
The artificial intelligence revolution has demanded unprecedented computational power, driving the evolution of specialized hardware architectures designed to handle the unique requirements of machine learning workloads. Three distinct categories of processors have emerged as dominant forces in the AI computing landscape: Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), and Neural Processing Units (NPUs). Each architecture brings distinct advantages and optimization strategies that cater to different aspects of artificial intelligence computation, from training massive neural networks to enabling real-time inference on edge devices.
Understanding the fundamental differences between these processor architectures has become crucial for organizations and developers seeking to optimize their AI implementations for maximum performance, efficiency, and cost-effectiveness. The choice between GPU, TPU, and NPU solutions can significantly impact project timelines, operational costs, and the feasibility of deploying AI applications across various environments, from cloud-based training clusters to mobile devices and embedded systems.
Explore the latest AI hardware trends to stay informed about emerging processor technologies and their applications in cutting-edge machine learning projects. The rapid pace of innovation in AI chip design continues to push the boundaries of computational efficiency while opening new possibilities for artificial intelligence applications across diverse industries and use cases.
Graphics Processing Units: The Foundation of Modern AI Computing
Graphics Processing Units have established themselves as the cornerstone of artificial intelligence computing, leveraging their massively parallel architecture originally designed for rendering complex graphics to excel at the matrix operations fundamental to machine learning algorithms. The parallel processing capabilities of GPUs, with thousands of cores operating simultaneously, provide exceptional performance for training deep neural networks and executing inference tasks that require substantial computational throughput.
The versatility of GPU architectures has made them the de facto standard for AI research and development, offering broad compatibility with popular machine learning frameworks such as TensorFlow, PyTorch, and various CUDA-optimized libraries. This widespread adoption has created a robust ecosystem of tools, libraries, and optimization techniques specifically designed to maximize GPU performance in artificial intelligence applications, making GPUs accessible to both experienced researchers and newcomers to the field.
Modern GPU architectures incorporate specialized tensor cores and mixed-precision computing capabilities that significantly accelerate neural network training and inference operations. These hardware optimizations, combined with sophisticated memory hierarchies and high-bandwidth interconnects, enable GPUs to handle increasingly complex models while maintaining reasonable energy efficiency for their computational output.
Tensor Processing Units: Google’s Specialized AI Architecture
Tensor Processing Units represent a fundamental shift toward application-specific integrated circuits designed exclusively for artificial intelligence workloads, particularly those involving neural network operations. Developed by Google to address the computational demands of their internal AI applications, TPUs optimize the specific mathematical operations most commonly used in machine learning, including matrix multiplications, convolutions, and activation functions.
The architectural design of TPUs emphasizes maximum efficiency for tensor operations through dedicated matrix multiplication units, large on-chip memory systems, and streamlined data paths that minimize energy consumption per operation. This specialization allows TPUs to achieve remarkable performance per watt ratios when executing compatible AI workloads, making them particularly attractive for large-scale training operations and high-volume inference deployments.
Discover advanced AI processing capabilities with Claude to explore how different processor architectures can be leveraged for various machine learning tasks and optimization strategies. The integration of TPUs into cloud computing platforms has democratized access to specialized AI hardware while providing scalable solutions for organizations requiring substantial computational resources.
TPU architecture incorporates sophisticated interconnect technologies that enable seamless scaling across multiple processing units, creating powerful distributed computing systems capable of training the largest neural networks currently feasible. The systolic array design and custom instruction set of TPUs optimize data flow patterns specific to neural network computations, resulting in superior efficiency compared to general-purpose processors when executing compatible workloads.
Neural Processing Units: Edge AI and Efficient Inference
Neural Processing Units have emerged as the specialized solution for edge computing applications where power efficiency, compact form factors, and real-time performance requirements demand highly optimized hardware architectures. Unlike their GPU and TPU counterparts designed primarily for data center environments, NPUs focus on delivering maximum inference performance per watt while maintaining compatibility with diverse deployment scenarios including mobile devices, autonomous vehicles, and Internet of Things applications.
The architectural philosophy behind NPUs emphasizes dataflow optimization and minimal power consumption through dedicated neural network accelerators, efficient memory systems, and specialized instruction sets tailored for common AI operations. This focus on efficiency enables NPUs to deliver impressive inference performance while operating within the strict power and thermal constraints typical of edge computing environments.
Modern NPU designs incorporate advanced features such as dynamic voltage and frequency scaling, intelligent workload scheduling, and support for quantized neural network models that further enhance energy efficiency without significantly compromising accuracy. These optimizations make NPUs particularly suitable for applications requiring continuous AI processing, such as computer vision systems, natural language processing on mobile devices, and real-time sensor data analysis.
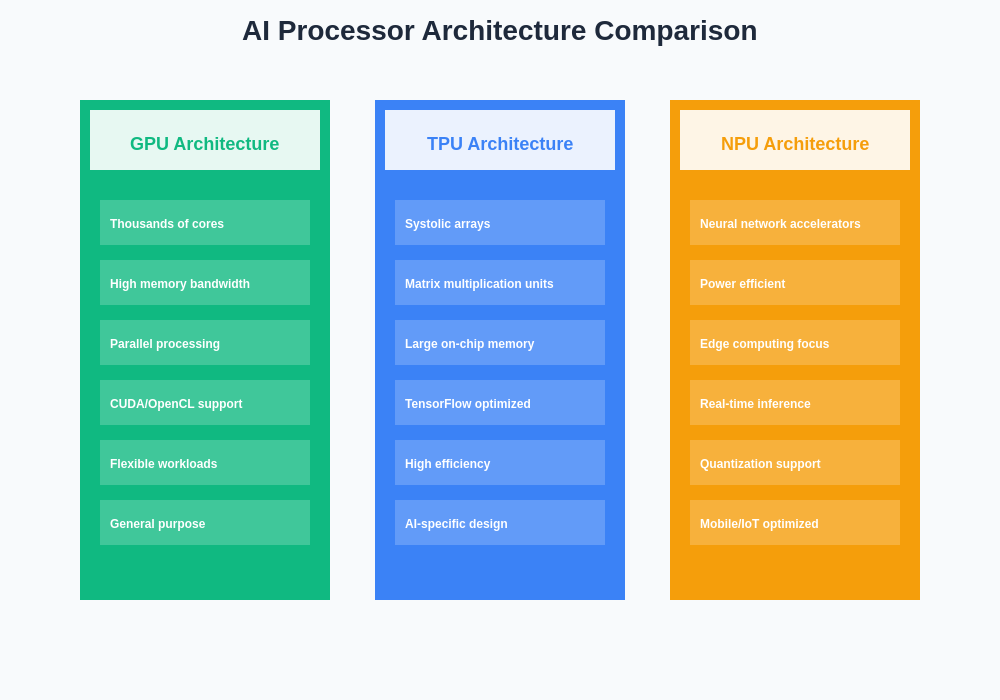
The fundamental architectural differences between GPU, TPU, and NPU designs reflect their respective optimization priorities and target applications. While GPUs excel at parallel general-purpose computing with thousands of cores optimized for diverse workloads, TPUs maximize tensor operation efficiency through specialized systolic arrays and matrix multiplication units, and NPUs prioritize power-constrained inference performance with neural network accelerators designed for edge computing scenarios.
Performance Characteristics and Benchmarking
Evaluating the performance characteristics of GPU, TPU, and NPU architectures requires careful consideration of multiple factors including computational throughput, memory bandwidth, energy efficiency, and compatibility with specific AI workloads. GPUs typically excel in scenarios requiring high parallel processing capability and broad framework compatibility, making them ideal for research environments and applications requiring flexibility in model architectures and training approaches.
TPUs demonstrate superior performance in large-scale training scenarios involving standard neural network architectures, particularly transformer models and convolutional neural networks that align well with TPU optimization strategies. The specialized nature of TPU architecture enables exceptional performance per dollar and per watt metrics when executing compatible workloads, though this specialization may limit flexibility for novel or experimental neural network designs.
NPUs achieve optimal performance in inference-focused applications where power efficiency and real-time response requirements take precedence over absolute computational throughput. The specialized optimization for common neural network operations enables NPUs to deliver impressive inference performance while maintaining power consumption levels suitable for battery-operated devices and embedded systems.
Enhance your AI research capabilities with Perplexity to access comprehensive performance data and benchmark results across different processor architectures and AI workloads. The complexity of modern AI applications often requires careful analysis of multiple performance metrics to determine the most suitable hardware architecture for specific use cases.
Training Performance and Scalability Considerations
The training phase of machine learning model development presents unique computational challenges that highlight the distinct advantages of each processor architecture. GPU-based training systems offer exceptional flexibility and broad compatibility with diverse neural network architectures, making them particularly valuable for research environments where experimental models and novel training approaches are common. The extensive software ecosystem surrounding GPU computing provides researchers and developers with sophisticated tools for optimization, debugging, and performance analysis.
TPU architectures excel in large-scale training scenarios involving well-established neural network designs, particularly those utilizing transformer architectures or convolutional networks that align with TPU optimization strategies. The ability to seamlessly scale TPU systems across hundreds or thousands of processing units enables training of the largest neural networks currently feasible, while the specialized tensor operations provide exceptional efficiency for standard training algorithms.
The distributed training capabilities of both GPU and TPU systems enable organizations to tackle increasingly complex machine learning challenges through coordinated parallel processing across multiple devices. However, the specific optimization strategies and communication patterns differ significantly between architectures, requiring careful consideration of model design and training algorithm selection to achieve optimal performance.
Inference Optimization and Deployment Strategies
Inference deployment represents a critical phase where the choice of processor architecture significantly impacts application performance, operational costs, and user experience. GPU-based inference systems provide excellent performance for applications requiring high throughput batch processing or real-time inference with complex models that benefit from parallel processing capabilities. The flexibility of GPU architectures enables deployment of diverse model types while maintaining reasonable performance characteristics across various application scenarios.
TPU inference systems demonstrate exceptional efficiency for applications involving standard neural network architectures deployed at scale, particularly in cloud environments where consistent workloads and predictable usage patterns enable optimal resource utilization. The specialized tensor operations and efficient memory systems of TPUs provide superior performance per dollar metrics for compatible inference workloads.
NPU architectures excel in edge inference scenarios where power efficiency, compact form factors, and real-time performance requirements demand specialized optimization. The ability to execute neural network inference with minimal power consumption enables continuous AI processing in battery-operated devices while maintaining acceptable performance levels for user-facing applications.
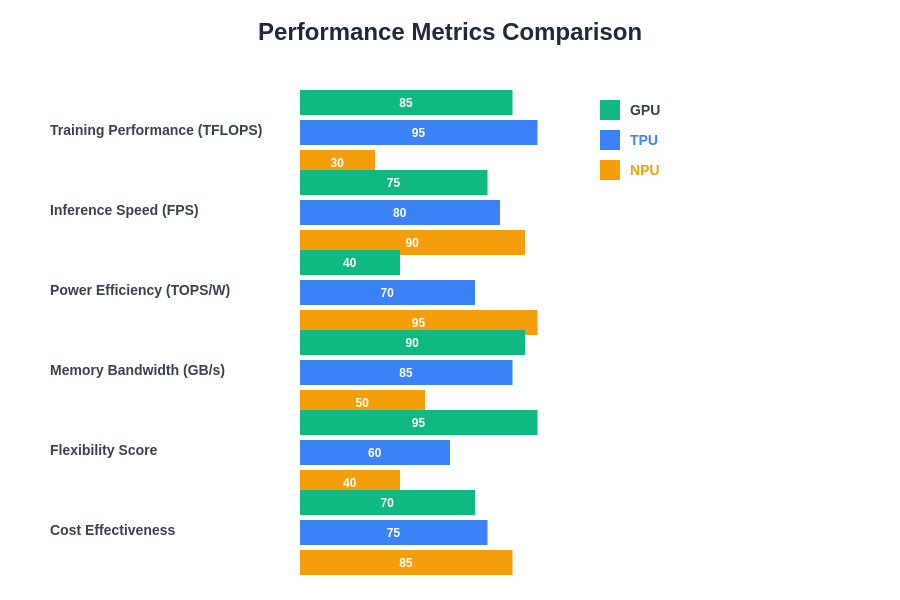
The comparative performance characteristics across different AI workloads reveal the specialized strengths of each processor architecture. GPUs demonstrate exceptional training performance and flexibility, TPUs excel in inference speed and specialized tensor operations, while NPUs achieve superior power efficiency ratings. These metrics highlight the importance of matching hardware capabilities to specific application requirements and deployment constraints.
Memory Architecture and Data Flow Optimization
The memory subsystem design represents a fundamental differentiator between GPU, TPU, and NPU architectures, with each approach optimized for specific data access patterns and computational requirements typical of their target applications. GPU memory architectures emphasize high bandwidth and large capacity to support diverse workloads, utilizing sophisticated caching hierarchies and memory management techniques to maximize utilization of available computational resources.
TPU memory systems focus on optimizing data flow patterns specific to tensor operations, incorporating large on-chip memory arrays and specialized interconnects that minimize data movement overhead during neural network computations. This optimization enables TPUs to achieve superior efficiency for compatible workloads while reducing energy consumption associated with memory operations.
NPU memory architectures prioritize power efficiency and compact implementation through specialized memory systems designed for common neural network data patterns. The integration of memory and processing elements in NPU designs enables efficient execution of inference operations while maintaining the low power consumption essential for edge computing applications.
The sophisticated memory management capabilities of modern AI processors include features such as automatic data prefetching, intelligent caching strategies, and optimized data layout techniques that significantly impact overall system performance. Understanding these memory architecture differences is crucial for optimizing AI applications and achieving maximum performance from available hardware resources.
Software Ecosystem and Development Tools
The software development ecosystem surrounding each processor architecture significantly influences adoption rates, development productivity, and long-term maintainability of AI applications. GPU computing benefits from a mature and comprehensive software stack including CUDA, ROCm, and various machine learning frameworks that provide extensive optimization capabilities and debugging tools for AI developers.
The TPU software ecosystem, while more specialized, offers tight integration with TensorFlow and other Google AI frameworks, providing streamlined development experiences for compatible applications. The cloud-based nature of most TPU deployments simplifies infrastructure management while providing access to sophisticated optimization tools and performance analysis capabilities.
NPU development environments vary significantly across different vendors and platforms, with emerging standards and tools gradually consolidating around common development approaches. The diversity of NPU implementations requires careful evaluation of software support and long-term compatibility when selecting hardware platforms for edge AI applications.
Cross-platform compatibility and portability considerations become increasingly important as organizations deploy AI applications across diverse hardware environments. The availability of hardware abstraction layers and portable optimization libraries can significantly impact development efficiency and application maintainability across different processor architectures.
Cost Analysis and Total Ownership Considerations
The economic factors associated with GPU, TPU, and NPU deployments extend beyond initial hardware acquisition costs to include operational expenses, development resources, and long-term maintenance requirements. GPU systems typically require significant upfront investment in hardware and infrastructure but offer flexibility that can reduce development costs and time-to-market for diverse AI applications.
TPU deployments often utilize cloud-based pricing models that can provide cost advantages for applications with predictable workloads and consistent usage patterns, while the specialized nature of TPU architecture may require additional development resources for optimization and troubleshooting. The pay-per-use pricing structure of cloud TPU services can be particularly attractive for organizations with variable computational requirements.
NPU solutions designed for edge deployment focus on minimizing operational costs through power efficiency and reduced infrastructure requirements, though the specialized nature of many NPU platforms may increase development complexity and limit vendor options for long-term support and maintenance.
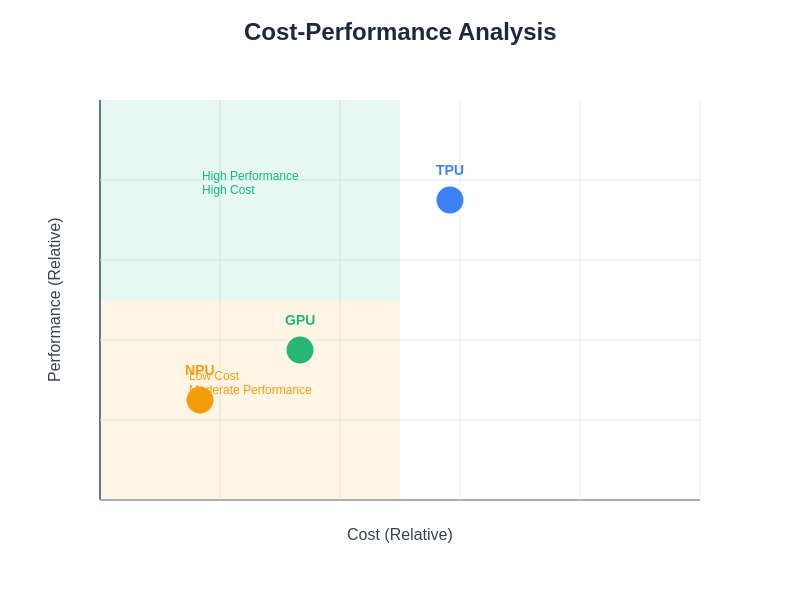
The comprehensive cost-performance analysis reveals the complex trade-offs between different processor architectures across various deployment scenarios. GPUs occupy the high-performance, high-cost quadrant suitable for research and flexible applications, TPUs provide optimal cost-performance ratios for large-scale specialized workloads, while NPUs deliver cost-effective solutions for power-constrained edge deployments. Total cost of ownership calculations must consider hardware costs, development resources, operational expenses, and long-term maintenance requirements.
Energy Efficiency and Sustainability Implications
Energy consumption has become a critical factor in AI hardware selection as organizations increasingly focus on sustainability and operational cost management. The massive computational requirements of modern AI applications can result in significant energy consumption, making processor efficiency a primary consideration for large-scale deployments and environmentally conscious organizations.
GPU architectures have made substantial improvements in energy efficiency through architectural optimizations, advanced manufacturing processes, and intelligent power management systems. However, the general-purpose nature of GPUs inherently limits their efficiency compared to specialized processors designed specifically for AI workloads.
TPU designs prioritize energy efficiency through specialized tensor operations and optimized data flow patterns that minimize unnecessary computational overhead. The focused architecture enables TPUs to achieve superior performance per watt metrics for compatible AI workloads, resulting in reduced operational costs and environmental impact for large-scale training and inference operations.
NPU architectures represent the pinnacle of energy efficiency for AI inference applications, utilizing specialized designs that maximize computational output while minimizing power consumption. This efficiency enables continuous AI processing in power-constrained environments while reducing operational costs and extending battery life in mobile applications.
The environmental implications of AI hardware choices extend beyond direct energy consumption to include manufacturing processes, lifecycle considerations, and disposal or recycling requirements. Organizations increasingly consider these factors when evaluating processor architectures for long-term AI strategy development.
Future Technological Trends and Evolution
The rapid evolution of AI hardware architectures continues to drive innovation across GPU, TPU, and NPU designs, with emerging technologies promising even greater performance, efficiency, and capability improvements in future generations. Advanced manufacturing processes enable increased transistor density and improved power efficiency while opening possibilities for novel architectural approaches that were previously impractical.
The integration of emerging technologies such as optical computing, quantum processing elements, and neuromorphic architectures may fundamentally alter the competitive landscape between different processor types. These innovations could enable breakthrough improvements in specific AI applications while potentially creating entirely new categories of specialized processors optimized for novel computational approaches.
The convergence of different processor architectures through hybrid designs that combine GPU flexibility, TPU efficiency, and NPU power optimization represents a promising direction for future AI hardware development. Such integrated approaches could provide optimal performance across diverse workloads while simplifying deployment and development complexity for AI applications.
Research into advanced memory technologies, including high-bandwidth memory systems, near-memory computing, and novel storage approaches, continues to address the memory bottlenecks that often limit AI application performance. These improvements will likely benefit all processor architectures while enabling new possibilities for large-scale AI deployments.
Implementation Guidelines and Best Practices
Selecting the optimal processor architecture for specific AI applications requires careful analysis of workload characteristics, performance requirements, deployment constraints, and long-term strategic objectives. GPU solutions typically provide the best choice for research environments, diverse application portfolios, and scenarios requiring maximum flexibility in model architecture and training approaches.
TPU architectures excel in production environments with well-defined neural network models, large-scale training requirements, and consistent workload patterns that align with TPU optimization strategies. The cloud-based nature of most TPU deployments makes them particularly suitable for organizations seeking to minimize infrastructure management overhead while accessing cutting-edge AI processing capabilities.
NPU implementations represent the optimal choice for edge computing applications where power efficiency, real-time performance, and compact form factors take precedence over absolute computational throughput. The specialized optimization for inference operations makes NPUs particularly valuable for mobile applications, IoT devices, and autonomous systems requiring continuous AI processing capabilities.
The successful implementation of any AI hardware architecture requires careful attention to software optimization, data pipeline efficiency, and system integration considerations. Organizations should invest in understanding the specific optimization techniques and best practices associated with their chosen processor architecture to achieve maximum performance and return on investment.
Strategic Considerations for Organizations
The long-term strategic implications of AI hardware choices extend beyond immediate technical requirements to encompass vendor relationships, technological roadmaps, and evolving industry standards. Organizations must balance current performance needs with future scalability requirements while considering the rapidly evolving landscape of AI hardware technologies.
The development of internal expertise and technical capabilities specific to chosen processor architectures represents a significant investment that influences long-term flexibility and competitive advantage. Organizations should consider the availability of skilled professionals, training resources, and ongoing support when evaluating different hardware platforms for strategic AI initiatives.
Vendor ecosystem stability, long-term roadmap alignment, and compatibility with emerging standards become increasingly important factors as AI applications mature and require sustained support over extended operational lifespans. The ability to adapt to evolving requirements while maintaining performance and cost effectiveness depends heavily on the strategic choices made during initial platform selection.
The integration of AI hardware decisions with broader organizational technology strategies ensures optimal alignment with business objectives while maximizing the value derived from AI investments. This holistic approach enables organizations to build sustainable competitive advantages through effective utilization of appropriate AI processing capabilities.
The future of artificial intelligence computing will likely involve sophisticated combinations of GPU, TPU, and NPU technologies, each contributing their specialized strengths to create comprehensive AI processing systems capable of handling the full spectrum of machine learning workloads. Understanding the unique characteristics and optimal applications of each processor architecture enables organizations to make informed decisions that maximize the effectiveness of their AI initiatives while positioning themselves for continued success in an increasingly AI-driven competitive landscape.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of AI processor technologies and their applications. Readers should conduct their own research and consider their specific requirements when selecting hardware architectures for AI applications. Performance characteristics and cost considerations may vary significantly depending on specific use cases, implementation details, and evolving technology developments.