
The complexity of modern artificial intelligence and machine learning projects has necessitated sophisticated data management strategies that transcend the boundaries of single cloud providers. Organizations pursuing advanced AI initiatives increasingly find themselves navigating the intricate landscape of multi-cloud data management, where datasets must be efficiently synchronized, secured, and optimized across diverse cloud environments. This distributed approach to AI dataset management represents both a strategic advantage and a technical challenge that requires careful planning, robust architecture, and comprehensive understanding of cloud-native technologies.
Explore the latest AI infrastructure trends to understand how organizations are leveraging multi-cloud strategies for enhanced performance, reduced vendor lock-in, and improved disaster recovery capabilities. The evolution of multi-cloud data management reflects the growing sophistication of AI workloads and the need for flexible, scalable infrastructure that can adapt to changing business requirements while maintaining optimal performance across different computing environments.
The Strategic Imperative of Multi-Cloud AI Data Management
The decision to implement multi-cloud data strategies for AI datasets stems from various compelling business and technical considerations that extend far beyond simple cost optimization. Organizations recognize that distributing AI datasets across multiple cloud providers creates unprecedented opportunities for enhanced performance, improved reliability, and strategic flexibility that single-cloud approaches cannot match. This strategic distribution enables organizations to leverage the unique strengths of different cloud providers while mitigating the risks associated with vendor lock-in and single points of failure.
The benefits of multi-cloud AI data management become particularly evident when considering the specialized services offered by different cloud providers. Amazon Web Services excels in mature data lakes and comprehensive machine learning services, Google Cloud Platform provides superior big data analytics and TensorFlow integration, while Microsoft Azure offers seamless enterprise integration and hybrid cloud capabilities. By strategically distributing datasets and workloads across these platforms, organizations can optimize their AI initiatives to leverage the best features of each provider while maintaining operational flexibility and competitive advantage.
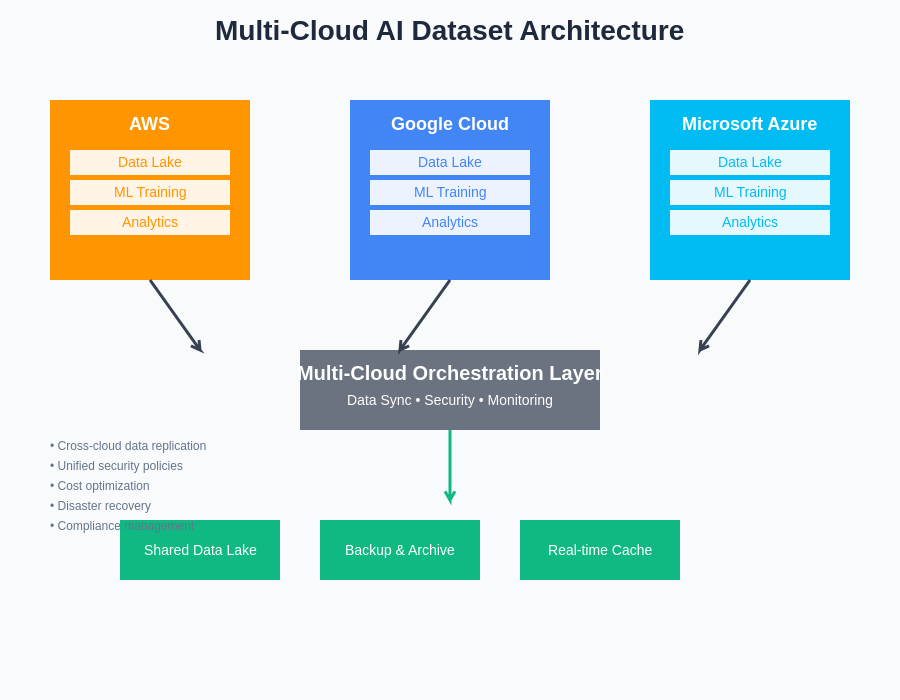
The architectural complexity of multi-cloud AI dataset management requires sophisticated orchestration layers that can seamlessly coordinate data flow, processing, and synchronization across diverse cloud environments while maintaining unified governance and security policies.
Enhance your AI workflows with advanced reasoning capabilities using Claude, which can help design and optimize multi-cloud data architectures for complex machine learning projects. The integration of intelligent planning tools with multi-cloud strategies enables organizations to make informed decisions about data placement, processing optimization, and resource allocation across distributed cloud environments.
Architectural Foundations for Distributed AI Dataset Management
Establishing robust architectural foundations for multi-cloud AI dataset management requires careful consideration of data flow patterns, processing requirements, and integration points between different cloud environments. The architecture must accommodate various data types, from structured databases to unstructured multimedia content, while ensuring consistent performance and accessibility across all cloud providers. This foundational approach involves creating standardized data formats, implementing universal access patterns, and establishing consistent metadata management practices that work seamlessly across diverse cloud platforms.
The cornerstone of effective multi-cloud AI data architecture lies in the implementation of cloud-agnostic data abstraction layers that provide unified interfaces for data access and manipulation regardless of the underlying cloud provider. These abstraction layers enable development teams to work with consistent APIs and data models while the underlying infrastructure handles the complexities of multi-cloud data distribution, synchronization, and optimization. This approach significantly reduces development complexity while maintaining the flexibility to optimize data placement and processing based on specific requirements and cost considerations.
Data Synchronization and Consistency Strategies
Maintaining data consistency and synchronization across multiple cloud providers presents one of the most significant technical challenges in multi-cloud AI dataset management. The distributed nature of multi-cloud environments introduces latency, network partitioning, and eventual consistency considerations that must be carefully addressed to ensure data integrity and availability. Effective synchronization strategies must balance the competing requirements of performance, consistency, and cost while accommodating the varying network characteristics and service capabilities of different cloud providers.
The implementation of robust data synchronization requires sophisticated understanding of distributed systems principles, including concepts such as eventual consistency, conflict resolution, and distributed transaction management. Organizations must carefully evaluate different synchronization patterns, from real-time streaming replication to batch-based synchronization, depending on their specific use cases and performance requirements. The choice of synchronization strategy significantly impacts system performance, cost, and operational complexity, making it crucial to align technical decisions with business objectives and operational capabilities.
Security and Compliance in Multi-Cloud Data Environments
Security considerations in multi-cloud AI dataset management extend far beyond traditional single-cloud security models, requiring comprehensive approaches that address the unique challenges of distributed data governance, cross-cloud network security, and consistent policy enforcement across diverse cloud environments. The complexity of managing security policies across multiple cloud providers necessitates sophisticated identity and access management systems that can provide unified authentication, authorization, and audit capabilities while respecting the specific security features and limitations of each cloud platform.
The implementation of effective multi-cloud security strategies requires deep understanding of each cloud provider’s security model, including their encryption capabilities, network isolation features, and compliance certifications. Organizations must establish consistent security baselines that can be implemented across all cloud providers while leveraging provider-specific security enhancements where appropriate. This approach ensures that sensitive AI datasets receive adequate protection regardless of their physical location while maintaining compliance with relevant industry regulations and organizational policies.
Leverage comprehensive research capabilities with Perplexity to stay updated on evolving security best practices and compliance requirements for multi-cloud data management. The rapidly changing landscape of cloud security requires continuous monitoring of new threats, emerging best practices, and evolving regulatory requirements that impact multi-cloud AI dataset management strategies.
Cost Optimization and Resource Management
Effective cost management in multi-cloud AI dataset environments requires sophisticated understanding of each cloud provider’s pricing models, performance characteristics, and optimization opportunities. The complexity of multi-cloud cost optimization extends beyond simple price comparisons to include considerations of data transfer costs, storage tier optimization, compute resource efficiency, and the hidden costs of data synchronization and management overhead. Organizations must develop comprehensive cost models that account for all aspects of multi-cloud operations while identifying opportunities for optimization through intelligent data placement and processing strategies.
The dynamic nature of cloud pricing and the varying cost structures of different providers create opportunities for significant cost savings through intelligent workload placement and resource utilization strategies. Organizations can optimize costs by leveraging spot instances for batch processing workloads, utilizing reserved capacity for predictable workloads, and implementing automated systems that dynamically move workloads to the most cost-effective cloud provider based on current pricing and performance characteristics. This dynamic optimization requires sophisticated monitoring and automation systems that can make real-time decisions about resource allocation and workload placement.
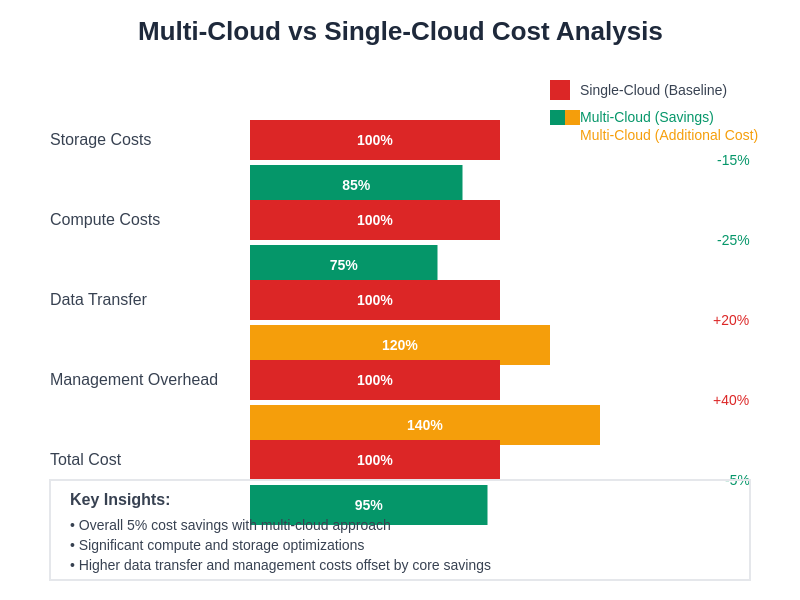
The financial implications of multi-cloud adoption reveal a complex balance of cost optimization opportunities and additional management overhead, with strategic implementations typically achieving overall cost savings through optimized resource utilization and competitive pricing leverage across multiple providers.
Data Pipeline Orchestration Across Cloud Boundaries
The orchestration of data pipelines that span multiple cloud providers requires sophisticated workflow management systems capable of handling the complexities of distributed processing, cross-cloud data movement, and heterogeneous service integration. Effective pipeline orchestration must accommodate varying service capabilities, performance characteristics, and operational constraints of different cloud providers while maintaining end-to-end visibility and control over data processing workflows. This orchestration challenge becomes particularly complex when dealing with real-time streaming data or time-sensitive machine learning training workflows that require coordinated processing across multiple cloud environments.
Modern data pipeline orchestration solutions for multi-cloud environments must provide robust error handling, automatic retry mechanisms, and intelligent failover capabilities that can gracefully handle cloud provider outages or performance degradation. The orchestration system must also support complex dependency management, conditional processing logic, and dynamic resource scaling to optimize performance and cost across diverse cloud environments. These capabilities enable organizations to build resilient data processing pipelines that can adapt to changing conditions while maintaining consistent performance and reliability.
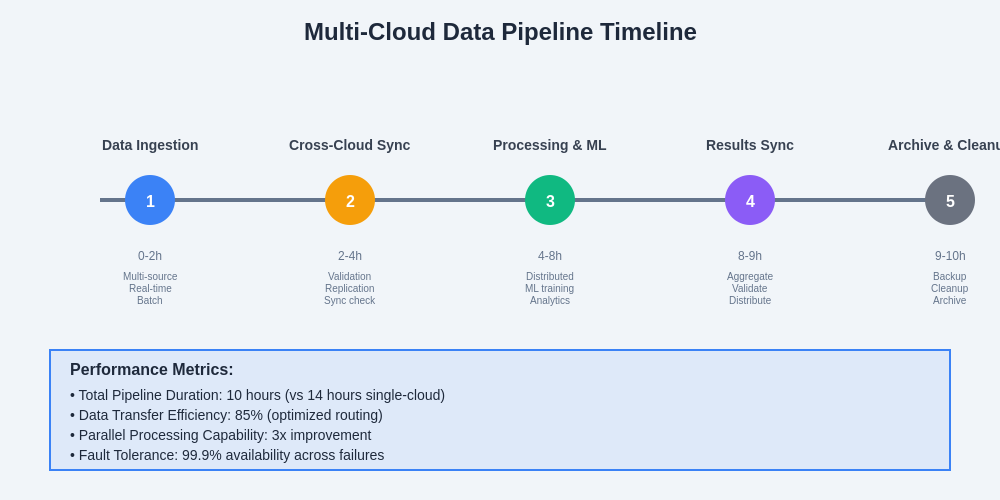
The temporal complexity of multi-cloud data pipeline execution demonstrates significant performance improvements over single-cloud approaches, with parallel processing capabilities and optimized data routing contributing to enhanced overall efficiency and reduced time-to-insight for AI and machine learning workloads.
Performance Optimization and Latency Management
Performance optimization in multi-cloud AI dataset management requires careful consideration of network latency, data locality, and processing efficiency across distributed cloud environments. The geographic distribution of cloud resources creates opportunities for improved global performance through strategic data placement and edge computing strategies, but also introduces challenges related to network latency and data transfer costs. Organizations must balance the benefits of data distribution against the performance implications of cross-cloud data access and processing workflows.
Effective performance optimization strategies for multi-cloud AI environments involve intelligent data caching, predictive data prefetching, and dynamic workload placement based on current network conditions and resource availability. These optimization techniques require sophisticated monitoring and analytics systems that can continuously evaluate performance metrics and automatically adjust data placement and processing strategies to maintain optimal performance. The implementation of these optimization strategies often requires custom development and integration work to bridge the gaps between different cloud providers’ native optimization features.
Machine Learning Model Distribution and Training Strategies
The distribution of machine learning model training across multiple cloud providers presents unique opportunities for enhanced performance and resource optimization, but also introduces significant challenges related to distributed training coordination, model synchronization, and result aggregation. Organizations must carefully evaluate different distributed training strategies, from simple data parallelism to sophisticated model parallelism approaches, depending on their specific model architectures and performance requirements. The choice of distributed training strategy significantly impacts training time, resource utilization, and overall project costs.
Advanced distributed training strategies for multi-cloud environments require sophisticated understanding of machine learning frameworks, distributed computing principles, and cloud-specific optimization techniques. Organizations must consider factors such as network bandwidth between cloud providers, computational capabilities of different instance types, and the specific features of each cloud provider’s machine learning services when designing distributed training strategies. The successful implementation of these strategies often requires custom integration work and careful performance tuning to achieve optimal results across diverse cloud environments.
Data Governance and Regulatory Compliance
Data governance in multi-cloud AI environments requires comprehensive frameworks that address the unique challenges of distributed data management while ensuring compliance with relevant regulatory requirements such as GDPR, HIPAA, and industry-specific data protection standards. The complexity of managing data governance across multiple cloud providers necessitates sophisticated policy management systems that can enforce consistent governance policies while accommodating the specific capabilities and limitations of each cloud platform. This governance framework must address data lineage tracking, access control management, and audit trail maintenance across distributed cloud environments.
The implementation of effective data governance strategies requires close collaboration between technical teams, legal departments, and compliance officers to ensure that multi-cloud data management practices align with organizational policies and regulatory requirements. Organizations must establish clear data classification schemes, implement robust access control mechanisms, and maintain comprehensive audit trails that can demonstrate compliance with relevant regulations. The dynamic nature of multi-cloud environments requires automated governance systems that can continuously monitor compliance status and automatically enforce policy requirements across all cloud providers.
Monitoring and Observability Across Cloud Platforms
Comprehensive monitoring and observability in multi-cloud AI dataset environments requires sophisticated systems capable of providing unified visibility into performance, security, and operational metrics across diverse cloud platforms. The heterogeneous nature of multi-cloud environments creates challenges for traditional monitoring approaches, necessitating the development of cloud-agnostic monitoring strategies that can normalize and correlate metrics from different cloud providers. Effective observability solutions must provide real-time visibility into data pipeline performance, resource utilization, and system health while enabling rapid identification and resolution of issues across distributed cloud environments.
The implementation of comprehensive observability solutions requires integration with multiple cloud provider monitoring services, custom metric collection systems, and centralized analytics platforms that can provide actionable insights into multi-cloud operations. Organizations must establish standardized logging and monitoring practices that work consistently across all cloud providers while leveraging provider-specific monitoring capabilities where appropriate. This comprehensive observability enables proactive management of multi-cloud AI datasets and supports data-driven optimization of performance and costs.
Disaster Recovery and Business Continuity Planning
Disaster recovery planning for multi-cloud AI datasets requires sophisticated strategies that leverage the distributed nature of multi-cloud environments to provide enhanced resilience and business continuity capabilities. The geographic distribution of cloud resources creates opportunities for robust disaster recovery strategies that can maintain service availability even in the event of significant regional outages or provider-specific failures. Organizations must develop comprehensive backup and recovery strategies that account for the unique characteristics of AI datasets, including their size, complexity, and interdependencies with machine learning models and processing pipelines.
Effective disaster recovery strategies for multi-cloud AI environments must address both data recovery and service continuity requirements, ensuring that critical AI workflows can continue operating even when primary cloud resources become unavailable. This requires sophisticated automation systems that can automatically detect failures, initiate failover procedures, and restore services using backup resources in alternative cloud environments. The complexity of these disaster recovery strategies requires careful testing and validation to ensure that they work effectively under various failure scenarios.
Future Trends and Emerging Technologies
The evolution of multi-cloud AI dataset management continues to be shaped by emerging technologies such as edge computing, quantum computing integration, and advanced AI-driven automation systems that promise to further enhance the capabilities and efficiency of distributed data management strategies. Organizations must stay informed about these technological developments and evaluate their potential impact on existing multi-cloud strategies while preparing for future adoption of emerging capabilities. The rapid pace of technological change requires flexible architectures that can adapt to new technologies and evolving requirements without requiring complete system redesigns.
The integration of artificial intelligence and machine learning technologies into multi-cloud management systems themselves represents a significant trend that promises to automate many of the complex decisions and optimizations required for effective multi-cloud operations. These AI-driven management systems can automatically optimize data placement, predict performance bottlenecks, and recommend cost optimization strategies based on historical usage patterns and current system conditions. The development of these intelligent management capabilities represents a significant opportunity for organizations to reduce operational complexity while improving performance and cost efficiency.
The continued evolution of cloud provider services and capabilities will create new opportunities for enhanced multi-cloud integration and optimization, requiring organizations to continuously evaluate and adapt their multi-cloud strategies to leverage new features and capabilities. The successful navigation of this evolving landscape requires close collaboration between technical teams, vendor relationships, and strategic planning initiatives that can anticipate future requirements and prepare for emerging opportunities in multi-cloud AI dataset management.
Disclaimer
This article is for informational purposes only and does not constitute professional advice regarding cloud architecture, data management, or security practices. The views expressed are based on current understanding of multi-cloud technologies and their applications in AI dataset management. Readers should conduct their own research, consult with qualified professionals, and consider their specific requirements when implementing multi-cloud data management strategies. Cloud provider services, pricing, and capabilities are subject to change, and organizations should verify current information before making implementation decisions.