
The architectural foundation of successful machine learning projects lies in the strategic design of data pipelines that efficiently process, transform, and deliver high-quality data to ML models. Two predominant approaches have emerged as cornerstones of modern data engineering: Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT). The choice between these methodologies profoundly impacts the performance, scalability, and maintainability of machine learning systems, making it crucial for data engineers and ML practitioners to understand the nuanced differences and optimal applications of each approach.
Explore the latest developments in AI and data engineering to stay informed about emerging trends that are reshaping how organizations build and deploy ML-powered data processing systems. The evolution of data pipeline architectures reflects the increasing sophistication of machine learning applications and the growing demand for real-time, scalable data processing solutions that can handle the complexity and volume of modern datasets.
Understanding ETL and ELT Fundamentals
The traditional Extract, Transform, Load paradigm has served as the backbone of data processing systems for decades, establishing a sequential workflow where data extraction from source systems precedes transformation operations, which are then followed by loading into target destinations. This approach emphasizes data quality and consistency by performing transformations in dedicated processing environments before data reaches its final destination, ensuring that downstream consumers receive clean, validated, and properly formatted datasets.
In contrast, the Extract, Load, Transform methodology reverses the order of operations by loading raw data directly into target systems before applying transformation logic within the destination environment itself. This architectural shift leverages the computational power and storage capabilities of modern data platforms, enabling organizations to store vast quantities of unprocessed data while applying transformations as needed for specific use cases and analytical requirements.
The fundamental difference between these approaches extends beyond mere sequencing of operations to encompass philosophical distinctions in data management, resource utilization, and system design. ETL prioritizes data quality and consistency through centralized transformation processes, while ELT emphasizes flexibility and scalability by distributing transformation responsibilities to powerful destination systems that can handle complex processing tasks efficiently.
ETL Architecture for Machine Learning Workflows
The ETL approach to machine learning data pipelines emphasizes rigorous data preparation and quality assurance through dedicated transformation layers that operate independently of storage systems. This architecture typically involves specialized ETL tools and platforms that extract data from diverse sources, apply comprehensive transformation logic including data cleaning, validation, aggregation, and feature engineering, before loading the processed datasets into data warehouses, data lakes, or ML-specific storage systems.
Machine learning workflows benefit from ETL architectures through enhanced data quality controls, standardized transformation processes, and reduced computational load on destination systems. The approach enables data engineers to implement sophisticated validation rules, handle complex data type conversions, and perform resource-intensive operations such as statistical analysis, anomaly detection, and feature scaling within dedicated processing environments optimized for such tasks.
Enhance your ML development with advanced AI assistants like Claude that can help design optimal data pipeline architectures and provide guidance on transformation logic implementation. The integration of AI-powered development tools accelerates the creation of robust ETL processes while ensuring adherence to best practices in data engineering and machine learning operations.
The ETL model proves particularly advantageous for machine learning applications requiring strict data governance, regulatory compliance, and consistent data quality standards. Industries such as healthcare, finance, and manufacturing often mandate rigorous data validation and audit trails that align naturally with ETL’s emphasis on comprehensive transformation processes executed in controlled environments before data reaches production systems.
ELT Architecture and Modern ML Platforms
The Extract, Load, Transform paradigm has gained significant traction in the machine learning community due to its alignment with cloud-native architectures and the computational capabilities of modern data platforms. ELT implementations typically leverage powerful data warehouses, distributed computing frameworks, and cloud-based analytics platforms that can efficiently process large volumes of raw data using SQL-based transformations, distributed processing engines, and specialized ML frameworks.
Contemporary ML platforms such as Snowflake, BigQuery, Databricks, and Amazon Redshift provide robust ELT capabilities through native support for complex analytical operations, user-defined functions, and integration with popular machine learning libraries. These platforms enable data scientists and engineers to perform feature engineering, statistical analysis, and model training directly within the data warehouse environment, eliminating the need for separate transformation infrastructure.
The ELT approach facilitates rapid experimentation and iterative development cycles that are essential for successful machine learning projects. Data scientists can quickly access raw datasets, apply different transformation strategies, and evaluate various feature engineering approaches without being constrained by predefined ETL processes. This flexibility accelerates model development while enabling teams to adapt their data processing logic as requirements evolve and new insights emerge.
Performance Implications and Scalability Considerations
Performance characteristics differ significantly between ETL and ELT approaches, with each methodology offering distinct advantages under specific conditions and requirements. ETL systems typically excel in scenarios involving complex transformation logic, limited destination system resources, and requirements for consistent processing performance across varying data volumes. The dedicated transformation infrastructure can be optimized for specific workloads and scaled independently of storage systems.
ELT architectures leverage the inherent scalability of modern cloud data platforms, enabling organizations to process massive datasets using distributed computing resources that automatically scale based on demand. This approach proves particularly effective for machine learning workloads that involve large-scale data processing, real-time analytics, and dynamic resource requirements that fluctuate based on model training schedules and inference demands.
The choice between ETL and ELT often depends on data volume, transformation complexity, and available infrastructure resources. ETL may provide better performance for smaller datasets with complex transformation requirements, while ELT typically offers superior scalability for large datasets with simpler transformation logic that can be efficiently executed using SQL-based operations or distributed computing frameworks.
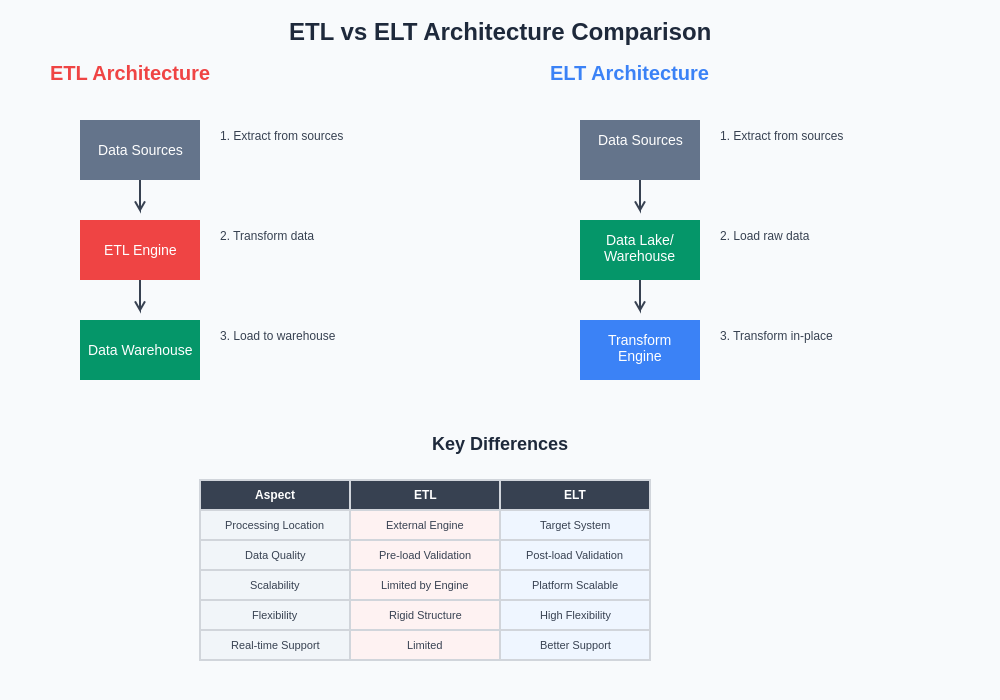
The architectural differences between ETL and ELT approaches fundamentally impact how machine learning teams design, implement, and maintain their data processing workflows. Understanding these structural distinctions enables organizations to make informed decisions about pipeline design based on their specific requirements, constraints, and technical capabilities.
Data Quality and Governance Implications
Data quality management represents a critical consideration when choosing between ETL and ELT approaches for machine learning pipelines, as the timing and location of data validation processes significantly impact the overall reliability and trustworthiness of ML models. ETL methodologies inherently emphasize data quality through comprehensive validation, cleansing, and standardization processes that occur before data reaches destination systems, providing strong guarantees about data integrity and consistency.
The centralized nature of ETL transformations enables implementation of sophisticated data quality frameworks that can detect anomalies, enforce business rules, and maintain comprehensive audit trails throughout the transformation process. This approach proves particularly valuable for machine learning applications in regulated industries where data lineage, compliance documentation, and quality assurance are paramount concerns that must be addressed before data can be used for model training or inference.
ELT approaches require different strategies for ensuring data quality, as raw data is loaded into destination systems before transformation and validation processes occur. This methodology necessitates robust data quality monitoring within the target environment, including implementation of data validation rules, anomaly detection systems, and quality metrics that operate on stored datasets rather than during the ingestion process.
Discover comprehensive research capabilities with Perplexity to explore advanced data quality frameworks and governance strategies that align with your chosen pipeline architecture. Modern data quality tools provide sophisticated monitoring and validation capabilities that can be adapted to both ETL and ELT methodologies.
Cost Optimization and Resource Management
Economic considerations play a crucial role in pipeline architecture decisions, as the cost implications of ETL and ELT approaches can vary significantly based on data volumes, processing complexity, and infrastructure choices. ETL systems typically require dedicated transformation infrastructure that must be provisioned, maintained, and scaled independently of data storage systems, potentially leading to higher operational costs but providing greater control over resource utilization and performance optimization.
ELT methodologies leverage the economies of scale provided by cloud data platforms, enabling organizations to pay for processing resources only when transformations are actively running while benefiting from the shared infrastructure and optimization capabilities of managed services. This approach can provide significant cost advantages for organizations with variable processing requirements or those seeking to minimize infrastructure management overhead.
The total cost of ownership calculations must consider not only direct infrastructure costs but also the ongoing expenses associated with system maintenance, monitoring, optimization, and skilled personnel required to operate each type of architecture effectively. ETL systems may require specialized expertise in transformation tools and dedicated infrastructure management, while ELT implementations often benefit from the simplified operations and reduced administrative overhead associated with managed cloud services.
Real-Time Processing and Streaming Considerations
Modern machine learning applications increasingly require real-time data processing capabilities to support use cases such as fraud detection, recommendation systems, and predictive maintenance that depend on immediate insights and rapid response times. The architectural differences between ETL and ELT approaches significantly impact how organizations can implement streaming data processing and real-time transformation capabilities.
Traditional ETL systems often struggle with real-time requirements due to their batch-oriented nature and sequential processing model that can introduce latency between data availability and model consumption. However, modern ETL platforms have evolved to support streaming transformations through technologies such as Apache Kafka, Apache Storm, and cloud-native streaming services that enable real-time data processing while maintaining the quality and governance benefits of traditional ETL approaches.
ELT architectures are naturally better positioned to support real-time processing requirements through their integration with streaming data platforms and the ability to perform transformations within high-performance analytical databases that can handle continuous data ingestion and immediate query processing. Cloud data platforms increasingly offer native streaming capabilities that seamlessly integrate with ELT workflows, enabling organizations to process real-time data streams while leveraging the scalability and flexibility of modern data warehouses.
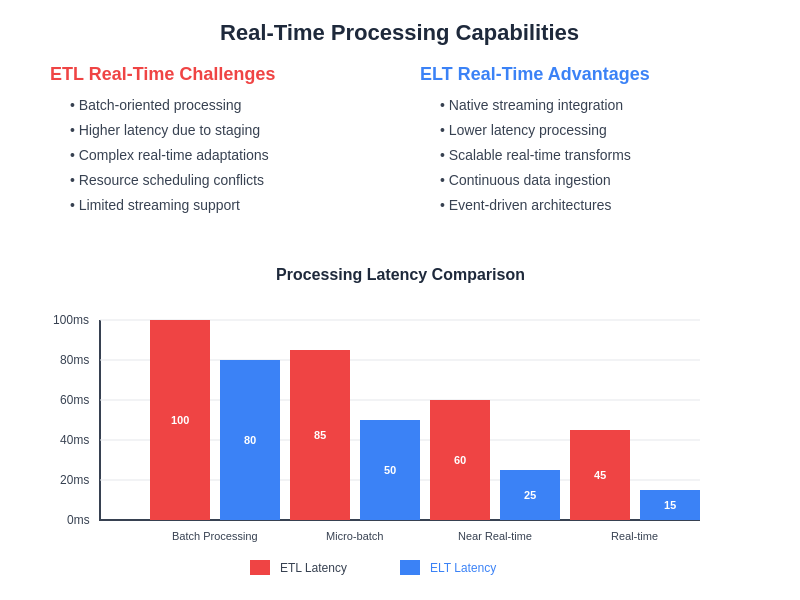
The implementation of real-time capabilities requires careful consideration of latency requirements, data freshness needs, and the complexity of transformation logic that must be applied to streaming data. Organizations must evaluate their specific use cases to determine whether ETL or ELT approaches better align with their real-time processing requirements and technical capabilities.
Tool Ecosystem and Technology Integration
The technology landscape surrounding ETL and ELT methodologies encompasses a diverse ecosystem of tools, platforms, and frameworks that cater to different architectural approaches and organizational requirements. Traditional ETL tools such as Informatica, Talend, and SSIS have established themselves as robust solutions for complex transformation workflows, while newer cloud-native ELT platforms like dbt, Fivetran, and Stitch focus on simplifying data integration and transformation within modern data warehouses.
Machine learning workflows benefit from specialized tools and frameworks that are designed to integrate seamlessly with either ETL or ELT architectures. MLOps platforms such as MLflow, Kubeflow, and Amazon SageMaker provide capabilities that can be adapted to both approaches, while feature stores and model serving platforms must be architected to work effectively with the chosen data pipeline methodology.
The integration complexity varies significantly between ETL and ELT approaches, with ETL systems often requiring more sophisticated orchestration and coordination between multiple specialized tools, while ELT implementations can leverage the integrated capabilities of modern data platforms to reduce the number of distinct technologies that must be managed and maintained.
Open-source alternatives have emerged as viable options for both approaches, with Apache Airflow providing workflow orchestration capabilities, Apache Spark enabling distributed data processing, and cloud-native solutions offering managed services that reduce operational complexity while providing enterprise-grade capabilities for both ETL and ELT implementations.
Security and Compliance Frameworks
Security considerations represent a fundamental aspect of data pipeline architecture that significantly influences the choice between ETL and ELT approaches, particularly for machine learning applications that process sensitive data or operate within regulated industries. ETL methodologies provide enhanced security through centralized transformation processes that enable comprehensive data masking, encryption, and access control implementations before data reaches destination systems.
The security model of ETL systems allows for implementation of defense-in-depth strategies where sensitive data transformations occur within secured processing environments that are isolated from broader organizational networks and systems. This approach facilitates compliance with regulations such as GDPR, HIPAA, and PCI-DSS by providing clear audit trails and ensuring that sensitive data transformations are performed within controlled environments.
ELT approaches require different security strategies due to the storage of raw data within destination systems before transformation occurs. This methodology necessitates robust security controls within data warehouses and analytical platforms, including comprehensive access management, data encryption at rest and in transit, and detailed monitoring of data access and transformation activities.
Modern cloud data platforms provide sophisticated security capabilities that can be leveraged for ELT implementations, including row-level security, column-level encryption, and integration with enterprise identity management systems. However, organizations must carefully evaluate whether these capabilities meet their specific security and compliance requirements, particularly when dealing with highly sensitive data or strict regulatory frameworks.
Performance Optimization Strategies
Optimizing the performance of data pipelines requires different approaches depending on the chosen architecture, with ETL and ELT methodologies presenting distinct opportunities and challenges for achieving optimal processing efficiency. ETL systems can be optimized through careful tuning of transformation logic, efficient resource allocation within processing environments, and strategic caching of intermediate results to reduce computational overhead.
The performance optimization of ETL workflows often focuses on minimizing data movement, optimizing transformation algorithms, and leveraging parallel processing capabilities to maximize throughput while maintaining data quality standards. Advanced ETL platforms provide sophisticated optimization features such as pushdown optimization, intelligent caching, and adaptive resource allocation that can significantly improve processing performance.
ELT performance optimization leverages the inherent capabilities of modern data platforms through query optimization, indexing strategies, and utilization of distributed computing resources. The optimization focus shifts from transformation logic to efficient data storage, query performance, and leveraging platform-specific features such as materialized views, partitioning, and columnar storage formats.
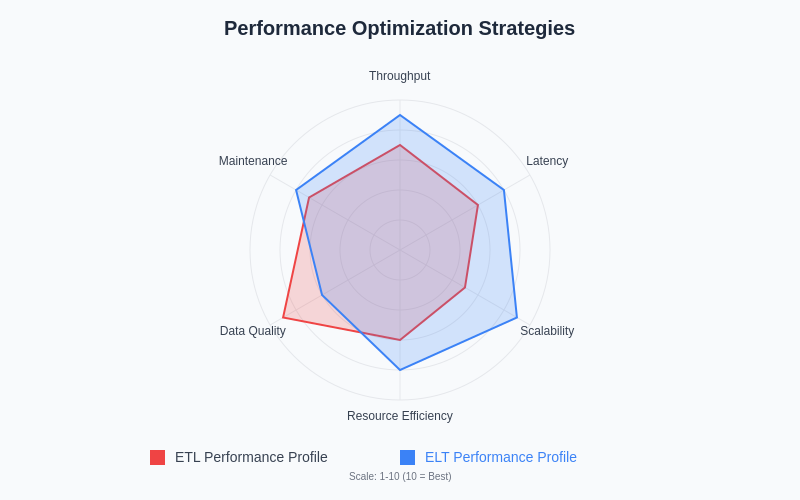
Modern data platforms provide automated optimization capabilities that can significantly enhance ELT performance without requiring manual tuning, including automatic query optimization, adaptive resource allocation, and intelligent caching mechanisms that learn from usage patterns to optimize future processing operations.
Monitoring and Observability Implementation
Effective monitoring and observability strategies are essential for maintaining reliable data pipelines regardless of the chosen architecture, but the implementation approaches differ significantly between ETL and ELT methodologies. ETL systems require comprehensive monitoring of transformation processes, resource utilization within processing environments, and data quality metrics throughout the transformation pipeline.
The distributed nature of ETL architectures necessitates sophisticated monitoring solutions that can track data flow across multiple systems, detect processing bottlenecks, and provide detailed visibility into transformation logic performance. Modern ETL platforms provide integrated monitoring capabilities, while organizations often supplement these with custom monitoring solutions that align with their specific operational requirements.
ELT monitoring focuses primarily on data warehouse performance, query execution efficiency, and data quality within destination systems. The consolidated nature of ELT processing enables simpler monitoring implementations that leverage the native observability features of data platforms while providing comprehensive insights into pipeline performance and data quality.
Advanced monitoring strategies for both approaches incorporate machine learning techniques to detect anomalies, predict performance issues, and automatically optimize pipeline operations based on historical patterns and real-time performance metrics. These intelligent monitoring systems can significantly reduce operational overhead while improving pipeline reliability and performance.
Future Trends and Emerging Technologies
The evolution of data pipeline architectures continues to be shaped by emerging technologies and changing requirements in the machine learning landscape. Hybrid approaches that combine elements of both ETL and ELT methodologies are gaining traction, enabling organizations to leverage the benefits of each approach while addressing specific use case requirements and technical constraints.
Cloud-native architectures are driving innovation in both ETL and ELT implementations through serverless computing, containerized processing environments, and managed services that reduce operational complexity while providing enterprise-grade capabilities. These technological advances enable organizations to focus on business logic and value creation rather than infrastructure management and system optimization.
The integration of artificial intelligence and machine learning capabilities directly into data pipeline platforms represents an emerging trend that promises to automate many aspects of pipeline design, optimization, and maintenance. AI-powered features such as automatic schema detection, intelligent data quality monitoring, and predictive resource scaling are becoming standard capabilities in modern data platforms.
Edge computing and distributed data processing requirements are creating new architectural patterns that blend traditional pipeline concepts with real-time processing capabilities, enabling organizations to process data closer to its source while maintaining centralized coordination and governance. These emerging patterns require careful consideration of the trade-offs between ETL and ELT approaches in distributed computing environments.
The continued advancement of data pipeline technologies promises to simplify the implementation of both ETL and ELT approaches while providing enhanced capabilities for handling the complexity and scale requirements of modern machine learning applications. Organizations that stay informed about these developments and adapt their architectures accordingly will be better positioned to leverage the full potential of their data assets for machine learning initiatives.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of data engineering practices and their applications in machine learning environments. Readers should conduct their own research and consider their specific requirements, compliance obligations, and technical constraints when choosing between ETL and ELT approaches. The effectiveness and suitability of each methodology may vary depending on organizational context, data characteristics, and technical infrastructure.