
The exponential growth of artificial intelligence and machine learning workloads has fundamentally transformed the requirements for high-performance networking infrastructure. As AI models continue to scale in complexity and size, with some modern large language models containing hundreds of billions or even trillions of parameters, the networking backbone that connects compute resources has become a critical bottleneck that can make or break the efficiency of training operations. The choice between 100 Gigabit Ethernet and 400 Gigabit Ethernet network technologies represents one of the most significant architectural decisions that organizations must make when designing AI training infrastructure.
Stay updated with the latest AI infrastructure trends to understand how networking technologies are evolving to meet the demands of next-generation artificial intelligence applications. The networking layer serves as the circulatory system of modern AI clusters, facilitating the massive data exchanges required for distributed training, model parallelism, and gradient synchronization that enable the creation of state-of-the-art AI systems.
Understanding High-Performance AI Networking Requirements
Modern machine learning training workloads impose unique and demanding requirements on network infrastructure that differ significantly from traditional enterprise networking needs. The distributed nature of contemporary AI training, where models are split across multiple GPUs and nodes, creates intensive communication patterns that require sustained high-bandwidth, low-latency connectivity between compute resources. These workloads typically involve frequent all-reduce operations where gradients must be synchronized across all participating nodes, creating network traffic patterns that can saturate even high-capacity links.
The challenge becomes particularly acute when training large transformer models or implementing techniques like pipeline parallelism, where different layers of a neural network are distributed across multiple devices. In these scenarios, the activation data must flow sequentially through the pipeline, making network latency a direct contributor to training time. Additionally, modern AI training often involves dynamic batching, checkpointing, and data loading operations that create bursty traffic patterns requiring networks to handle both sustained throughput and sudden spikes in bandwidth demand.
The memory constraints of individual GPUs have also driven the adoption of techniques like gradient accumulation and model sharding, which further increase the networking requirements as intermediate results must be communicated between nodes more frequently. These architectural considerations have made network performance a primary factor in determining the overall efficiency and cost-effectiveness of AI training infrastructure, elevating networking from a supporting role to a critical component that directly impacts the feasibility of training large-scale AI models.
100 Gigabit Ethernet: The Established Foundation
100 Gigabit Ethernet has emerged as the backbone technology for many existing AI training clusters, representing a mature and well-understood networking standard that offers a balanced combination of performance, cost, and ecosystem support. The technology provides substantial bandwidth improvements over previous generations while maintaining compatibility with existing network management tools and practices that many organizations have already adopted. The widespread adoption of 100GbE in enterprise and hyperscale data centers has created a robust ecosystem of switches, transceivers, and cables that enables competitive pricing and reliable supply chains.
The technical characteristics of 100GbE make it well-suited for medium-scale AI training workloads, particularly those involving models with tens to hundreds of billions of parameters distributed across clusters of dozens to hundreds of GPUs. The technology typically delivers consistent performance with well-understood latency characteristics, making it predictable for capacity planning and performance optimization. Network architects appreciate the mature tooling ecosystem surrounding 100GbE, including comprehensive monitoring solutions, traffic engineering capabilities, and troubleshooting methodologies that have been refined over years of deployment experience.
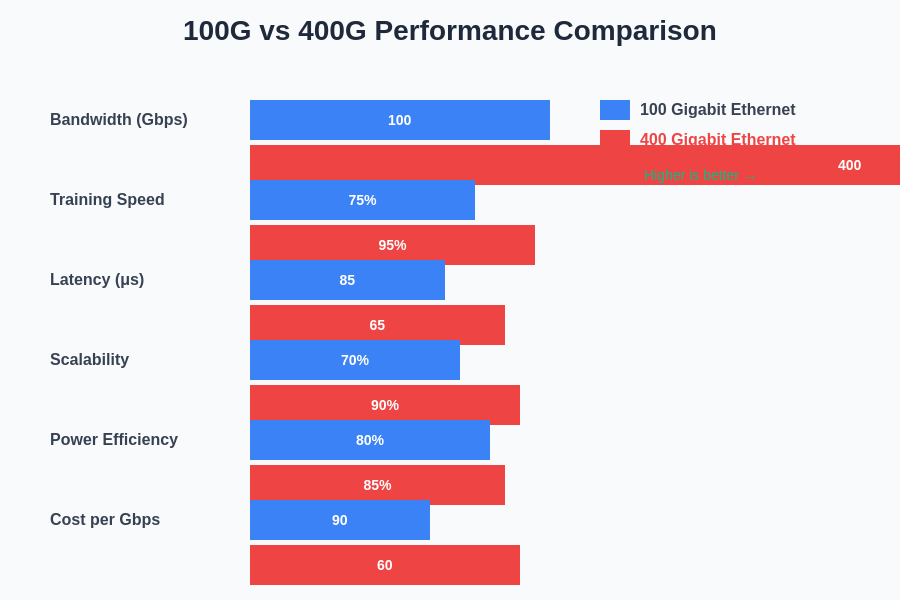
The performance characteristics between 100GbE and 400GbE extend beyond simple bandwidth differences, encompassing factors such as latency reduction, improved scalability, and enhanced power efficiency that directly impact AI training effectiveness.
From an economic perspective, 100GbE represents a sweet spot for many organizations, offering significant performance improvements over lower-speed alternatives while avoiding the premium pricing associated with cutting-edge technologies. The mature supply chain and competitive vendor landscape have driven down costs for both switching infrastructure and optical components, making 100GbE accessible to a broader range of organizations. This cost-effectiveness extends to operational expenses as well, with well-understood power consumption characteristics and maintenance requirements that facilitate accurate total cost of ownership calculations.
400 Gigabit Ethernet: The Next Generation Standard
400 Gigabit Ethernet represents the cutting edge of high-performance networking technology, designed to address the escalating bandwidth requirements of modern AI and high-performance computing workloads. This next-generation standard delivers four times the bandwidth of 100GbE while introducing architectural improvements that enhance both performance and efficiency in demanding AI training environments. The technology incorporates advanced signal processing techniques and improved error correction mechanisms that enable reliable transmission of data at unprecedented speeds.
Explore advanced AI infrastructure with Claude to understand how cutting-edge networking technologies integrate with modern AI development workflows and training methodologies. The architectural advantages of 400GbE extend beyond raw bandwidth, incorporating features specifically designed to handle the communication patterns typical in distributed AI training workloads.
The technical sophistication of 400GbE enables new approaches to network design that can significantly improve the efficiency of AI training clusters. The higher bandwidth per port reduces the number of network connections required to achieve target aggregate bandwidth, simplifying cabling infrastructure and reducing potential failure points. Advanced quality of service capabilities and traffic shaping features provide fine-grained control over network resource allocation, enabling optimization for specific AI workload characteristics such as the bursty traffic patterns associated with gradient synchronization operations.
The technology also incorporates enhanced telemetry and monitoring capabilities that provide deeper visibility into network performance characteristics, enabling more sophisticated optimization strategies for AI workloads. These monitoring capabilities are particularly valuable for identifying and resolving performance bottlenecks that can significantly impact training efficiency, such as network congestion during synchronized operations or suboptimal traffic distribution across available links.
Performance Analysis and Benchmarking
The performance characteristics of 100GbE and 400GbE networks in AI training environments reveal significant differences that extend beyond simple bandwidth comparisons. Comprehensive benchmarking studies have demonstrated that 400GbE can reduce training times for large language models by 20-40% compared to 100GbE implementations, with the benefits becoming more pronounced as model size and cluster scale increase. These improvements stem not only from increased bandwidth but also from reduced network latency and more efficient handling of the small message sizes typical in gradient communication patterns.
Detailed analysis of training workloads reveals that the benefits of 400GbE are particularly pronounced during gradient synchronization phases, where the higher bandwidth enables faster completion of all-reduce operations that are critical bottlenecks in distributed training. The reduced serialization delay associated with higher bandwidth links also contributes to lower overall training latency, particularly important for interactive AI development workflows where rapid iteration is essential for productivity.
Real-world performance measurements have shown that 400GbE networks can sustain higher utilization rates during peak training phases, maintaining consistent performance even under the intensive communication patterns associated with large-scale distributed training. This sustained performance capability translates to more predictable training times and improved resource utilization, factors that are crucial for organizations operating large-scale AI training infrastructure where any performance inefficiency is amplified across hundreds or thousands of GPUs.
The performance advantages extend to emerging AI training techniques such as mixture of experts models and sparse training algorithms, which create irregular communication patterns that benefit from the additional bandwidth headroom provided by 400GbE. These advanced training techniques are becoming increasingly important for achieving state-of-the-art results in AI applications, making the network performance characteristics of 400GbE increasingly relevant for organizations pursuing cutting-edge AI research and development.
Scalability and Architecture Considerations
The architectural implications of choosing between 100GbE and 400GbE extend far beyond individual link performance, influencing the overall design and scalability characteristics of AI training infrastructure. 400GbE enables more efficient network topologies that can support larger cluster sizes while maintaining non-blocking communication between all nodes. This scalability advantage becomes particularly important as AI models continue to grow in size and complexity, requiring distributed training across increasingly large numbers of GPUs and compute nodes.
Network topology design for AI clusters must carefully balance factors such as bandwidth, latency, and cost while providing the flexibility to accommodate future growth. 400GbE enables the construction of flatter network hierarchies with fewer switching tiers, reducing latency and simplifying network management while providing better performance consistency across all communication paths. This architectural simplification can significantly reduce operational complexity and improve system reliability, factors that become increasingly important as cluster sizes grow.
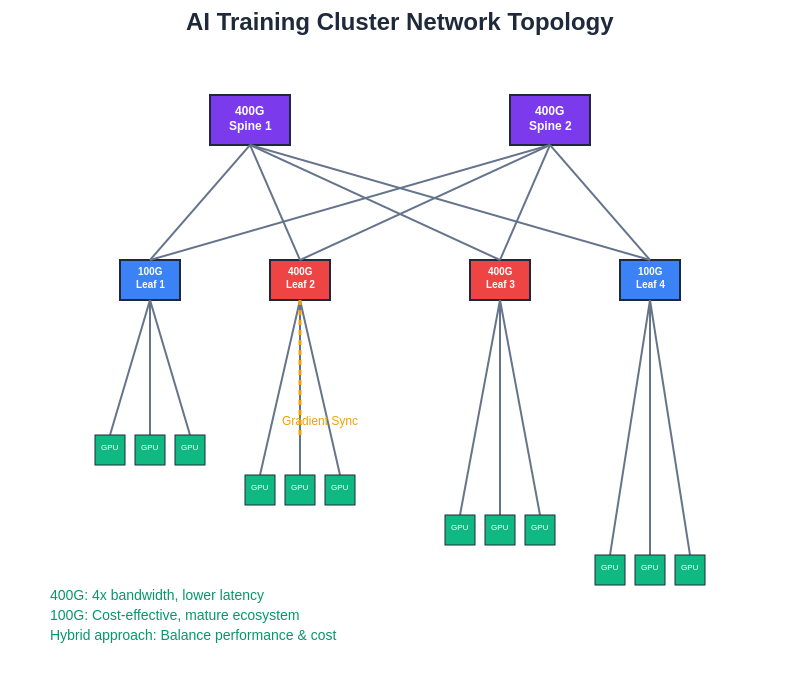
Modern AI training clusters utilize spine-leaf architectures that can accommodate both 100GbE and 400GbE technologies, with hybrid deployments often providing optimal cost-performance balance by strategically placing high-bandwidth links where they deliver maximum training acceleration benefits.
The higher port density achievable with 400GbE switching infrastructure also enables more efficient use of data center space and power resources, important considerations for organizations operating large-scale AI training facilities. Fewer switches and cables are required to achieve equivalent aggregate bandwidth, reducing both capital costs and ongoing operational overhead. This efficiency improvement becomes more significant as cluster sizes scale beyond thousands of nodes, where traditional 100GbE implementations may require complex multi-tier network architectures that introduce additional latency and management complexity.
Enhance your AI research capabilities with Perplexity to access comprehensive information about network architecture best practices and emerging trends in high-performance computing infrastructure. The architectural choices made during initial deployment significantly impact the long-term scalability and upgrade path for AI training infrastructure.
Cost Analysis and Economic Implications
The economic analysis of 100GbE versus 400GbE for AI training infrastructure requires careful consideration of both immediate capital expenses and long-term operational costs, with the optimal choice varying significantly based on deployment scale, workload characteristics, and organizational growth projections. Initial capital costs for 400GbE infrastructure typically represent a 50-100% premium over equivalent 100GbE implementations, driven primarily by the higher costs of switching equipment and optical transceivers that are still in the early stages of market adoption.
However, this initial cost premium must be evaluated against the potential productivity benefits and long-term infrastructure efficiency gains that 400GbE can provide. Organizations operating large-scale AI training clusters may find that the reduced training times enabled by 400GbE more than compensate for the higher networking costs through improved GPU utilization and faster time-to-results for AI development projects. The economic value of reduced training time becomes particularly significant for organizations where AI model development is directly tied to business outcomes or competitive advantage.
The total cost of ownership analysis must also consider factors such as power consumption, cooling requirements, and data center space utilization, where 400GbE often provides advantages through higher port density and more efficient switching architectures. These operational efficiency gains compound over time, potentially making 400GbE more cost-effective than 100GbE over multi-year deployment cycles despite higher initial capital requirements.
Future-proofing considerations also play a crucial role in the economic analysis, as the networking infrastructure represents a foundational investment that must support evolving AI workloads and scaling requirements over several years. The higher bandwidth capacity of 400GbE provides greater headroom for accommodating growth in model sizes and training dataset complexity, potentially delaying or eliminating the need for costly network infrastructure upgrades that would be required sooner with 100GbE implementations.
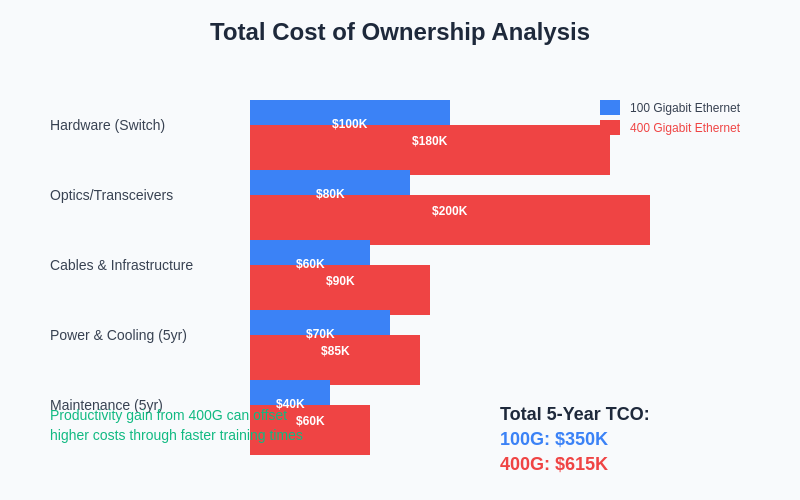
The total cost of ownership analysis reveals that while 400GbE requires higher initial capital investment, the productivity gains from reduced training times and improved resource utilization can provide compelling return on investment for organizations with substantial AI development activities.
Implementation Strategies and Best Practices
Successful deployment of high-performance networking for AI training requires careful attention to implementation details that can significantly impact overall system performance and reliability. Network design should incorporate redundancy and fault tolerance mechanisms that ensure training jobs can continue even in the event of individual link or switch failures, as training interruptions can result in significant loss of computational work and time. This requires careful consideration of network topology design, with multiple paths between nodes and intelligent traffic distribution mechanisms that can adapt to changing network conditions.
The physical infrastructure design must also account for the high-density cabling requirements associated with AI clusters, where hundreds or thousands of network connections must be managed within confined data center spaces. Proper cable management becomes critical for both performance and maintainability, with careful attention to signal integrity and electromagnetic interference that can impact network performance at high data rates. The choice of optical versus copper connections, cable routing strategies, and connector technologies all influence both performance and operational efficiency.
Configuration optimization for AI workloads requires understanding the specific communication patterns and requirements of distributed training algorithms. Network buffer sizing, quality of service configuration, and traffic prioritization must be tuned to accommodate the bursty traffic patterns and latency-sensitive operations characteristic of AI training workloads. Many organizations find value in implementing network monitoring and telemetry solutions that provide real-time visibility into network performance and utilization, enabling proactive identification and resolution of performance issues.
Testing and validation procedures should include comprehensive performance characterization under realistic AI training workloads, as synthetic network benchmarks may not accurately reflect the performance characteristics experienced during actual model training. This includes evaluation of network performance during different phases of training, from initial data loading through gradient synchronization and checkpointing operations, ensuring that the network can maintain consistent performance across all operational scenarios.
Integration with AI Training Frameworks
The integration between high-performance networking infrastructure and AI training frameworks represents a critical factor that can significantly impact the realized benefits of advanced networking technologies. Modern distributed training frameworks such as PyTorch Distributed Data Parallel, TensorFlow’s distribution strategies, and specialized communication libraries like NCCL have evolved to efficiently utilize high-bandwidth network connections, but proper configuration and optimization are essential to achieve maximum performance benefits.
The communication patterns generated by different AI training frameworks vary significantly in their network utilization characteristics, with some algorithms creating sustained high-bandwidth requirements while others generate bursty traffic with specific latency sensitivities. Understanding these patterns is crucial for selecting appropriate network technologies and configuration parameters that align with the specific requirements of the AI workloads being deployed. Framework-specific optimizations, such as gradient compression, communication overlap, and hierarchical reduction strategies, can significantly influence the effective utilization of available network bandwidth.
Advanced features such as Remote Direct Memory Access capabilities and GPU-direct networking can provide additional performance benefits by reducing CPU overhead and memory bandwidth requirements associated with network communication. These technologies are particularly beneficial for large-scale training workloads where network communication represents a significant portion of overall system activity, enabling more efficient utilization of both network and compute resources.
The evolution of AI training frameworks continues to drive new requirements for network infrastructure, with emerging techniques such as pipeline parallelism, model parallelism, and sparse training algorithms creating novel communication patterns that may favor different network architectures and technologies. Organizations planning network infrastructure investments must consider not only current framework requirements but also anticipated future developments that may change the networking requirements for AI training workloads.
Future Technology Trends and Evolution
The trajectory of high-performance networking technology for AI applications points toward continued evolution driven by the relentless scaling of AI model complexity and the emergence of new training paradigms that place ever-increasing demands on network infrastructure. Beyond 400GbE, the industry is already developing 800GbE and even higher-speed standards that will provide the bandwidth necessary to support future generations of AI models with trillions of parameters distributed across massive clusters of specialized AI processors.
Emerging technologies such as in-network computing, programmable switches, and AI-optimized network protocols promise to further enhance the efficiency of AI training networks by moving beyond simple data transport to provide intelligent processing and optimization capabilities directly within the network infrastructure. These advances may enable new approaches to distributed training that can achieve better performance and efficiency than current methods, potentially changing the fundamental trade-offs between network bandwidth, latency, and cost.
The integration of networking with specialized AI hardware continues to evolve, with new interconnect technologies and system architectures that provide tighter coupling between compute and network resources. These developments may blur the traditional boundaries between networking and computing infrastructure, enabling new system designs that can more efficiently support the communication patterns required by advanced AI training algorithms.
The convergence of networking technologies with cloud computing and edge computing paradigms also presents new opportunities and challenges for AI training infrastructure. Hybrid cloud training scenarios, where workloads span multiple data centers or combine on-premises and cloud resources, will require network technologies that can efficiently support distributed training across wide-area networks with varying performance characteristics and connectivity options.
Strategic Decision Framework
Organizations evaluating the choice between 100GbE and 400GbE for AI training infrastructure should develop a comprehensive decision framework that considers both current requirements and future growth projections, balancing technical performance benefits against cost considerations and implementation complexity. This framework should begin with a detailed analysis of current and anticipated AI workloads, including model sizes, training cluster scales, and performance requirements that will influence the networking infrastructure requirements.
The evaluation process should include detailed modeling of training performance under different network configurations, considering not only bandwidth requirements but also latency sensitivity and traffic pattern characteristics specific to the organization’s AI development practices. This analysis should extend beyond simple throughput calculations to include factors such as training convergence rates, development iteration cycles, and the economic value of reduced training times for the organization’s AI initiatives.
Risk assessment and future-proofing considerations play crucial roles in the decision process, as networking infrastructure represents a multi-year investment that must accommodate evolving requirements and technologies. Organizations should evaluate their tolerance for technical risk, considering factors such as technology maturity, vendor ecosystem stability, and the availability of skilled personnel to support advanced networking technologies.
The decision framework should also incorporate broader organizational factors such as budget constraints, deployment timelines, and integration requirements with existing infrastructure and operational processes. A phased deployment approach may be appropriate for some organizations, beginning with 100GbE for immediate needs while planning migration paths to 400GbE as requirements and budgets evolve.
The strategic importance of AI initiatives within the organization should influence the networking technology selection, with mission-critical AI development projects potentially justifying the premium costs associated with cutting-edge networking technologies, while research or experimental projects may be better served by more cost-effective solutions that can be upgraded as requirements become clearer.
Conclusion and Recommendations
The choice between 100GbE and 400GbE networking technologies for AI training infrastructure represents a complex decision that requires careful evaluation of technical requirements, economic considerations, and strategic objectives. While 400GbE offers compelling performance advantages and future-proofing benefits, 100GbE remains a viable and cost-effective option for many AI training scenarios, particularly those involving smaller to medium-scale deployments or organizations with budget constraints.
The rapid evolution of AI model architectures and training methodologies continues to drive increasing demands on network infrastructure, making the selection of appropriate networking technologies a critical factor in the success of AI initiatives. Organizations should adopt a strategic approach to network infrastructure planning that considers not only immediate requirements but also anticipated future growth and technological evolution that may impact networking needs over the infrastructure lifecycle.
The investment in high-performance networking infrastructure for AI training should be viewed as an enabler of innovation and competitive advantage rather than simply a cost center, with the potential productivity benefits and capabilities enabled by advanced networking technologies often justifying premium investments for organizations with significant AI development activities. As AI continues to transform industries and create new business opportunities, the networking infrastructure that enables effective AI development will become increasingly important for organizational success and competitiveness in the digital economy.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of networking technologies and their applications in AI training environments. Readers should conduct their own research and consider their specific requirements when selecting networking infrastructure for AI applications. Network performance and cost characteristics may vary based on specific implementations, vendor selections, and deployment scenarios.