
The modern data landscape demands platforms that can seamlessly integrate traditional analytics with cutting-edge artificial intelligence and machine learning capabilities. As organizations increasingly recognize data as their most valuable asset, the choice between leading platforms becomes critical for long-term success. Two giants dominate this space: Databricks, with its unified analytics platform built for collaborative data science, and Snowflake, with its cloud-native data warehouse architecture designed for scalable analytics. Understanding the nuances, strengths, and limitations of each platform is essential for making informed decisions that will shape an organization’s data strategy for years to come.
Explore the latest AI development trends to understand how data platforms are evolving to support next-generation artificial intelligence applications. The convergence of data warehousing, data lakes, and machine learning platforms has created a complex ecosystem where the right choice can accelerate innovation while the wrong decision can create technical debt and operational challenges that persist for years.
Platform Philosophy and Architecture
The fundamental difference between Databricks and Snowflake lies in their architectural philosophy and original design intentions. Databricks emerged from the Apache Spark ecosystem with a primary focus on big data processing and machine learning workflows. The platform was conceived to address the complexity of distributed computing and make advanced analytics accessible to data scientists and engineers working with large-scale datasets. This heritage is evident in every aspect of Databricks’ design, from its notebook-centric interface to its deep integration with popular machine learning libraries and frameworks.
Snowflake, conversely, was built from the ground up as a cloud-native data warehouse designed to solve the scalability and performance limitations of traditional data warehousing solutions. The platform’s architecture separates compute from storage, enabling independent scaling of resources based on workload demands. This separation allows organizations to optimize costs while maintaining high performance for analytical workloads. Snowflake’s approach prioritizes ease of use, SQL compatibility, and seamless data sharing capabilities that make it particularly attractive for traditional business intelligence and reporting use cases.
The architectural differences between these platforms create distinct advantages for different types of workloads and organizational needs. Databricks excels in scenarios requiring complex data transformations, real-time processing, and advanced machine learning model development and deployment. The platform’s distributed computing capabilities and support for multiple programming languages make it ideal for data engineering tasks that involve processing diverse data sources and formats at scale.

The fundamental architectural approaches of these platforms reflect their different origins and design philosophies, with Databricks emphasizing distributed computing and collaborative development while Snowflake focuses on scalable cloud-native data warehousing with separated compute and storage layers.
Machine Learning and AI Capabilities
When evaluating AI-readiness, Databricks demonstrates clear advantages in machine learning model development, training, and deployment workflows. The platform provides native support for popular machine learning frameworks including TensorFlow, PyTorch, scikit-learn, and MLlib, along with comprehensive MLOps capabilities through MLflow. This integrated approach enables data scientists to manage the entire machine learning lifecycle from experimentation through production deployment within a single platform environment.
Discover advanced AI capabilities with Claude to enhance your data science workflows with intelligent coding assistance and comprehensive analytical support. Databricks’ strength in machine learning extends beyond basic model training to include advanced features such as automated machine learning, distributed hyperparameter tuning, and sophisticated model serving capabilities that can handle high-throughput inference workloads with low latency requirements.
Snowflake has made significant investments in AI and machine learning capabilities, but its approach differs fundamentally from Databricks’ comprehensive machine learning platform. Snowflake’s AI features focus primarily on SQL-based machine learning functions, automated insights generation, and integration with external machine learning platforms. The platform excels in scenarios where organizations need to apply machine learning to traditional business intelligence workloads or require simple predictive analytics that can be implemented using familiar SQL syntax.
The platform’s Snowpark feature represents a significant evolution in Snowflake’s machine learning capabilities, enabling data scientists to build and deploy machine learning models using Python, Scala, and Java directly within the Snowflake environment. This development bridges the gap between traditional SQL-based analytics and modern data science workflows, though it still lacks the comprehensive machine learning ecosystem that Databricks provides natively.
Data Processing and Performance Characteristics
Performance characteristics vary significantly between the platforms depending on workload types and data processing requirements. Databricks leverages Apache Spark’s distributed computing engine to provide exceptional performance for large-scale data processing, complex transformations, and iterative machine learning algorithms. The platform’s ability to process structured and unstructured data in batch and streaming modes makes it particularly well-suited for organizations dealing with diverse data sources and real-time processing requirements.
Snowflake’s performance strength lies in its optimized query engine and automatic performance tuning capabilities that deliver consistent performance for analytical workloads without requiring extensive optimization or tuning efforts. The platform’s virtual warehouse architecture enables automatic scaling and resource allocation based on query complexity and concurrency requirements. This approach significantly reduces the operational overhead associated with performance optimization while ensuring predictable query response times.
The choice between platforms often depends on the specific performance requirements and data processing patterns within an organization. Databricks excels in scenarios requiring complex data transformations, real-time processing, and machine learning workloads that benefit from distributed computing architectures. Organizations processing large volumes of streaming data or implementing complex ETL pipelines often find Databricks’ performance characteristics more suitable for their needs.
Cost Structure and Economic Considerations
Understanding the cost implications of each platform requires careful analysis of usage patterns, data volumes, and computational requirements. Databricks employs a consumption-based pricing model that charges for compute resources, storage, and platform features based on actual usage. This model can be cost-effective for organizations with variable workloads or those that can optimize resource utilization through careful workload management and scheduling.
Snowflake’s pricing model separates compute and storage costs, enabling organizations to optimize expenses by scaling resources independently based on specific requirements. The platform’s automatic scaling capabilities can help control costs by dynamically adjusting compute resources based on workload demands, though this automation requires careful monitoring to prevent unexpected cost escalation during peak usage periods.
Enhance your research capabilities with Perplexity for comprehensive cost analysis and platform comparison research that supports informed decision-making processes. The total cost of ownership for either platform extends beyond direct platform fees to include implementation costs, training expenses, and ongoing operational overhead that can vary significantly based on organizational requirements and existing technical capabilities.
Integration Ecosystem and Compatibility
The integration ecosystem surrounding each platform plays a crucial role in determining overall effectiveness and adoption within existing technology stacks. Databricks provides extensive integration capabilities with popular data sources, cloud services, and third-party tools commonly used in modern data engineering and machine learning workflows. The platform’s support for multiple programming languages and its compatibility with Apache Spark ecosystem tools make it highly flexible for organizations with diverse technical requirements.
Snowflake’s integration strength lies in its broad compatibility with business intelligence tools, data integration platforms, and cloud services across major cloud providers. The platform’s SQL-first approach ensures compatibility with existing reporting tools and makes it accessible to analysts and business users who are comfortable with traditional SQL-based workflows. Snowflake’s data sharing capabilities enable secure collaboration between organizations without requiring complex data movement or replication processes.
Both platforms offer robust APIs and connector libraries that facilitate integration with custom applications and specialized tools. However, the choice between platforms often depends on the specific tools and technologies already deployed within an organization’s existing technology stack and the level of integration complexity required for specific use cases.
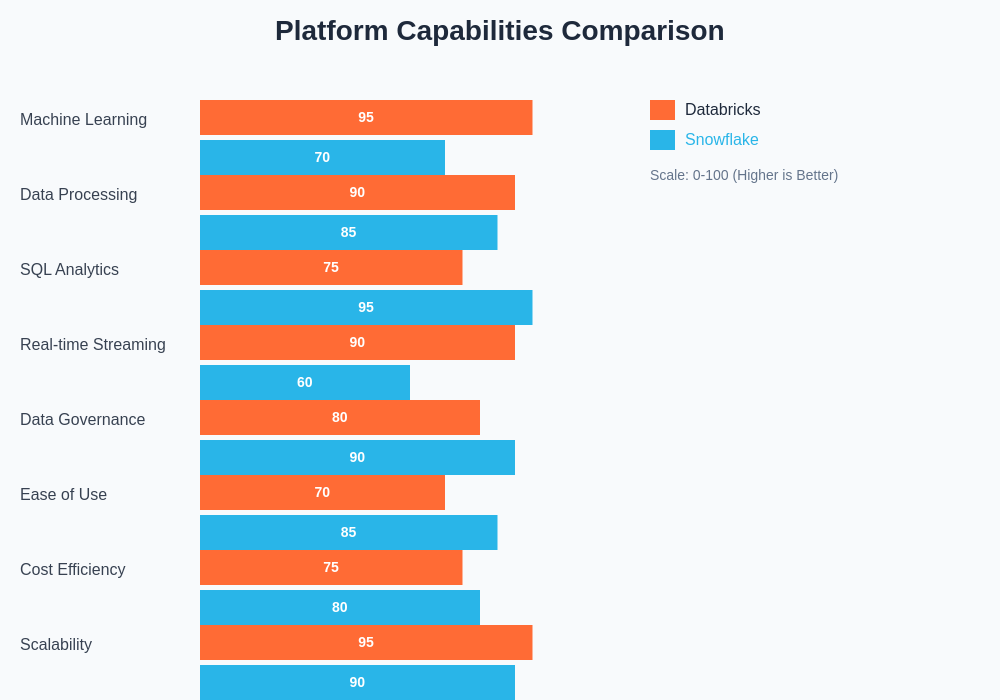
The comprehensive capability assessment reveals distinct strengths for each platform, with Databricks excelling in machine learning and real-time processing capabilities while Snowflake demonstrates superior performance in SQL analytics and ease of use metrics that appeal to traditional business intelligence teams.
Security and Governance Features
Enterprise-grade security and governance capabilities are essential considerations for organizations handling sensitive data and operating in regulated industries. Databricks provides comprehensive security features including encryption at rest and in transit, fine-grained access controls, and audit logging capabilities that meet enterprise security requirements. The platform’s integration with cloud provider security services enables organizations to leverage existing security infrastructure and maintain consistent security policies across their data ecosystem.
Snowflake’s security architecture includes advanced features such as end-to-end encryption, multi-factor authentication, and network policies that provide robust protection for sensitive data. The platform’s built-in governance features include comprehensive audit trails, data lineage tracking, and privacy controls that help organizations maintain compliance with regulatory requirements and internal data governance policies.
Both platforms continue to evolve their security and governance capabilities in response to changing regulatory requirements and emerging security threats. The choice between platforms often depends on specific compliance requirements, existing security infrastructure, and the level of security customization required for particular organizational needs.
Scalability and Enterprise Readiness
Scalability characteristics differ significantly between the platforms based on their underlying architectural approaches and design philosophies. Databricks’ distributed computing architecture enables horizontal scaling that can handle massive datasets and complex computational workloads across hundreds or thousands of nodes. This scalability makes it particularly suitable for organizations processing petabyte-scale datasets or implementing computationally intensive machine learning algorithms that require significant parallel processing capabilities.
Snowflake’s scalability approach focuses on elastic scaling of compute resources through its virtual warehouse architecture, enabling organizations to handle varying workloads without manual intervention or complex configuration changes. The platform’s ability to automatically scale compute resources based on query complexity and concurrency requirements provides predictable performance characteristics that many enterprises find appealing for production analytical workloads.
Enterprise readiness encompasses factors beyond raw scalability including operational maturity, support quality, and ecosystem stability. Both platforms have demonstrated enterprise-grade capabilities through extensive customer deployments and continue to invest in operational excellence and customer support infrastructure that meets the demands of large-scale enterprise deployments.
Development Experience and User Interface
The development experience and user interface design philosophy create distinct user experiences that appeal to different types of users and organizational cultures. Databricks provides a notebook-centric development environment that supports collaborative data science workflows and enables seamless integration of code, visualizations, and documentation within a single interface. This approach appeals particularly to data scientists and engineers who value flexibility and the ability to combine multiple programming languages and tools within their development workflow.
Snowflake’s user experience emphasizes SQL-first development with a web-based interface that provides familiar database administration and query development capabilities. The platform’s approach makes it accessible to traditional database administrators and business analysts who prefer SQL-based development workflows. Recent additions including Snowpark have expanded the platform’s development capabilities while maintaining the SQL-centric user experience that many organizations value.
The choice between development environments often reflects organizational culture and the technical background of primary platform users. Organizations with strong data science teams may prefer Databricks’ flexible notebook environment, while those with traditional business intelligence teams might find Snowflake’s SQL-first approach more intuitive and productive.
Real-Time Processing and Streaming Capabilities
Real-time data processing capabilities have become increasingly important as organizations seek to derive immediate insights from streaming data sources and implement real-time decision-making systems. Databricks provides comprehensive streaming capabilities through Structured Streaming, enabling organizations to process and analyze continuous data streams with the same APIs used for batch processing. This unified approach simplifies the development and maintenance of streaming applications while providing the performance characteristics required for low-latency processing requirements.
Snowflake’s approach to real-time processing focuses primarily on near-real-time analytics through features such as Snowpipe for continuous data ingestion and Dynamic Tables for incrementally updated datasets. While these capabilities support many real-time use cases, they may not provide the sub-second latency requirements needed for applications requiring immediate response to streaming data events.
Organizations implementing Internet of Things solutions, fraud detection systems, or real-time recommendation engines often find Databricks’ streaming capabilities more suitable for their requirements, while those focused on business intelligence and reporting applications may find Snowflake’s near-real-time capabilities sufficient for their needs.
Vendor Lock-in and Platform Independence
Considerations around vendor lock-in and platform independence have become increasingly important as organizations seek to maintain flexibility and avoid dependence on single technology providers. Databricks’ foundation on open-source Apache Spark provides a degree of platform independence, as applications developed on Databricks can potentially be migrated to other Spark-based platforms or run on self-managed Spark clusters. However, platform-specific features and optimizations may create dependencies that complicate migration efforts.
Snowflake’s proprietary architecture and SQL dialect create stronger platform dependencies, though the platform’s broad ecosystem of integration tools and standard SQL compatibility help mitigate some lock-in concerns. Organizations can often migrate data and many analytical workloads to alternative platforms, though complex applications leveraging Snowflake-specific features may require significant modification during migration processes.
The practical impact of vendor lock-in varies significantly based on organizational requirements, technical capabilities, and strategic priorities. Some organizations prioritize platform independence and open standards, while others are willing to accept platform dependencies in exchange for improved functionality, performance, or operational simplicity.
Industry-Specific Considerations and Use Cases
Different industries and use cases may favor one platform over another based on specific requirements, regulatory constraints, and operational characteristics. Financial services organizations often prefer platforms with strong compliance capabilities, real-time processing features, and robust security controls that support fraud detection and risk management applications. Healthcare organizations may prioritize platforms with comprehensive privacy controls, audit capabilities, and the ability to process diverse data types including unstructured clinical data.
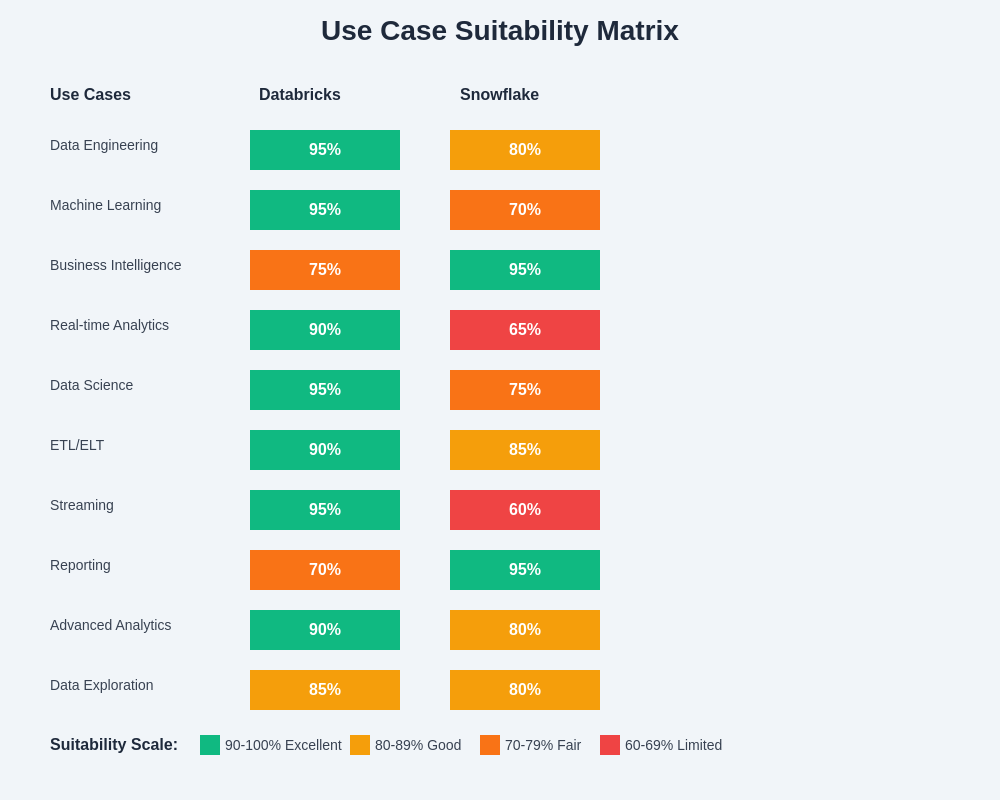
The use case suitability analysis demonstrates clear patterns in platform strengths, with Databricks showing exceptional performance for data engineering, machine learning, and streaming applications while Snowflake excels in business intelligence, reporting, and traditional analytical workloads.
Retail and e-commerce companies frequently require platforms that can handle high-velocity transaction data, support real-time recommendation systems, and provide the analytical capabilities needed for dynamic pricing and inventory optimization. Manufacturing organizations may prioritize platforms that excel at processing sensor data, support predictive maintenance applications, and provide the machine learning capabilities needed for quality control and process optimization.
The choice between platforms often depends on the specific combination of requirements within an organization’s primary use cases and the relative importance of different platform capabilities. Organizations should carefully evaluate how each platform addresses their specific industry requirements and strategic objectives rather than relying solely on general platform comparisons.
Future Roadmap and Strategic Direction
Understanding the strategic direction and future roadmap of each platform provides valuable insight into long-term viability and alignment with organizational objectives. Databricks continues to invest heavily in machine learning and AI capabilities, with significant focus on large language models, automated machine learning, and MLOps features that support the complete machine learning lifecycle. The platform’s roadmap emphasizes deeper integration with cloud services and continued innovation in distributed computing and real-time processing capabilities.
Snowflake’s strategic direction focuses on expanding beyond traditional data warehousing to become a comprehensive data platform that supports diverse analytical workloads. The platform continues to invest in machine learning capabilities, application development features, and data sharing functionality that enables new business models and collaborative analytics approaches. Snowflake’s roadmap includes significant investments in performance optimization and cost management features that address common customer concerns.
Both platforms demonstrate strong commitment to innovation and continue to evolve rapidly in response to changing market requirements and customer feedback. Organizations should consider not only current platform capabilities but also the alignment between platform roadmaps and their own strategic objectives when making long-term platform decisions.
The competitive landscape in data platforms continues to evolve rapidly, with both vendors and emerging competitors introducing new capabilities and approaches that may impact future platform selection decisions. Organizations should maintain awareness of industry trends and emerging technologies that could influence their platform strategy over time.
Decision Framework and Selection Criteria
Developing a systematic approach to platform evaluation requires consideration of multiple factors including technical requirements, organizational capabilities, budget constraints, and strategic objectives. Organizations should begin by clearly defining their primary use cases and identifying the most critical platform capabilities needed to support those use cases effectively. This requirements analysis should consider both current needs and anticipated future requirements based on organizational growth and strategic plans.
Technical evaluation should include performance testing with representative datasets and workloads, assessment of integration capabilities with existing systems, and evaluation of development productivity using realistic scenarios. Organizations should also consider the learning curve and training requirements associated with each platform, particularly for teams with existing skills in specific technologies or methodologies.
Economic analysis should extend beyond direct platform costs to include implementation expenses, training costs, operational overhead, and the potential impact of improved productivity or capabilities on business outcomes. Organizations should develop total cost of ownership models that account for all relevant factors over the expected platform lifespan.
The selection process should involve stakeholders from multiple organizational functions including data engineering, data science, business intelligence, and business leadership to ensure that platform capabilities align with diverse organizational needs and objectives. This collaborative approach helps identify potential issues and ensures broad organizational support for the selected platform.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on publicly available information about Databricks and Snowflake platforms and their capabilities. Readers should conduct their own thorough evaluation and consider their specific requirements when selecting data platforms. Platform capabilities, pricing, and features may change over time, and organizations should verify current information directly with vendors before making decisions. The effectiveness of either platform may vary depending on specific use cases, data characteristics, and organizational requirements.