The exponential growth of machine learning applications has created an unprecedented demand for sophisticated data version control systems capable of handling massive datasets, complex model files, and intricate experimental workflows. Traditional version control systems like Git, while exceptional for source code management, face significant limitations when dealing with the large binary files that characterize modern machine learning projects. This challenge has given rise to specialized solutions like Data Version Control (DVC) and Git Large File Storage (Git LFS), each offering unique approaches to managing the complexities of machine learning data versioning.
Stay updated with the latest AI and ML trends to understand how data version control fits into the broader ecosystem of machine learning operations and best practices. The choice between different version control systems can significantly impact the efficiency, scalability, and reproducibility of machine learning projects, making it crucial for data scientists and ML engineers to understand the nuances and capabilities of each approach.
Understanding the Data Version Control Challenge
Machine learning projects present unique challenges that distinguish them from traditional software development workflows. The scale of data involved often reaches terabytes or even petabytes, with individual model files frequently exceeding gigabyte sizes. These datasets undergo constant evolution through preprocessing pipelines, feature engineering transformations, and iterative model training processes that generate multiple versions of both raw and processed data. The complexity extends beyond mere file size to encompass intricate dependencies between datasets, model parameters, experimental configurations, and computational environments.
Traditional Git repositories struggle with these requirements due to fundamental design limitations that prioritize text-based diff operations and assume relatively small file sizes. When machine learning teams attempt to version control large datasets using standard Git workflows, they encounter performance degradation, repository bloat, and storage limitations that can render collaborative development nearly impossible. This reality has necessitated the development of specialized tools that can handle the unique requirements of machine learning data versioning while maintaining the collaborative benefits of modern version control systems.
The challenge becomes even more pronounced when considering the need for reproducibility in machine learning experiments. Data scientists must be able to recreate exact experimental conditions, including specific dataset versions, model configurations, and preprocessing steps, often months or years after the initial experiments were conducted. This requirement demands version control solutions that can efficiently track not just the final outputs but the entire pipeline of transformations and dependencies that contribute to machine learning model development.
Git LFS: Extending Git for Large Files
Git Large File Storage represents a straightforward extension to the Git ecosystem that addresses the fundamental limitation of handling large binary files within traditional Git repositories. By implementing a pointer-based system, Git LFS maintains the familiar Git workflow while offloading large files to separate storage backends. When users commit large files to a Git LFS-enabled repository, the system replaces the actual file content with a small text pointer that references the file’s location in the LFS storage system. This approach allows teams to maintain their existing Git workflows while gaining the ability to version control large datasets and model files effectively.
The architecture of Git LFS integrates seamlessly with existing Git hosting platforms like GitHub, GitLab, and Bitbucket, providing a low-friction path for teams already invested in these ecosystems. The system handles file transfers transparently, downloading only the specific versions of large files that are needed for a particular checkout or branch. This selective downloading mechanism significantly reduces bandwidth requirements and local storage needs, particularly beneficial for teams working with extensive datasets across multiple experiments and model iterations.
Enhance your ML workflows with advanced AI tools like Claude to complement your data version control strategy with intelligent code generation and analysis capabilities. Git LFS excels in scenarios where teams need to maintain compatibility with existing Git-based workflows while adding large file support without fundamentally altering their development processes or requiring extensive retraining of team members.
DVC: Purpose-Built for Machine Learning
Data Version Control represents a more comprehensive approach to the machine learning version control challenge, designed from the ground up to address the specific needs of data science and machine learning workflows. Unlike Git LFS, which focuses primarily on large file storage, DVC provides a complete framework for managing machine learning experiments, including data versioning, pipeline orchestration, experiment tracking, and reproducibility guarantees. The system treats machine learning projects as complex directed acyclic graphs where datasets, preprocessing steps, training procedures, and model outputs are interconnected nodes in a computational pipeline.
DVC’s architecture separates the concerns of code versioning and data versioning while maintaining clear relationships between them. Source code remains in Git repositories, while DVC manages large files and datasets through its own metafile system that tracks data versions, dependencies, and transformations. This separation allows teams to leverage the strengths of both systems: Git’s exceptional source code management capabilities and DVC’s specialized data and experiment management features. The result is a more sophisticated approach to machine learning project organization that can handle complex experimental workflows and large-scale data operations.
The system’s pipeline functionality enables teams to define reproducible workflows that automatically track dependencies between different stages of machine learning projects. When datasets are updated or preprocessing parameters are modified, DVC can automatically determine which downstream components need to be recalculated, enabling efficient incremental updates and ensuring consistency across complex experimental setups. This capability is particularly valuable for large-scale machine learning projects where manual tracking of dependencies becomes impractical.
Storage and Scalability Considerations
The storage architectures of DVC and Git LFS reflect their different design philosophies and target use cases, with significant implications for scalability and cost management. Git LFS relies on the storage infrastructure provided by Git hosting platforms, which typically offer limited free storage with paid tiers for larger requirements. This model works well for smaller teams and projects but can become costly for organizations dealing with extensive datasets or numerous experimental iterations. The platform dependency also creates vendor lock-in scenarios where migrating to different hosting providers requires careful consideration of data transfer costs and storage compatibility.
DVC offers greater flexibility in storage backend selection, supporting a wide range of cloud storage providers including Amazon S3, Google Cloud Storage, Azure Blob Storage, and traditional shared file systems. This flexibility enables organizations to optimize storage costs by selecting the most appropriate backend for their specific requirements and budget constraints. The system’s storage-agnostic design also facilitates multi-cloud strategies and helps avoid vendor lock-in while providing options for both hot and cold storage tiers depending on access patterns and cost optimization requirements.
The scalability characteristics of each system reflect these architectural differences significantly. Git LFS performance can degrade with very large repositories or when dealing with numerous large files due to its integration with Git’s core operations. DVC’s independent architecture allows it to scale more effectively with dataset size and complexity, as its operations are decoupled from Git’s performance characteristics. For organizations anticipating significant growth in dataset sizes or experimental complexity, these scalability differences can have long-term implications for workflow efficiency and team productivity.

The fundamental architectural differences between DVC and Git LFS create distinct advantages for different use cases, with DVC’s modular approach enabling more sophisticated machine learning workflows while Git LFS provides simpler integration with existing development practices.
Workflow Integration and Team Collaboration
The integration of data version control systems into existing development workflows significantly impacts team productivity and collaboration effectiveness. Git LFS maintains the familiar Git command structure and workflow patterns, allowing teams to adopt large file support without substantial changes to their established development practices. Developers can continue using standard Git operations like clone, pull, push, and merge while transparently handling large files through the LFS system. This continuity reduces the learning curve and change management overhead associated with adopting new tooling.
DVC requires a more significant workflow adaptation but provides correspondingly more powerful capabilities for machine learning specific operations. Teams must learn DVC-specific commands for data operations while maintaining their existing Git workflows for source code management. The dual-system approach initially appears more complex but enables more sophisticated experiment management and reproducibility guarantees that are difficult to achieve with Git LFS alone. The investment in learning DVC’s workflow patterns typically pays dividends for teams engaged in serious machine learning development.
Collaboration patterns differ significantly between the two approaches, with implications for team coordination and project organization. Git LFS collaboration follows standard Git patterns, with team members sharing large files through the same branching and merging strategies used for source code. This familiarity facilitates adoption but can lead to conflicts when multiple team members simultaneously modify large datasets or model files. DVC’s approach to collaboration emphasizes shared data repositories and pipeline definitions that can be more easily coordinated across team members working on different aspects of machine learning projects.
Performance and Efficiency Analysis
Performance characteristics vary dramatically between DVC and Git LFS depending on specific use cases and operational patterns. Git LFS performs well for scenarios involving moderate numbers of large files with infrequent updates, as its integration with Git’s core operations provides familiar performance characteristics for most workflow operations. However, performance can degrade significantly when repositories contain thousands of large files or when teams frequently switch between branches containing different versions of extensive datasets. The system’s reliance on Git’s internal structures means that operations like repository cloning or branch switching must process metadata for all tracked files, even those not immediately needed.
DVC’s architecture enables more efficient handling of large-scale data operations through its independent file tracking and selective synchronization capabilities. The system can efficiently handle repositories containing millions of files and terabytes of data while maintaining responsive performance for common operations. DVC’s caching mechanisms and incremental synchronization features reduce bandwidth requirements and local storage needs, particularly beneficial for teams working with frequently updated datasets or complex experimental pipelines that generate numerous intermediate files.
Leverage advanced research capabilities with Perplexity to stay informed about performance optimizations and best practices for data version control in machine learning projects. The efficiency differences become more pronounced as projects scale, with DVC generally providing better performance characteristics for large-scale machine learning operations while Git LFS offers simpler deployment and management for smaller projects.
Experiment Tracking and Reproducibility
The ability to track experiments and ensure reproducibility represents a critical differentiator between DVC and Git LFS, with significant implications for research validity and operational efficiency. Git LFS provides basic versioning capabilities for large files but lacks sophisticated mechanisms for tracking the relationships between different components of machine learning experiments. Teams using Git LFS must implement additional tooling or manual processes to maintain experiment metadata, parameter tracking, and result correlation across different experimental runs.
DVC integrates comprehensive experiment tracking capabilities directly into its core functionality, automatically maintaining relationships between datasets, parameters, code versions, and experimental outcomes. The system’s pipeline definitions create explicit dependency graphs that ensure reproducibility by tracking all inputs, parameters, and transformations that contribute to specific experimental results. This automated tracking eliminates many sources of human error that can compromise experiment reproducibility and provides clear audit trails for regulatory compliance or research publication requirements.
The reproducibility guarantees provided by each system reflect these different approaches to experiment management. Git LFS can ensure that specific versions of large files are available but cannot automatically guarantee that all dependencies and environmental factors are correctly reproduced. DVC’s more comprehensive approach to dependency tracking and environment management provides stronger reproducibility guarantees but requires more sophisticated setup and configuration to achieve these benefits effectively.
Cost Considerations and Resource Management
The economic implications of choosing between DVC and Git LFS extend beyond simple storage costs to encompass bandwidth utilization, infrastructure complexity, and operational overhead. Git LFS pricing is typically tied to Git hosting platform storage and bandwidth limits, which can create predictable but potentially expensive cost structures for organizations with large datasets or frequent data updates. The platform-dependent pricing models may not align well with actual usage patterns, particularly for teams that access historical data infrequently but require extensive storage for archival purposes.
DVC’s flexible storage backend support enables more sophisticated cost optimization strategies, including the use of different storage tiers for active versus archival data. Teams can implement cost-effective strategies like storing frequently accessed datasets in high-performance storage while archiving older experimental data in cheaper cold storage tiers. The system’s efficient synchronization and caching mechanisms can also reduce bandwidth costs by minimizing unnecessary data transfers and enabling more efficient collaboration patterns.
The total cost of ownership considerations extend beyond direct storage and bandwidth expenses to include infrastructure management, training, and operational complexity. Git LFS typically requires less specialized knowledge and infrastructure management, making it potentially more cost-effective for smaller teams or organizations without dedicated MLOps resources. DVC’s more sophisticated capabilities may justify higher operational complexity for organizations where advanced experiment tracking and reproducibility features provide significant business value.
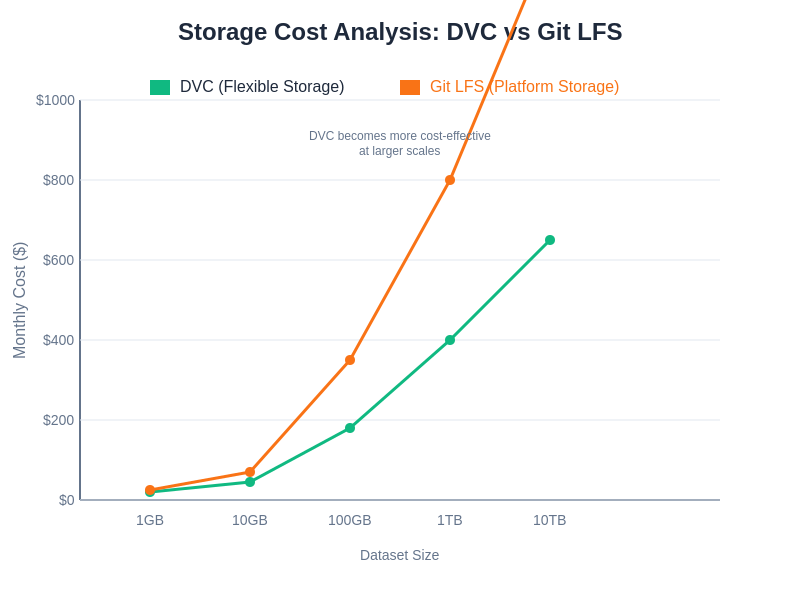
The cost dynamics between DVC and Git LFS vary significantly based on usage patterns, team size, and storage requirements, with different solutions offering advantages at different scales of operation and organizational maturity levels.
Use Case Scenarios and Recommendations
The choice between DVC and Git LFS should be driven by specific organizational requirements, team characteristics, and project complexity factors rather than abstract technical preferences. Git LFS represents an optimal choice for teams that primarily need to add large file support to existing Git-based workflows without fundamental changes to their development processes. This scenario commonly applies to software development teams that occasionally work with large assets, small machine learning projects, or organizations in the early stages of ML adoption where simplicity and familiar workflows take precedence over advanced features.
DVC becomes the preferred solution for teams engaged in serious machine learning development where experiment reproducibility, complex pipeline management, and sophisticated data versioning are critical requirements. This includes research organizations, data science teams working on production machine learning systems, and any environment where regulatory compliance or research publication standards demand comprehensive experiment tracking and reproducibility guarantees. The additional complexity and learning investment required for DVC adoption typically proves worthwhile for these more demanding use cases.
Hybrid approaches combining both systems can be effective in certain organizational contexts where different teams have varying requirements. Development teams might use Git LFS for general large file support while specialized machine learning teams adopt DVC for experimental work. However, such mixed approaches require careful coordination to avoid conflicts and ensure consistent data management practices across the organization.
Migration Strategies and Implementation
Organizations considering migration from Git LFS to DVC or vice versa face significant technical and operational challenges that require careful planning and execution. Migrating from Git LFS to DVC involves extracting large files from LFS storage, reorganizing repository structures to align with DVC conventions, and retraining team members on new workflow patterns. The process can be complex for repositories with extensive history or complex branching structures but generally provides opportunities to improve experiment organization and reproducibility practices.
Migration in the opposite direction, from DVC to Git LFS, typically involves consolidating DVC’s distributed data management into Git LFS’s more centralized approach. This migration may result in the loss of some advanced features like pipeline tracking and experiment metadata, but can simplify operational overhead for teams that do not require DVC’s more sophisticated capabilities. Such migrations should be approached cautiously, as the loss of DVC’s experiment tracking capabilities can impact reproducibility for ongoing projects.
New projects have the luxury of selecting the most appropriate system from the outset, avoiding migration complexity while optimizing for specific requirements. The selection criteria should emphasize long-term scalability, team capabilities, and organizational requirements rather than short-term convenience factors. Early architectural decisions about data version control can have lasting implications for project maintainability and team productivity.
Integration with MLOps Ecosystems
The broader MLOps ecosystem integration capabilities of DVC and Git LFS significantly impact their suitability for different organizational contexts and technological environments. Git LFS integrates naturally with Git-centric development toolchains and CI/CD systems, providing straightforward paths for incorporating large file handling into existing DevOps practices. This integration advantage makes Git LFS attractive for organizations with established Git-based workflows that need to add machine learning capabilities without disrupting existing development processes.
DVC offers more sophisticated integration with specialized MLOps tools and platforms, including native support for experiment tracking systems, model registries, and automated pipeline orchestration tools. The system’s API-first design and extensive plugin ecosystem enable integration with tools like MLflow, Weights & Biases, and various cloud-based machine learning platforms. These integration capabilities make DVC particularly valuable for organizations building comprehensive MLOps infrastructures or working with complex multi-stage machine learning pipelines.
The choice between systems should consider not only current integration requirements but also anticipated future needs as MLOps practices mature and toolchains evolve. Organizations investing heavily in MLOps infrastructure may benefit from DVC’s more extensive ecosystem integration, while teams focused on simpler workflows might prefer Git LFS’s straightforward integration patterns.
Security and Compliance Considerations
Data security and regulatory compliance requirements increasingly influence version control system selection, particularly for organizations handling sensitive datasets or operating in regulated industries. Git LFS inherits the security model of its underlying Git hosting platform, which can provide enterprise-grade security features but may limit flexibility for organizations with specific compliance requirements. The centralized storage approach of Git LFS can simplify security auditing and access control management but may create single points of failure or compliance risk.
DVC’s flexible storage backend architecture enables more sophisticated security implementations, including the use of organization-controlled storage systems with custom encryption, access controls, and audit logging capabilities. The system can integrate with enterprise identity management systems and supports fine-grained access controls for different datasets and experimental resources. These capabilities make DVC particularly suitable for organizations with strict data governance requirements or those working with sensitive datasets that require careful access control management.
Compliance considerations extend beyond basic security features to encompass audit trails, data lineage tracking, and reproducibility documentation. DVC’s comprehensive experiment tracking and pipeline management capabilities provide detailed audit trails that can support regulatory compliance requirements, while Git LFS requires additional tooling or manual processes to achieve similar compliance documentation standards.
Future Evolution and Technology Trends
The continued evolution of both DVC and Git LFS reflects broader trends in machine learning infrastructure and development practices that will influence their long-term viability and feature development trajectories. Git LFS benefits from its close integration with the Git ecosystem and the continued investment in Git-based development tools, ensuring ongoing compatibility and feature development aligned with broader software development trends. The system’s simplicity and familiar workflow patterns provide stability advantages that are likely to remain relevant as development practices evolve.
DVC’s future development focuses on deeper integration with cloud-native machine learning platforms and advanced MLOps capabilities including automated pipeline optimization, intelligent caching strategies, and enhanced collaboration features for distributed teams. The system’s architecture supports more sophisticated extensions and integrations that align with the increasing complexity and scale of modern machine learning operations. These development directions suggest continued differentiation from simpler alternatives like Git LFS.
The emergence of new technologies including federated learning, edge computing for machine learning, and advanced automated machine learning platforms will likely influence the requirements for data version control systems. Organizations should consider not only current capabilities but also the development trajectories and community support levels that will determine long-term viability and feature evolution for their chosen data version control solutions.
Conclusion and Decision Framework
The selection between DVC and Git LFS should be guided by a systematic evaluation of organizational requirements, team capabilities, and project characteristics rather than technical preferences or short-term convenience factors. Git LFS provides an excellent solution for teams that need to add large file support to existing Git workflows without significant process changes, particularly suitable for smaller projects, mixed development teams, or organizations in early stages of machine learning adoption where simplicity and familiarity outweigh advanced features.
DVC represents the superior choice for organizations engaged in serious machine learning development where experiment reproducibility, sophisticated pipeline management, and comprehensive data versioning are critical requirements. The system’s advanced capabilities justify its additional complexity for research organizations, production machine learning teams, and any environment where regulatory compliance or publication standards demand comprehensive experiment tracking and reproducibility guarantees.
The decision framework should evaluate factors including project scale, team expertise, infrastructure requirements, cost considerations, and long-term strategic objectives to determine the most appropriate solution. Organizations may also benefit from pilot implementations or gradual adoption strategies that allow practical evaluation of both systems before making comprehensive commitments to particular approaches.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of data version control technologies and their applications in machine learning workflows. Readers should conduct their own research and consider their specific requirements when selecting data version control solutions. The effectiveness and suitability of different systems may vary depending on specific use cases, organizational constraints, and project requirements.