The exponential growth in artificial intelligence model complexity has created an unprecedented demand for computational resources that far exceeds the capabilities of single-GPU systems. Modern large language models, computer vision architectures, and multimodal AI systems require distributed training approaches that harness the collective power of multiple graphics processing units across interconnected computing nodes. This comprehensive exploration delves into the intricate world of distributed AI training, examining the architectural foundations, optimization strategies, and practical implementation techniques that enable researchers and organizations to scale their machine learning workflows to previously unattainable levels of performance and efficiency.
Stay updated with the latest AI infrastructure trends that showcase cutting-edge developments in distributed computing and large-scale machine learning deployments. The transition from single-node training to distributed multi-GPU clusters represents a fundamental shift in how artificial intelligence systems are developed, trained, and deployed at enterprise scale, requiring sophisticated understanding of both hardware architectures and software optimization techniques.
Architectural Foundations of Distributed AI Training
The foundation of effective distributed AI training lies in understanding the complex interplay between hardware topology, network infrastructure, and software orchestration layers that collectively enable seamless scaling across multiple compute nodes. Modern distributed training architectures typically employ hierarchical communication patterns that optimize data movement between processing units while minimizing latency and maximizing bandwidth utilization throughout the entire cluster ecosystem.
The most prevalent architectural approach involves organizing compute nodes into logical groups where intra-node communication leverages high-bandwidth interconnects such as NVLink or NVSwitch, while inter-node communication utilizes high-performance networking solutions including InfiniBand, Ethernet, or specialized interconnects designed specifically for machine learning workloads. This hierarchical approach ensures that the most frequent communication patterns, typically gradient synchronization and parameter updates, occur over the fastest available communication channels while less frequent operations utilize more cost-effective networking infrastructure.
Memory hierarchy optimization plays a crucial role in distributed training architectures, where each GPU maintains its own high-bandwidth memory while sharing system memory and storage resources across the cluster. The effective management of this memory hierarchy requires sophisticated caching strategies, prefetching mechanisms, and data staging techniques that ensure compute units remain saturated with training data while minimizing idle time caused by memory access bottlenecks or network communication delays.
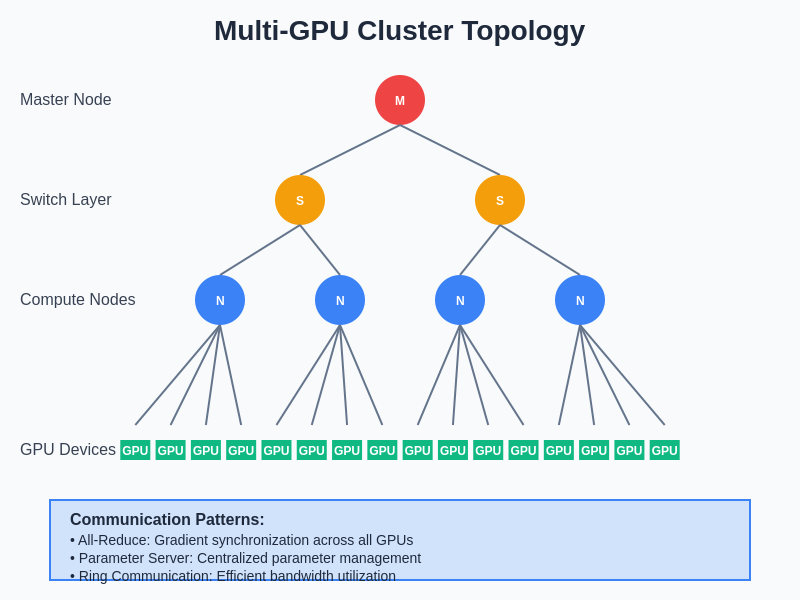
The hierarchical organization of modern distributed training clusters demonstrates the critical importance of topology-aware communication patterns that optimize data flow between processing units while minimizing latency and maximizing bandwidth utilization across all levels of the compute hierarchy.
Multi-GPU Communication Patterns and Protocols
The efficiency of distributed AI training fundamentally depends on the communication patterns and protocols used to synchronize model parameters and gradients across multiple processing units. The most common approaches include parameter server architectures, all-reduce collective operations, and hybrid strategies that combine multiple communication patterns to optimize performance for specific model architectures and cluster configurations.
Parameter server architectures employ dedicated nodes that maintain authoritative copies of model parameters while worker nodes compute gradients and submit updates to these centralized servers. This approach offers excellent scalability characteristics for sparse models and asynchronous training scenarios but can create communication bottlenecks when dealing with dense models or synchronous training requirements that demand frequent parameter synchronization across all participating nodes.
All-reduce collective communication patterns distribute the parameter synchronization burden across all participating nodes, eliminating single points of failure while enabling efficient bandwidth utilization through techniques such as ring all-reduce or tree-based reduction algorithms. These approaches excel in scenarios where model parameters are dense and require frequent synchronization, particularly in synchronous training configurations where all nodes must maintain consistent parameter states throughout the training process.
Enhance your AI development capabilities with Claude for advanced reasoning about distributed system architectures and optimization strategies. The selection of appropriate communication patterns requires careful analysis of model characteristics, cluster topology, and performance requirements to achieve optimal scaling efficiency across diverse training scenarios.
Cluster Hardware Architecture and Topology Design
The physical architecture of multi-GPU clusters significantly influences training performance, scalability, and cost-effectiveness of distributed AI workloads. Modern cluster designs must balance computational density, memory capacity, storage throughput, and network bandwidth while considering power consumption, cooling requirements, and maintenance accessibility that collectively determine the total cost of ownership for large-scale AI training infrastructure.
High-performance computing nodes typically feature multiple GPUs interconnected through specialized high-bandwidth links such as NVIDIA’s NVLink technology, which provides significantly higher bandwidth and lower latency compared to traditional PCIe connections. These intra-node connections enable efficient data sharing between GPUs on the same system while reducing the need for expensive inter-node communication during gradient synchronization and parameter update operations.
Network topology design plays a critical role in cluster performance, with modern installations employing fat-tree, dragonfly, or custom topologies optimized for the specific communication patterns exhibited by distributed machine learning workloads. The selection of appropriate network topology requires careful consideration of bisection bandwidth, network diameter, fault tolerance characteristics, and scalability properties that directly impact training performance as cluster sizes increase beyond hundreds or thousands of compute nodes.
Storage architecture represents another crucial component of cluster design, where high-performance parallel file systems such as Lustre, GPFS, or distributed object storage systems provide the massive throughput required to feed training data to hundreds of GPUs simultaneously. The integration of storage systems with compute nodes requires careful consideration of data locality, caching strategies, and bandwidth allocation to ensure that storage systems do not become performance bottlenecks during intensive training operations.
Software Stack and Framework Optimization
The software ecosystem supporting distributed AI training encompasses multiple layers of abstraction, from low-level communication libraries through high-level machine learning frameworks, each requiring careful optimization to achieve maximum performance from underlying hardware resources. Modern distributed training frameworks such as PyTorch Distributed, TensorFlow Distribution Strategy, and Horovod provide abstractions that simplify the development of distributed training applications while offering fine-grained control over performance-critical aspects of the training process.
Communication library optimization represents a fundamental aspect of software stack performance, where libraries such as NCCL (NVIDIA Collective Communications Library), MPI (Message Passing Interface), and custom implementations provide the low-level primitives required for efficient gradient synchronization and parameter updates across distributed systems. These libraries implement sophisticated algorithms for collective operations, topology-aware communication patterns, and automatic performance tuning that adapt to specific hardware configurations and workload characteristics.
Framework-level optimizations include automatic mixed precision training, gradient compression techniques, and dynamic loss scaling that collectively reduce memory requirements and accelerate training throughput while maintaining numerical stability and convergence characteristics. Advanced optimization techniques such as gradient accumulation, pipeline parallelism, and tensor parallelism enable the training of extremely large models that exceed the memory capacity of individual GPUs while maintaining computational efficiency across distributed systems.
Memory management optimization involves sophisticated strategies for managing GPU memory allocation, data prefetching, and garbage collection that collectively minimize memory fragmentation and maximize GPU utilization throughout extended training runs. These optimizations become particularly critical when training large models that approach the memory limits of available hardware, requiring careful coordination between memory allocation strategies and communication patterns to avoid out-of-memory errors or performance degradation.
Load Balancing and Resource Allocation Strategies
Effective load balancing across distributed AI training clusters requires sophisticated understanding of both static and dynamic factors that influence computational workload distribution among available processing units. Static load balancing strategies consider factors such as hardware heterogeneity, network topology, and model architecture characteristics to pre-assign computational tasks to specific nodes, while dynamic approaches adapt resource allocation based on runtime performance metrics and changing workload characteristics.
Model parallelism strategies enable the distribution of large neural networks across multiple GPUs by partitioning model parameters, activations, or computational graphs among available processing units. This approach becomes essential when training models that exceed the memory capacity of individual GPUs, requiring careful coordination of forward and backward pass computations to minimize communication overhead while maintaining computational efficiency across distributed resources.
Data parallelism represents the most common approach to distributed training, where identical model replicas process different subsets of training data before synchronizing gradients or parameters across all participating nodes. The effectiveness of data parallelism depends heavily on batch size scaling strategies, gradient synchronization frequency, and load balancing techniques that ensure all processing units remain fully utilized throughout the training process.
Leverage Perplexity for advanced research on emerging load balancing algorithms and resource allocation strategies that optimize distributed training performance across heterogeneous cluster environments. Hybrid parallelization approaches combine multiple strategies to achieve optimal resource utilization for specific model architectures and cluster configurations, requiring sophisticated analysis of communication patterns, memory requirements, and computational characteristics to achieve maximum training efficiency.
Performance Monitoring and Profiling Techniques
Comprehensive performance monitoring and profiling represent essential components of distributed AI training optimization, providing the insights necessary to identify bottlenecks, optimize resource utilization, and ensure stable training performance across extended training runs. Modern profiling tools provide detailed visibility into GPU utilization, memory consumption, network communication patterns, and synchronization overhead that collectively determine overall system performance and efficiency.
GPU-level monitoring encompasses metrics such as compute utilization, memory bandwidth utilization, temperature profiles, and power consumption patterns that provide insights into individual device performance and potential optimization opportunities. Advanced profiling tools such as NVIDIA Nsight Systems, PyTorch Profiler, and TensorFlow Profiler offer detailed timeline views of kernel execution, memory transfers, and communication operations that enable identification of performance bottlenecks and optimization opportunities.
Network performance monitoring requires specialized tools and techniques that capture communication patterns, bandwidth utilization, latency characteristics, and error rates across cluster interconnects. These metrics become particularly critical in large-scale deployments where network congestion or hardware failures can significantly impact training performance and stability, requiring automated monitoring and alerting systems that enable rapid response to performance degradation or system failures.
System-level monitoring encompasses broader infrastructure metrics including CPU utilization, system memory consumption, storage throughput, and environmental factors such as temperature and power consumption that collectively influence cluster performance and reliability. The integration of monitoring data from multiple sources enables comprehensive performance analysis and predictive maintenance strategies that minimize downtime and optimize long-term system reliability.
Fault Tolerance and Checkpoint Management
Distributed AI training systems must incorporate sophisticated fault tolerance mechanisms that ensure training progress is preserved despite inevitable hardware failures, network disruptions, or software errors that occur during extended training runs spanning days, weeks, or months. Modern fault tolerance strategies employ a combination of checkpointing, redundancy, and automatic recovery mechanisms that minimize training disruption while maintaining data consistency and model convergence properties.
Checkpoint management strategies must balance the frequency of checkpoint creation with the overhead of persisting large model states to stable storage systems. Advanced checkpointing approaches employ techniques such as incremental checkpointing, asynchronous checkpoint creation, and distributed checkpoint storage that minimize the impact on training performance while ensuring rapid recovery from various failure scenarios.
Elastic training capabilities enable distributed systems to dynamically adapt to changing resource availability by adding or removing compute nodes without interrupting ongoing training processes. This functionality becomes particularly valuable in cloud computing environments where resource availability and pricing fluctuate dynamically, requiring sophisticated resource management and workload migration strategies that maintain training efficiency while optimizing cost-effectiveness.
Automatic failure detection and recovery systems monitor cluster health and training progress to identify and respond to various failure modes including hardware failures, network partitions, and software errors. These systems must distinguish between transient issues that resolve automatically and permanent failures requiring human intervention, implementing appropriate recovery strategies that minimize training disruption while maintaining system stability and data integrity.
Scaling Strategies and Performance Optimization
The effective scaling of distributed AI training requires comprehensive understanding of the relationship between cluster size, model architecture, dataset characteristics, and training performance that collectively determine the optimal configuration for specific workloads and performance objectives. Linear scaling represents the ideal scenario where training throughput increases proportionally with the number of processing units, but achieving this ideal requires careful optimization of communication patterns, synchronization strategies, and load balancing techniques.
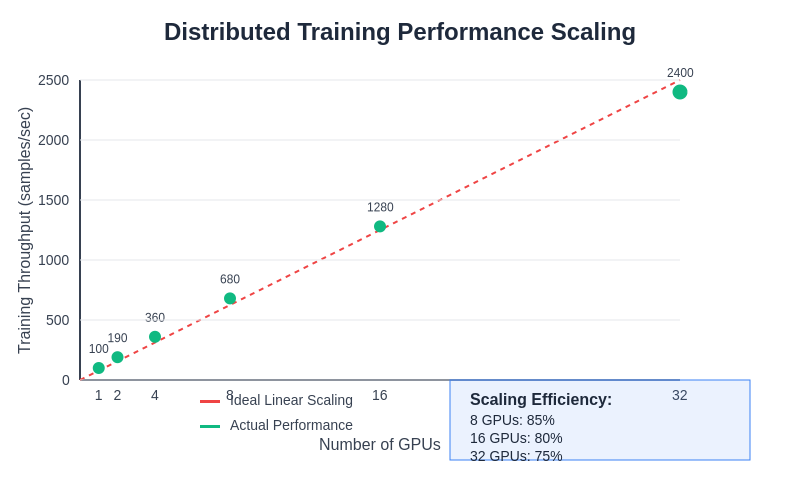
Real-world performance scaling demonstrates the challenges and opportunities inherent in distributed AI training, where careful optimization can achieve substantial performance improvements while revealing the practical limitations imposed by communication overhead, synchronization requirements, and hardware constraints that affect scaling efficiency as cluster sizes increase.
Batch size scaling strategies play a crucial role in distributed training performance, where larger batch sizes can improve computational efficiency and reduce communication overhead but may require modifications to learning rate schedules, optimization algorithms, and regularization techniques to maintain convergence properties. Advanced scaling techniques such as learning rate warmup, batch size ramping, and adaptive optimization algorithms enable effective utilization of large-scale distributed resources while maintaining training stability and model quality.
Communication optimization techniques including gradient compression, quantization, and sparsification can significantly reduce network bandwidth requirements and synchronization overhead in large-scale distributed training scenarios. These optimizations must balance the reduction in communication cost against potential impacts on model convergence and final performance, requiring careful evaluation and tuning for specific model architectures and training objectives.
Pipeline parallelism enables the training of extremely large models by partitioning computational graphs across multiple devices and overlapping forward and backward pass computations to maximize resource utilization. This approach requires careful analysis of memory requirements, communication patterns, and synchronization constraints to achieve optimal performance while maintaining numerical accuracy and convergence properties.

Advanced optimization techniques demonstrate significant improvements in memory efficiency, communication overhead reduction, and overall system performance through systematic application of compression algorithms, precision optimization, and intelligent resource management strategies that collectively enable more efficient utilization of distributed computing resources.
Cost Optimization and Resource Management
The economic considerations of distributed AI training encompass both direct computational costs and indirect expenses related to infrastructure management, power consumption, and operational overhead that collectively determine the total cost of ownership for large-scale training infrastructure. Effective cost optimization requires sophisticated analysis of the relationship between performance requirements, resource utilization, and economic constraints to identify configurations that maximize training efficiency while minimizing total expenses.
Cloud-based training platforms offer dynamic resource allocation capabilities that enable cost optimization through spot instance utilization, automatic scaling, and pay-per-use pricing models that can significantly reduce training costs for workloads with flexible timing requirements. However, these platforms may introduce additional complexity related to data transfer costs, network performance variability, and resource availability fluctuations that must be carefully managed to ensure predictable training performance and costs.
On-premises infrastructure provides greater control over performance characteristics and long-term costs but requires significant capital investment and ongoing operational expertise to maintain optimal performance and reliability. The decision between cloud and on-premises deployments requires careful analysis of training frequency, model complexity, security requirements, and long-term strategic objectives that collectively influence the total cost of ownership for distributed training infrastructure.
Power consumption optimization represents an increasingly important aspect of cost management, where techniques such as dynamic voltage and frequency scaling, workload scheduling, and cooling system optimization can significantly reduce operational expenses while maintaining training performance. Advanced power management strategies may incorporate renewable energy utilization, thermal management optimization, and predictive maintenance approaches that minimize both energy consumption and infrastructure maintenance costs.
Future Directions and Emerging Technologies
The evolution of distributed AI training continues to accelerate through advances in hardware architecture, communication technologies, and algorithmic innovations that collectively enable the training of increasingly complex models with improved efficiency and reduced resource requirements. Emerging hardware technologies such as specialized AI accelerators, optical interconnects, and neuromorphic computing architectures promise to fundamentally alter the landscape of distributed training infrastructure and optimization strategies.
Advanced communication technologies including remote direct memory access (RDMA), GPU-direct storage, and high-bandwidth interconnects are reducing the latency and overhead associated with distributed training communication patterns. These technologies enable new optimization strategies and architectural approaches that can significantly improve training efficiency while reducing the complexity of distributed system management and optimization.
Algorithmic innovations in areas such as federated learning, continual learning, and few-shot learning are creating new paradigms for distributed AI training that emphasize privacy preservation, incremental model updates, and efficient utilization of limited training data. These approaches require new infrastructure capabilities and optimization strategies that differ significantly from traditional distributed training approaches, creating opportunities for specialized hardware and software solutions.
The integration of artificial intelligence techniques into the management and optimization of distributed training systems themselves represents an emerging area of research and development. Machine learning approaches to resource allocation, performance optimization, and failure prediction promise to automate many aspects of distributed system management while improving performance and reliability beyond what is achievable through traditional optimization approaches.
Disclaimer
This article is for informational and educational purposes only and does not constitute professional advice regarding infrastructure design, implementation, or optimization. The information presented is based on current understanding of distributed computing technologies and best practices, which continue to evolve rapidly. Readers should conduct thorough research, consult with qualified professionals, and perform appropriate testing before implementing distributed AI training systems in production environments. Performance characteristics, cost implications, and technical requirements may vary significantly based on specific use cases, hardware configurations, and organizational constraints.