
The proliferation of artificial intelligence systems across industries has created unprecedented opportunities for innovation and efficiency, but it has also raised critical concerns about user privacy and data protection. As organizations increasingly rely on vast datasets to train sophisticated machine learning models, the challenge of preserving individual privacy while maintaining the utility of AI systems has become paramount. Differential privacy emerges as a mathematical framework that addresses this fundamental tension, offering a rigorous approach to protecting user data while enabling meaningful statistical analysis and machine learning applications.
Stay updated with the latest AI privacy developments to understand how emerging technologies are addressing data protection challenges in modern AI systems. The implementation of differential privacy represents a crucial step toward building trustworthy AI systems that can operate effectively while respecting user privacy and complying with increasingly stringent data protection regulations worldwide.
Understanding the Privacy Challenge in AI Systems
Modern artificial intelligence systems depend heavily on large datasets that often contain sensitive personal information, creating inherent privacy risks that traditional anonymization techniques fail to adequately address. The conventional approach of removing personally identifiable information from datasets has proven insufficient against sophisticated re-identification attacks, where adversaries can combine anonymized data with auxiliary information to reveal individual identities and sensitive attributes. This vulnerability has been demonstrated repeatedly in academic research and real-world scenarios, highlighting the urgent need for more robust privacy protection mechanisms.
The challenge becomes particularly acute in machine learning contexts where models can inadvertently memorize and leak information about their training data. Recent research has shown that neural networks can be vulnerable to membership inference attacks, where adversaries can determine whether a specific individual’s data was used to train a model, and model inversion attacks, where sensitive attributes of training data can be reconstructed from model outputs. These privacy vulnerabilities underscore the importance of implementing privacy-preserving techniques that provide mathematical guarantees rather than relying on ad-hoc anonymization methods.
The Mathematical Foundation of Differential Privacy
Differential privacy provides a mathematically rigorous definition of privacy that quantifies the maximum amount of information that can be learned about any individual from the output of a randomized algorithm. The fundamental principle underlying differential privacy is that the presence or absence of any single individual’s data should not significantly affect the probability distribution of the algorithm’s output, thereby ensuring that participation in a dataset does not substantially increase an individual’s privacy risk.
The formal definition of differential privacy involves the concept of epsilon-differential privacy, where epsilon represents the privacy budget that controls the trade-off between privacy protection and data utility. A smaller epsilon value provides stronger privacy guarantees but may reduce the accuracy of statistical queries or machine learning models, while a larger epsilon allows for more accurate results at the cost of weaker privacy protection. This mathematical formulation enables organizations to make informed decisions about privacy-utility trade-offs based on their specific requirements and risk tolerance.
Explore advanced AI privacy solutions with Claude to understand how cutting-edge AI assistants can help implement privacy-preserving techniques in your data analysis workflows. The mathematical rigor of differential privacy provides a solid foundation for building AI systems that can be trusted with sensitive data while delivering meaningful insights and predictions.
Implementation Mechanisms and Techniques
The practical implementation of differential privacy relies on carefully designed noise addition mechanisms that introduce controlled randomness into data analysis processes. The most common approach is the Laplace mechanism, which adds noise drawn from a Laplace distribution to the output of deterministic functions, with the magnitude of noise calibrated to the sensitivity of the function and the desired privacy level. This technique is particularly effective for numerical queries such as counting, averaging, and statistical aggregation operations commonly used in data analysis and machine learning preprocessing.
For more complex scenarios involving high-dimensional data or sophisticated machine learning algorithms, advanced mechanisms such as the exponential mechanism and composition techniques provide additional flexibility and improved utility. The exponential mechanism is particularly useful for selecting optimal outputs from discrete sets while maintaining differential privacy, making it valuable for feature selection, hyperparameter optimization, and other decision-making processes in machine learning pipelines. Composition theorems allow multiple differentially private algorithms to be combined while maintaining overall privacy guarantees, enabling the construction of complex AI systems with end-to-end privacy protection.
Privacy-Preserving Machine Learning Architectures
The integration of differential privacy into machine learning systems requires careful consideration of where and how privacy mechanisms are applied throughout the learning pipeline. One approach involves adding noise directly to training data before model training, known as input perturbation, which provides strong privacy guarantees but may significantly impact model accuracy for complex learning tasks. This approach is particularly suitable for simpler models and scenarios where data owners want to release privatized datasets for multiple analysis purposes.
Alternative approaches focus on output perturbation, where noise is added to model parameters, gradients, or predictions during the training process. Techniques such as differentially private stochastic gradient descent have shown promising results in training neural networks with formal privacy guarantees while maintaining competitive performance on various tasks. These methods typically involve careful tuning of noise parameters, learning rates, and clipping thresholds to achieve optimal privacy-utility trade-offs for specific applications and model architectures.
Real-World Applications and Case Studies
Major technology companies have begun implementing differential privacy in production systems to protect user data while enabling valuable data analysis and product improvements. Apple’s deployment of differential privacy in iOS and macOS represents one of the most prominent real-world applications, using local differential privacy to collect aggregate statistics about user behavior, app crashes, and feature usage while preventing the company from learning information about individual users. This implementation demonstrates how differential privacy can be scaled to millions of users while providing actionable insights for product development and quality assurance.
Google has similarly implemented differential privacy in various products and research initiatives, including privacy-preserving location analytics, federated learning systems, and advertising measurement platforms. These implementations showcase the versatility of differential privacy across different application domains and highlight the practical challenges involved in balancing privacy protection with business requirements and user experience considerations.
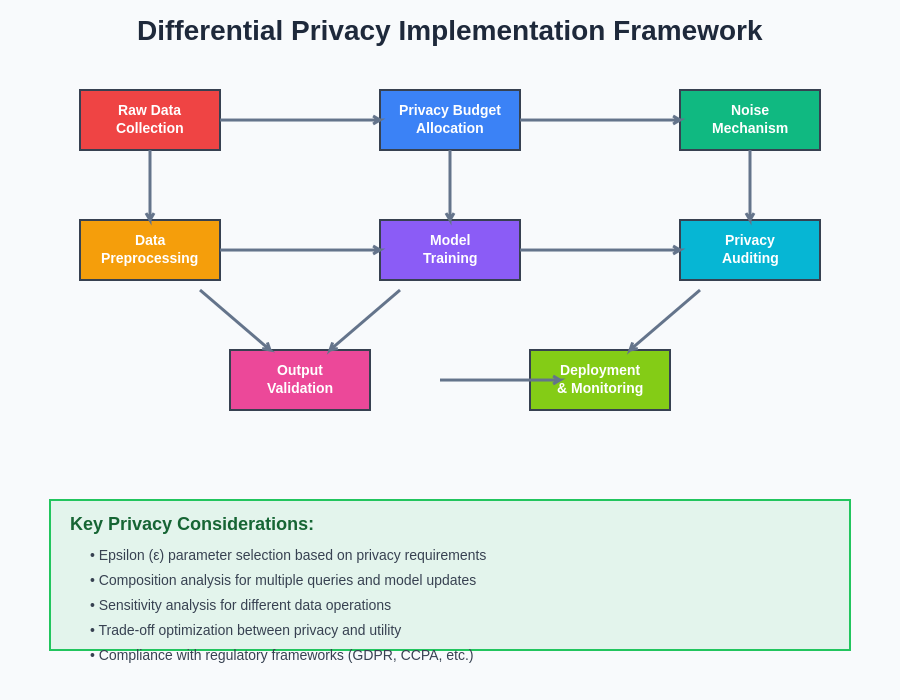
The implementation of differential privacy in real-world AI systems requires a systematic approach that addresses technical, operational, and regulatory considerations. This framework illustrates the key components and decision points involved in designing privacy-preserving AI systems that can operate effectively in production environments while maintaining strong privacy guarantees.
Discover comprehensive AI research capabilities with Perplexity to stay informed about the latest developments in privacy-preserving AI techniques and their applications across different industries and use cases.
Challenges and Limitations
Despite its theoretical elegance and practical promise, differential privacy faces several challenges that limit its widespread adoption in AI systems. The privacy-utility trade-off remains a fundamental limitation, as achieving strong privacy guarantees often requires adding substantial amounts of noise that can degrade the quality of machine learning models or statistical analyses. This trade-off is particularly pronounced for high-dimensional data and complex models where small amounts of noise can significantly impact performance.
The selection of appropriate privacy parameters presents another significant challenge, as it requires domain expertise and careful consideration of threat models, regulatory requirements, and business objectives. Organizations must navigate the complex landscape of privacy regulations such as GDPR and CCPA while ensuring that their differential privacy implementations provide meaningful protection against realistic adversarial scenarios. Additionally, the communication of privacy guarantees to stakeholders and end users remains challenging, as the mathematical concepts underlying differential privacy can be difficult to explain in intuitive terms.
Regulatory Compliance and Standards
The regulatory landscape surrounding data privacy has evolved rapidly in recent years, with frameworks such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States establishing strict requirements for data processing and user consent. Differential privacy offers a promising approach for demonstrating compliance with these regulations by providing quantifiable privacy guarantees that can be audited and verified by regulatory authorities.
However, the integration of differential privacy into existing compliance frameworks requires careful consideration of legal definitions, technical specifications, and audit procedures. Organizations must work closely with legal experts and privacy professionals to ensure that their differential privacy implementations align with regulatory expectations and provide adequate protection for data subjects. The development of industry standards and best practices for differential privacy implementation will be crucial for widespread adoption and regulatory acceptance.
Advanced Techniques and Emerging Research
The field of differential privacy continues to evolve with new techniques and applications that address limitations of traditional approaches and extend privacy protection to emerging AI paradigms. Federated learning with differential privacy represents a particularly promising direction, enabling multiple organizations to collaboratively train machine learning models without sharing raw data while maintaining strong privacy guarantees for individual participants.
Recent research has also explored the application of differential privacy to deep learning architectures, including convolutional neural networks, recurrent neural networks, and transformer models. These efforts focus on developing specialized noise injection techniques, adaptive privacy budgeting methods, and architecture modifications that maintain model performance while providing formal privacy guarantees. Additionally, the emergence of hybrid privacy models that combine differential privacy with other privacy-preserving techniques such as homomorphic encryption and secure multi-party computation offers new possibilities for protecting sensitive data in complex AI systems.
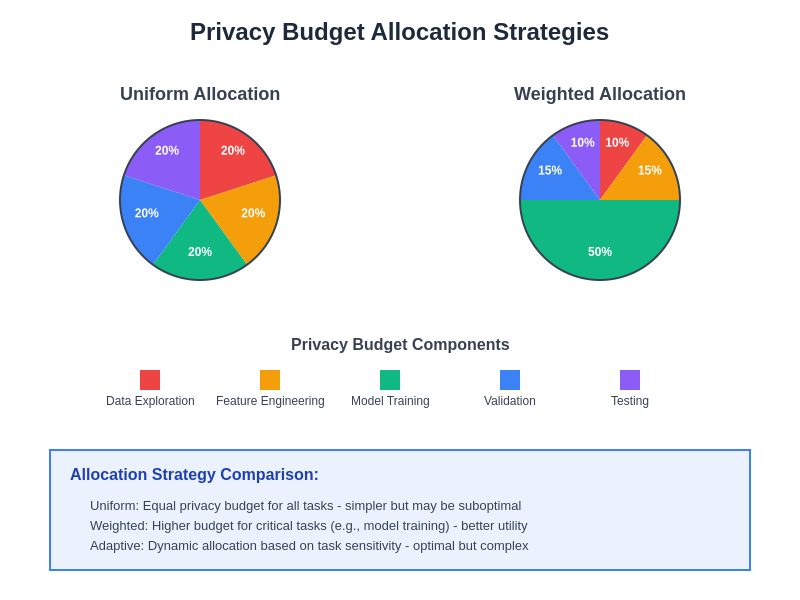
Effective privacy budget management is crucial for maintaining privacy guarantees across complex AI workflows that involve multiple analysis stages and iterative model development processes. This visualization demonstrates different strategies for allocating privacy budgets across various components of AI systems to optimize the trade-off between privacy protection and model utility.
Economic and Business Implications
The adoption of differential privacy in AI systems has significant economic implications that extend beyond technical implementation costs to encompass broader business strategy and competitive positioning. Organizations that successfully implement privacy-preserving AI systems can gain competitive advantages through enhanced customer trust, regulatory compliance, and access to privacy-sensitive data sources that competitors cannot utilize effectively. This strategic value proposition becomes increasingly important as consumers become more privacy-conscious and regulators impose stricter penalties for privacy violations.
The cost-benefit analysis of differential privacy implementation must consider both direct technical costs and indirect benefits such as reduced regulatory risk, improved brand reputation, and expanded market opportunities. Organizations that invest early in privacy-preserving AI capabilities may find themselves better positioned to navigate evolving privacy regulations and consumer expectations while maintaining their ability to extract value from data assets.
Integration with Existing AI Infrastructure
The successful deployment of differential privacy in production AI systems requires careful integration with existing machine learning infrastructure, data pipelines, and operational procedures. This integration involves modifying data preprocessing workflows, adjusting model training procedures, and implementing new monitoring and auditing capabilities to ensure ongoing privacy compliance. Organizations must also consider the impact of differential privacy on model deployment, inference performance, and system scalability.
The technical challenges of integration are compounded by organizational considerations such as training data science teams, updating development processes, and establishing governance frameworks for privacy parameter selection and budget management. Successful implementation typically requires cross-functional collaboration between data scientists, privacy engineers, legal teams, and business stakeholders to ensure that privacy-preserving AI systems meet both technical and business requirements.
Future Directions and Industry Trends
The future of differential privacy in AI systems is likely to be shaped by several key trends including the development of more sophisticated privacy mechanisms, the emergence of privacy-preserving AI platforms, and the establishment of industry standards for privacy-preserving machine learning. Automated privacy parameter selection and adaptive privacy budgeting represent particularly promising research directions that could significantly reduce the complexity of implementing differential privacy in practice.
The growing emphasis on explainable AI and algorithmic fairness also intersects with differential privacy research, as organizations seek to develop AI systems that are simultaneously private, fair, and interpretable. This convergence of privacy, fairness, and explainability requirements presents both challenges and opportunities for developing more holistic approaches to responsible AI development.
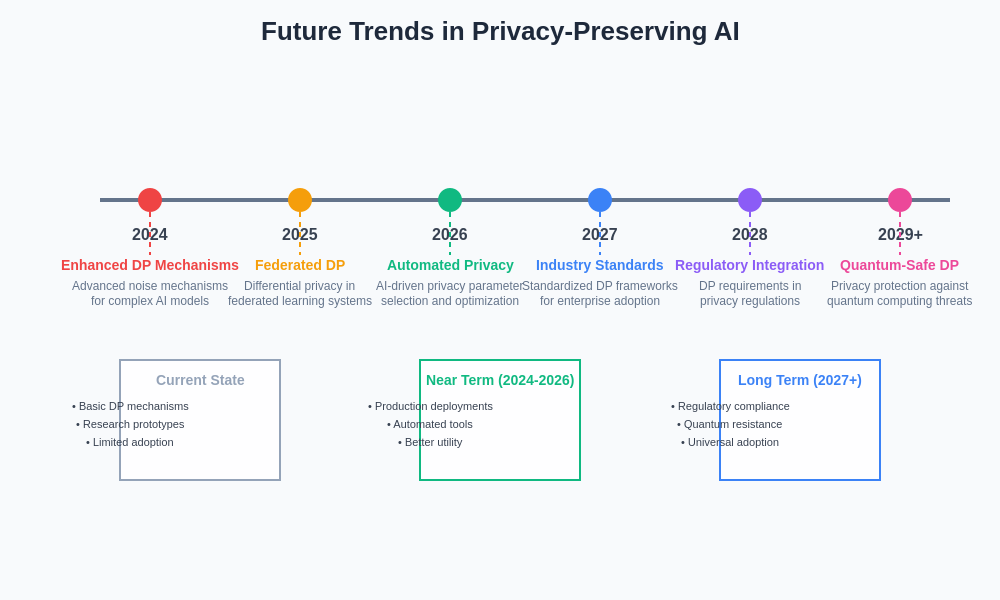
The evolution of privacy-preserving AI technologies is driven by converging trends in regulation, technology, and user expectations. This roadmap illustrates the key developments expected to shape the future of differential privacy and related techniques in AI systems over the coming years.
Best Practices for Implementation
Organizations considering the adoption of differential privacy for their AI systems should follow established best practices to ensure successful implementation and ongoing compliance. These practices include conducting thorough privacy risk assessments, selecting appropriate privacy parameters based on threat modeling and regulatory requirements, and implementing comprehensive monitoring and auditing systems to track privacy budget consumption and model performance.
The development of privacy-first AI systems requires a cultural shift toward privacy-by-design principles that integrate privacy considerations into every stage of the AI development lifecycle. This includes training development teams on privacy-preserving techniques, establishing clear governance processes for privacy parameter selection, and implementing automated tools for privacy budget management and compliance monitoring.
Successful implementation also requires ongoing collaboration with privacy experts, legal professionals, and regulatory authorities to ensure that differential privacy implementations remain aligned with evolving requirements and best practices. Organizations should invest in building internal expertise while also engaging with the broader privacy research community to stay current with emerging techniques and applications.
The promise of differential privacy lies not just in its mathematical rigor but in its potential to enable a new paradigm of trustworthy AI systems that can extract value from sensitive data while providing meaningful privacy protection. As the technology continues to mature and regulatory frameworks evolve, differential privacy is poised to become an essential component of responsible AI development and deployment across industries.
Disclaimer
This article is for informational purposes only and does not constitute legal, technical, or professional advice. The implementation of differential privacy in AI systems involves complex technical and regulatory considerations that may vary by jurisdiction and application domain. Readers should consult with qualified experts and conduct thorough assessments of their specific requirements before implementing privacy-preserving AI techniques. The effectiveness of differential privacy may vary depending on implementation details, threat models, and operational contexts.