In the rapidly evolving landscape of artificial intelligence and machine learning, maintaining consistent datasets across multiple systems has emerged as one of the most critical challenges facing data engineers and AI practitioners. As organizations increasingly deploy AI models across distributed environments, from cloud platforms to edge devices, the complexity of ensuring data coherence and consistency has grown exponentially. The success of AI initiatives fundamentally depends on the reliability and accuracy of the underlying data, making robust synchronization mechanisms not just a technical necessity but a strategic imperative for any serious AI deployment.
Stay updated with the latest AI infrastructure trends to understand how data synchronization challenges are evolving alongside advancing AI technologies. The intersection of distributed computing, real-time processing, and machine learning creates unique demands that traditional data management approaches often fail to address adequately.
Data synchronization in AI contexts extends far beyond simple data replication or backup strategies. It encompasses a comprehensive ecosystem of processes, protocols, and technologies designed to maintain data integrity, ensure temporal consistency, manage version control, and handle conflict resolution across heterogeneous computing environments. The stakes are particularly high in AI applications because inconsistent data can lead to model drift, degraded performance, biased outcomes, and ultimately, compromised decision-making processes that can have significant business and societal implications.
The Fundamental Challenge of Distributed AI Data
Modern AI systems rarely operate in isolation. They typically span multiple environments including cloud data lakes, on-premises servers, edge computing devices, mobile applications, and various third-party services. Each of these environments may have different data formats, processing capabilities, network constraints, and operational requirements. The challenge of maintaining consistency across such diverse systems is compounded by the dynamic nature of AI workloads, where datasets are continuously updated, models are retrained, and new data sources are integrated into existing pipelines.
The complexity increases further when considering the temporal aspects of AI data synchronization. Unlike traditional business applications where eventual consistency might be acceptable, many AI applications require near real-time data consistency to maintain model accuracy and performance. This requirement is particularly critical in scenarios such as fraud detection, autonomous systems, real-time recommendation engines, and dynamic pricing algorithms where outdated or inconsistent data can lead to incorrect decisions with immediate consequences.
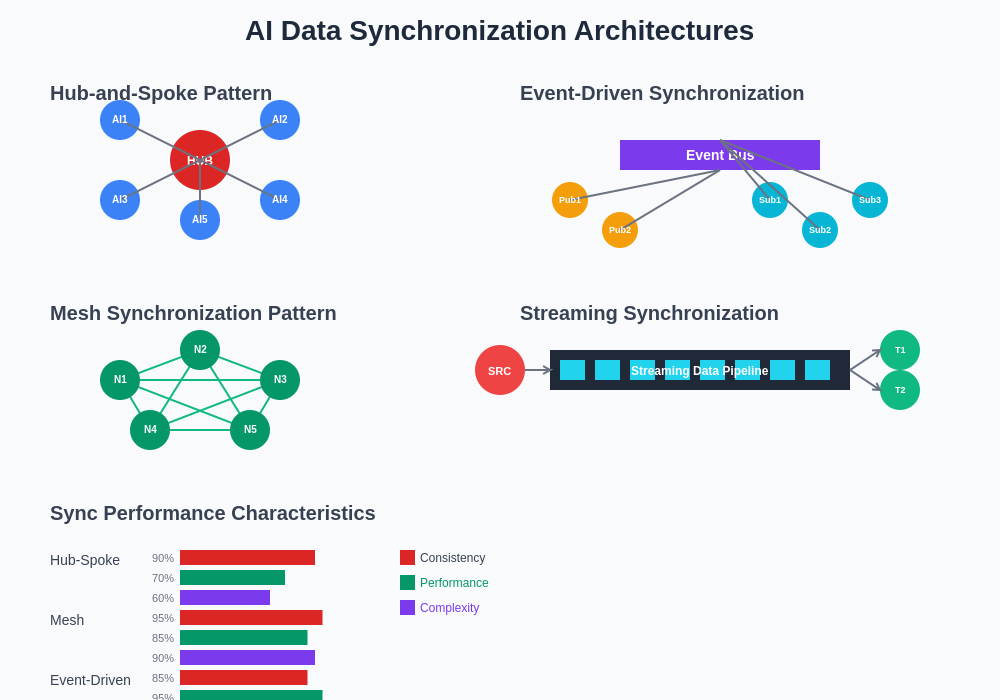
Understanding the various synchronization patterns available for AI systems is crucial for making informed architectural decisions. Each pattern offers distinct advantages and trade-offs in terms of consistency guarantees, performance characteristics, and implementation complexity that must be carefully evaluated against specific AI application requirements.
Furthermore, the scale of AI datasets presents unique synchronization challenges. Modern AI systems often work with petabytes of data, including structured databases, unstructured text, images, videos, and sensor data streams. Synchronizing such massive volumes of data across distributed systems while maintaining performance and cost efficiency requires sophisticated strategies that go far beyond traditional database synchronization techniques.
Architectural Patterns for AI Data Synchronization
Successful data synchronization in AI environments requires careful consideration of architectural patterns that can accommodate the unique requirements of machine learning workloads. The choice of architecture significantly impacts not only the technical implementation but also the operational complexity, maintenance overhead, and long-term scalability of AI systems.
Explore advanced AI development with Claude to understand how modern AI architectures handle complex data synchronization challenges through intelligent system design and automated management processes.
The hub-and-spoke pattern represents one of the most commonly implemented approaches for AI data synchronization. In this architecture, a central data hub serves as the authoritative source of truth, with various AI systems and applications connecting as spokes to receive synchronized data. This pattern offers several advantages including simplified conflict resolution, centralized data governance, and easier monitoring and auditing. However, it also introduces potential bottlenecks and single points of failure that must be carefully managed through redundancy and failover mechanisms.
Alternatively, the mesh synchronization pattern distributes synchronization responsibilities across multiple nodes, allowing for more resilient and scalable architectures. In this approach, each node can synchronize directly with others, creating a more fault-tolerant system that can continue operating even when individual nodes fail. The complexity of conflict resolution increases significantly in mesh architectures, but the improved reliability and performance characteristics often justify this additional complexity in large-scale AI deployments.
Event-driven synchronization architectures have gained particular traction in AI environments due to their ability to provide near real-time data consistency while maintaining system decoupling. In this pattern, data changes trigger events that propagate through the system, allowing various AI components to update their local datasets accordingly. This approach enables responsive AI systems that can adapt quickly to changing data conditions while maintaining consistency across distributed components.
Real-Time Synchronization Strategies
The demand for real-time AI capabilities has intensified the focus on synchronization strategies that can maintain data consistency with minimal latency. Real-time synchronization in AI contexts presents unique challenges because it must balance the need for immediate data availability with the computational overhead of continuous synchronization processes.
Streaming data synchronization has emerged as a preferred approach for many real-time AI applications. By treating data updates as continuous streams rather than discrete batch operations, organizations can achieve near real-time consistency across distributed AI systems. Technologies such as Apache Kafka, Apache Pulsar, and cloud-native streaming services provide the infrastructure necessary to implement robust streaming synchronization patterns that can handle the high-volume, high-velocity data requirements of modern AI applications.
Change data capture mechanisms represent another critical component of real-time synchronization strategies. These systems monitor data sources for changes and propagate updates to downstream AI systems with minimal delay. Advanced change data capture implementations can provide transaction-level consistency guarantees while maintaining high performance, ensuring that AI models always work with the most current data available.
The implementation of real-time synchronization requires careful consideration of network latency, bandwidth limitations, and processing overhead. Optimization strategies such as delta synchronization, where only changes are transmitted rather than complete datasets, can significantly improve performance and reduce network utilization. Additionally, intelligent caching and prefetching mechanisms can help maintain responsive AI system performance even in environments with challenging network conditions.
Conflict Resolution and Data Governance
In distributed AI environments, conflicts are inevitable. Different systems may attempt to update the same data simultaneously, network partitions may cause temporary inconsistencies, and various data sources may provide conflicting information. Robust conflict resolution mechanisms are essential for maintaining data integrity and ensuring reliable AI system operation.
Last-writer-wins strategies represent the simplest approach to conflict resolution, but they may not be appropriate for AI applications where data accuracy is critical. More sophisticated approaches include vector clocks and logical timestamps that can provide better ordering guarantees for conflicting updates. In AI contexts, domain-specific conflict resolution rules often prove most effective, incorporating business logic and data quality considerations into the resolution process.
Enhance your research capabilities with Perplexity to stay informed about emerging best practices in AI data governance and conflict resolution strategies that ensure robust and reliable AI system operation.
Data lineage tracking becomes particularly important in synchronized AI environments where data may flow through multiple systems and undergo various transformations. Comprehensive lineage tracking enables organizations to understand the provenance of their AI data, identify sources of inconsistencies, and implement targeted remediation strategies when synchronization issues arise. Modern data governance platforms integrate lineage tracking with synchronization monitoring to provide holistic visibility into data flow and consistency across AI systems.
Version control for AI datasets adds another layer of complexity to synchronization challenges. Unlike traditional software versioning, AI dataset versioning must account for the statistical properties of data, model compatibility requirements, and the impact of changes on model performance. Sophisticated versioning strategies can enable controlled rollbacks, A/B testing of different dataset versions, and gradual deployment of updated data across distributed AI systems.
Performance Optimization and Scalability
Achieving optimal performance in AI data synchronization requires a multi-faceted approach that addresses both technical and operational considerations. The scale and complexity of modern AI datasets demand synchronization solutions that can handle massive data volumes while maintaining acceptable performance characteristics across diverse computing environments.
Compression and encoding strategies play a crucial role in optimizing synchronization performance. Advanced compression algorithms specifically designed for AI data types can significantly reduce network bandwidth requirements and storage overhead. Specialized encoding techniques for different data modalities, such as image compression for computer vision applications or feature encoding for structured datasets, can provide additional performance benefits while preserving the information content necessary for AI model performance.
Intelligent scheduling and prioritization mechanisms help ensure that critical AI workloads receive the data synchronization resources they require. Priority-based synchronization can ensure that time-sensitive AI applications, such as fraud detection or autonomous systems, receive preferential treatment during periods of high synchronization load. Additionally, adaptive scheduling algorithms can dynamically adjust synchronization frequency based on data change rates, system load, and application requirements.
Caching strategies specifically designed for AI workloads can significantly improve synchronization performance and reduce system load. Multi-level caching architectures that account for the access patterns of AI applications can provide substantial performance improvements while reducing the bandwidth and computational resources required for continuous synchronization. Intelligent cache invalidation mechanisms ensure that cached data remains consistent with authoritative sources while minimizing unnecessary cache updates.
Monitoring and Observability
Effective monitoring and observability are essential for maintaining reliable AI data synchronization across distributed systems. The complexity of modern AI infrastructures requires comprehensive monitoring strategies that can provide visibility into synchronization performance, data consistency, and system health across all components of the AI ecosystem.
Real-time synchronization monitoring must track multiple dimensions of system performance including synchronization latency, data throughput, error rates, and consistency metrics. Advanced monitoring platforms provide dashboards and alerting mechanisms that enable operations teams to quickly identify and respond to synchronization issues before they impact AI system performance. Predictive monitoring capabilities can even anticipate synchronization problems based on historical patterns and system behavior.
Data quality monitoring represents a critical component of AI synchronization observability. Automated data quality checks can detect inconsistencies, anomalies, and corruption that may occur during synchronization processes. These monitoring systems can provide early warning of data quality issues that might otherwise go undetected until they impact AI model performance or decision-making processes.
Comprehensive logging and audit trails enable detailed forensic analysis of synchronization events and provide the visibility necessary for compliance and governance requirements. Modern logging systems can correlate synchronization events across multiple systems, providing end-to-end visibility into data flow and enabling rapid troubleshooting of complex synchronization issues.
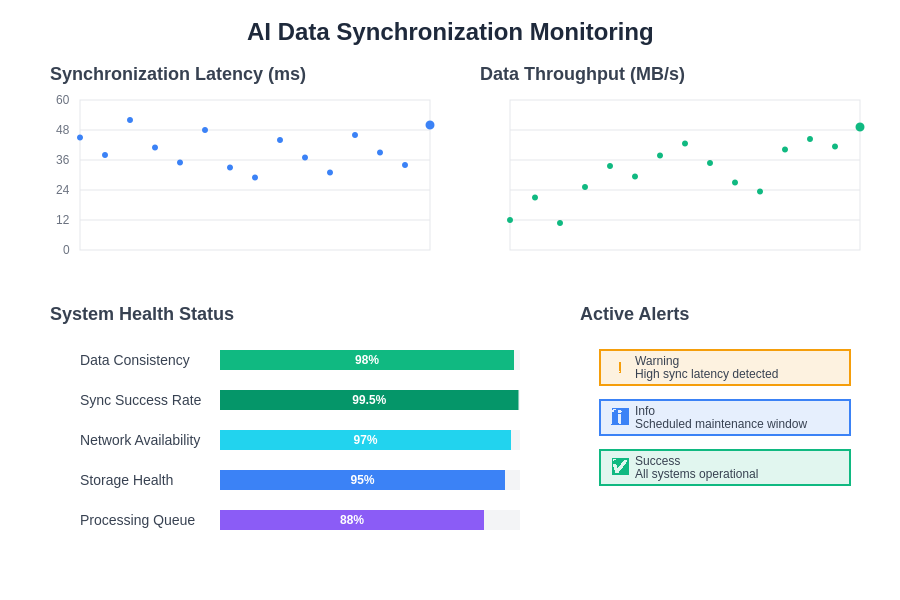
Effective monitoring of AI data synchronization requires comprehensive dashboards that track multiple performance dimensions including latency, throughput, system health, and alert status. Real-time visibility into these metrics enables proactive identification and resolution of synchronization issues before they impact AI system performance.
Security Considerations in AI Data Synchronization
Security represents a paramount concern in AI data synchronization, particularly as organizations increasingly work with sensitive personal data, proprietary algorithms, and critical business information. The distributed nature of AI systems creates multiple potential attack vectors that must be carefully addressed through comprehensive security strategies.
Encryption in transit and at rest provides fundamental protection for synchronized AI data. Advanced encryption schemes specifically designed for AI workloads can provide strong security guarantees while minimizing the performance impact of cryptographic operations. Key management becomes particularly complex in distributed AI environments, requiring robust systems that can securely distribute and rotate encryption keys across multiple systems and environments.
Access control and authentication mechanisms must account for the automated nature of AI data synchronization while maintaining security. Service-to-service authentication protocols, API key management, and role-based access control systems provide the security infrastructure necessary for automated synchronization processes. Advanced authentication mechanisms can also provide audit trails that track all data access and modification events across the synchronized AI ecosystem.
Data privacy and compliance considerations add additional layers of complexity to AI synchronization security. Regulations such as GDPR, CCPA, and industry-specific compliance requirements may impose restrictions on how AI data can be synchronized, stored, and processed across different jurisdictions and systems. Privacy-preserving synchronization techniques, such as differential privacy and federated learning approaches, can help organizations maintain compliance while enabling effective AI data synchronization.
Cloud-Native Synchronization Solutions
The adoption of cloud-native architectures has significantly influenced approaches to AI data synchronization, providing new tools and capabilities while introducing unique challenges related to multi-cloud and hybrid deployments. Cloud-native synchronization solutions offer several advantages including managed infrastructure, automatic scaling, and integrated security features.
Container orchestration platforms such as Kubernetes provide the foundation for deploying scalable AI data synchronization systems. Containerized synchronization services can automatically scale based on data volume and processing requirements, providing the flexibility necessary to handle varying AI workloads. Service mesh technologies add sophisticated communication and security capabilities to containerized synchronization architectures.
Serverless computing platforms enable event-driven synchronization architectures that can provide cost-effective solutions for AI data synchronization. Serverless functions can automatically trigger synchronization processes based on data changes, system events, or scheduled intervals, providing responsive synchronization capabilities without the overhead of maintaining dedicated infrastructure.
Multi-cloud synchronization strategies address the reality that many organizations deploy AI systems across multiple cloud providers and on-premises environments. Cross-cloud synchronization introduces additional complexity related to network connectivity, data transfer costs, and vendor-specific service integration, but it also provides important benefits including improved resilience, cost optimization, and avoidance of vendor lock-in.
Emerging Technologies and Future Trends
The landscape of AI data synchronization continues to evolve rapidly as new technologies and approaches emerge to address the growing complexity and scale of AI deployments. Understanding these emerging trends is crucial for organizations planning long-term AI infrastructure investments.
Blockchain and distributed ledger technologies offer potential solutions for maintaining authoritative records of AI data changes across distributed systems. While still in early stages of adoption, blockchain-based synchronization systems could provide immutable audit trails and decentralized consensus mechanisms that enhance data integrity and trust in AI systems.
Edge computing integration presents both opportunities and challenges for AI data synchronization. As more AI processing moves to edge devices, synchronization systems must accommodate the unique constraints of edge environments including limited bandwidth, intermittent connectivity, and resource constraints. Intelligent data reduction and edge-cloud synchronization strategies are emerging to address these challenges.
Artificial intelligence itself is being applied to optimize data synchronization processes. Machine learning algorithms can predict synchronization requirements, optimize network utilization, and automatically detect and resolve data inconsistencies. AI-driven synchronization systems promise to reduce operational overhead while improving performance and reliability.
The integration of AI data synchronization with broader DevOps and MLOps practices represents another important trend. Synchronized data management is becoming an integral part of continuous integration and deployment pipelines for AI applications, enabling more rapid and reliable deployment of AI models and updates.
Best Practices and Implementation Guidelines
Successful implementation of AI data synchronization requires adherence to established best practices while remaining flexible enough to accommodate the unique requirements of specific AI applications and environments. These guidelines provide a framework for designing and implementing robust synchronization solutions.
Start with comprehensive data modeling and architecture planning that accounts for the full lifecycle of AI data from ingestion through processing to archival. Understanding data relationships, access patterns, and consistency requirements early in the design process enables more effective synchronization strategies and reduces the risk of costly architectural changes later in the implementation process.
Implement incremental rollout strategies that allow for gradual deployment and testing of synchronization systems. Starting with non-critical workloads and gradually expanding to more sensitive applications provides opportunities to identify and resolve issues before they impact production AI systems. Comprehensive testing including load testing, failure scenario testing, and data consistency validation should be integral parts of the rollout process.
Establish clear operational procedures for monitoring, troubleshooting, and maintaining synchronization systems. Documentation of synchronization architectures, runbooks for common issues, and escalation procedures for critical problems ensure that operations teams can effectively maintain system reliability. Regular performance reviews and capacity planning help ensure that synchronization systems continue to meet requirements as AI workloads evolve and grow.
Invest in team training and capability development to ensure that technical staff have the knowledge and skills necessary to design, implement, and maintain sophisticated AI data synchronization systems. The rapidly evolving nature of AI technologies requires ongoing education and professional development to stay current with best practices and emerging technologies.
The future of AI depends fundamentally on our ability to maintain consistent, reliable, and secure data across increasingly complex distributed systems. Organizations that invest in robust data synchronization capabilities position themselves to take full advantage of AI technologies while avoiding the pitfalls of inconsistent or unreliable data. As AI continues to evolve and expand into new domains, the importance of sophisticated data synchronization will only continue to grow, making it an essential capability for any organization serious about AI success.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of AI technologies and data synchronization practices. Readers should conduct their own research and consider their specific requirements when implementing AI data synchronization solutions. The effectiveness and suitability of synchronization approaches may vary depending on specific use cases, technical requirements, and organizational constraints.