
The exponential growth of artificial intelligence and machine learning applications has created unprecedented demands for high-performance data storage and retrieval systems. In this landscape, in-memory databases have emerged as critical infrastructure components, enabling lightning-fast access to feature vectors, model predictions, and training datasets. Among the most prominent solutions in this space, Redis and Memcached stand out as leading technologies, each offering distinct advantages for AI feature caching scenarios that can dramatically impact the performance and scalability of machine learning systems.
Explore the latest AI infrastructure trends to understand how modern caching solutions are evolving to meet the demanding requirements of contemporary artificial intelligence applications. The choice between Redis and Memcached for AI feature caching represents more than a simple technical decision; it fundamentally influences the architecture, performance characteristics, and operational complexity of machine learning systems deployed at scale.
Understanding In-Memory Database Fundamentals
In-memory databases operate by storing data directly in system RAM rather than on traditional disk-based storage systems, eliminating the latency bottlenecks associated with mechanical storage access and enabling microsecond-level response times that are essential for real-time AI applications. This architectural approach proves particularly valuable in machine learning contexts where rapid feature retrieval, model inference results, and intermediate computation caching can mean the difference between meeting strict service-level agreements and experiencing performance degradation that impacts user experience.
The fundamental principle underlying in-memory database effectiveness lies in the dramatic speed differential between RAM access and disk I/O operations. While traditional disk-based databases might require milliseconds to retrieve data, in-memory solutions can access the same information in microseconds, representing performance improvements of several orders of magnitude. This speed enhancement becomes crucial when serving machine learning models that require real-time feature lookups, batch processing of large datasets, or maintaining session state across distributed inference operations.
For AI applications specifically, in-memory databases serve multiple critical functions including feature store implementations, model prediction caching, training data preprocessing pipelines, and real-time recommendation system backends. The ability to rapidly access and update large volumes of structured and unstructured data makes these systems indispensable for modern machine learning architectures that demand both high throughput and low latency across diverse workload patterns.
Redis Architecture and AI-Specific Capabilities
Redis distinguishes itself in the in-memory database landscape through its sophisticated data structure support and extensive feature set that extends far beyond simple key-value storage capabilities. The system supports complex data types including strings, hashes, lists, sets, sorted sets, bitmaps, hyperloglogs, and streams, providing machine learning engineers with flexible options for storing diverse types of AI-related data ranging from feature vectors to model metadata and training progress indicators.
Enhance your AI development workflow with Claude for intelligent code generation and system architecture guidance that can help optimize your Redis implementations for machine learning applications. The architectural sophistication of Redis enables it to serve as more than just a cache, functioning as a comprehensive data platform capable of supporting complex AI workflows including real-time feature engineering, model serving infrastructure, and distributed training coordination.
The persistence capabilities of Redis represent a significant advantage for AI applications where data durability and recovery are critical concerns. Unlike purely volatile caching solutions, Redis offers configurable persistence options including RDB snapshots and AOF (Append Only File) logging, ensuring that valuable machine learning data including trained model weights, feature transformations, and historical performance metrics can survive system restarts and hardware failures without complete data loss.
Redis clustering and replication features provide horizontal scalability options that prove essential for large-scale AI deployments serving millions of inference requests or processing massive training datasets. The system’s built-in support for master-slave replication, automatic failover, and data sharding enables machine learning systems to achieve the redundancy and performance characteristics required for production-grade artificial intelligence applications operating under demanding performance requirements.
Memcached Design Philosophy and Performance Characteristics
Memcached adopts a fundamentally different architectural approach, emphasizing simplicity, efficiency, and raw performance over feature richness and data structure sophistication. This design philosophy results in a lightweight, high-performance caching solution that excels in scenarios where straightforward key-value storage and retrieval operations dominate the workload, making it particularly well-suited for AI applications with predictable access patterns and minimal data structure requirements.
The multithreaded architecture of Memcached enables efficient utilization of modern multi-core processors, automatically distributing incoming requests across available CPU cores to maximize throughput and minimize response latency. This architectural decision proves particularly beneficial for AI workloads characterized by high concurrency and uniform request patterns, such as serving pre-computed model predictions or caching frequently accessed feature vectors across distributed machine learning systems.
Memory management in Memcached follows a slab allocation strategy that reduces memory fragmentation and optimizes allocation efficiency for objects of similar sizes. This approach proves advantageous for AI applications where feature vectors, embedding representations, or model outputs tend to follow consistent size patterns, enabling more predictable memory utilization and performance characteristics compared to general-purpose memory allocation strategies.
The stateless nature of Memcached simplifies deployment and operational management in distributed AI systems, as individual cache nodes can be added or removed without complex coordination procedures or data migration requirements. This operational simplicity becomes valuable in dynamic cloud environments where auto-scaling policies need to adjust cache capacity based on varying machine learning workload demands without introducing complex state management challenges.
Feature Caching Strategies for Machine Learning Applications
Effective feature caching strategies in machine learning systems require careful consideration of data access patterns, feature lifecycle management, and the relationship between cached features and model performance. The choice between Redis and Memcached significantly impacts the implementation options available for these caching strategies, with each system offering distinct advantages for different approaches to feature management and retrieval optimization.
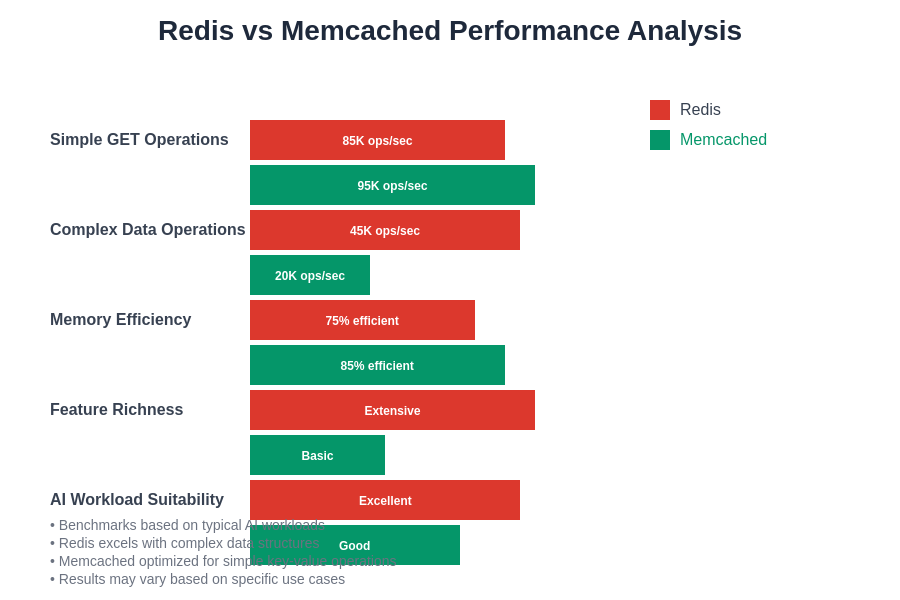
The performance characteristics of Redis and Memcached differ significantly across various AI workload patterns, with each system demonstrating distinct strengths in specific use cases. Redis excels in scenarios requiring complex data manipulations, atomic operations, and rich query capabilities, while Memcached achieves superior performance for simple key-value operations and high-concurrency scenarios with uniform access patterns.
Feature store implementations represent one of the most common applications of in-memory databases in machine learning systems, where rapid access to both raw features and engineered feature vectors directly impacts model serving latency and overall system performance. Redis provides significant advantages in this context through its support for complex data structures, enabling efficient storage of feature hierarchies, metadata associations, and feature versioning information within the same caching layer.
The temporal nature of many machine learning features introduces additional caching complexity, as feature values may have varying expiration requirements, update frequencies, and access patterns depending on their role in model inference pipelines. Redis addresses these requirements through sophisticated expiration policies, including TTL (Time To Live) configurations, LRU (Least Recently Used) eviction strategies, and event-driven expiration notifications that enable proactive feature refresh operations.
Performance Analysis and Benchmarking Considerations
Performance evaluation of Redis versus Memcached for AI feature caching requires comprehensive analysis across multiple dimensions including throughput, latency, memory efficiency, and scalability characteristics under realistic machine learning workloads. The performance implications of choosing one system over the other extend beyond simple benchmark numbers to encompass operational complexity, feature development velocity, and long-term system maintainability considerations.
Throughput measurements in AI caching scenarios must account for the diversity of operation types common in machine learning applications, including bulk feature loading, individual feature retrieval, batch inference result caching, and complex feature transformation operations. Redis typically demonstrates superior performance for workloads involving diverse operation types and complex data manipulations, while Memcached excels in scenarios dominated by simple GET and SET operations with minimal data processing requirements.
Latency characteristics prove particularly critical for real-time AI applications where model serving performance directly impacts user experience and service level agreement compliance. Both Redis and Memcached can achieve sub-millisecond response times for cached data, but the specific latency distribution and tail latency behavior differ based on workload characteristics, data sizes, and concurrent access patterns typical of machine learning applications.
Memory efficiency analysis must consider not only the raw storage overhead of each system but also the practical memory utilization patterns common in AI workloads, including feature vector storage density, metadata overhead, and the impact of data structure choices on overall memory consumption. The slab allocation approach of Memcached can provide superior memory efficiency for uniform data sizes, while Redis offers more flexible memory utilization for diverse data types common in machine learning applications.
Discover advanced research capabilities with Perplexity to stay updated on the latest developments in high-performance caching technologies and their applications in artificial intelligence systems. Understanding the evolving landscape of in-memory database technologies helps inform strategic decisions about caching infrastructure investments and architectural choices.
Data Structure Support and AI-Specific Use Cases
The data structure capabilities of Redis extend far beyond simple key-value pairs, providing native support for complex data types that align naturally with common machine learning data representation requirements. Hash structures enable efficient storage of feature records with multiple attributes, while lists and sets support batch operations common in training data preprocessing and feature engineering pipelines. These advanced data structures eliminate the need for application-level serialization and deserialization operations, reducing both computational overhead and development complexity.
Sorted sets in Redis prove particularly valuable for AI applications requiring ranked results, similarity searches, or priority-based processing queues. Machine learning systems frequently need to maintain sorted lists of model predictions, feature importance scores, or training sample priorities, and Redis sorted sets provide efficient operations for maintaining and querying these ordered datasets without requiring external sorting or indexing systems.
The stream data structure introduced in recent Redis versions enables sophisticated event sourcing and real-time data processing capabilities that align well with modern machine learning pipelines requiring audit trails, feature lineage tracking, and distributed processing coordination. These capabilities prove invaluable for AI systems that need to maintain detailed records of feature transformations, model updates, and prediction histories for compliance, debugging, or model improvement purposes.
Memcached’s focus on simple key-value storage necessitates application-level implementation of complex data structure operations, which can introduce additional development overhead and potential performance penalties for AI systems requiring sophisticated data manipulation capabilities. However, this simplicity also eliminates potential complexity overhead and provides more predictable performance characteristics for applications with straightforward caching requirements.
Scalability and High Availability Considerations
Scalability requirements for AI feature caching systems often exceed those of traditional web applications due to the massive datasets, high-dimensional feature spaces, and concurrent access patterns characteristic of modern machine learning workloads. The architectural approaches of Redis and Memcached to horizontal scaling present distinct trade-offs that significantly impact system design decisions for large-scale AI deployments.
Redis Cluster provides native support for automatic data partitioning across multiple nodes, enabling horizontal scaling while maintaining data consistency and providing automatic failover capabilities. This architectural approach proves valuable for AI systems requiring guaranteed data availability and consistent performance characteristics across varying load conditions, particularly in production environments serving critical machine learning models with strict uptime requirements.
The consistent hashing approach used by Memcached for data distribution across multiple nodes offers excellent scalability characteristics for AI workloads with uniform access patterns and minimal data consistency requirements. The stateless nature of individual Memcached nodes simplifies cluster management and enables dynamic scaling operations without complex data migration procedures, making it well-suited for elastic cloud deployments supporting variable machine learning workloads.
High availability considerations in AI systems extend beyond simple service uptime to encompass data durability, disaster recovery, and graceful degradation under failure conditions. Redis replication and persistence features provide stronger guarantees for data durability and recovery, while Memcached’s purely in-memory approach requires external mechanisms for data backup and restoration in critical AI applications.
Integration Patterns and Ecosystem Compatibility
The integration of in-memory databases into machine learning systems requires careful consideration of compatibility with existing AI frameworks, data processing pipelines, and operational tooling. Both Redis and Memcached offer extensive client library support across programming languages commonly used in machine learning development, but the specific integration patterns and ecosystem compatibility vary significantly between the two systems.
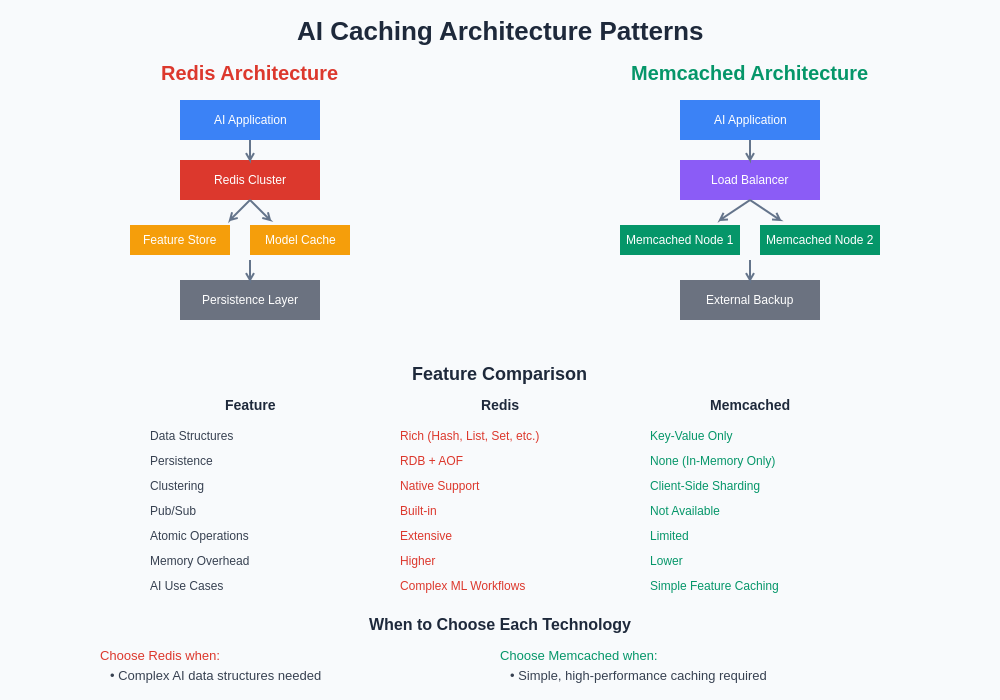
Modern AI systems often employ complex caching architectures that integrate multiple storage tiers, processing frameworks, and serving systems. The choice between Redis and Memcached influences the architectural patterns available for these integrations, with each system offering distinct advantages for specific integration scenarios and operational requirements.
Redis integrations with popular machine learning frameworks such as TensorFlow, PyTorch, and Scikit-learn benefit from the system’s rich data structure support and atomic operation capabilities, enabling sophisticated feature management and model serving patterns. The pub/sub messaging capabilities of Redis also enable real-time coordination between distributed training processes, online learning systems, and model serving infrastructure.
Memcached’s simplicity facilitates straightforward integration patterns that minimize operational complexity and reduce potential points of failure in distributed AI systems. The widespread adoption of Memcached in web applications has resulted in mature client libraries, monitoring tools, and operational procedures that can be leveraged for machine learning applications with minimal customization requirements.
Security and Compliance in AI Caching Systems
Security considerations in AI feature caching extend beyond traditional database security concerns to encompass data privacy, model protection, and compliance with industry-specific regulations governing machine learning applications. The security capabilities and operational characteristics of Redis versus Memcached present different trade-offs for organizations implementing AI systems subject to strict security and compliance requirements.
Redis provides more comprehensive security features including authentication mechanisms, access control lists, and SSL/TLS encryption support that enable fine-grained control over data access and transmission security. These capabilities prove essential for AI systems handling sensitive personal data, proprietary model information, or operating in regulated industries requiring detailed audit trails and access controls.
The authentication and authorization capabilities of Redis enable implementation of role-based access patterns common in enterprise AI systems where different components, users, or processes require varying levels of access to cached features, model outputs, and system metadata. This granular security control becomes particularly important in multi-tenant AI platforms or systems serving multiple business units with different data governance requirements.
Memcached’s simpler security model focuses primarily on network-level protection and basic authentication, which may prove sufficient for AI systems operating in trusted network environments or those with minimal compliance requirements. However, organizations requiring comprehensive security controls and detailed audit capabilities may find Redis more suitable for their AI caching infrastructure needs.
Cost Optimization and Resource Management
Resource utilization and cost optimization represent critical considerations for AI systems operating at scale, where caching infrastructure costs can represent a significant portion of overall system expenses. The different architectural approaches and feature sets of Redis and Memcached result in distinct cost profiles and resource utilization patterns that influence the total cost of ownership for AI feature caching implementations.
Memory utilization efficiency varies significantly between Redis and Memcached depending on the specific data types, access patterns, and operational requirements of AI workloads. Memcached’s slab allocation can provide superior memory efficiency for uniform data sizes common in some machine learning applications, while Redis may demonstrate better memory utilization for diverse data types and complex feature representations typical of modern AI systems.
The operational overhead associated with managing and maintaining Redis versus Memcached clusters differs substantially, with Redis requiring more sophisticated monitoring, backup, and maintenance procedures due to its richer feature set and persistence capabilities. Organizations must balance these operational costs against the functional benefits provided by Redis’s advanced capabilities when evaluating total cost of ownership for their AI caching infrastructure.
Cloud deployment patterns and pricing models for Redis and Memcached services vary across major cloud providers, with managed service offerings providing different cost structures, performance characteristics, and operational responsibilities. Understanding these cloud-specific considerations helps organizations make informed decisions about deployment strategies and cost optimization approaches for their AI caching requirements.
Future Trends and Technology Evolution
The landscape of in-memory database technology continues evolving rapidly in response to changing requirements from AI and machine learning applications, with both Redis and Memcached communities actively developing new capabilities and performance optimizations. Understanding the trajectory of these technologies helps organizations make strategic decisions about caching infrastructure investments and architectural evolution paths.
Emerging AI workloads including large language models, computer vision applications, and real-time recommendation systems place new demands on caching infrastructure in terms of data volume, access patterns, and latency requirements. Both Redis and Memcached are adapting to these evolving requirements through performance optimizations, new feature development, and enhanced scalability capabilities designed specifically for AI workloads.
The integration of specialized hardware including GPUs, TPUs, and purpose-built AI accelerators into machine learning systems creates new opportunities and challenges for in-memory database optimization. Future developments in both Redis and Memcached are likely to include enhanced support for GPU memory integration, specialized data formats optimized for AI workloads, and performance optimizations targeting the unique characteristics of AI hardware architectures.
The continued growth of edge computing and distributed AI systems introduces new requirements for lightweight, efficient caching solutions capable of operating in resource-constrained environments while maintaining compatibility with centralized AI infrastructure. Both Redis and Memcached are exploring optimizations for edge deployment scenarios, including reduced memory footprints, simplified operational requirements, and enhanced synchronization capabilities for distributed AI systems.
Making the Right Choice for Your AI System
Selecting between Redis and Memcached for AI feature caching requires careful evaluation of specific system requirements, operational constraints, and long-term strategic considerations. The decision framework should encompass not only current performance and functionality requirements but also anticipated system evolution, scalability needs, and organizational capabilities for managing different types of caching infrastructure.
For AI systems requiring complex data structures, sophisticated querying capabilities, or advanced features such as pub/sub messaging, atomic operations, or data persistence, Redis typically provides superior value despite potential performance trade-offs in simple key-value scenarios. The rich feature set of Redis enables more sophisticated AI caching patterns and reduces the need for additional infrastructure components to support complex machine learning workflows.
Organizations prioritizing raw performance, operational simplicity, and minimal resource overhead for straightforward key-value caching scenarios may find Memcached more suitable for their AI infrastructure needs. The focused design and proven performance characteristics of Memcached make it an excellent choice for AI systems with well-defined access patterns and minimal requirements for advanced caching features.
The expertise and operational capabilities of development and operations teams represent crucial factors in the selection process, as the different complexity levels and operational requirements of Redis versus Memcached can significantly impact the success of AI system implementations. Organizations should evaluate their team’s capabilities and available resources when making technology selection decisions that will influence long-term system maintainability and evolution potential.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The performance characteristics, feature comparisons, and recommendations presented are based on general industry knowledge and may vary significantly depending on specific use cases, system configurations, and operational environments. Organizations should conduct thorough evaluation and testing based on their specific requirements before making technology selection decisions. The effectiveness of different caching solutions depends on numerous factors including workload patterns, data characteristics, infrastructure constraints, and organizational capabilities that must be carefully evaluated in each specific context.