
The relentless demand for computational power in artificial intelligence and machine learning applications has driven the industry toward specialized hardware solutions that can deliver superior performance while maintaining energy efficiency. Field-Programmable Gate Arrays (FPGAs) have emerged as a compelling alternative to traditional CPUs and GPUs for AI acceleration, offering unique advantages in terms of customization, latency, and power consumption. Among the leading FPGA providers, Xilinx (now part of AMD) and Intel Altera stand as the dominant forces, each offering distinct approaches to AI acceleration that cater to different aspects of machine learning workload optimization.
Discover the latest trends in AI hardware acceleration to understand how FPGA technology is reshaping the landscape of high-performance computing for artificial intelligence applications. The choice between Xilinx and Intel Altera platforms represents a critical decision point for organizations seeking to implement FPGA-based AI acceleration, as each platform brings unique strengths, architectural philosophies, and ecosystem advantages that can significantly impact the success of machine learning deployments.
Understanding FPGA AI Acceleration Fundamentals
Field-Programmable Gate Arrays represent a unique category of semiconductor devices that bridge the gap between the flexibility of software-based solutions and the performance advantages of custom silicon implementations. Unlike fixed-function processors, FPGAs consist of configurable logic blocks, programmable interconnects, and specialized components that can be reconfigured to implement custom digital circuits optimized for specific computational tasks. This reconfigurability makes FPGAs particularly well-suited for AI acceleration, where the ability to implement custom data paths, optimize memory access patterns, and create specialized processing units can deliver substantial performance improvements over general-purpose computing platforms.
The fundamental advantage of FPGA-based AI acceleration lies in the ability to create highly optimized implementations that minimize computational overhead and maximize data throughput. Traditional processors must execute instructions sequentially through predefined execution units, whereas FPGAs can implement parallel processing architectures that are specifically designed for the mathematical operations common in machine learning algorithms. This includes custom implementations of matrix multiplication units, convolution engines, activation function processors, and specialized memory controllers that can significantly accelerate neural network inference and training operations.
The programmable nature of FPGAs also enables dynamic adaptation to different AI model architectures and evolving algorithm requirements. As machine learning research continues to produce new network topologies, optimization techniques, and computational approaches, FPGA implementations can be updated and reconfigured to support these innovations without requiring new hardware deployments. This adaptability represents a significant advantage over fixed-function AI accelerators that may become obsolete as AI algorithms evolve and improve over time.
Xilinx Architecture and AI Acceleration Capabilities
Xilinx has established itself as a pioneering force in FPGA-based AI acceleration through its comprehensive Versal and Zynq UltraScale+ product portfolios, which integrate traditional FPGA fabric with specialized AI processing units and high-performance ARM processors. The Versal ACAP (Adaptive Compute Acceleration Platform) represents Xilinx’s most advanced offering for AI acceleration, featuring dedicated AI engines that can deliver up to 400 TOPS (Tera Operations Per Second) of INT8 performance while maintaining the flexibility to implement custom processing pipelines and data flow architectures.
The architectural philosophy behind Xilinx’s AI acceleration approach centers on heterogeneous computing, where different types of processing units work in concert to optimize overall system performance. The Versal platform combines scalar processors, vector processors, programmable logic, and specialized AI engines within a unified architecture that can be programmed and configured to match the specific requirements of different AI workloads. This approach enables developers to implement hybrid solutions that leverage the strengths of each processing element while minimizing the bottlenecks and inefficiencies that can occur when different computational tasks are forced through inappropriate processing units.
Xilinx’s software ecosystem for AI development revolves around the Vitis unified development platform, which provides high-level synthesis tools, AI model optimization frameworks, and comprehensive debugging and profiling capabilities. The Vitis AI development environment supports popular machine learning frameworks including TensorFlow, PyTorch, and Caffe, enabling developers to import pre-trained models and automatically generate optimized FPGA implementations through advanced compilation and optimization techniques. This toolchain abstracts much of the complexity associated with FPGA development while still providing access to low-level optimization capabilities for performance-critical applications.
Experience advanced AI development capabilities with Claude to explore how modern AI platforms can assist with FPGA development, optimization strategies, and implementation planning for complex machine learning workloads. The integration of AI-powered development tools with FPGA design flows represents an emerging trend that can significantly accelerate the development and deployment of optimized AI acceleration solutions.
Intel Altera Platform Overview and ML Optimization
Intel Altera’s approach to FPGA-based AI acceleration emphasizes tight integration with Intel’s broader ecosystem of processors, memory technologies, and development tools, creating a comprehensive platform that leverages synergies across multiple product lines. The Agilex and Stratix series FPGAs incorporate advanced process technologies, high-bandwidth memory interfaces, and specialized digital signal processing blocks that are optimized for the mathematical operations common in machine learning algorithms. Intel’s acquisition of Altera has enabled deeper integration between FPGA acceleration capabilities and Intel’s CPU and GPU product lines, creating opportunities for heterogeneous computing solutions that span multiple processing paradigms.
The Agilex FPGA family represents Intel’s most recent innovation in AI-optimized FPGA architecture, featuring enhanced DSP blocks, variable-precision arithmetic units, and advanced memory controllers that can deliver significant performance improvements for neural network inference and training workloads. These devices incorporate hardened floating-point units, specialized tensor processing capabilities, and high-speed SerDes interfaces that enable efficient communication with other system components. The architectural design emphasizes modularity and scalability, allowing developers to implement solutions that can grow and adapt as computational requirements evolve over time.
Intel’s software development ecosystem for FPGA-based AI acceleration centers on the OneAPI initiative, which aims to provide a unified programming model that spans CPUs, GPUs, and FPGAs through common development tools and optimization frameworks. The Intel FPGA AI Suite provides comprehensive support for popular machine learning frameworks and includes advanced optimization tools that can automatically generate efficient FPGA implementations from high-level model descriptions. This approach reduces development complexity while enabling fine-grained optimization of performance-critical components through access to low-level hardware features and custom implementation techniques.
Performance Comparison and Benchmarking Analysis
The performance characteristics of Xilinx and Intel Altera FPGA platforms for AI acceleration depend heavily on the specific workload characteristics, implementation methodology, and optimization techniques employed in each solution. Comprehensive benchmarking across different neural network architectures reveals that both platforms can deliver substantial performance improvements over traditional CPU and GPU implementations, though the optimal choice depends on factors such as model complexity, batch size requirements, precision needs, and power consumption constraints.
For convolutional neural network inference workloads, both Xilinx Versal and Intel Agilex platforms demonstrate exceptional performance capabilities, with throughput advantages ranging from 2x to 10x compared to high-end GPUs, depending on the specific network architecture and optimization level. The specialized AI processing units in Xilinx Versal devices excel in dense computation scenarios with regular data access patterns, while Intel Agilex platforms show particular strength in applications requiring high-precision arithmetic operations and complex memory access patterns that benefit from the programmable logic fabric’s flexibility.
Latency characteristics represent another critical performance dimension where FPGA-based solutions demonstrate significant advantages over traditional acceleration platforms. Both Xilinx and Intel Altera FPGAs can achieve sub-millisecond inference latencies for moderately complex neural networks, with deterministic timing characteristics that are essential for real-time applications. The ability to implement custom data paths and eliminate software overhead enables FPGA solutions to achieve consistent, predictable performance that is particularly valuable in edge computing scenarios where response time guarantees are crucial for application success.
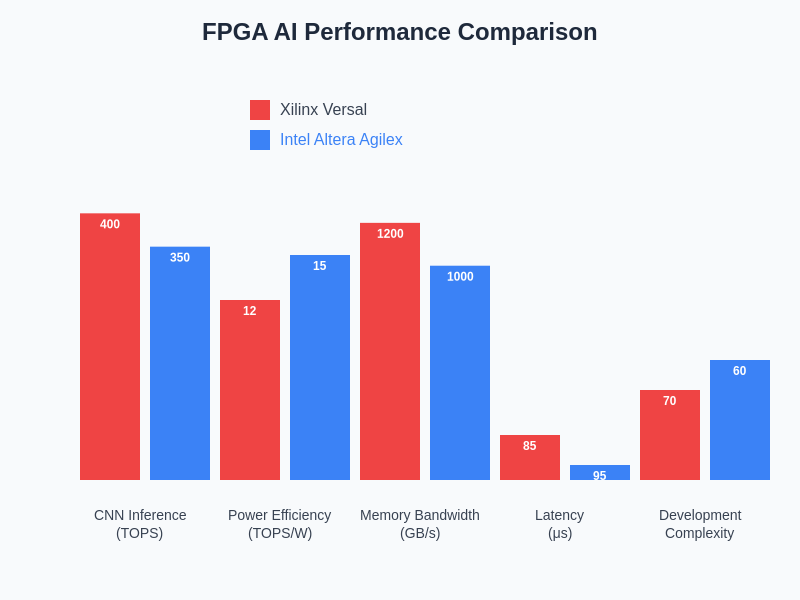
The comparative performance analysis reveals distinct strengths and optimization opportunities for each platform, with performance advantages varying significantly based on workload characteristics and implementation approaches. Understanding these performance trade-offs is essential for making informed platform selection decisions that align with specific application requirements and development constraints.
Development Ecosystem and Tool Comparison
The development ecosystem surrounding FPGA-based AI acceleration represents a critical factor in platform selection, as the availability of comprehensive tools, documentation, and community support can significantly impact development productivity and time-to-market objectives. Xilinx’s Vitis platform provides an extensive suite of development tools that span high-level synthesis, AI model optimization, system-level integration, and performance analysis capabilities. The platform’s integration with popular machine learning frameworks enables rapid prototyping and deployment of AI acceleration solutions while maintaining access to low-level optimization capabilities for performance-critical applications.
Intel’s development ecosystem leverages the company’s extensive experience in software development tools and compiler technologies, providing a comprehensive development environment that emphasizes productivity and ease of use. The OneAPI framework enables developers to create applications that can target multiple processing architectures through a unified programming model, reducing the complexity associated with heterogeneous computing implementations. The Intel FPGA AI Suite includes specialized tools for neural network optimization, quantization, and deployment that can automatically generate efficient FPGA implementations from standard AI model formats.
Both platforms provide extensive simulation and verification capabilities that enable thorough testing and validation of AI acceleration implementations before hardware deployment. The availability of cloud-based development environments allows developers to access advanced FPGA resources without requiring significant upfront hardware investments, accelerating the development process and enabling broader experimentation with different optimization techniques and architectural approaches.
Enhance your research capabilities with Perplexity to access comprehensive information about FPGA development methodologies, optimization techniques, and implementation best practices for AI acceleration applications. The combination of advanced AI research capabilities with specialized FPGA knowledge creates opportunities for innovative solutions that push the boundaries of performance and efficiency in machine learning acceleration.
Power Efficiency and Thermal Considerations
Power efficiency represents a fundamental advantage of FPGA-based AI acceleration, particularly in edge computing and mobile applications where energy consumption directly impacts system viability and operational costs. Both Xilinx and Intel Altera platforms demonstrate superior power efficiency compared to high-performance GPUs and server-class CPUs when implementing optimized AI acceleration solutions. The ability to implement custom data paths that eliminate unnecessary computational overhead and optimize memory access patterns enables FPGA solutions to achieve higher performance per watt ratios that are particularly valuable in power-constrained environments.
Xilinx’s Versal platform incorporates advanced power management features including dynamic voltage and frequency scaling, clock gating, and power island isolation that enable fine-grained control over power consumption based on workload requirements. The heterogeneous architecture allows different processing elements to be independently power-managed, ensuring that energy is consumed only by active computational units while idle components remain in low-power states. This granular power management capability is particularly beneficial for AI applications with variable computational loads that can benefit from dynamic power optimization strategies.
Intel Agilex FPGAs leverage advanced process technologies and architectural innovations to achieve industry-leading power efficiency for AI acceleration workloads. The platform’s variable-precision arithmetic units enable optimal power consumption by using only the precision required for specific computational tasks, while advanced memory controllers minimize power consumption associated with data movement and storage operations. The integration with Intel’s broader ecosystem of power management technologies enables comprehensive system-level power optimization that spans multiple processing elements and system components.
Thermal management considerations play a crucial role in FPGA-based AI acceleration system design, as sustained high-performance operation requires effective heat dissipation strategies that maintain device reliability while enabling maximum computational throughput. Both Xilinx and Intel Altera platforms provide comprehensive thermal monitoring and management capabilities that enable proactive thermal control and system protection. The ability to implement custom thermal management algorithms within the FPGA fabric enables adaptive performance scaling that maintains optimal operation across varying environmental conditions and workload characteristics.
Memory Architecture and Bandwidth Optimization
Memory architecture and bandwidth optimization represent critical factors in FPGA-based AI acceleration performance, as the computational intensity of machine learning algorithms places substantial demands on memory subsystems that must efficiently support high-throughput data movement and storage operations. Both Xilinx and Intel Altera platforms incorporate advanced memory controller technologies and high-bandwidth interface capabilities that enable efficient utilization of external memory resources while minimizing latency and power consumption associated with data access operations.
Xilinx Versal devices support multiple memory technologies including DDR4, DDR5, HBM2, and LPDDR4, providing flexibility in memory subsystem design that can be optimized for specific application requirements and cost constraints. The platform’s memory controllers incorporate advanced features such as error correction, bandwidth optimization, and quality-of-service management that ensure reliable and efficient memory access across different workload scenarios. The integration of high-bandwidth memory interfaces enables support for memory-intensive AI workloads that require substantial data throughput capabilities.
Intel Agilex FPGAs provide comprehensive memory interface capabilities that leverage Intel’s expertise in memory controller design and optimization technologies. The platform supports advanced memory standards and incorporates specialized memory optimization features that can significantly improve overall system performance for AI acceleration applications. The availability of multiple memory interface options enables flexible system architecture designs that can be tailored to specific performance, power, and cost requirements.
The programmable logic fabric in both platforms enables implementation of custom memory management and data movement strategies that can be optimized for specific AI algorithm characteristics and data access patterns. This includes the ability to implement specialized caching mechanisms, data prefetching strategies, and memory bandwidth optimization techniques that can significantly improve overall system performance while reducing power consumption associated with memory operations.
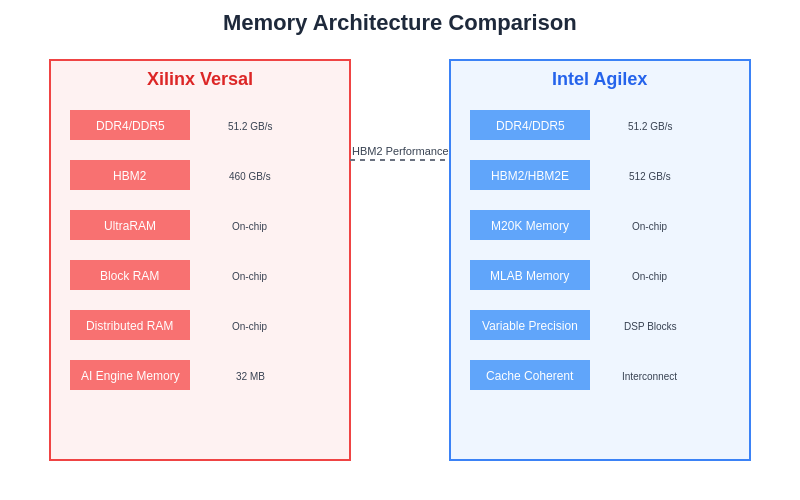
The memory architecture capabilities of each platform significantly impact overall AI acceleration performance, with optimization opportunities varying based on workload characteristics and implementation strategies. Understanding these memory-related performance factors is essential for developing efficient AI acceleration solutions that maximize computational throughput while minimizing resource consumption.
AI Model Deployment and Optimization Strategies
The deployment and optimization of AI models on FPGA platforms requires specialized techniques and methodologies that leverage the unique capabilities of reconfigurable hardware while addressing the constraints and limitations associated with FPGA implementations. Both Xilinx and Intel Altera platforms provide comprehensive model optimization tools that can automatically generate efficient FPGA implementations from popular machine learning frameworks, though achieving optimal performance often requires manual optimization and fine-tuning of implementation parameters and architectural choices.
Model quantization represents a critical optimization technique for FPGA-based AI acceleration, as reducing numerical precision can significantly improve computational throughput, reduce memory bandwidth requirements, and decrease power consumption while maintaining acceptable accuracy levels. Both platforms support various quantization strategies including INT8, INT4, and mixed-precision implementations that enable developers to optimize the trade-off between computational efficiency and model accuracy based on specific application requirements. Advanced quantization techniques such as post-training quantization and quantization-aware training are supported through comprehensive toolchains that automate much of the optimization process.
Neural network pruning and sparsity exploitation represent additional optimization opportunities that can significantly improve FPGA implementation efficiency by eliminating unnecessary computations and optimizing resource utilization. Both platforms provide tools and techniques for implementing sparse neural network acceleration that can take advantage of the programmable logic fabric’s flexibility to create custom processing architectures optimized for sparse computation patterns. These optimizations can deliver substantial performance improvements while reducing power consumption and resource requirements.
Pipeline optimization and dataflow management are crucial for achieving maximum performance in FPGA-based AI acceleration implementations. The ability to implement custom pipeline architectures that optimize data movement and computational overlap enables significant performance improvements over conventional processing approaches. Both Xilinx and Intel Altera platforms provide design tools and optimization frameworks that assist developers in creating efficient pipeline implementations while managing the complexity associated with concurrent data processing and resource sharing.
Edge Computing and Real-Time Applications
FPGA-based AI acceleration demonstrates particular advantages in edge computing and real-time application scenarios where low latency, deterministic performance, and power efficiency are critical requirements. Both Xilinx and Intel Altera platforms offer specialized product variants and optimization features that are specifically designed for edge deployment scenarios, including compact form factors, extended temperature ranges, and integrated connectivity options that simplify system integration and deployment processes.
The deterministic timing characteristics of FPGA implementations enable predictable performance that is essential for real-time AI applications such as autonomous vehicle control, industrial automation, and medical device monitoring. Unlike software-based implementations that may experience variable execution times due to operating system overhead and resource contention, FPGA solutions can provide guaranteed response times and consistent computational throughput that meet the stringent timing requirements of safety-critical applications.
Edge deployment scenarios often involve resource-constrained environments where power consumption, thermal dissipation, and physical size represent significant design constraints. Both FPGA platforms provide power optimization features and compact packaging options that enable deployment in mobile, battery-powered, and space-constrained applications while maintaining high computational performance. The ability to implement custom power management strategies within the programmable logic fabric enables adaptive optimization that can extend battery life and reduce thermal requirements in challenging deployment environments.
Connectivity and communication capabilities represent important considerations for edge AI acceleration applications that must interface with various sensors, actuators, and communication networks. Both Xilinx and Intel Altera platforms provide comprehensive I/O capabilities and communication protocol support that enables direct integration with edge computing infrastructure while minimizing the need for additional interface components and reducing overall system complexity and cost.
Cloud and Datacenter Deployment Considerations
The deployment of FPGA-based AI acceleration in cloud and datacenter environments presents unique opportunities and challenges that differ significantly from edge computing scenarios. Both Xilinx and Intel Altera platforms offer high-performance variants specifically designed for datacenter deployment, featuring enhanced computational capabilities, advanced connectivity options, and management features that enable efficient integration with existing cloud infrastructure and virtualization platforms.
Virtualization and multi-tenancy support represent critical requirements for cloud deployment scenarios where FPGA resources must be efficiently shared among multiple users and applications. Both platforms provide hardware and software features that enable secure partitioning of FPGA resources, allowing multiple independent AI acceleration tasks to execute concurrently while maintaining isolation and performance guarantees. This capability is essential for cloud service providers that must efficiently utilize expensive FPGA hardware across diverse customer workloads and applications.
Scalability and cluster-level optimization capabilities enable FPGA-based AI acceleration to address large-scale machine learning workloads that require distributed processing across multiple devices and compute nodes. Both platforms support advanced interconnect technologies and cluster management frameworks that enable efficient scaling of AI acceleration capabilities while maintaining low-latency communication and synchronized operation across multiple FPGA devices. These capabilities are particularly important for training large neural networks and processing massive datasets that exceed the capacity of individual acceleration devices.
Management and monitoring capabilities represent essential features for datacenter deployment scenarios where automated resource allocation, performance monitoring, and fault detection are required for efficient operation. Both Xilinx and Intel Altera platforms provide comprehensive management interfaces and monitoring capabilities that enable integration with existing datacenter management systems while providing detailed visibility into FPGA utilization, performance metrics, and operational status.
Cost Analysis and Return on Investment
The economic considerations associated with FPGA-based AI acceleration encompass multiple factors including initial hardware costs, development expenses, operational costs, and potential performance benefits that must be carefully evaluated to determine overall return on investment. Both Xilinx and Intel Altera platforms span a wide range of price points and performance capabilities, enabling organizations to select solutions that align with specific budget constraints and performance requirements while optimizing total cost of ownership over the system lifecycle.
Development costs represent a significant consideration for FPGA-based AI acceleration projects, as the specialized skills and extended development timelines required for FPGA implementation can substantially impact project economics. Both platforms provide high-level development tools and optimization frameworks that can reduce development complexity and accelerate time-to-market, though achieving optimal performance often requires specialized expertise and iterative optimization processes that add to overall project costs. The availability of pre-optimized IP cores, reference designs, and consulting services can help mitigate development risks and reduce overall project costs.
Operational cost considerations include power consumption, cooling requirements, maintenance expenses, and infrastructure costs that can significantly impact the long-term economics of FPGA-based AI acceleration deployments. The superior power efficiency of FPGA solutions compared to GPU-based alternatives can result in substantial operational cost savings in large-scale deployments, particularly in scenarios where electricity costs and cooling requirements represent significant operational expenses. The longer operational lifespans and lower failure rates typical of FPGA devices can also contribute to reduced maintenance costs and improved system reliability.
Performance benefits and revenue opportunities enabled by FPGA-based AI acceleration must be quantified and compared against implementation costs to determine overall project viability and return on investment. Applications that can benefit from reduced latency, improved throughput, or enhanced accuracy may generate substantial business value that justifies the additional complexity and cost associated with FPGA implementation. The ability to implement custom optimization strategies and adapt to evolving algorithm requirements can provide competitive advantages that generate ongoing value throughout the system lifecycle.
Future Trends and Technology Roadmap
The evolution of FPGA technology for AI acceleration continues to advance through architectural innovations, process technology improvements, and software development tool enhancements that promise to further improve performance, reduce development complexity, and expand application opportunities. Both Xilinx and Intel Altera have published technology roadmaps that indicate continued investment in AI-specific features, enhanced development tools, and tighter integration with emerging AI frameworks and methodologies.
Next-generation FPGA architectures are incorporating increasingly sophisticated AI acceleration features including dedicated neural processing units, advanced numeric formats, and specialized memory hierarchies that are optimized for machine learning workloads. The integration of hybrid computing elements that combine traditional programmable logic with fixed-function AI acceleration units promises to deliver improved performance density while maintaining the flexibility advantages that distinguish FPGA solutions from fixed-function alternatives.
Software development tool evolution represents a critical factor in expanding FPGA adoption for AI acceleration, as improvements in high-level synthesis, automatic optimization, and debug capabilities can significantly reduce the expertise and development time required for successful FPGA implementation. Both vendors are investing heavily in AI-assisted development tools that can automate many of the complex optimization decisions required for efficient FPGA implementation while providing guidance and feedback that helps developers understand and optimize their designs.
The convergence of FPGA technology with emerging computing paradigms including quantum computing, neuromorphic processing, and edge AI inference represents an exciting frontier that could unlock new application opportunities and performance capabilities. The programmable nature of FPGA devices positions them well to serve as research and development platforms for exploring these emerging technologies while providing pathways for transitioning experimental approaches into production-ready implementations.
Conclusion and Platform Selection Guidelines
The selection between Xilinx and Intel Altera FPGA platforms for AI acceleration represents a complex decision that must consider multiple technical, economic, and strategic factors specific to each application scenario and organizational context. Both platforms offer compelling capabilities and advantages that can deliver substantial benefits for appropriately matched use cases, though the optimal choice depends heavily on specific requirements, constraints, and objectives that vary significantly across different applications and deployment scenarios.
Organizations prioritizing maximum computational performance and advanced AI-specific features may find Xilinx Versal platforms particularly attractive due to their dedicated AI processing units and comprehensive optimization tools. The platform’s heterogeneous architecture and extensive software ecosystem provide excellent capabilities for demanding AI acceleration applications that require both high performance and implementation flexibility. The strong ecosystem of partners, consultants, and third-party IP providers further enhances the platform’s appeal for complex projects that can benefit from external expertise and pre-developed solutions.
Intel Altera platforms offer compelling advantages for organizations that value tight integration with Intel’s broader technology ecosystem and prefer development environments that leverage familiar Intel software tools and methodologies. The platform’s emphasis on unified programming models and cross-architecture compatibility can simplify development for teams with existing Intel technology expertise while providing pathways for implementing heterogeneous computing solutions that span multiple processing paradigms. The extensive Intel partner ecosystem and established enterprise relationships provide additional support and integration opportunities.
The decision between platforms should ultimately be based on comprehensive evaluation of specific application requirements, performance objectives, development constraints, and long-term strategic considerations. Prototype development and proof-of-concept implementations using both platforms may be necessary for applications with demanding performance requirements or unique constraints that make platform selection particularly critical for project success.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of FPGA technologies and their applications in AI acceleration. Readers should conduct their own research and consider their specific requirements when selecting FPGA platforms for AI acceleration applications. Performance characteristics and capabilities may vary depending on specific implementations, optimization techniques, and application requirements. Organizations should engage with qualified technical consultants and conduct thorough evaluations before making platform selection decisions for critical applications.