The proliferation of artificial intelligence applications on mobile devices has created a fundamental architectural decision point that shapes the entire user experience and technical infrastructure of modern applications. The choice between on-device processing and cloud inference represents more than a simple technical trade-off; it encompasses considerations of privacy, performance, cost, scalability, and user experience that collectively determine the viability and success of mobile AI implementations.
Stay updated with the latest AI developments as mobile edge computing continues to evolve rapidly, introducing new capabilities and optimization techniques that reshape how we approach intelligent mobile applications. The landscape of mobile AI processing has reached a pivotal moment where technological advances in mobile hardware, optimization frameworks, and cloud infrastructure have made both approaches increasingly viable for different use cases and application requirements.
The Evolution of Mobile AI Processing
The journey toward sophisticated mobile AI processing has been marked by significant technological breakthroughs that have transformed what was once considered computationally impossible on mobile devices into routine capabilities. Early mobile AI implementations relied heavily on cloud processing due to the limited computational resources available on mobile hardware, but the rapid advancement of mobile processors, specialized neural processing units, and efficient model architectures has fundamentally altered this paradigm.
Modern smartphones and mobile devices now incorporate dedicated AI acceleration hardware, including neural processing units, graphics processing units optimized for machine learning workloads, and specialized tensor processing cores that can execute complex neural network operations with remarkable efficiency. These hardware advances have been complemented by sophisticated software frameworks and model optimization techniques that enable the deployment of increasingly complex AI models directly on mobile devices without sacrificing performance or battery life.
The cloud infrastructure supporting mobile AI has simultaneously evolved to provide ultra-low latency processing capabilities, edge computing nodes positioned closer to end users, and scalable inference services that can handle massive concurrent request volumes. This parallel evolution has created a rich ecosystem of options for mobile AI deployment, each with distinct advantages and limitations that must be carefully evaluated based on specific application requirements and user needs.
Understanding On-Device Processing Architecture
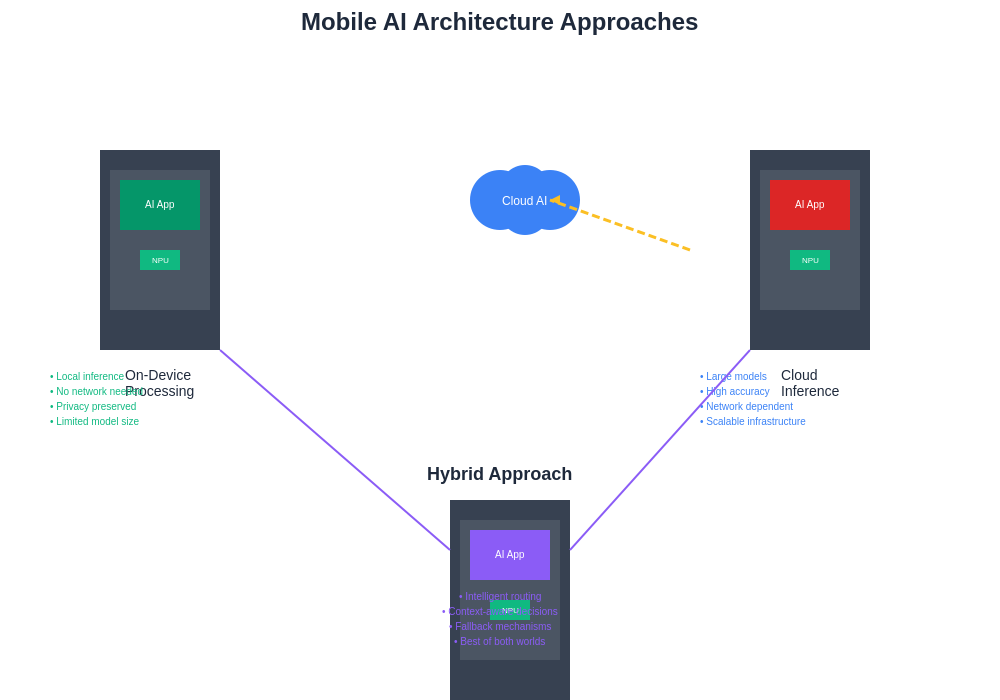
On-device AI processing represents a paradigm where machine learning models execute entirely within the confines of the mobile device, utilizing local computational resources to perform inference operations without requiring network connectivity or external dependencies. This approach leverages the increasingly sophisticated hardware capabilities of modern mobile devices, including specialized neural processing units, optimized mobile GPUs, and efficient CPU architectures designed to handle machine learning workloads effectively.
The technical implementation of on-device processing involves several critical components that work together to enable efficient local inference. Mobile-optimized neural network frameworks such as TensorFlow Lite, PyTorch Mobile, and platform-specific solutions like Core ML and ML Kit provide the runtime infrastructure necessary to execute trained models on mobile hardware. These frameworks incorporate advanced optimization techniques including quantization, pruning, and knowledge distillation that reduce model size and computational requirements while maintaining acceptable accuracy levels.
Explore cutting-edge AI tools like Claude to understand how advanced AI systems can be optimized for different deployment scenarios, including mobile edge computing environments that require careful balance between performance and resource constraints. The optimization strategies employed in on-device processing often involve sophisticated trade-offs between model accuracy, inference speed, memory usage, and energy consumption that require deep understanding of both the underlying hardware capabilities and the specific requirements of the target application.
Cloud Inference Architecture and Implementation
Cloud-based AI inference represents an alternative approach where mobile applications transmit input data to remote servers equipped with powerful computational resources, receive processed results, and present them to users through the mobile interface. This architecture leverages the virtually unlimited computational capacity of cloud infrastructure to execute large, complex models that would be impractical or impossible to run efficiently on mobile hardware.
The technical foundation of cloud inference relies on robust server infrastructure optimized for machine learning workloads, including specialized hardware such as graphics processing units, tensor processing units, and field-programmable gate arrays that can execute neural network operations at massive scale. Cloud providers have developed sophisticated inference services that automatically handle model loading, request routing, auto-scaling, and result delivery through high-performance APIs that can process millions of requests efficiently.
The implementation of cloud inference involves careful consideration of network architecture, data transmission protocols, caching strategies, and edge computing deployment to minimize latency and ensure reliable service delivery. Modern cloud inference systems often incorporate content delivery networks, regional processing nodes, and intelligent request routing to position computational resources as close as possible to end users while maintaining the flexibility and scalability advantages of centralized processing.
Performance Characteristics and Optimization
The performance characteristics of on-device processing and cloud inference differ significantly across multiple dimensions that directly impact user experience and application viability. On-device processing typically provides consistent, predictable inference times that are independent of network conditions, server load, or external dependencies. This consistency enables real-time applications such as augmented reality, camera filters, and interactive experiences that require immediate response to user input without perceptible delay.
Cloud inference performance is fundamentally dependent on network connectivity, geographic proximity to processing centers, and server capacity allocation. While cloud infrastructure can execute much larger and more sophisticated models than mobile hardware, the total response time includes network transmission delays, server processing time, and result delivery that can introduce significant variability in user experience. However, cloud processing can achieve higher absolute accuracy and handle more complex reasoning tasks that exceed the capabilities of mobile hardware.
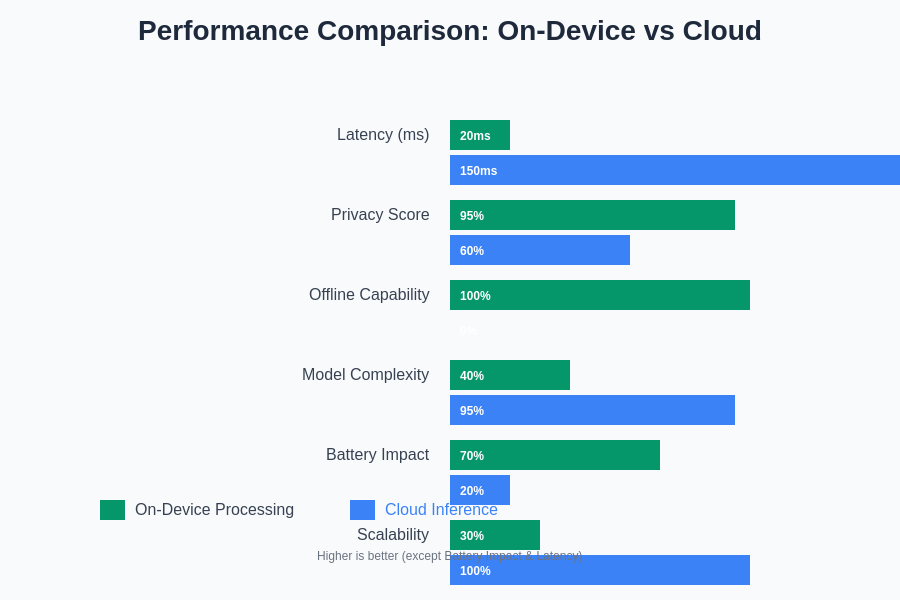
The optimization strategies for each approach require fundamentally different techniques and considerations. On-device optimization focuses on model compression, quantization, and hardware-specific acceleration techniques that maximize efficiency within strict resource constraints. Cloud optimization emphasizes scalability, load distribution, and infrastructure efficiency that can handle varying demand patterns while maintaining consistent service quality across large user populations.
Privacy and Security Considerations
Privacy represents one of the most significant differentiating factors between on-device processing and cloud inference, with implications that extend far beyond technical implementation to encompass user trust, regulatory compliance, and ethical considerations. On-device processing provides inherent privacy advantages by ensuring that sensitive data never leaves the user’s device, eliminating concerns about data transmission, storage, and potential breaches in cloud infrastructure.
The privacy benefits of on-device processing are particularly relevant for applications handling sensitive information such as personal photos, voice recordings, health data, financial information, and location data. By processing this information locally, applications can provide intelligent features without exposing private data to external systems or creating permanent records in cloud databases that might be subject to access requests, security breaches, or unauthorized use.
Cloud inference inherently involves transmitting user data to external systems, creating privacy considerations that must be carefully addressed through encryption, anonymization, data retention policies, and compliance with privacy regulations such as GDPR, CCPA, and industry-specific requirements. While cloud providers have developed sophisticated security measures and privacy protection techniques, the fundamental architecture requires trust in external data handling practices and creates potential attack vectors that do not exist in on-device processing.
Discover advanced AI research capabilities with Perplexity to explore the latest developments in privacy-preserving machine learning techniques that are shaping the future of both on-device and cloud-based AI processing. The ongoing development of techniques such as federated learning, differential privacy, and homomorphic encryption is creating new hybrid approaches that combine the benefits of both processing paradigms while addressing their respective limitations.
Cost Analysis and Economic Implications
The economic considerations surrounding on-device processing versus cloud inference involve complex calculations that encompass development costs, operational expenses, scalability requirements, and long-term maintenance considerations. On-device processing typically involves higher upfront development costs due to the complexity of model optimization, platform-specific implementation, and testing across diverse hardware configurations, but results in lower ongoing operational costs since processing occurs on user devices rather than paid cloud infrastructure.
Cloud inference generally requires lower initial development investment since models can be deployed without extensive optimization and can leverage existing cloud infrastructure, but creates ongoing operational costs that scale with usage, including compute resources, data transfer, storage, and infrastructure management. The cost structure of cloud inference can become significant for applications with large user bases or computationally intensive processing requirements.
The economic implications extend beyond direct costs to include considerations of user acquisition, retention, and monetization strategies. Applications utilizing on-device processing can operate without ongoing cloud costs, potentially enabling different pricing models and reducing barriers to scaling user adoption. Cloud-based applications must carefully balance processing costs against revenue generation while ensuring that infrastructure expenses do not exceed the economic value generated by user engagement.
Real-World Application Scenarios
Different types of mobile AI applications demonstrate clear preferences for either on-device processing or cloud inference based on their specific requirements and constraints. Camera applications with real-time filters, object recognition, and augmented reality features typically favor on-device processing to provide immediate visual feedback without network dependencies. These applications benefit from the consistent performance and privacy advantages of local processing while providing engaging user experiences that require minimal latency.
Voice assistants and natural language processing applications often utilize hybrid approaches that combine on-device processing for wake word detection and basic commands with cloud inference for complex natural language understanding and knowledge retrieval. This architecture provides immediate responsiveness for simple interactions while leveraging cloud capabilities for sophisticated reasoning tasks that exceed mobile hardware limitations.
Enterprise applications handling sensitive business data frequently mandate on-device processing to ensure compliance with security policies and regulatory requirements. Medical imaging applications, financial analysis tools, and industrial inspection systems often require local processing to prevent sensitive data from leaving controlled environments while providing intelligent analysis capabilities.
Hybrid Processing Strategies
The evolution of mobile AI architecture has increasingly embraced hybrid approaches that combine the strengths of both on-device processing and cloud inference to create more sophisticated and capable applications. These hybrid strategies involve intelligent decision-making systems that dynamically select the appropriate processing method based on factors such as network availability, model complexity, privacy sensitivity, and performance requirements.
Intelligent fallback mechanisms represent one common hybrid approach where applications attempt on-device processing first but seamlessly transition to cloud inference when local resources are insufficient or when higher accuracy is required. This strategy provides the benefits of local processing when possible while ensuring that applications remain functional and capable even when dealing with complex tasks that exceed device capabilities.
Progressive enhancement strategies involve implementing basic functionality through on-device processing while offering advanced features through cloud inference. This approach ensures that core application functionality remains available regardless of network conditions while providing enhanced capabilities when cloud resources are accessible. The implementation requires careful user experience design to ensure that the transition between different processing modes feels natural and intuitive.
Battery Life and Resource Management
Energy consumption represents a critical consideration for mobile AI applications that directly impacts user experience and device usability. On-device processing involves intensive computational operations that can significantly impact battery life, particularly for applications that perform continuous or frequent inference operations. The energy efficiency of on-device processing depends heavily on hardware optimization, model efficiency, and intelligent resource management strategies that balance performance with power consumption.
Cloud inference shifts computational load away from mobile devices, potentially extending battery life by reducing local processing requirements. However, network communication required for cloud inference also consumes energy, and the total energy impact depends on factors such as data transmission volume, network efficiency, and frequency of inference requests. Applications must carefully consider the energy trade-offs between local computation and network communication to optimize overall power consumption.
Advanced power management strategies involve dynamic adjustment of processing approaches based on device battery level, charging status, and usage patterns. Applications can implement intelligent scheduling that delays non-critical cloud inference operations during low battery conditions or utilizes more efficient on-device processing when power conservation is prioritized over maximum accuracy or capability.
Network Dependency and Offline Functionality
The relationship between mobile AI applications and network connectivity represents a fundamental architectural consideration that impacts user experience, application reliability, and market accessibility. On-device processing provides complete independence from network connectivity, ensuring that AI-powered features remain functional regardless of internet availability, network quality, or data plan limitations.
This network independence is particularly valuable for applications used in environments with unreliable connectivity, international travel scenarios where data costs are prohibitive, or situations where users prefer to limit data usage. Applications that rely entirely on cloud inference become unusable when network connectivity is unavailable, creating significant limitations in user experience and application utility.
The implementation of effective offline functionality requires sophisticated model deployment strategies, local data caching, and graceful degradation approaches that maintain core functionality even when advanced cloud-based features are unavailable. Applications must carefully design user interfaces and feature sets to clearly communicate availability of different capabilities based on connectivity status while ensuring that offline modes provide meaningful value to users.
Scalability and Infrastructure Requirements
Scalability considerations differ dramatically between on-device processing and cloud inference, with each approach presenting unique challenges and opportunities for applications targeting large user populations. On-device processing scales naturally with user adoption since computational resources grow proportionally with the number of devices, but requires significant upfront investment in model optimization, testing, and platform-specific development to ensure consistent performance across diverse hardware configurations.
Cloud inference requires careful infrastructure planning and resource allocation to handle varying demand patterns, geographic distribution, and peak usage scenarios. While cloud infrastructure provides theoretically unlimited scalability, the practical implementation requires sophisticated load balancing, auto-scaling, and resource management strategies that can respond dynamically to changing demand while maintaining consistent service quality and cost efficiency.
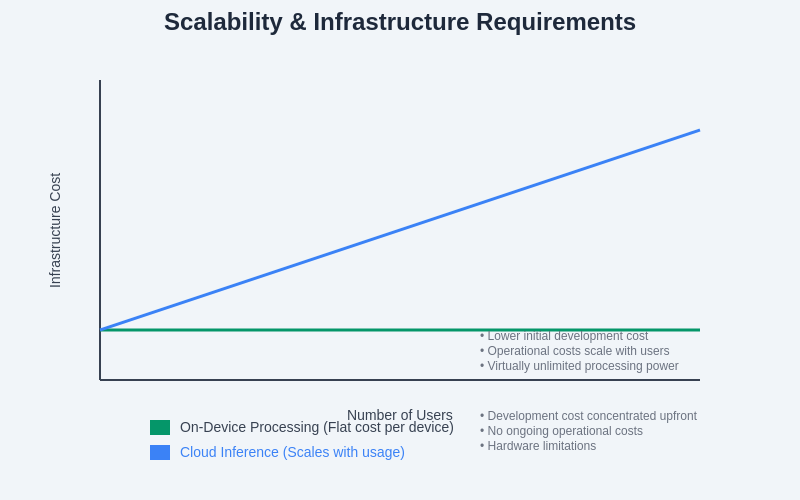
The infrastructure requirements for supporting large-scale mobile AI deployment involve considerations of content delivery networks, regional processing centers, model versioning and deployment systems, monitoring and analytics platforms, and disaster recovery capabilities. Organizations must carefully evaluate their technical capabilities, operational expertise, and financial resources when selecting appropriate scalability strategies for their specific application requirements and growth projections.
Future Technological Developments
The future of mobile AI processing is shaped by rapid advances in multiple technological domains that promise to blur the distinctions between on-device processing and cloud inference while creating new hybrid approaches that leverage the strengths of both paradigms. Advances in mobile hardware design, including more efficient neural processing units, improved battery technology, and specialized AI acceleration chips, continue to expand the capabilities of on-device processing while reducing energy consumption and heat generation.
Edge computing infrastructure development is creating new intermediate options that position processing capabilities closer to end users without requiring full on-device implementation. These edge computing nodes can provide lower latency than traditional cloud processing while maintaining the scalability and management advantages of centralized infrastructure, creating new architectural possibilities for mobile AI applications.
The development of federated learning systems represents a particularly promising direction that enables collaborative model training across distributed devices while preserving privacy and reducing the need for centralized data collection. These systems allow mobile applications to benefit from collective learning experiences while maintaining the privacy and autonomy advantages of on-device processing.
Emerging compression and optimization techniques continue to make larger and more sophisticated models viable for mobile deployment, while advances in cloud infrastructure efficiency and edge computing are reducing the latency and cost disadvantages of remote processing. The convergence of these technological trends suggests a future where mobile AI applications will have unprecedented flexibility in selecting and combining processing approaches to optimize for specific use cases and requirements.
The integration of 5G networks and improved wireless communication protocols is reducing the performance gap between on-device processing and cloud inference by enabling ultra-low latency communication and higher bandwidth data transmission. These network advances make cloud inference more viable for real-time applications while opening new possibilities for sophisticated hybrid processing approaches that can dynamically optimize between local and remote processing based on real-time conditions and requirements.
Disclaimer
This article is provided for informational purposes only and does not constitute technical or business advice. The rapidly evolving nature of mobile AI technology means that specific technical details, performance characteristics, and best practices may change as new developments emerge. Readers should conduct thorough research and testing appropriate to their specific use cases and requirements when making architectural decisions for mobile AI applications. The effectiveness of different processing approaches may vary significantly based on specific application requirements, target hardware, user populations, and business objectives.