
The machine learning operations landscape has evolved dramatically with the rise of containerized deployments and cloud-native architectures, positioning Kubernetes as the foundational platform for scalable ML workloads. Within this ecosystem, two prominent frameworks have emerged as leading solutions for orchestrating machine learning pipelines: Kubeflow and MLflow. These platforms represent different philosophies and approaches to ML pipeline management, each offering unique advantages for organizations seeking to operationalize their machine learning workflows at scale.
Explore the latest AI and ML developments to understand how containerized ML platforms are reshaping the industry landscape. The choice between Kubeflow and MLflow often determines the trajectory of an organization’s MLOps maturity, influencing everything from development velocity to operational complexity and long-term scalability considerations.
Understanding Kubeflow’s Kubernetes-First Architecture
Kubeflow represents a comprehensive machine learning platform built specifically for Kubernetes environments, designed from the ground up to leverage the orchestration, scaling, and resource management capabilities inherent in Kubernetes clusters. This Kubernetes-native approach provides organizations with a unified platform that seamlessly integrates with existing cloud infrastructure while offering sophisticated workflow orchestration capabilities that can handle complex multi-stage ML pipelines with ease.
The platform’s architecture encompasses multiple interconnected components including Kubeflow Pipelines for workflow orchestration, Katib for hyperparameter tuning, KFServing for model deployment, and Jupyter notebook integration for interactive development. This holistic approach creates a complete ML ecosystem where data scientists and ML engineers can collaborate effectively while maintaining consistent deployment patterns and resource utilization strategies across different stages of the machine learning lifecycle.
Kubeflow’s deep integration with Kubernetes enables advanced features such as automatic resource scaling, fault tolerance, and distributed training capabilities that are essential for enterprise-grade machine learning operations. The platform leverages Kubernetes’ native scheduling and resource management features to optimize compute utilization and ensure reliable execution of ML workloads across diverse infrastructure configurations.
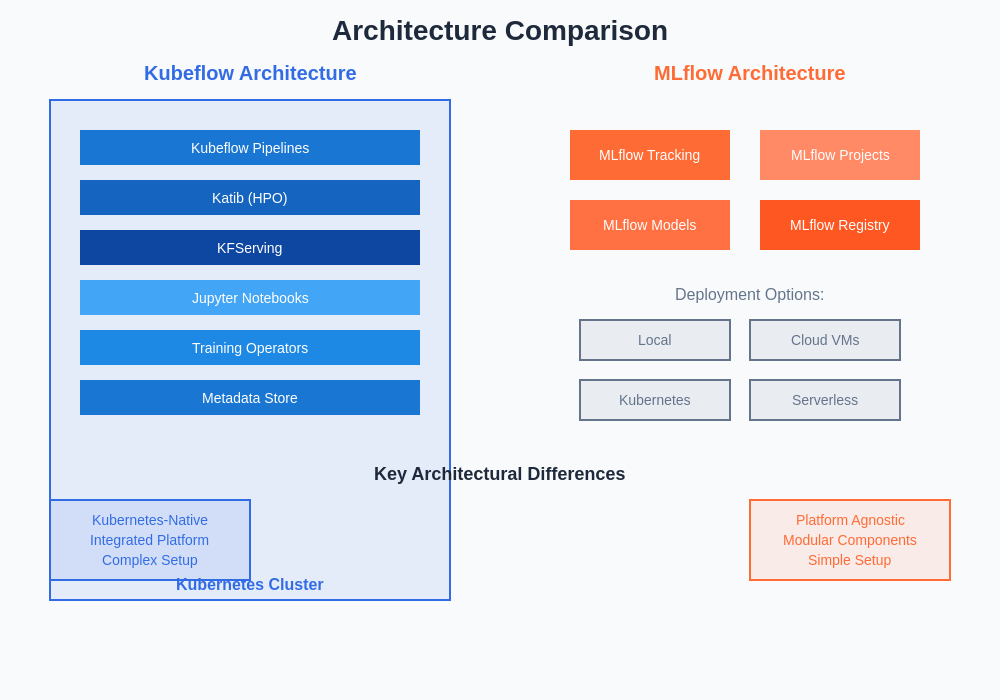
The architectural differences between Kubeflow and MLflow reflect their fundamentally different approaches to ML operations, with Kubeflow providing a comprehensive Kubernetes-native platform while MLflow offers modular components that can be deployed across various infrastructure configurations.
MLflow’s Simplified Approach to ML Lifecycle Management
MLflow takes a fundamentally different approach to machine learning operations by focusing on simplicity, flexibility, and broad compatibility across different deployment environments. Rather than requiring a specific infrastructure foundation, MLflow provides a lightweight, modular framework that can be deployed on various platforms including local development environments, traditional servers, cloud instances, and yes, Kubernetes clusters when needed.
The MLflow ecosystem consists of four primary components: MLflow Tracking for experiment management, MLflow Projects for reproducible runs, MLflow Models for model packaging and deployment, and MLflow Registry for model versioning and lifecycle management. This modular design allows organizations to adopt MLflow incrementally, implementing only the components that align with their immediate needs while maintaining the flexibility to expand their usage over time.
Discover advanced AI capabilities with Claude for comprehensive analysis and comparison of complex ML platform architectures. MLflow’s philosophy emphasizes reducing barriers to entry for machine learning teams while providing enterprise-grade capabilities for tracking, reproducibility, and model management across diverse technological stacks and organizational structures.
Pipeline Orchestration and Workflow Management
The fundamental difference between Kubeflow and MLflow becomes most apparent when examining their approaches to pipeline orchestration and workflow management. Kubeflow Pipelines provides a sophisticated domain-specific language for defining complex ML workflows using Python decorators and containerized components, enabling the creation of directed acyclic graphs that represent intricate data processing and model training sequences.
Kubeflow’s pipeline system offers advanced features such as conditional execution, parallel processing, resource allocation specifications, and integration with Kubernetes operators for specialized workloads. This capability makes it particularly well-suited for organizations with complex ML workflows that require sophisticated orchestration, resource management, and integration with multiple data sources and computing resources.
MLflow approaches workflow management through its Projects component, which focuses on reproducible execution of ML code rather than complex orchestration. MLflow Projects can be combined with external workflow orchestrators like Apache Airflow, Prefect, or even Kubeflow Pipelines to create sophisticated pipeline architectures while maintaining the simplicity and flexibility that characterizes the MLflow ecosystem.
Container Orchestration and Kubernetes Integration
Kubeflow’s Kubernetes-native design provides seamless integration with container orchestration platforms, offering automatic scaling, resource management, and fault tolerance that are essential for production ML workloads. The platform leverages Kubernetes operators and custom resource definitions to manage ML-specific workloads such as distributed training jobs, hyperparameter tuning experiments, and model serving deployments.
The deep Kubernetes integration enables Kubeflow to provide advanced features such as GPU scheduling, node affinity rules, persistent volume management, and network policies that are crucial for managing complex ML workloads in production environments. This integration also facilitates sophisticated monitoring, logging, and observability capabilities through integration with Kubernetes-native monitoring solutions.
MLflow’s relationship with Kubernetes is more flexible and optional, allowing organizations to deploy MLflow components on Kubernetes when desired while maintaining compatibility with other deployment options. MLflow can run effectively on Kubernetes using standard deployment patterns, but it doesn’t require the deep architectural integration that characterizes Kubeflow’s approach.
Experiment Tracking and Model Management
MLflow excels in experiment tracking and model management through its comprehensive tracking server and model registry components. The MLflow Tracking system provides detailed logging of parameters, metrics, artifacts, and model versions with a user-friendly interface that makes it easy for data scientists to compare experiments and identify optimal model configurations.
The MLflow Model Registry offers sophisticated model lifecycle management capabilities including model versioning, stage transitions, approval workflows, and integration with CI/CD systems for automated model deployment. This comprehensive approach to model management has made MLflow a popular choice for organizations prioritizing experiment reproducibility and model governance.
Enhance your research capabilities with Perplexity for comprehensive analysis of ML platform features and capabilities. Kubeflow provides experiment tracking through integration with external systems or custom implementations, but its primary strength lies in workflow orchestration rather than comprehensive experiment management, requiring organizations to implement additional tooling for complete experiment tracking capabilities.
Scalability and Enterprise Deployment Considerations
Kubeflow’s Kubernetes-native architecture provides inherent advantages for organizations requiring massive scale and complex resource management scenarios. The platform can leverage Kubernetes’ horizontal scaling capabilities to handle training workloads that span hundreds or thousands of compute nodes, making it particularly attractive for organizations with large-scale deep learning initiatives or complex distributed computing requirements.
The enterprise deployment story for Kubeflow includes sophisticated multi-tenancy features, role-based access control, resource quotas, and integration with enterprise authentication systems. These capabilities make Kubeflow suitable for large organizations with complex organizational structures and stringent security requirements, though they also contribute to increased operational complexity.
MLflow’s scalability approach focuses on simplicity and compatibility rather than native orchestration capabilities. While MLflow components can be scaled horizontally and deployed across multiple environments, achieving massive scale typically requires integration with external orchestration platforms and careful architecture design to ensure optimal performance and resource utilization.
Development Experience and Learning Curve
The development experience differs significantly between these platforms, with MLflow prioritizing simplicity and ease of adoption while Kubeflow emphasizes comprehensive functionality and Kubernetes-native workflows. MLflow’s learning curve is generally considered more accessible for data scientists and ML engineers who want to quickly implement experiment tracking and model management without extensive infrastructure knowledge.
Kubeflow requires deeper understanding of Kubernetes concepts, containerization strategies, and distributed systems principles to fully leverage its capabilities. This learning curve can be substantial for teams without strong DevOps or infrastructure experience, but it provides access to sophisticated workflow orchestration and resource management capabilities that are difficult to achieve with simpler platforms.
The development workflow in MLflow emphasizes iterative experimentation and rapid prototyping, with straightforward APIs for logging experiments and managing models. Kubeflow’s development experience centers around defining containerized pipeline components and orchestrating complex workflows, which can be more complex but offers greater flexibility for sophisticated ML operations.
Integration Ecosystem and Third-Party Tools
MLflow’s open architecture and broad compatibility have fostered a rich ecosystem of integrations with popular ML libraries, cloud platforms, and development tools. The platform integrates seamlessly with scikit-learn, TensorFlow, PyTorch, XGBoost, and numerous other ML frameworks while providing plugins for major cloud providers and deployment platforms.
Kubeflow’s integration ecosystem focuses primarily on Kubernetes-native tools and cloud-native technologies. The platform provides excellent integration with Kubernetes operators, Istio for service mesh capabilities, monitoring solutions like Prometheus and Grafana, and cloud-specific services from major providers including Google Cloud, AWS, and Azure.
Both platforms support integration with popular data processing frameworks such as Apache Spark, Apache Beam, and various data storage solutions, though the integration patterns and architectural approaches differ based on each platform’s underlying philosophy and technical architecture.

The comprehensive feature comparison reveals the distinct strengths of each platform, with Kubeflow excelling in pipeline orchestration and Kubernetes integration while MLflow leads in experiment tracking and deployment flexibility. Understanding these capability differences is crucial for making informed platform selection decisions.
Cost Considerations and Resource Optimization
The cost implications of choosing between Kubeflow and MLflow extend beyond licensing considerations to include infrastructure requirements, operational complexity, and resource utilization efficiency. Kubeflow’s Kubernetes requirement introduces additional infrastructure complexity that may increase operational costs, particularly for smaller organizations or teams without existing Kubernetes expertise.
However, Kubeflow’s sophisticated resource management and scheduling capabilities can lead to more efficient utilization of compute resources, particularly in environments with diverse workloads and varying resource requirements. The platform’s ability to automatically scale resources and optimize GPU utilization can result in significant cost savings for organizations with substantial ML compute requirements.
MLflow’s lightweight architecture and flexible deployment options can reduce infrastructure costs and operational overhead, particularly for organizations with simpler ML workflows or those operating in resource-constrained environments. The platform’s compatibility with various deployment options allows organizations to optimize costs based on their specific requirements and constraints.
Security and Compliance Features
Enterprise security and compliance requirements play a crucial role in platform selection decisions, with both Kubeflow and MLflow offering different approaches to addressing these concerns. Kubeflow leverages Kubernetes’ built-in security features including role-based access control, network policies, pod security policies, and integration with enterprise authentication systems to provide comprehensive security controls.
The platform’s integration with Kubernetes security ecosystems enables advanced features such as workload isolation, encrypted communication, secure secrets management, and audit logging that are essential for organizations operating in regulated industries or handling sensitive data. Kubeflow’s multi-tenancy capabilities also support complex organizational structures with sophisticated access control requirements.
MLflow’s security model focuses on securing the tracking server and model registry components while providing flexibility for organizations to implement additional security layers based on their specific deployment architecture. The platform supports authentication, authorization, and encryption for data in transit and at rest, though achieving comprehensive security often requires additional infrastructure and configuration.
Performance and Monitoring Capabilities
Performance monitoring and observability represent critical aspects of production ML operations, with both platforms offering different approaches to monitoring and performance optimization. Kubeflow’s integration with Kubernetes monitoring ecosystems provides comprehensive observability through tools like Prometheus, Grafana, and Jaeger, enabling detailed monitoring of resource utilization, pipeline performance, and system health.
The platform’s native integration with Kubernetes enables sophisticated monitoring of distributed training jobs, resource allocation efficiency, and system performance metrics that are essential for optimizing ML workloads at scale. Kubeflow also provides integration with specialized ML monitoring tools for tracking model performance, data drift, and prediction quality.
MLflow’s monitoring capabilities focus primarily on experiment tracking and model performance metrics, with integration points for external monitoring solutions when comprehensive infrastructure monitoring is required. The platform provides detailed logging of experiment parameters, metrics, and artifacts while supporting custom metric logging for specialized monitoring requirements.
Future Roadmap and Community Development
The evolution trajectory of both platforms reflects their different architectural philosophies and target use cases, with Kubeflow continuing to enhance its Kubernetes-native capabilities and MLflow expanding its cross-platform compatibility and enterprise features. Kubeflow’s development roadmap emphasizes deeper integration with cloud-native technologies, enhanced multi-tenancy features, and improved developer experience for complex ML workflows.
MLflow’s roadmap focuses on expanding model management capabilities, improving integration with popular ML frameworks, and enhancing enterprise features while maintaining its core philosophy of simplicity and broad compatibility. The platform continues to evolve its model registry, deployment capabilities, and integration ecosystem to address enterprise requirements without compromising accessibility.
Both platforms benefit from active open-source communities and commercial backing, with Kubeflow supported by Google and other cloud providers, and MLflow backed by Databricks. This support ensures continued development and enterprise-grade reliability for both platforms while driving innovation in the MLOps space.
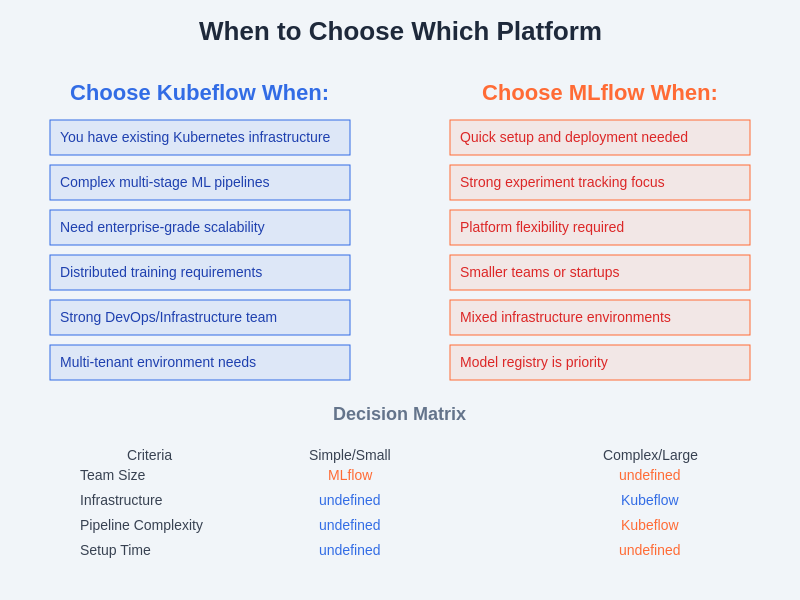
The choice between Kubeflow and MLflow ultimately depends on organizational requirements, technical constraints, and strategic objectives rather than absolute superiority of one platform over another. Organizations with sophisticated Kubernetes infrastructure and complex ML workflows often find Kubeflow’s comprehensive approach advantageous, while those prioritizing simplicity, flexibility, and broad compatibility may prefer MLflow’s modular architecture. Understanding these fundamental differences enables organizations to make informed decisions that align with their technical capabilities, operational requirements, and long-term MLOps strategy.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The comparison between Kubeflow and MLflow is based on publicly available information and general industry knowledge. Organizations should conduct their own evaluation and testing to determine the most suitable platform for their specific requirements. Platform capabilities and features may change over time, and readers should refer to official documentation for the most current information.