
The development and testing of artificial intelligence systems fundamentally depends on access to high-quality, representative datasets that accurately reflect real-world scenarios and edge cases. However, obtaining sufficient real-world data for comprehensive testing often presents significant challenges, including privacy concerns, data scarcity, regulatory compliance requirements, and the inherent difficulty of capturing rare but critical scenarios that AI models must handle reliably. Synthetic dataset generation has emerged as a transformative solution that enables developers and researchers to create comprehensive, controlled, and ethically compliant datasets that serve as the foundation for robust AI system development and validation.
Explore the latest AI development trends and techniques to understand how synthetic data generation is revolutionizing machine learning workflows and enabling more comprehensive testing methodologies. The ability to generate synthetic datasets on demand has become a cornerstone of modern AI development, enabling teams to test edge cases, validate model performance across diverse scenarios, and ensure robust system behavior without the constraints and limitations associated with real-world data collection.
The Evolution of Dataset Generation
Traditional approaches to AI model testing have relied heavily on manually curated datasets, often supplemented by basic data augmentation techniques that provide limited variation and fail to capture the full complexity of real-world scenarios. This approach has proven inadequate for developing truly robust AI systems that must perform reliably across diverse conditions, handle unexpected inputs gracefully, and maintain consistent performance when deployed in production environments where data distribution may differ significantly from training conditions.
The evolution toward synthetic dataset generation represents a paradigm shift that empowers developers to create comprehensive testing environments that systematically explore the full parameter space of potential inputs, edge cases, and failure modes. This systematic approach to dataset creation enables more thorough validation of AI system behavior while providing granular control over data characteristics, distribution properties, and the specific scenarios that models encounter during testing and validation phases.
Modern synthetic data generation techniques leverage advanced algorithms, generative models, and domain-specific knowledge to create datasets that not only match the statistical properties of real-world data but also systematically explore regions of the input space that would be difficult or impossible to capture through traditional data collection methods. This comprehensive coverage ensures that AI systems are tested against a broad spectrum of scenarios, improving their robustness and reliability when deployed in production environments.
Foundational Principles of Synthetic Data
The creation of effective synthetic datasets requires a deep understanding of both the underlying domain characteristics and the specific requirements of the AI systems being tested. Successful synthetic data generation goes beyond simple random sampling and instead focuses on creating data that captures the essential patterns, relationships, and statistical properties that define the problem domain while systematically exploring edge cases and boundary conditions that are critical for comprehensive testing.
Statistical fidelity represents one of the most fundamental aspects of synthetic data generation, requiring that generated datasets accurately reflect the distributional properties, correlation structures, and dependency relationships present in real-world data. This statistical alignment ensures that AI models trained or tested on synthetic data will exhibit similar behavior patterns when exposed to authentic data sources, maintaining the validity and relevance of testing results obtained through synthetic dataset evaluation.
Leverage advanced AI capabilities with Claude for sophisticated data analysis and synthetic dataset design that incorporates complex domain knowledge and statistical requirements. The integration of AI-powered analysis tools enables developers to create more sophisticated synthetic datasets that capture subtle patterns and relationships that might be overlooked through traditional statistical approaches.
Techniques for Structured Data Generation
Structured data generation encompasses a wide range of methodologies designed to create tabular datasets, relational database content, and other forms of organized information that maintain logical consistency, referential integrity, and realistic value distributions. The generation of synthetic structured data requires careful consideration of column relationships, constraint satisfaction, and the preservation of business logic that governs how different data elements interact within the broader system context.
Rule-based generation approaches provide deterministic methods for creating structured datasets that conform to specific business rules, validation constraints, and logical relationships. These approaches excel in scenarios where data generation must satisfy complex interdependencies, maintain referential integrity across multiple tables, and ensure that generated records represent valid business entities that could realistically exist within the target domain.
Probabilistic generation methods leverage statistical models, learned distributions, and correlation matrices to create structured datasets that capture the natural variation and randomness present in real-world data sources. These techniques enable the generation of datasets that exhibit realistic patterns of missing values, outlier distributions, and correlation structures while maintaining the ability to systematically explore different regions of the parameter space through controlled sampling strategies.
Machine learning-based generation approaches utilize trained models, including variational autoencoders, generative adversarial networks, and transformer-based architectures, to learn complex patterns from existing datasets and generate new synthetic records that maintain similar characteristics while introducing appropriate variation. These approaches are particularly effective for capturing subtle patterns and non-linear relationships that would be difficult to model through traditional statistical methods.
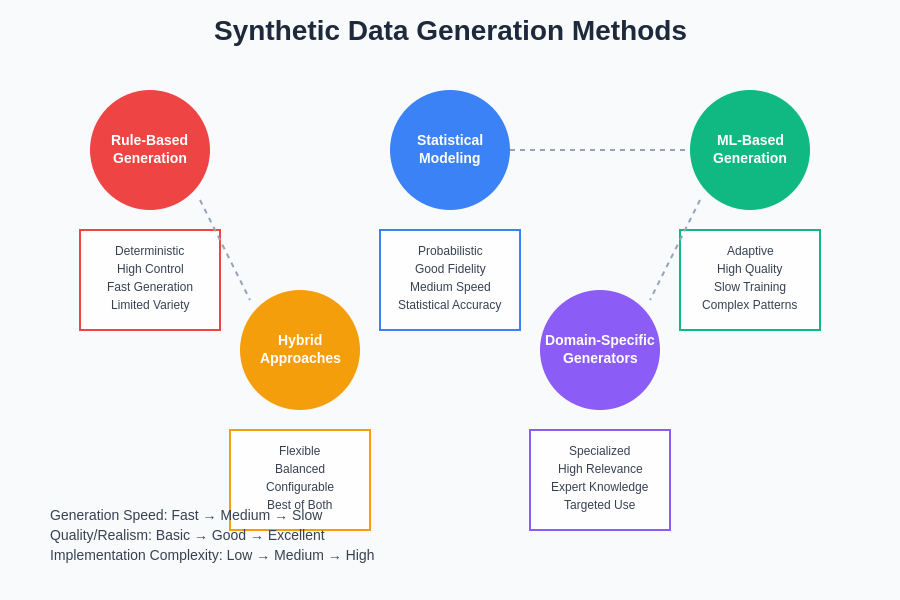
The landscape of synthetic data generation encompasses multiple methodologies, each optimized for different data types, quality requirements, and computational constraints. Understanding the strengths and limitations of various approaches enables developers to select the most appropriate techniques for their specific testing and validation requirements.
Advanced Image and Media Synthesis
Visual data generation has experienced revolutionary advances through the development of sophisticated generative models capable of creating photorealistic images, videos, and other media content that serves diverse testing and validation requirements. These capabilities enable comprehensive testing of computer vision systems, media processing algorithms, and multimodal AI applications without requiring extensive collections of real-world visual content.
Generative Adversarial Networks have established themselves as powerful tools for creating high-quality synthetic images that capture the essential visual characteristics of specific domains while enabling systematic exploration of visual variations, lighting conditions, object configurations, and environmental factors. The adversarial training process ensures that generated images maintain photorealistic quality while providing fine-grained control over specific visual attributes and scene characteristics.
Diffusion models represent the cutting edge of image synthesis technology, offering unprecedented control over image generation through text prompts, style transfer, and conditional generation techniques. These models enable the creation of diverse visual datasets that systematically explore different visual scenarios, object combinations, and environmental conditions that are essential for comprehensive computer vision system testing.
Video synthesis capabilities extend these principles to temporal media, enabling the generation of dynamic visual content that captures motion patterns, temporal consistency, and the complex interactions between objects over time. This capability is essential for testing video analysis systems, autonomous vehicle perception algorithms, and other AI applications that must process temporal visual information.
Natural Language and Text Generation
The generation of synthetic text data has become increasingly sophisticated through the deployment of large language models and specialized text generation techniques that can create diverse, contextually appropriate, and linguistically correct content across multiple domains and use cases. These capabilities enable comprehensive testing of natural language processing systems, content analysis algorithms, and conversational AI applications without requiring extensive collections of human-generated text.
Domain-specific text generation involves training or fine-tuning language models on specialized corpora to generate content that reflects the vocabulary, style, and structural characteristics specific to particular industries, academic fields, or communication contexts. This approach ensures that synthetic text data accurately represents the linguistic patterns and domain-specific knowledge that AI systems will encounter in production environments.
Multilingual text generation capabilities enable the creation of synthetic datasets that span multiple languages, dialects, and cultural contexts, facilitating the testing of global AI applications and ensuring that natural language processing systems perform consistently across diverse linguistic environments. These capabilities are essential for developing AI systems that must operate effectively in international markets and multicultural contexts.
Conversational data generation focuses on creating realistic dialogue patterns, question-answer pairs, and interactive text sequences that capture the natural flow of human communication. This specialized form of text generation is crucial for testing chatbots, virtual assistants, and other conversational AI systems that must engage with users in natural, contextually appropriate ways.
The landscape of synthetic data generation encompasses multiple methodologies, each optimized for different data types, quality requirements, and computational constraints. Understanding the strengths and limitations of various approaches enables developers to select the most appropriate techniques for their specific testing and validation requirements.
Time Series and Temporal Data Simulation
Temporal data presents unique challenges for synthetic generation due to the complex dependencies, seasonal patterns, and long-range correlations that characterize time-based datasets. Effective time series synthesis requires sophisticated modeling approaches that capture both the statistical properties and the temporal dynamics that define how values evolve over time.
Autoregressive models provide foundational approaches for time series generation by modeling how current values depend on historical observations, enabling the generation of synthetic sequences that maintain realistic temporal dependencies and trend patterns. These models can be extended to incorporate external factors, seasonal components, and regime changes that influence temporal behavior.
State space models offer more sophisticated approaches to temporal data generation by explicitly modeling the underlying latent states that drive observable time series behavior. These models enable the generation of synthetic datasets that capture complex temporal patterns, non-stationary behavior, and the influence of unobserved factors on system dynamics.
Enhance your AI research capabilities with Perplexity for comprehensive analysis of temporal data patterns and advanced time series modeling techniques. The integration of advanced analytical tools enables more sophisticated approaches to temporal data synthesis that capture subtle patterns and dependencies.
Neural approaches to time series generation, including recurrent neural networks, LSTMs, and transformer architectures, provide powerful methods for learning complex temporal patterns from historical data and generating synthetic sequences that maintain similar dynamic characteristics while exploring different temporal scenarios and edge cases.
Privacy-Preserving Synthetic Data
The generation of synthetic datasets that preserve privacy while maintaining utility represents one of the most critical aspects of modern AI development, particularly in domains involving sensitive personal information, healthcare records, financial data, and other confidential information sources. Privacy-preserving synthetic data generation techniques enable comprehensive AI system testing without exposing sensitive information or violating privacy regulations.
Differential privacy techniques provide mathematical guarantees about the privacy protection offered by synthetic datasets by introducing carefully calibrated noise that prevents the identification of individual records while preserving the statistical properties necessary for effective AI model testing. These techniques enable the creation of synthetic datasets that maintain utility for machine learning applications while providing strong privacy guarantees.
Federated synthetic data generation approaches enable the creation of comprehensive datasets by combining insights from multiple data sources without requiring direct data sharing or centralized data collection. These approaches are particularly valuable for creating synthetic datasets that represent diverse populations and use cases while maintaining the privacy and security of individual data contributors.
Anonymization and pseudonymization techniques complement synthetic data generation by providing additional layers of privacy protection through the removal or transformation of identifying information. The combination of these approaches with synthetic data generation creates robust privacy-preserving workflows that enable comprehensive AI testing while maintaining compliance with privacy regulations and ethical guidelines.
Quality Assessment and Validation
The effectiveness of synthetic datasets depends critically on rigorous quality assessment and validation procedures that ensure generated data maintains the statistical properties, distributional characteristics, and domain-specific patterns necessary for meaningful AI system testing. Comprehensive validation approaches combine statistical analysis, domain expertise, and empirical testing to verify that synthetic datasets serve their intended purposes effectively.
Statistical validation techniques focus on comparing the distributional properties, correlation structures, and summary statistics of synthetic datasets with those of reference datasets to ensure that generated data maintains the essential statistical characteristics of the target domain. These comparisons help identify potential biases, distributional shifts, or other artifacts that might compromise the effectiveness of synthetic data for AI testing purposes.
Domain-specific validation involves leveraging expert knowledge and domain understanding to assess whether synthetic datasets capture the essential patterns, relationships, and characteristics that define the problem space. This validation approach is particularly important for specialized domains where statistical similarity alone may not be sufficient to ensure that synthetic data adequately represents real-world scenarios.
Empirical validation through AI model testing provides direct assessment of synthetic dataset effectiveness by comparing the performance of models trained or tested on synthetic data with those evaluated on real-world datasets. This validation approach provides concrete evidence about the utility of synthetic data for specific AI applications and helps identify areas where synthetic data generation techniques may need refinement.
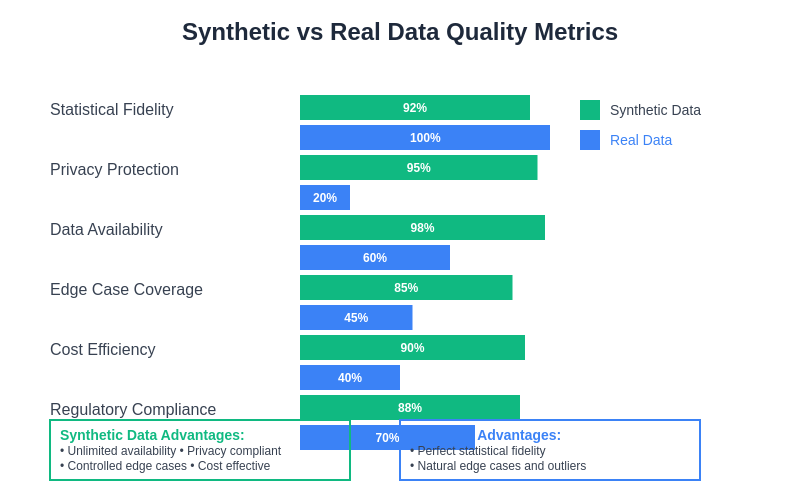
Quality assessment frameworks provide systematic approaches for evaluating synthetic dataset effectiveness across multiple dimensions, including statistical fidelity, privacy preservation, computational efficiency, and practical utility for AI system development and testing.
Implementation Frameworks and Tools
The practical application of synthetic data generation requires robust frameworks and tools that streamline the creation, validation, and deployment of synthetic datasets across diverse AI development workflows. Modern synthetic data platforms provide comprehensive solutions that integrate generation algorithms, quality assessment tools, and deployment infrastructure to support enterprise-scale synthetic data initiatives.
Open-source frameworks such as SDV (Synthetic Data Vault), DataSynthesizer, and CTGAN provide accessible implementations of state-of-the-art synthetic data generation algorithms along with evaluation metrics and validation tools. These frameworks enable developers to quickly implement synthetic data generation capabilities without requiring deep expertise in the underlying mathematical and algorithmic foundations.
Commercial synthetic data platforms offer enterprise-grade solutions that combine advanced generation algorithms with scalable infrastructure, compliance management, and integration capabilities designed to support large-scale AI development initiatives. These platforms typically provide user-friendly interfaces, automated quality assessment, and integration with popular machine learning frameworks and data engineering tools.
Cloud-based synthetic data services provide on-demand access to synthetic data generation capabilities without requiring local infrastructure investment or specialized expertise. These services enable organizations to leverage advanced synthetic data techniques while maintaining flexibility and scalability in their AI development workflows.
Integration with AI Development Pipelines
The effective utilization of synthetic datasets requires seamless integration with existing AI development pipelines, automated testing frameworks, and continuous integration systems that support modern software development practices. This integration ensures that synthetic data generation becomes an integral part of the development workflow rather than an isolated activity.
Automated dataset generation capabilities enable the creation of synthetic datasets as part of continuous integration pipelines, ensuring that AI models are consistently tested against fresh synthetic data that explores different scenarios and edge cases. This automation helps maintain the robustness and reliability of AI systems throughout the development lifecycle.
Version control and dataset management systems provide essential infrastructure for tracking synthetic dataset evolution, maintaining reproducibility, and managing the lifecycle of synthetic data assets. These systems ensure that synthetic datasets remain aligned with evolving AI system requirements while providing auditability and traceability for compliance and quality assurance purposes.
Testing framework integration enables the seamless incorporation of synthetic datasets into existing AI model testing and validation procedures, ensuring that synthetic data evaluation becomes a standard component of AI system quality assurance. This integration helps identify potential issues and performance degradation before AI systems are deployed to production environments.
Performance Optimization and Scalability
The generation of large-scale synthetic datasets requires careful attention to performance optimization and scalability considerations that ensure synthetic data creation remains practical and cost-effective for enterprise applications. Modern synthetic data generation techniques must balance quality requirements with computational efficiency to support the data volume requirements of contemporary AI systems.
Distributed generation approaches leverage parallel computing resources and cloud infrastructure to accelerate synthetic data creation while maintaining quality and consistency across generated datasets. These approaches enable the creation of massive synthetic datasets that would be impractical to generate using single-machine approaches.
Incremental generation techniques enable the efficient creation of synthetic datasets that can be extended and refined over time without requiring complete regeneration. This approach is particularly valuable for scenarios where synthetic data requirements evolve as AI systems mature and new testing scenarios are identified.
Caching and reuse strategies optimize synthetic data generation by identifying opportunities to reuse previously generated data components, leverage pre-computed statistical models, and minimize redundant computation. These optimizations significantly reduce the time and computational resources required for synthetic dataset creation.
Domain-Specific Applications
Different application domains present unique challenges and requirements for synthetic data generation, necessitating specialized approaches that address domain-specific constraints, regulatory requirements, and use case characteristics. Understanding these domain-specific considerations is essential for creating effective synthetic datasets that serve their intended purposes.
Healthcare applications require synthetic data generation techniques that maintain patient privacy while capturing the complex relationships between symptoms, diagnoses, treatments, and outcomes that characterize medical data. These applications often involve regulatory compliance requirements that influence synthetic data generation strategies and validation procedures.
Financial services applications demand synthetic datasets that capture the complex patterns of financial transactions, risk factors, and market dynamics while maintaining compliance with financial regulations and privacy requirements. The generation of synthetic financial data must carefully balance realism with privacy protection to support effective AI system testing.
Autonomous vehicle development relies on synthetic datasets that capture diverse driving scenarios, weather conditions, traffic patterns, and edge cases that are difficult or dangerous to collect through real-world data gathering. The quality and comprehensiveness of synthetic driving data directly impacts the safety and reliability of autonomous vehicle systems.
Cybersecurity applications require synthetic datasets that represent diverse attack patterns, network configurations, and system vulnerabilities without exposing actual security information or creating additional attack vectors. The generation of synthetic cybersecurity data must balance realism with security considerations to support effective threat detection system development.
Future Directions and Emerging Trends
The field of synthetic data generation continues to evolve rapidly, driven by advances in generative modeling, computational capabilities, and the growing recognition of synthetic data as a critical enabler of AI system development and testing. Understanding emerging trends and future directions helps organizations prepare for the next generation of synthetic data capabilities and applications.
Foundation model approaches to synthetic data generation leverage large-scale pre-trained models to create high-quality synthetic datasets across multiple domains and modalities. These approaches promise to democratize access to sophisticated synthetic data generation capabilities while reducing the expertise and computational resources required for effective implementation.
Multimodal synthetic data generation techniques enable the creation of comprehensive datasets that span multiple data types, including text, images, audio, and sensor data, with maintained consistency and correlation across modalities. This capability is essential for testing complex AI systems that process multiple forms of input data simultaneously.
Adaptive synthetic data generation systems automatically adjust generation parameters and techniques based on AI model performance feedback, creating closed-loop systems that continuously optimize synthetic dataset characteristics to improve AI system testing effectiveness. This adaptive approach promises to make synthetic data generation more responsive to evolving AI system requirements.
Real-time synthetic data generation capabilities enable the creation of synthetic datasets on-demand during AI system operation, supporting dynamic testing scenarios and adaptive system behavior that responds to changing operational conditions. This capability extends synthetic data applications beyond static testing to include dynamic system adaptation and continuous learning scenarios.
The integration of synthetic data generation with emerging AI technologies, including quantum computing, neuromorphic systems, and edge AI platforms, will create new opportunities and challenges for synthetic dataset creation and utilization. Understanding these emerging integration opportunities helps organizations prepare for the future evolution of AI system development and testing methodologies.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The implementation of synthetic data generation techniques should be carefully evaluated for specific use cases, regulatory requirements, and technical constraints. Readers should conduct thorough testing and validation of synthetic data approaches before deployment in production environments. The effectiveness and appropriateness of synthetic data techniques may vary significantly depending on specific domain requirements, data characteristics, and application contexts.