The artificial intelligence revolution has fundamentally transformed how we approach computational challenges, with specialized hardware architectures becoming the cornerstone of efficient machine learning operations. Among the most prominent contenders in the cloud AI training hardware space, Intel Gaudi and Google TPU represent two distinct philosophical approaches to accelerating deep learning workloads, each offering unique advantages and specialized optimizations that cater to different aspects of the modern AI development pipeline.
Explore the latest AI hardware trends to understand how cutting-edge processors are shaping the future of machine learning and artificial intelligence applications. The competition between these specialized processing units reflects a broader industry shift toward purpose-built silicon solutions that can handle the enormous computational demands of contemporary AI models while maintaining cost-effectiveness and energy efficiency.
Understanding Intel Gaudi Architecture
Intel Gaudi processors represent a comprehensive approach to AI acceleration that combines high-performance computing capabilities with flexible programming models designed to accommodate diverse machine learning workloads. The Gaudi architecture emphasizes scalability and interoperability, providing developers with a familiar development environment while delivering substantial performance improvements over traditional CPU-based training approaches.
The Gaudi processors feature a heterogeneous design that incorporates multiple processing engines optimized for different aspects of neural network computation. This includes specialized tensor processing units for matrix operations, dedicated engines for data movement and transformation, and integrated networking capabilities that enable efficient multi-node scaling. The architecture’s emphasis on programmability allows researchers and engineers to implement custom optimizations and experimental algorithms without being constrained by rigid hardware limitations.
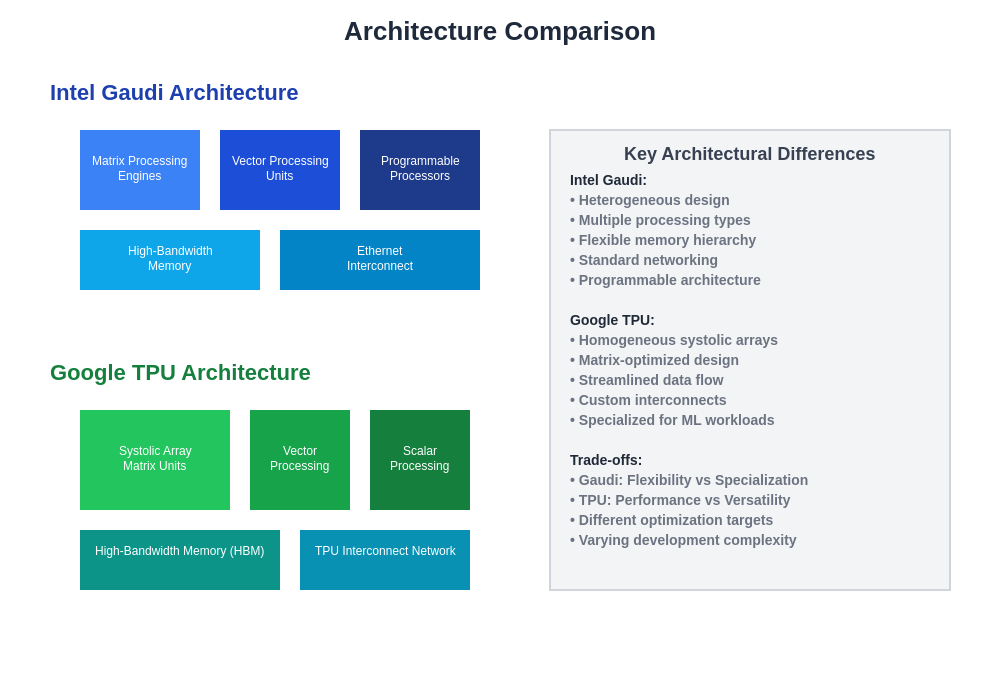
The architectural differences between Intel Gaudi and Google TPU reflect fundamentally different approaches to AI acceleration, with Gaudi emphasizing flexibility and programmability while TPU focuses on specialized optimization for matrix operations and neural network workloads.
Intel’s approach with Gaudi reflects a broader strategy of democratizing AI acceleration by providing tools and frameworks that integrate seamlessly with existing software stacks. The processors support popular machine learning frameworks including TensorFlow, PyTorch, and others through optimized libraries and runtime environments that abstract hardware complexity while exposing performance-critical features to developers who require fine-grained control over execution.
Exploring Google TPU Innovation
Google’s Tensor Processing Unit represents a revolutionary approach to AI acceleration that emerged from the company’s internal need to efficiently handle massive-scale machine learning workloads across its global infrastructure. The TPU architecture embodies Google’s deep understanding of neural network computation patterns, resulting in a highly specialized design that excels at the specific mathematical operations that dominate modern deep learning algorithms.
The TPU’s design philosophy centers on maximizing throughput for matrix multiplication operations, which form the computational core of neural network training and inference. This specialization enables TPUs to achieve remarkable performance density and energy efficiency for supported workloads, though it comes with trade-offs in terms of flexibility and general-purpose computing capabilities compared to more versatile architectures.
Enhance your AI development with Claude’s advanced capabilities for comprehensive analysis and optimization of machine learning workflows across different hardware platforms. Google’s TPU ecosystem includes multiple generations of processors, each optimized for specific use cases ranging from inference acceleration in mobile applications to large-scale training of transformer models that power modern natural language processing systems.
Performance Characteristics and Benchmarking
The performance comparison between Intel Gaudi and Google TPU requires careful consideration of multiple factors including workload characteristics, model architectures, batch sizes, and optimization strategies. Intel Gaudi processors demonstrate particular strength in scenarios that benefit from flexible programming models and require integration with existing software infrastructures, while TPUs excel in workloads that align closely with their specialized computational strengths.
Benchmark results across different model types reveal nuanced performance characteristics that depend heavily on specific implementation details and optimization approaches. Large language models, computer vision networks, and recommendation systems each present unique computational patterns that interact differently with the architectural strengths of each platform. Understanding these performance profiles is crucial for making informed decisions about hardware selection for specific AI projects.
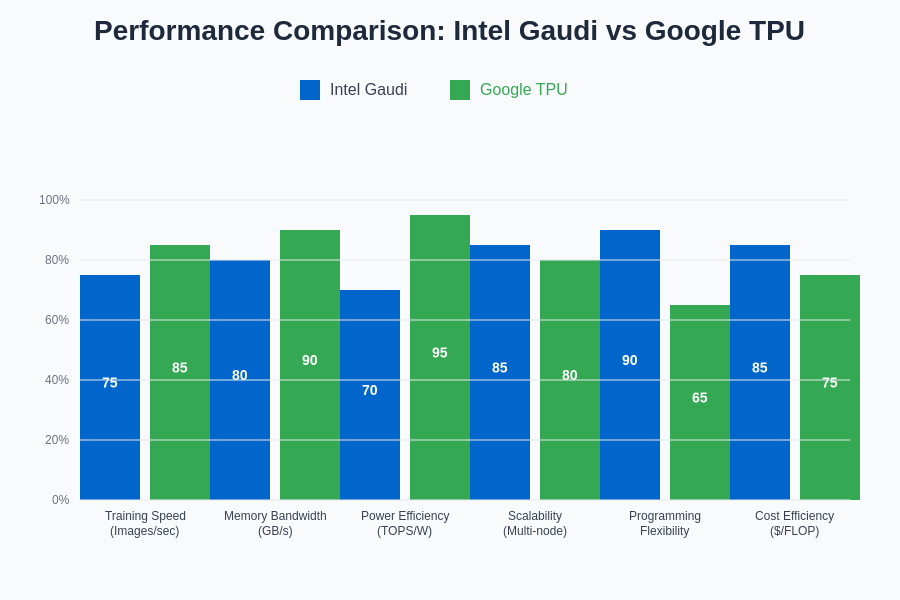
The performance metrics demonstrate that while both platforms excel in different areas, the choice between Intel Gaudi and Google TPU often depends on specific workload characteristics, with Gaudi showing advantages in programming flexibility and multi-node scalability, while TPU demonstrates superior power efficiency and raw computational throughput for matrix-heavy operations.
The scalability characteristics of both platforms represent another critical performance dimension, with each architecture offering different approaches to multi-node training and distributed computing. Intel Gaudi’s emphasis on standard networking protocols and flexible interconnect options contrasts with Google’s tightly integrated TPU pod architectures that provide highly optimized communication patterns for supported scaling scenarios.
Development Ecosystem and Software Support
The software ecosystem surrounding each hardware platform significantly influences the practical adoption and long-term viability of AI training solutions. Intel Gaudi benefits from extensive integration with established machine learning frameworks and development tools, providing developers with familiar programming environments and debugging capabilities that accelerate development cycles and reduce the learning curve associated with adopting new hardware platforms.
Google TPU’s software stack reflects the company’s deep integration with its cloud services and machine learning platforms, offering seamless access to advanced features like automatic mixed precision training, dynamic batching, and optimized data pipeline management. The TPU ecosystem includes specialized tools for performance profiling, model optimization, and distributed training orchestration that leverage Google’s extensive experience in operating large-scale machine learning systems.
The choice between platforms often depends on existing software investments and team expertise, as migration costs and training requirements can significantly impact the total cost of ownership for AI training infrastructure. Organizations with established workflows around specific frameworks or cloud platforms may find one ecosystem more naturally aligned with their operational requirements and strategic objectives.
Cost Analysis and Economic Considerations
The economic aspects of AI training hardware selection extend beyond simple acquisition costs to encompass total cost of ownership factors including power consumption, cooling requirements, software licensing, operational overhead, and opportunity costs associated with development time and resource utilization efficiency. Intel Gaudi’s positioning in the market reflects a strategy of providing competitive price-performance ratios while maintaining compatibility with existing infrastructure investments.
Google TPU pricing models are closely integrated with Google Cloud Platform services, offering various consumption-based options that can provide cost advantages for organizations that can effectively utilize the platform’s specialized capabilities. The economic benefits of TPU utilization often manifest most clearly in scenarios involving large-scale training workloads that can fully leverage the architecture’s throughput advantages and integrated cloud services.
Discover comprehensive AI research capabilities with Perplexity to analyze market trends and cost optimization strategies for AI hardware deployment across different cloud platforms. The rapidly evolving landscape of AI hardware pricing requires ongoing evaluation as both vendors continue to introduce new generations of processors with improved price-performance characteristics and expanded feature sets.
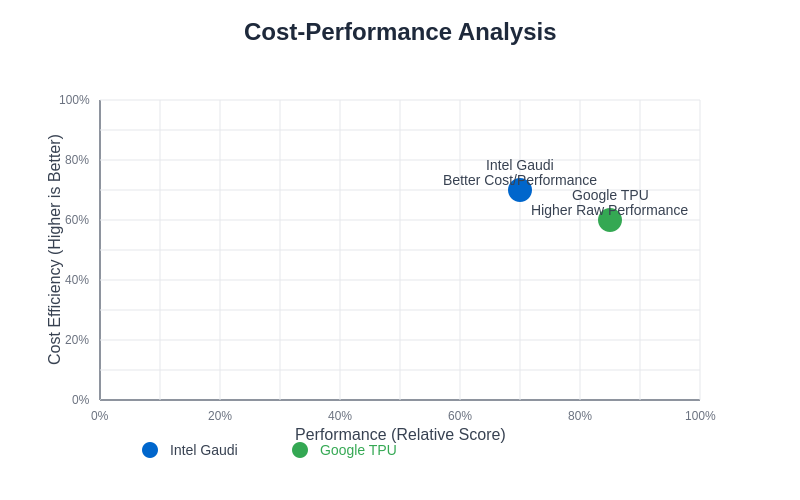
The cost-performance analysis reveals that Intel Gaudi typically offers better cost efficiency for organizations requiring flexible deployment options and custom optimization capabilities, while Google TPU provides higher absolute performance for workloads that can fully utilize its specialized architecture and cloud-native integration features.
Architectural Deep Dive and Technical Specifications
The fundamental architectural differences between Intel Gaudi and Google TPU reflect distinct approaches to solving the computational challenges inherent in modern AI workloads. Intel Gaudi’s heterogeneous design incorporates multiple specialized processing units that can operate independently or in coordination, providing flexibility for handling diverse computational patterns while maintaining high utilization rates across different phases of training and inference operations.
The Gaudi architecture includes dedicated matrix multiplication engines, vector processing units, and programmable processors that can be dynamically allocated based on workload requirements. This flexibility enables efficient handling of models with irregular computation patterns or custom operations that may not map efficiently to more specialized architectures. The integrated high-bandwidth memory system and advanced interconnect capabilities support both intra-processor and inter-processor communication patterns required for large-scale distributed training scenarios.
Google TPU’s architecture represents a more focused approach that maximizes efficiency for the specific mathematical operations that dominate neural network computation. The systolic array design enables massive parallelism for matrix operations while minimizing data movement overhead, resulting in exceptional performance density for supported workloads. The TPU’s memory hierarchy and data flow patterns are specifically optimized for the access patterns typical of neural network training, reducing latency and improving overall system efficiency.
Scalability and Multi-Node Training
The scalability characteristics of AI training hardware become increasingly critical as model sizes continue to grow and training datasets expand to encompass billions or trillions of parameters. Intel Gaudi’s approach to scaling emphasizes standards-based interconnect technologies and flexible topology options that enable organizations to construct training clusters tailored to their specific requirements and existing infrastructure constraints.
Gaudi processors incorporate high-speed Ethernet connectivity and support for various network topologies, allowing for cost-effective scaling using commodity networking equipment. This approach provides flexibility in cluster design and can leverage existing data center infrastructure while maintaining competitive performance for distributed training scenarios. The software stack includes optimized communication libraries and runtime systems that efficiently handle the coordination and synchronization requirements of large-scale parallel training.
Google TPU pods represent a more integrated approach to scaling that combines specialized hardware with tightly optimized software to deliver exceptional performance for supported workloads. The pod architecture provides high-bandwidth, low-latency interconnects between TPU cores, enabling efficient scaling to hundreds or thousands of processing units for the largest training jobs. This integrated approach can deliver superior performance for workloads that align well with the TPU’s computational model but may be less flexible for scenarios that require custom topologies or integration with non-Google infrastructure.
Memory Architecture and Data Management
Memory subsystem design represents a critical factor in AI training performance, as modern neural networks require efficient handling of massive datasets and intermediate computational results that can exceed the capacity of traditional memory hierarchies. Intel Gaudi processors incorporate high-bandwidth memory subsystems with sophisticated caching mechanisms designed to minimize data movement overhead while providing sufficient capacity for large-scale training workloads.
The Gaudi memory architecture includes multiple levels of cache hierarchy optimized for different access patterns common in neural network computation. The design emphasizes flexibility in memory allocation and management, allowing software to optimize data placement and movement patterns based on specific model characteristics and training strategies. This programmable approach to memory management enables optimization opportunities that may not be available in more rigid architectures.
Google TPU’s memory system reflects the architecture’s specialization for neural network computation, with memory bandwidth and capacity carefully balanced to match the computational throughput of the processing units. The design minimizes unnecessary data movement through careful optimization of data flow patterns and strategic placement of memory resources relative to computational elements. This tight integration between memory and compute resources enables high utilization rates and energy efficiency for supported workloads.
Programming Models and Developer Experience
The programming experience and development workflow associated with each platform significantly influences adoption patterns and long-term success in the competitive AI hardware market. Intel Gaudi’s software stack emphasizes compatibility with existing development practices and provides extensive debugging and profiling tools that enable developers to optimize performance while maintaining familiar workflows and development methodologies.
The Gaudi programming model supports multiple abstraction levels, from high-level framework integration that requires minimal code changes to low-level optimization interfaces that enable expert developers to extract maximum performance for specific use cases. This flexibility allows organizations to adopt the platform incrementally while building expertise and optimizing critical workloads over time. The comprehensive documentation and community support resources facilitate knowledge transfer and accelerate the development of optimized applications.
Google TPU’s programming environment is tightly integrated with Google’s cloud ecosystem and machine learning platforms, providing streamlined workflows for common training scenarios while abstracting many low-level optimization details. The platform excels in scenarios where developers can leverage pre-built optimization strategies and established best practices, though it may require more significant adaptation for workloads that deviate from common patterns or require extensive customization.
Energy Efficiency and Environmental Impact
The environmental considerations associated with large-scale AI training have become increasingly important as organizations seek to balance computational requirements with sustainability goals and operational cost constraints. Both Intel Gaudi and Google TPU architectures incorporate various energy efficiency optimizations, though they achieve efficiency through different design strategies and operational approaches.
Intel Gaudi’s energy efficiency stems from its flexible architecture that can dynamically adjust power consumption based on workload characteristics and utilization patterns. The heterogeneous design enables selective activation of processing units based on computational requirements, reducing power consumption during phases of training that don’t require full system utilization. Advanced power management features and process technology optimizations contribute to competitive energy efficiency across diverse workload scenarios.
Google TPU’s energy efficiency benefits from the architecture’s specialization for neural network computation, which enables high computational throughput per watt for supported workloads. The systolic array design and optimized data flow patterns minimize unnecessary data movement and computation overhead, resulting in efficient utilization of available power budget. Google’s integration of TPUs into its global infrastructure also enables optimization opportunities at the data center level that may not be available to individual organizations deploying standalone hardware solutions.
Market Position and Industry Adoption
The competitive landscape for AI training hardware continues to evolve rapidly as new entrants join the market and existing players introduce successive generations of improved processors. Intel Gaudi’s market position reflects the company’s broader strategy of leveraging its extensive experience in high-performance computing and established relationships with enterprise customers to capture market share in the growing AI acceleration segment.
The adoption patterns for Intel Gaudi demonstrate particular strength in organizations that value integration with existing infrastructure and development workflows, as well as scenarios that require flexible deployment options or custom optimization strategies. The platform’s compatibility with standard software stacks and development tools reduces adoption barriers and enables gradual migration from CPU-based training approaches.
Google TPU’s market presence is closely tied to the broader adoption of Google Cloud Platform services and the company’s leadership in machine learning research and development. Organizations that are already invested in Google’s cloud ecosystem often find TPU adoption to be a natural extension of their existing infrastructure, while the platform’s association with cutting-edge research attracts organizations seeking access to the latest AI acceleration technologies.
Future Roadmap and Technology Evolution
The future development trajectories of both Intel Gaudi and Google TPU reflect broader industry trends toward increased specialization, improved energy efficiency, and enhanced programmability for AI acceleration hardware. Intel’s roadmap includes successive generations of Gaudi processors with improved performance characteristics, expanded feature sets, and enhanced integration with emerging AI workload patterns and software frameworks.
The evolution of Intel’s AI acceleration strategy encompasses not only hardware improvements but also comprehensive software ecosystem development, including optimized libraries, development tools, and integration with popular machine learning platforms. This holistic approach aims to reduce the total cost of ownership for AI training infrastructure while providing the flexibility and performance required for next-generation AI applications.
Google’s TPU development roadmap continues to push the boundaries of specialized AI acceleration while expanding the range of supported workloads and improving integration with cloud services. Future TPU generations are expected to incorporate advances in process technology, architectural innovations, and software optimization that maintain the platform’s leadership in performance density and energy efficiency for neural network computation.
The continued evolution of both platforms reflects the dynamic nature of the AI hardware market and the ongoing innovation required to meet the computational demands of increasingly sophisticated machine learning models and applications. Organizations planning long-term AI infrastructure investments must consider not only current capabilities but also the trajectory of future development and the alignment of vendor roadmaps with evolving requirements.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The information presented is based on publicly available data and industry analysis as of the publication date. Performance characteristics, pricing, and feature availability may vary based on specific configurations, workloads, and deployment scenarios. Readers should conduct thorough evaluation and testing based on their specific requirements before making hardware selection decisions. The rapidly evolving nature of AI hardware technology means that specifications and capabilities may change significantly over time.