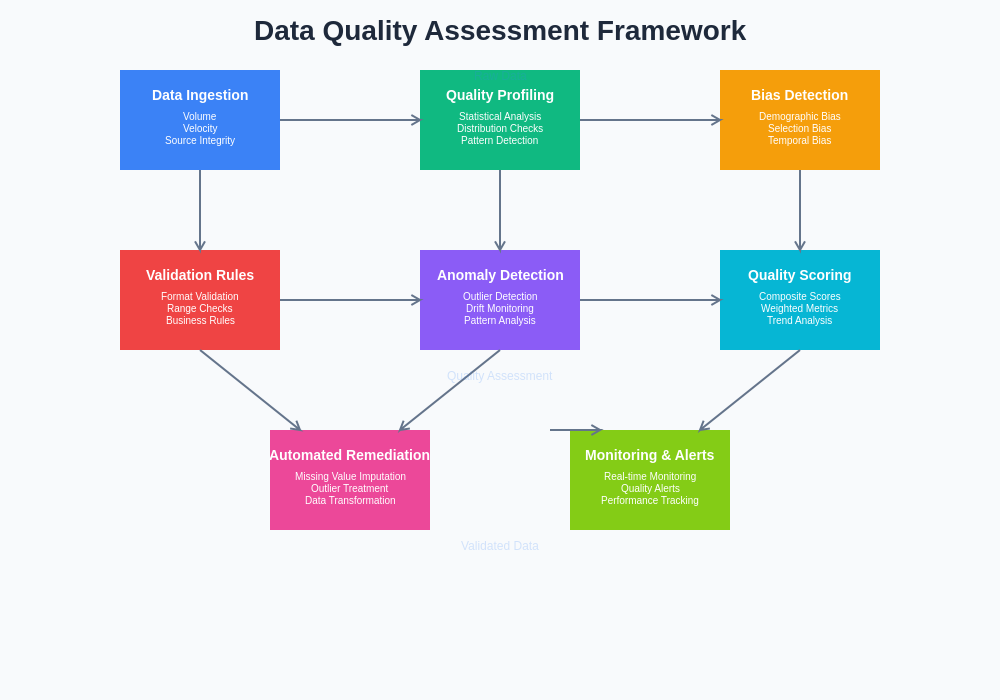
The comprehensive evaluation of dataset health requires a systematic framework that integrates multiple assessment dimensions, from basic statistical analysis through advanced bias detection and domain-specific metrics. This holistic approach ensures that potential quality issues are identified and addressed before they can compromise model performance or lead to unexpected behavior in production systems.
Longitudinal Quality Monitoring and Drift Detection
Data quality is not a static characteristic but rather a dynamic property that can change over time due to evolving data sources, changing collection processes, or shifts in the underlying phenomena being measured. Longitudinal monitoring systems track quality metrics over time, identifying trends, seasonal patterns, and sudden changes that might indicate emerging quality problems or shifts in data generation processes. This temporal perspective is essential for maintaining model performance as new data is collected and integrated into existing datasets.
Drift detection algorithms specifically monitor for statistical changes in data distributions that might indicate that the training data is becoming less representative of current conditions. Concept drift occurs when the relationship between input features and target variables changes over time, while covariate drift refers to changes in the distribution of input features themselves. Both types of drift can significantly degrade model performance and require retraining or adaptation strategies to maintain acceptable performance levels.
Quality degradation detection systems identify subtle declines in data quality that might not be immediately apparent but can accumulate over time to significantly impact model performance. These systems often employ statistical process control techniques, anomaly detection algorithms, and trend analysis to identify emerging quality problems before they reach levels that severely compromise model effectiveness. Early detection enables proactive intervention and correction before quality issues become severe enough to require extensive remediation efforts.
Integration with MLOps and Data Pipeline Management
Modern machine learning operations require seamless integration of data quality assessment into automated pipelines that handle data ingestion, preprocessing, model training, and deployment. Quality gates within these pipelines automatically halt processing when quality metrics fall below acceptable thresholds, preventing poor-quality data from reaching production models. These automated checks must be carefully calibrated to avoid unnecessary pipeline failures while maintaining strict quality standards.
Quality metadata management systems track quality assessments alongside dataset versions, model experiments, and performance metrics, enabling comprehensive understanding of the relationship between data quality and model performance. This metadata integration supports root cause analysis when model performance degrades and facilitates decisions about when retraining or data remediation is necessary to maintain acceptable system performance.
Automated remediation systems can apply predefined correction strategies when specific quality issues are detected, such as imputing missing values, removing outliers, or applying data transformation techniques to address distributional problems. However, these automated corrections must be carefully designed and monitored to ensure they improve rather than degrade overall data quality, and they should typically be accompanied by alerts to human operators who can assess whether more comprehensive intervention is necessary.
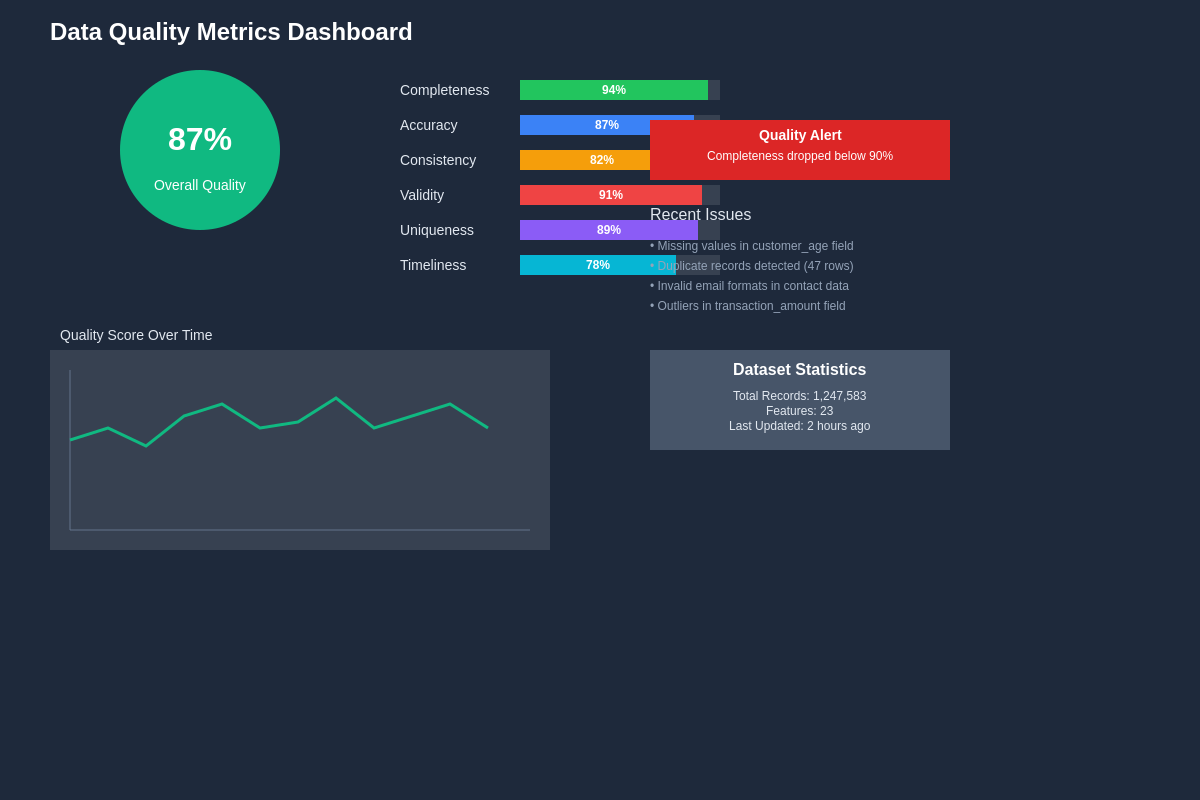
Effective data quality management requires comprehensive visualization and monitoring tools that provide both high-level overviews and detailed drill-down capabilities. Real-time dashboards enable data teams to quickly identify emerging quality issues and track the effectiveness of remediation efforts across multiple datasets and quality dimensions.
Advanced Techniques for Quality Assessment
Machine learning techniques are increasingly being applied to data quality assessment itself, creating sophisticated systems that can identify subtle quality problems that might escape traditional rule-based approaches. Anomaly detection algorithms trained on high-quality reference datasets can identify unusual patterns or outliers that indicate potential quality problems, while clustering techniques can reveal unexpected groupings in data that might indicate collection errors or processing problems.
Ensemble approaches that combine multiple quality assessment techniques often provide more robust and comprehensive evaluation than any single method alone. These ensemble systems can weight different assessment components based on their reliability and relevance for specific data types and applications, providing more nuanced and accurate quality evaluations than simple aggregation of individual metrics.
Deep learning approaches to quality assessment can identify complex patterns and relationships that indicate quality problems, particularly in high-dimensional data such as images, text, or time series. These approaches can learn from examples of high and low-quality data to develop more sophisticated quality assessment capabilities than traditional statistical methods, though they require careful validation to ensure they generalize appropriately to new datasets and scenarios.
Quality-Driven Model Development Strategies
The integration of quality assessment into model development workflows enables more informed decisions about data preprocessing, feature selection, and model architecture choices. Quality-aware preprocessing pipelines can apply different transformation strategies based on detected quality issues, such as more aggressive outlier removal for datasets with identified accuracy problems or specialized imputation techniques for datasets with systematic missingness patterns.
Feature selection processes that incorporate quality metrics can prioritize high-quality features while excluding or down-weighting features with identified quality problems. This quality-informed feature selection can improve model performance while reducing the risk of learning from corrupted or unreliable data sources. Similarly, model architecture choices can be influenced by quality assessments, with more robust architectures chosen for datasets with identified quality challenges.
Adaptive training strategies can adjust learning parameters, regularization techniques, and validation approaches based on quality assessments, providing more appropriate training procedures for datasets with specific quality characteristics. For example, datasets with identified bias problems might benefit from specialized fairness-aware training techniques, while datasets with temporal quality issues might require modified validation strategies that account for time-based quality variations.
Regulatory Compliance and Quality Documentation
Increasing regulatory attention to AI systems requires comprehensive documentation of data quality assessment processes and outcomes, particularly in regulated industries such as healthcare, finance, and transportation. Quality documentation must demonstrate that appropriate assessments were conducted, that identified issues were adequately addressed, and that ongoing monitoring systems are in place to detect emerging quality problems. This documentation serves both compliance and technical purposes, supporting audit processes while also facilitating debugging and improvement efforts.
Standardization efforts in data quality assessment are emerging to provide consistent frameworks and metrics across organizations and industries, facilitating comparison and benchmarking while reducing the burden of developing custom quality assessment systems. These standards typically specify required quality dimensions, recommended metrics, and documentation requirements that support both technical effectiveness and regulatory compliance.
Quality certification processes may eventually emerge that provide third-party validation of data quality assessment procedures and outcomes, similar to existing certification programs for software quality or security practices. Such certification could provide additional assurance for high-stakes AI applications while standardizing quality assessment practices across the industry.
Future Directions and Emerging Technologies
The field of data quality assessment continues to evolve rapidly, driven by advancing machine learning techniques, increasing dataset complexity, and growing awareness of the importance of quality for AI system reliability and fairness. Federated learning scenarios present new challenges for quality assessment, as data remains distributed across multiple organizations or devices, requiring new approaches for assessing quality without centralizing sensitive data.
Real-time quality assessment systems are becoming increasingly important as AI systems are deployed in dynamic environments where data characteristics can change rapidly. These systems must balance comprehensive quality evaluation with the performance requirements of real-time applications, leading to development of lightweight assessment techniques and adaptive sampling strategies that maintain quality monitoring capabilities while minimizing computational overhead.
Automated quality improvement systems represent the next frontier, moving beyond detection and assessment to automatically implement corrections and improvements that enhance dataset quality. These systems must be carefully designed to avoid introducing new problems while addressing identified quality issues, requiring sophisticated understanding of data relationships and quality interdependencies.
The integration of domain expertise into automated quality assessment systems promises to improve the relevance and accuracy of quality evaluations by incorporating specialized knowledge about specific application areas, data types, and quality requirements. This integration might involve expert systems, knowledge graphs, or hybrid human-AI approaches that combine automated assessment capabilities with human expertise and judgment.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. Data quality assessment requirements vary significantly across different applications, industries, and regulatory environments. Readers should consult with qualified data scientists, domain experts, and legal advisors when implementing data quality assessment systems for specific applications. The effectiveness of quality assessment techniques depends on proper implementation, appropriate calibration, and ongoing maintenance and monitoring.