
The foundation of every successful artificial intelligence and machine learning initiative lies not in sophisticated algorithms or cutting-edge hardware, but in the quality and strategic management of data that powers these systems. In an era where organizations across industries are racing to implement AI-driven solutions, the distinction between success and failure increasingly depends on how effectively they can collect, curate, and maintain high-quality datasets that serve as the bedrock for intelligent systems.
Discover the latest AI trends and methodologies that are shaping how organizations approach data strategy and machine learning implementation. The strategic importance of data in AI development cannot be overstated, as even the most advanced machine learning models will fail to deliver meaningful results when trained on poor-quality, biased, or inadequately structured datasets.
The Strategic Foundation of AI Data Management
Building a comprehensive data strategy for artificial intelligence requires a fundamental shift in how organizations perceive and manage their information assets. Unlike traditional data management approaches that focus primarily on storage and retrieval, AI-centric data strategies demand rigorous attention to data quality, consistency, representativeness, and ethical considerations that directly impact model performance and business outcomes.
The strategic framework for AI data management encompasses multiple dimensions including data acquisition methodologies, quality assurance protocols, privacy and compliance requirements, and long-term sustainability planning. Organizations must develop systematic approaches to identify relevant data sources, establish collection processes that maintain consistency over time, and implement validation mechanisms that ensure data integrity throughout the machine learning pipeline. This comprehensive approach requires coordination across multiple departments, from IT and data engineering teams to domain experts and compliance officers who collectively contribute to the creation of robust data ecosystems.
Modern AI data strategies also recognize the dynamic nature of machine learning requirements, where data needs evolve continuously as models are refined, new use cases emerge, and business objectives shift. This necessitates flexible data architectures that can adapt to changing requirements while maintaining the quality and governance standards essential for reliable AI performance. Organizations that successfully navigate this complexity typically invest significant resources in developing standardized processes, automated quality monitoring systems, and cross-functional teams dedicated to data stewardship and AI enablement.
Establishing Data Quality Standards and Metrics
The development of robust data quality standards represents one of the most critical components of any successful AI data strategy. Quality in the context of machine learning extends far beyond traditional metrics such as completeness and accuracy to encompass more nuanced characteristics including representativeness, consistency across different data sources, temporal stability, and freedom from various forms of bias that can compromise model performance and fairness.
Establishing comprehensive quality metrics requires deep understanding of both the intended use cases for the AI system and the potential failure modes that could arise from poor data quality. Organizations must develop systematic approaches to measuring data completeness across all relevant features, assessing the accuracy of labeled data through multiple validation techniques, and evaluating the representativeness of datasets relative to the target population or problem domain. These metrics must be continuously monitored and updated as new data is acquired and as understanding of the problem space evolves.
Enhance your AI capabilities with advanced tools like Claude that can assist in data analysis, quality assessment, and strategic planning for machine learning initiatives. The implementation of quality standards also requires sophisticated monitoring systems that can detect anomalies, identify drift in data distributions, and alert stakeholders to potential issues before they impact model performance. These systems must be designed to operate at scale, handling large volumes of data while maintaining sensitivity to subtle quality degradation that might not be immediately apparent through simple statistical measures.
Data Collection Strategies and Source Diversification
Effective data collection for AI systems requires strategic thinking about source diversity, collection methodologies, and long-term sustainability of data acquisition processes. Organizations must balance the need for large volumes of training data with requirements for quality, relevance, and ethical compliance, often necessitating complex trade-offs between different collection approaches and data sources.
The most successful AI data strategies typically incorporate multiple data collection methodologies, ranging from automated sensor data acquisition and web scraping to structured data exports from enterprise systems and carefully designed human annotation processes. Each collection method introduces unique quality challenges and bias risks that must be understood and mitigated through appropriate validation and preprocessing techniques. Organizations must also consider the temporal aspects of data collection, ensuring that datasets capture sufficient historical variation to enable robust model training while remaining current enough to reflect contemporary conditions and user behaviors.
Strategic data collection also involves careful consideration of external data sources, partnerships with other organizations, and potential acquisition of third-party datasets that can supplement internally generated information. These external sources can provide valuable diversity and scale but require rigorous evaluation to ensure compatibility with internal quality standards and compliance requirements. Organizations must develop systematic processes for evaluating potential data partnerships, negotiating appropriate usage rights, and integrating external data sources into their existing data management infrastructure.
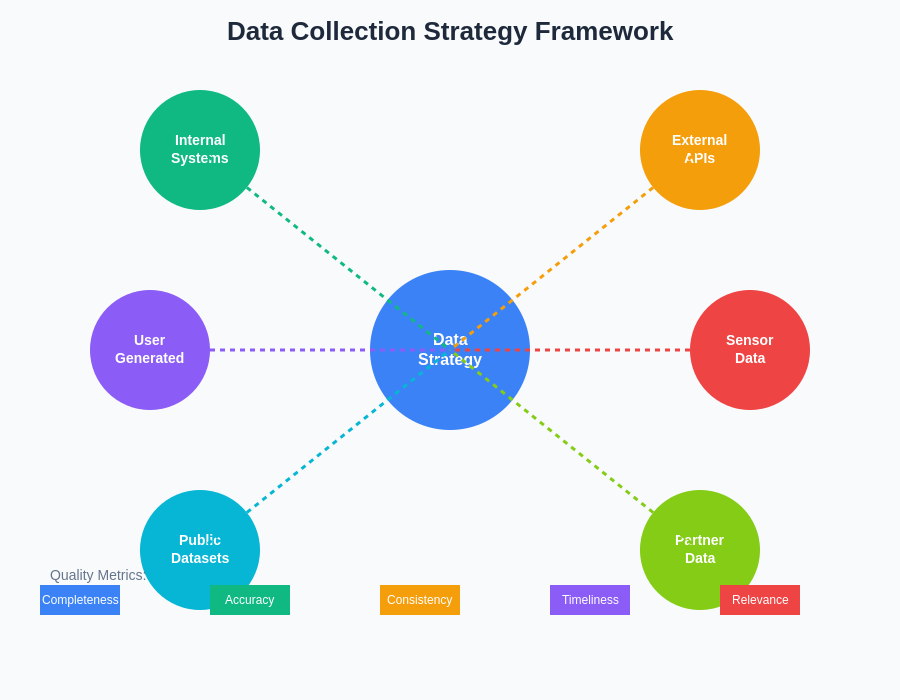
The framework for strategic data collection encompasses multiple interconnected components that must work together to ensure comprehensive coverage of the problem space while maintaining quality and compliance standards. This systematic approach enables organizations to build robust datasets that support reliable model training and deployment across diverse use cases and operational environments.
Data Preprocessing and Feature Engineering Excellence
The transformation of raw data into high-quality features suitable for machine learning represents a critical phase where strategic thinking and technical expertise must converge to maximize the value of collected datasets. Effective preprocessing strategies go beyond simple data cleaning to encompass sophisticated transformation techniques, feature selection methodologies, and encoding approaches that preserve essential information while removing noise and irrelevant variations that could compromise model performance.
Strategic preprocessing begins with comprehensive exploratory data analysis that reveals patterns, anomalies, and relationships within the dataset that inform subsequent transformation decisions. This analysis must consider not only statistical properties of individual features but also complex interactions between variables, temporal dependencies, and domain-specific constraints that influence how data should be processed and structured for optimal machine learning performance.
The feature engineering process requires deep collaboration between domain experts who understand the business context and data scientists who possess the technical skills to implement sophisticated transformation techniques. This collaboration is essential for developing features that capture relevant business logic while remaining interpretable and maintainable over time. Organizations must also establish systematic approaches to feature validation, ensuring that engineered features actually improve model performance and align with business objectives rather than simply increasing dataset complexity.
Advanced preprocessing strategies also incorporate considerations of model interpretability, computational efficiency, and deployment constraints that influence how features should be designed and implemented. Features that perform well during training may prove problematic in production environments due to latency requirements, data availability constraints, or interpretability needs that were not adequately considered during the development phase.
Addressing Bias and Ensuring Fairness in Datasets
The challenge of bias in machine learning datasets represents one of the most complex and critical aspects of AI data strategy, requiring systematic approaches to identification, measurement, and mitigation of various forms of bias that can compromise both model performance and ethical outcomes. Understanding bias in AI datasets extends beyond simple demographic considerations to encompass sampling bias, temporal bias, confirmation bias, and numerous other systematic distortions that can arise throughout the data collection and curation process.
Effective bias mitigation strategies require comprehensive auditing processes that examine datasets from multiple perspectives, utilizing both statistical techniques and domain expertise to identify potential sources of unfairness or systematic error. These audits must consider not only the representativeness of the dataset relative to the target population but also more subtle forms of bias such as measurement bias, where data collection processes themselves introduce systematic distortions that may not be immediately apparent through standard statistical analysis.
Leverage comprehensive research capabilities with Perplexity to stay informed about the latest developments in bias detection and fairness techniques for machine learning datasets. Organizations must also develop systematic approaches to bias correction that go beyond simple demographic balancing to address root causes of bias in data collection processes, feature selection methodologies, and labeling procedures.
The implementation of fairness constraints requires careful consideration of different definitions of fairness, which can sometimes conflict with each other or with traditional optimization objectives. Organizations must develop clear policies regarding acceptable trade-offs between different fairness metrics and establish governance processes that ensure these policies are consistently applied throughout the data pipeline and model development process.
Data Validation and Quality Assurance Processes
Comprehensive data validation represents a cornerstone of effective AI data strategy, requiring systematic processes that can detect quality issues, inconsistencies, and anomalies across large-scale datasets while maintaining the efficiency necessary for continuous data ingestion and model updates. Modern validation approaches combine automated statistical testing with domain-specific quality checks and human review processes that collectively ensure datasets meet the rigorous standards required for reliable machine learning performance.
Statistical validation techniques form the foundation of automated quality assurance, utilizing methods such as distribution analysis, outlier detection, correlation testing, and temporal consistency checks to identify potential data quality issues. These techniques must be carefully calibrated to distinguish between legitimate variations in the data and genuine quality problems, requiring sophisticated threshold setting and adaptive monitoring that can evolve with changing data characteristics over time.
Domain-specific validation requires deep understanding of the business context and problem domain, enabling the detection of quality issues that may not be apparent through purely statistical approaches. This includes logical consistency checks, business rule validation, and expert review processes that ensure data makes sense from a domain perspective and aligns with known constraints and relationships within the problem space.
The integration of human review processes into automated validation workflows represents a critical component of comprehensive quality assurance, particularly for complex domains where automated techniques may miss subtle quality issues or where human judgment is required to assess the appropriateness of edge cases and unusual observations.
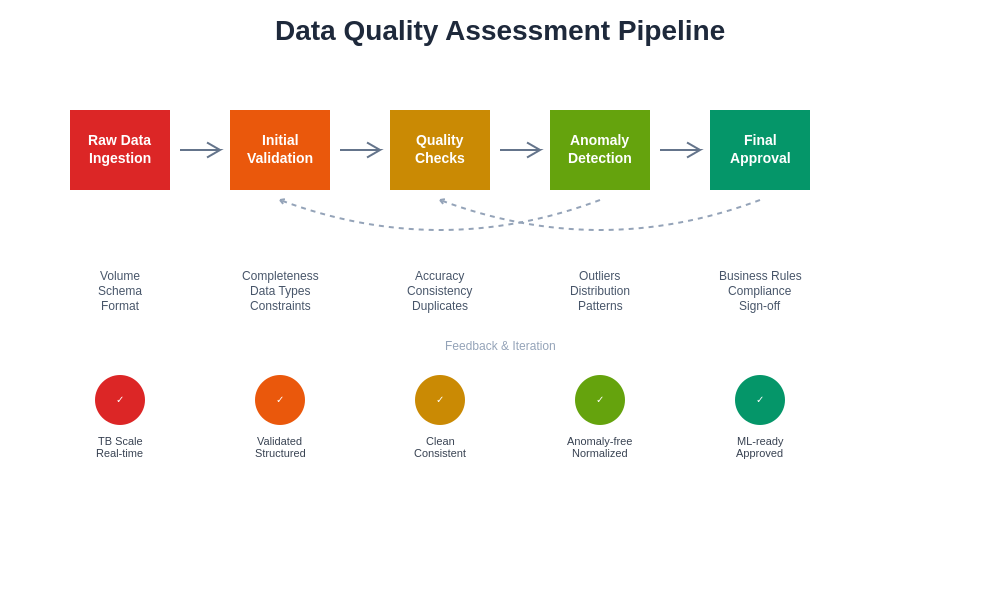
The systematic approach to data quality assessment involves multiple layers of validation that work together to ensure comprehensive coverage of potential quality issues while maintaining efficiency and scalability for large-scale data processing operations.
Scalable Data Infrastructure and Architecture
The technical infrastructure supporting AI data strategies must be designed to handle the unique requirements of machine learning workloads, including high-volume data processing, complex transformation pipelines, versioning and reproducibility needs, and the ability to serve data efficiently to training and inference processes. Modern AI data architectures typically incorporate cloud-native technologies, distributed processing frameworks, and specialized storage systems optimized for the access patterns and performance requirements of machine learning applications.
Scalable data architecture begins with careful consideration of storage strategies that can accommodate the volume, velocity, and variety characteristics of AI datasets while providing the access performance required for efficient model training and deployment. This often involves hybrid approaches that combine different storage technologies, including object storage for raw data archives, distributed file systems for processing workloads, and specialized databases for structured data and metadata management.
The processing infrastructure must support complex data transformation pipelines that can handle both batch and streaming data processing requirements while maintaining data lineage tracking, quality monitoring, and error handling capabilities. Modern architectures typically leverage containerized processing frameworks, orchestration systems, and auto-scaling capabilities that can adapt to varying computational demands while maintaining cost efficiency and resource utilization optimization.
Data serving infrastructure represents another critical component, requiring systems that can efficiently deliver training data to machine learning frameworks while supporting the low-latency requirements of real-time inference applications. This often involves sophisticated caching strategies, data partitioning approaches, and content delivery optimizations that minimize the time required to access relevant data subsets.
Data Governance and Compliance Framework
Effective data governance for AI initiatives requires comprehensive frameworks that address privacy protection, regulatory compliance, audit trail maintenance, and access control while supporting the collaborative and iterative nature of machine learning development processes. These frameworks must balance the need for data accessibility and experimentation with requirements for security, privacy, and regulatory compliance that vary significantly across industries and jurisdictions.
Privacy protection in AI data strategies encompasses multiple dimensions including data anonymization, differential privacy techniques, federated learning approaches, and comprehensive consent management processes that ensure individual privacy rights are respected throughout the data lifecycle. Organizations must develop systematic approaches to privacy risk assessment that consider both direct identification risks and more subtle privacy vulnerabilities that can arise from sophisticated data analysis and model inference techniques.
Regulatory compliance requirements continue to evolve rapidly as governments and industry bodies develop new frameworks for AI governance and data protection. Organizations must establish flexible compliance processes that can adapt to changing regulatory requirements while maintaining the agility necessary for effective AI development and deployment. This often involves close collaboration with legal and compliance teams to develop data handling procedures that meet current requirements while remaining adaptable to future regulatory changes.
Access control and audit trail management represent critical operational components of data governance frameworks, requiring sophisticated identity management, role-based access control, and comprehensive logging systems that can track data usage, transformation, and access patterns throughout the organization. These systems must provide sufficient granularity to support detailed audit requirements while remaining manageable and efficient for day-to-day operations.
Continuous Improvement and Dataset Evolution
The dynamic nature of AI applications and business environments necessitates systematic approaches to dataset evolution and continuous improvement that can adapt to changing requirements, new data sources, and evolving understanding of the problem domain. Effective dataset management strategies recognize that initial data collection and curation efforts represent just the beginning of an ongoing process of refinement, expansion, and optimization that continues throughout the lifecycle of AI systems.
Continuous improvement processes begin with comprehensive monitoring systems that track model performance, data drift, and business outcomes to identify opportunities for dataset enhancement and optimization. These monitoring systems must be designed to detect both gradual changes in data characteristics and sudden shifts that could indicate fundamental changes in the underlying problem domain or data generating processes.
Dataset evolution strategies must also incorporate systematic approaches to incorporating new data sources, updating existing data collection processes, and retiring outdated or irrelevant information that no longer contributes to model performance or business objectives. This requires sophisticated change management processes that can assess the impact of dataset modifications on existing models while ensuring that changes support long-term strategic objectives.
The integration of feedback loops from model performance, user interactions, and business outcomes represents a critical component of continuous improvement efforts, enabling organizations to identify specific areas where dataset enhancements could deliver the greatest impact on overall system performance and business value.
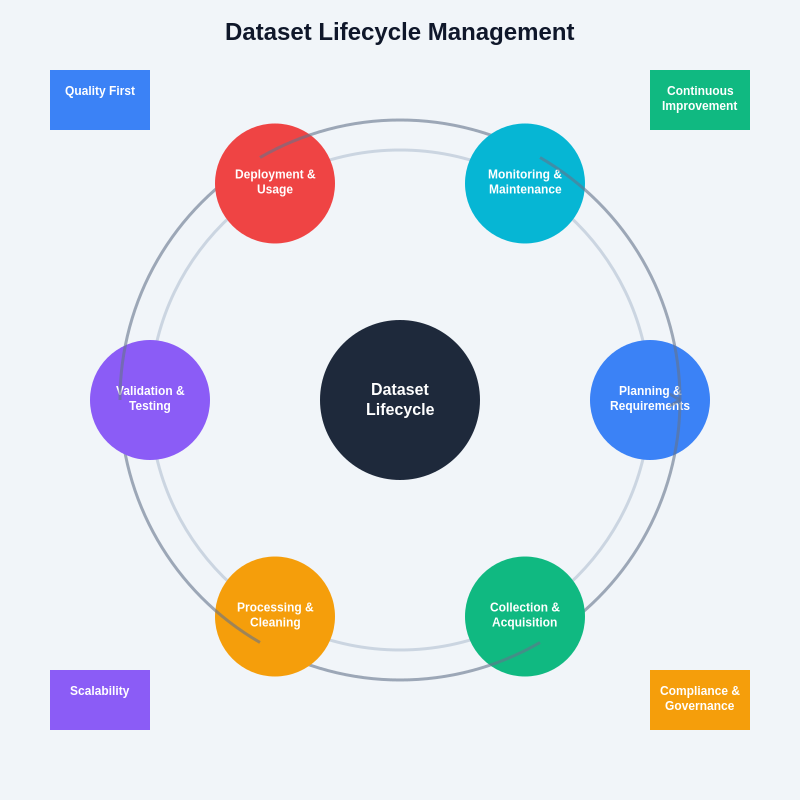
The comprehensive approach to dataset lifecycle management encompasses all phases from initial collection through continuous improvement, ensuring that data assets remain valuable and relevant throughout their operational lifetime while supporting evolving business requirements and technological capabilities.
Advanced Analytics and Data Science Integration
The integration of advanced analytics capabilities into AI data strategies enables organizations to extract maximum value from their datasets while supporting sophisticated model development and deployment processes. This integration requires careful coordination between data engineering teams responsible for data infrastructure and data scientists focused on model development and analysis, ensuring that technical capabilities align with analytical requirements and business objectives.
Advanced analytics integration encompasses multiple dimensions including statistical analysis, predictive modeling, anomaly detection, and pattern recognition techniques that can enhance both data quality assessment and feature engineering processes. These analytical capabilities must be embedded throughout the data pipeline, providing continuous insights into data characteristics, quality trends, and potential optimization opportunities.
The implementation of automated analytics processes enables organizations to scale their data science capabilities while maintaining consistency and quality in analytical outputs. This often involves the development of standardized analytical workflows, reusable analysis templates, and automated reporting systems that can provide regular insights into dataset characteristics and quality metrics without requiring manual intervention for routine assessments.
Integration with machine learning development workflows represents another critical aspect, requiring data platforms that can efficiently support model training, validation, and deployment processes while maintaining the data lineage and reproducibility requirements essential for reliable AI system development.
Economic Considerations and ROI Optimization
The economic aspects of AI data strategies require careful consideration of both direct costs associated with data collection, storage, and processing, and indirect costs related to quality assurance, governance, and opportunity costs associated with delayed or suboptimal implementations. Organizations must develop comprehensive cost models that account for all aspects of data strategy implementation while providing clear visibility into the return on investment generated by high-quality data assets.
Direct cost optimization involves strategic decisions about data collection methodologies, infrastructure investments, and processing approaches that balance cost efficiency with quality requirements and performance objectives. This often requires sophisticated analysis of different sourcing options, technology alternatives, and operational approaches to identify the most cost-effective solutions for specific use cases and organizational constraints.
The economic value of data quality improvements can be significant but is often difficult to quantify directly, requiring organizations to develop measurement frameworks that can track the business impact of data strategy investments. This includes metrics related to model performance improvements, reduced development time, decreased operational costs, and enhanced business outcomes that result from higher-quality datasets and more effective data management processes.
Long-term economic planning for data strategies must also consider the evolving nature of data requirements, technology costs, and business objectives, requiring flexible approaches that can adapt to changing conditions while maintaining cost efficiency and return on investment optimization.
Future Trends and Strategic Planning
The rapidly evolving landscape of artificial intelligence and data science continues to introduce new technologies, methodologies, and best practices that influence how organizations should approach their data strategies for AI initiatives. Staying ahead of these trends requires systematic monitoring of technological developments, industry practices, and regulatory changes that could impact data strategy effectiveness and competitiveness.
Emerging technologies such as automated machine learning, federated learning, synthetic data generation, and advanced privacy-preserving techniques are reshaping how organizations can collect, process, and utilize data for AI applications. Strategic planning processes must consider how these technologies might influence future data requirements and capabilities while maintaining focus on current operational needs and immediate business objectives.
The increasing sophistication of AI applications is also driving demand for more specialized and higher-quality datasets, requiring organizations to continuously evolve their data collection and curation capabilities to support advanced use cases such as multimodal learning, transfer learning, and few-shot learning scenarios that were not previously feasible or practical.
Strategic planning for AI data initiatives must also consider the growing importance of ethical AI and responsible machine learning practices, which are influencing how organizations approach data collection, bias mitigation, and fairness considerations throughout their AI development processes.
Building effective data strategies for artificial intelligence requires a comprehensive approach that integrates technical excellence with strategic business thinking, ethical considerations, and long-term sustainability planning. Organizations that successfully navigate this complexity typically invest significant resources in developing standardized processes, cross-functional expertise, and flexible infrastructure that can adapt to evolving requirements while maintaining the quality and governance standards essential for reliable AI performance. The future success of AI initiatives will increasingly depend on the quality and strategic management of the data assets that power these systems, making data strategy a critical competitive differentiator for organizations across all industries.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The strategies and approaches discussed should be adapted to specific organizational requirements, regulatory environments, and technical constraints. Readers should consult with qualified data science and legal professionals when implementing AI data strategies. The effectiveness of data strategies may vary significantly depending on specific use cases, industry requirements, and organizational capabilities.